
- 1将AI助手集成到微信公众号中, 无代码实现智能对话能力_微信公众号如何引入ai回复
- 2中文自然语言处理--基于玻森情感词典自定义计算中文文本情感值
- 3LIF神经元介绍
- 4python使用nltk库中的download()下载无法使用_resource averaged_perceptron_tagger not found. ple
- 5事半功倍,掌握12个在VSCode中进行Python开发的小技巧_vscode如何编写python
- 6大模型内容分享(八):知识抽取简述_大模型知识抽取
- 7模型报错:RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory_maskrcnn报错_incompatiblekeys(missing_keys=[], unexp
- 8目标检测 | 盘点目标检测中的特征融合技巧(根据YOLO v4总结)
- 9基于GPT-SoVITS少样本语音转换的实时交互TTS_基于gpt-sovits的webtts
- 10typescript基础_declare class
Neural Approaches to Conversational AI Question Answering(问答,任务型对话,闲聊)_conversational questionanswering
赞
踩
摘要
本文概述了最近几年开发的对话式AI神经方法。 我们将对话系统分为三类:(1)问答代理,(2)面向任务的对话代理和(3)聊天机器人。 对于每个类别,我们将使用特定的系统和模型作为案例研究,对当前最先进的神经方法进行回顾,画出它们与传统方法之间的联系,并讨论已取得的进展和仍面临的挑战。
Chapter 1 Introduction
开发一种智能对话系统1,不仅可以模拟人类对话,还可以回答有关电影明星的最新消息到爱因斯坦的相对论等主题的问题,并完成诸如旅行计划之类的复杂任务,这是该国运行时间最长的目标之一AI。直到最近,这个目标仍然遥不可及。但是,现在,随着大量的对话数据可用于培训,并且在深度学习(DL)和强化学习(RL)中的突破被应用到了对话AI中,我们在学术研究界和业界都看到了可喜的成果。
会话式AI是自然用户界面的基础。这是一个快速发展的领域,吸引了自然语言处理(NLP),信息检索(IR)和机器学习(ML)社区的许多研究人员。例如,SIGIR 2018创建了一条人工智能,语义学和对话的新轨道,以桥接AI和IR方面的研究,特别是针对问题解答(QA),深度语义以及与智能代理的对话。
近年来,有关深度学习和对话系统的小型教程和调查论文行业兴起。 Yih等。 (2015b,2016);高(2017)回顾了针对IR和NLP任务广泛的深度学习方法,包括对话。 Chen等。 (2017e)提出了有关对话的教程,重点是面向任务的代理。 Serban等。 (2015年; 2018年)调查了可用于发展对话主体的公共对话数据集。 Chen等。 (2017b)回顾了流行的用于对话的深度神经网络模型,重点是有监督的学习方法。目前的工作大大扩展了Chen等人的研究范围。 (2017b); Serban等。 (2015)通过超越数据和监督学习来提供我们认为是针对对话AI的神经方法的首次调查,针对NLP和IR受众。2其贡献是:
•我们对最近几年开发的对话式AI神经方法进行了全面调查,涵盖了QA,面向任务和社交机器人,并具有最佳决策的统一视图。
•我们在现代神经方法和传统方法之间建立了联系,使我们能够更好地了解研究的原因和方式,以及如何继续前进。
•我们提出了使用监督学习和强化学习来培训对话代理的最新方法。
•我们勾勒出了由研究团体开发并在行业中发布的对话系统的概况,并通过案例研究展示了已取得的进展以及我们仍面临的挑战。
1.1 Who Should Read this Paper?
本文基于2018年SIGIR和ACL大会(Gao等人,2018a,b)上提供的教程,其中IR和NLP社区是主要目标受众。 但是,具有其他背景(例如机器学习)的观众也将发现它是具有大量指针的对话式AI的无障碍入门,尤其是最近开发的神经方法。
我们希望本文能够为学生,研究人员和软件开发人员提供宝贵的资源。 它提供了一个统一的视图,并详细介绍了理解和创建现代对话代理所需的重要思想和见解,这将有助于以看起来自然和直观的方式使数百万用户访问世界知识和服务。
该调查的结构如下:
•本章的其余部分介绍了对话任务,并提供了一个统一的视图,其中将开放域对话表述为最佳决策过程。
•第2章介绍了基本的数学工具和机器学习概念,并回顾了深度学习和强化学习技术的最新进展,这是开发神经对话代理的基础。
•第3章介绍了问题解答(QA)代理,重点介绍了基于知识的QA和机器阅读理解(MRC)的神经模型。
•第4章介绍了面向任务的对话代理,着重于将深度强化学习应用于对话管理。
•第5章介绍社交聊天机器人,重点介绍完全数据驱动的神经方法,以端对端地生成对话响应。
•第6章简要回顾了行业中的几种对话系统。
•第7章在本文的结尾部分讨论了研究趋势。
1.2 Dialogue: What Kinds of Problems?
图1.1显示了制定业务决策过程中的人与人对话。该示例说明了对话系统希望解决的各种问题:
•问题解答:代理需要根据从各种数据源(包括文本集合(如Web文档)和预编译的知识库,如销售和营销数据集)中获得的丰富知识,为用户查询提供简洁,直接的答案,如图所示。在图1.1中将3变为5。
•任务完成:座席需要完成用户任务,从餐馆预订到会议安排(例如,图1.1中的6到7号弯),以及商务旅行计划。
•社交聊天:座席需要与用户无缝且适当地对话(例如通过图灵测试测得的人),并提供有用的建议(例如,图1.1中的1至2)。
可以设想,上述对话可以由一组代理(也称为机器人)共同完成,每个代理都旨在解决特定类型的任务,例如QA机器人,任务完成机器人,社交聊天机器人。根据是否进行对话以帮助用户完成特定任务(例如,获取查询的答案或安排会议),这些漫游器可以分为两类:面向任务和聊天。
当今市场上大多数流行的个人助理,例如Amazon Alexa,Apple Siri,Google Home和Microsoft Cortana,都是面向任务的机器人。这些只能处理相对简单的任务,例如报告天气和请求歌曲。聊天对话机器人的一个示例是Microsoft XiaoIce。建立对话代理程序以完成如图1.1所示的复杂任务,对于IR和NLP社区以及AI来说,仍然是最根本的挑战之一。
典型的面向任务的对话代理由四个模块组成,如图1.2(上图)所示:(1)自然语言理解(NLU)模块,用于识别用户意图并提取相关信息; (2)状态跟踪器,用于跟踪对话状态,以捕获到目前为止会话中的所有基本信息; (3)一种对话策略,可根据当前状态选择下一步操作; (4)自然语言生成(NLG)模块,用于将主体动作转换为自然语言响应。近年来,趋势是通过使用深度神经网络统一这些模块来开发完全数据驱动的系统,该神经网络将用户输入直接映射到代理输出,如图1.2(底部)所示。


大多数面向任务的机器人都是使用模块化系统实现的,该机器人通常可以访问外部数据库,以在该数据库上查询完成任务的信息(Young等,2013; Tur and De Mori,2011)。 另一方面,社交聊天机器人通常使用单一(非模块化)系统来实现。 由于社交聊天机器人的主要目标是通过情感联系而不是完成特定任务而成为人类的AI伴侣,因此通常通过在大量的人与人之间的对话数据上训练基于DNN的响应生成模型来模仿人类的对话( Ritter等人,2011; Sordoni等人,2015b; Vinyals and Le,2015; Shang等人,2015)。 直到最近,研究人员才开始探索如何在世界知识(Ghazvininejad等人,2018)和图像(Mostafazadeh等人,2017)中建立交流的基础,从而使对话更加有趣和有趣。
1.3 A Unified View: Dialogue as Optimal Decision Making
图1.1中的示例对话可以表述为决策过程。它具有自然的层次结构:顶层进程选择要为特定子任务激活的代理(例如,回答问题,安排会议,提供推荐或只是随意聊天),而底层进程则受控制通过选定的代理,选择原始操作来完成子任务。
这样的分层决策过程可以在马尔可夫决策过程(MDP)的选项数学框架中进行铸造(Sutton等人,1999b),其中选项将原始动作概括为更高级别的动作。这是对传统MDP设置的扩展,在传统MDP设置中,代理只能在每个时间步选择原始动作,而代理可以选择“多步”动作,例如可以是一系列完成原始任务的原始动作。
如果我们将每个选项都视为一项行动,那么强化学习框架自然可以捕获高层和低层流程。对话代理在MDP中导航,并通过一系列离散步骤与其环境进行交互。在每个步骤中,代理都会观察当前状态,并根据策略选择一个操作。然后,特工会收到奖励并观察到新的状态,继续循环直到情节终止。对话学习的目标是找到最佳策略,以最大化预期的回报。表1.1使用统一的RL视图制定了一个对话主体样本,其中状态-动作空间描述了问题的复杂性,而奖励是要优化的目标函数。
分层MDP的统一视图已经被用来指导一些大型开放域对话系统的开发。最近的例子包括获得了2017年Amazon Alexa奖的社交聊天机器人Sounding Board 3,以及自2014年发布以来可以吸引全球超过6.6亿用户的最受欢迎的社交聊天机器人Microsoft XiaoIce4。这两种系统都使用分层对话经理:管理整个对话过程的管理员(最高级别),以及处理不同类型的会话段(子任务)的技能(低级)集合。
表1.1中的奖励功能在CPS中似乎是矛盾的(例如,我们需要最小化CPS才能有效完成任务,而最大化CPS来提高用户参与度),建议我们在开发时必须平衡长期和短期收益对话系统。例如,XiaoIce是针对用户参与度进行了优化的社交聊天机器人,但还配备了230多种技能,其中大部分是质量检查和任务导向的。 XiaoIce针对预期的CPS进行了优化,该CPS对应于长期而非短期的参与。尽管结合许多面向任务和QA技能可以在短期内降低CPS,因为这些技能可以通过最小化CPS来帮助用户更有效地完成任务,但是这些新技能使XiaoIce成为了有效且值得信赖的个人助手,从而加强了与人类用户的情感纽带长期来说。
尽管RL为构建对话代理提供了统一的ML框架,但应用RL需要通过与真实用户进行交互来训练对话代理,这在许多领域中都非常昂贵。因此,在实践中,我们经常使用结合了不同ML方法优势的混合方法。例如,我们可能会使用模仿和/或监督学习方法(如果存在大量的人与人之间的会话语料库)来获得合理的良好代理,应用RL继续改进它。 在本文的其余部分,我们将研究这些机器学习方法及其在训练对话系统中的用途。

1.4 The Transition of NLP to Neural Approaches
现在,神经方法正在改变NLP和IR的领域,其中数十年来,符号方法一直占据主导地位。
NLP应用程序与其他数据处理系统的不同之处在于,它们使用各种级别的语言知识,包括语音,形态,语法,语义和语篇(Jurafsky和Martin,2009年)。从历史上看,许多NLP领域都围绕着图1.3的体系结构进行组织,研究人员将其工作与一个或另一个组件任务(例如形态分析或解析)保持一致。通过将自然语言语句映射到(或从)一系列人类定义的,明确的符号表示(或从中生成),可以将这些组成任务视为在不同级别上解决(或实现)自然语言的歧义(或多样性)。作为词性(POS)标签,上下文无关文法,一阶谓词演算。随着数据驱动和统计方法的兴起,这些组件仍然存在,并已被改编为丰富的工程特征来源,可用于各种机器学习模型(Manning等人,2014)。
神经方法不依赖任何人类定义的符号表示,而是学习特定于任务的神经空间,其中使用低维连续向量将特定于任务的知识隐式表示为语义概念。如图1.4所示,神经方法通常通过三个步骤来执行NLP任务(例如,机器阅读理解和对话):(1)将符号用户输入和知识编码为它们的神经语义表示,其中语义相关或相似的概念是表示为彼此接近的向量; (2)在神经空间中进行推理以根据输入和系统状态生成系统响应; (3)将系统响应解码为在符号空间中输出的自然语言。编码,推理和解码是使用(不同体系结构的)神经网络实现的,可以通过反向传播和随机梯度下降以端到端的方式堆叠到深度神经网络中。
端到端训练导致最终应用程序与神经网络体系结构之间更紧密的耦合,从而减少了对传统NLP组件边界(如形态分析和解析)的需求。这极大地拉平了图1.3的技术堆栈,并大大减少了特征工程的需求。取而代之的是,重点已转移到针对最终应用精心定制日益复杂的神经网络架构。
混合方法的研究也结合了神经方法和符号方法的优势,例如(Mou等,2016; Liang等,2016)。 如图1.4所示,神经方法可以端到端的方式进行训练,对释义替换很健壮,但是在执行效率和可解释性方面很弱。 另一方面,象征性方法很难训练并且对释义交替很敏感,但是执行起来更容易解释和有效。

Chapter 2
Machine Learning Background
本章在后面的章节中简要介绍了与对话式AI最相关的深度学习和强化学习技术。
2.1 Machine Learning Basics
Mitchell(1997)广泛地将机器学习定义为包括任何计算机程序,该程序可以通过经验E改善在某些任务T上的性能,该任务由P度量。
如表1.1所示,对话是一个定义明确的学习问题,其中T,P和E指定如下:
•T:与用户进行对话以实现用户的目标。
•P:表1.1中定义的累积奖励。
•E:一组对话,每个对话都是一系列用户-代理交互。
举一个简单的例子,通过人工标注问题-答案对的经验,单回合QA对话代理可能会提高其性能,这可以通过在QA任务中生成的答案的准确性或相关性来衡量。
使用监督学习(SL)构建ML代理的常用方法包括数据集,模型,成本函数(又称损失函数)和优化过程。
•数据集由(x,y ∗)对组成,其中每个输入x都有一个真实的输出y ∗。在QA中,x由输入问题和从中生成答案的文档组成,而y ∗是由知识渊博的外部主管提供的所需答案。
•模型的形式通常为y = f(x;θ),其中f是由θ参数化的函数(例如神经网络),该函数将输入x映射到输出y。
•成本函数的形式为L(y ∗,f(x;θ))。 L(。)isoften设计了错误的平滑功能,并且可以区分。 θ。满足这些条件的常用成本函数是均方误差(MSE),定义为:
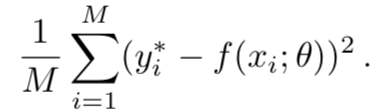
该优化可视为一种搜索算法,用于确定使L(。)最小的最佳θ。 鉴于L是可微的,深度学习最广泛使用的优化程序是小批量随机梯度下降(SGD),每批更新后的θ为
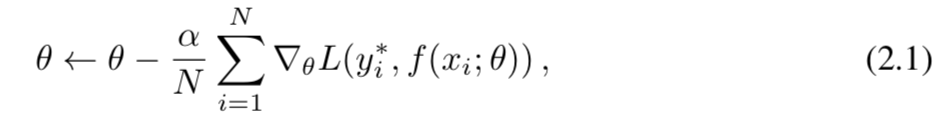
其中N是批次大小,α是学习率。
Common Supervised Learning Metrics.
训练模型后,可以在保留数据集上对其进行测试,以评估其泛化性能。 假设模型为f(·;θ),并且保持集包含N个数据点:D = {((x1,y1 ∗),(x2,y2 ∗),。 。 。 ,(xN,yN ∗)}。
第一个指标是上述均方误差,适用于回归问题(即yi ∗被视为实数值):
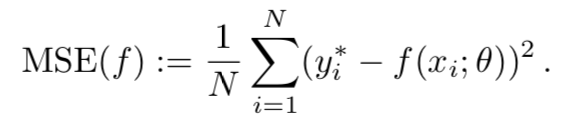
对于分类问题,yi ∗从被视为类别的有限集中获取值。 为简单起见,在此假设yi ∗∈{+1,−1},因此如果yi ∗为+1,则示例(xi,yi ∗)被称为正(或负)。
(或-1)。 •
经常使用以下指标:
准确性:f正确预测的示例分数:

其他度量也被广泛使用,尤其是对于二进制分类以外的复杂任务,例如BLEU评分(Papineni等,2002)。
Reinforcement Learning.以上SL配方适用于固定数据集上的预测任务。 但是,在诸如对话1的交互问题中,要获得既要正确又代表代理人必须采取行动的所有状态的期望行为的示例,可能是具有挑战性的。 在未开发的领土上,代理必须学习如何通过自身与未知环境进行交互来采取行动。 这种学习天堂被称为强化学习(RL),其中在主体和外部环境之间存在反馈回路。 换句话说,虽然SL从经验丰富的外部主管提供的以前的经验中学习,但RL则通过自己的经验来学习。 RL在几个重要方面与SL有所不同(Sutton和Barto,2018; Mitchell,1997)
Exploration-exploitation tradeoff.
在RL中,代理需要从环境中收集奖励信号。 这就提出了一个问题,即哪种实验策略可导致更有效的学习。 代理必须利用其已知的知识来获得高额报酬,同时还必须探索未知的状态和操作以在将来做出更好的操作选择。
Delayed reward and temporal credit assignment.
在RL中,不能像SL中那样以(x,y ∗)形式获得训练信息。 相反,当代理执行一系列操作时,环境仅提供延迟的奖励。 例如,直到会话结束,我们才知道对话是否能够成功完成任务。 因此,代理人必须确定产生其最终奖励将被归功于其序列中的哪些动作,这就是时间信用分配问题。
Partially observed states.
在许多RL问题中,在每个步骤中从环境中感知到的观察结果(例如,每个对话回合中的用户输入)仅提供了有关环境整体状态的部分信息,代理选择了下一步行动就基于该信息。 神经方法通过对在当前和过去的步骤中观察到的所有信息进行编码来学习一个深层的神经网络来表示状态,例如,所有先前的对话转弯以及从外部数据库中检索到的结果。
SL和RL的主要挑战是泛化-代理商在看不见的输入上表现良好的能力。 已经提出了许多学习理论和算法来成功地应对挑战,例如通过在可用的训练经验量与模型能力之间寻求良好的权衡来避免欠拟合和过拟合。 与以前的技术相比,神经方法通过利用深度神经网络的表示学习能力提供了一种可能更有效的解决方案,我们将在下一部分中进行简要介绍。
2.2 Deep Learning
深度学习(DL)涉及训练神经网络,其原始形式由单个层(即感知器)组成(Rosenblatt,1957)。 感知器甚至无法学习诸如逻辑XOR之类的简单功能,因此后续工作探索了“深度”架构的使用,该架构在输入和输出之间增加了隐藏层(Rosenblatt,1962; Minsky和Papert,1969),一种形式。 神经网络,通常称为多层感知器(MLP)或深度神经网络(DNN)。 本节介绍一些用于NLP和IR的常用DNN。 感兴趣的读者可以参考Goodfellow等。 (2016)进行全面讨论。
2.2.1 Foundations
考虑文本分类问题:用诸如“体育”和“政治”之类的域名标记文本字符串(例如,文档或查询)。如图2.1(左)所示,经典的ML算法首先使用一组手工设计的特征(例如,单词和字符的n元语法,实体和词组等)将文本字符串映射到矢量表示x,然后学习具有softmax层的线性分类器,以计算域标签y = f(x; W)的分布,其中W是使用SGD从训练数据中学习的矩阵,以最大程度地减少误分类错误。设计工作主要集中在要素工程上。
DL方法不是使用针对x的手工设计特征,而是使用DNN共同优化了特征表示和分类,如图2.1(右)所示。我们看到DNN由两半组成。上半部可视为线性分类器,类似于图2.1中的经典ML模型(左),不同之处在于其输入向量h不是基于手工设计的特征,而是使用下半部学习的DNN,可以看作是与分类器一起以端到端的方式优化的特征生成器。与经典ML不同,设计DL分类器的工作主要在于优化DNN架构以进行有效的表示学习。
对于NLP任务,根据我们希望在文本中捕获的语言结构的类型,我们可以应用不同类型的神经网络(NN)层结构,例如用于局部词依存关系的卷积层和用于全局词序列的递归层。这些层可以组合和堆叠以形成一个深层的体系结构,以在不同的抽象级别捕获不同的语义和上下文信息。下面介绍了几个广泛使用的NN层:
Word Embedding Layers.在符号空间中,每个单词都表示为一个热向量,其维数n是预定义词汇表的大小。 词汇量通常很大; 例如,n> 100K。 我们应用由线性投影矩阵We∈Rn×m参数化的词嵌入模型,将每个单热向量映射到m维实值向量(m≪ n)在神经空间中,语义上更相似的词的嵌入向量彼此更接近。

Fully Connected Layers.
它们执行W
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

