
- 1Hive08_分区表
- 2【AI大模型应用开发】【LangChain系列】1. 全面学习LangChain输入输出I/O模块:理论介绍+实战示例+细节注释_langchain+openai构建module i/o
- 3CityScapes数据集_leftimg8bit和rightimg8bit
- 4华为ensp中ospf多区域管理 原理及配置命令(详解)
- 5chatglm 130B:两个主要的稳定训练方法_chatglm13使用
- 6异常——获取异常信息
- 7LeetCode动态规划基础题-总结(超级长文)_一个人从一个房间走到另一个房间需要走n米,这个人每步可以走1米或2米,他一共有多
- 8CorelDRAW2024新功能介绍及CorelProducts Keygen注册机下载_cdr2024
- 9如何用Python编程进行文本处理_python文本处理
- 10数据挖掘——如何利用Python实现产品关联性分析apriori算法篇
AI视频风格转换:Stable Diffusion+TemporalKit_stable diffusion 视频换背景
赞
踩
基本方法
首先通过 Temporal-Kit 这个插件提取视频中的关键帧图片,然后使用 Stable Diffusion WebUI 重绘关键帧图片,然后再使用 Temporal-Kit 处理转换后的关键帧图片,它会自动补充关键帧之间的图片,最后拼合这些图片,形成视频。
这个方法建议尽量找些背景简单的、主体在画面中占比较大且动作变化较慢的,这样重绘时生成的图片元素会比较稳定、主体动作衔接到位,效果会好一些。
安装TemporalKit
方法一
在Stable Diffusion WebUI中通过网址安装,依次打开“扩展插件”-“从网址安装”页签,输入Github仓库地址: https://github.com/CiaraStrawberry/TemporalKit.git,然后点击“安装”,安装成功后会看到一个重启的提示,然后在“已安装”页签中重启就可以了。如下图所示:

重启SD后会在一级菜单中看到 Temporal-Kit 页签。

如果没有看到,请查看控制台是否有错误日志。我这里出现了找不到模块的错误:
ModuleNotFoundError: No module named 'moviepy'
ModuleNotFoundError: No module named 'scenedetect'
这是因为Temporal-Kit依赖的某些Python包不存在,使用pip安装它们就行了。
- source /root/stable-diffusion-webui/venv/bin/activate
- pip install moviepy
- pip install scenedetect
我这里还使用了 source xxx/activate,这是因为我的Stable Diffusion WebUI运行在一个Python虚拟环境中,如果你的也是,需要先激活这个虚拟环境,注意修改成你自己的文件路径,然后把包安装到这个虚拟环境中才可以找到它们。
安装完这些依赖包后,重启SD,正常情况下应该就能出来了。如果还不行,请留言说明问题。
方法二
不能直接访问Github,比如访问不了外网,可以把这个插件下载后,再放到SD WebUI的扩展插件目录中。
这个插件的下载地址:https://github.com/CiaraStrawberry/TemporalKit.git
如果你访问Github不方便,也可以关注我的公/众/号:萤火遛AI(yinghuo6ai),发消息:视频风格转换,即可获取下载地址。
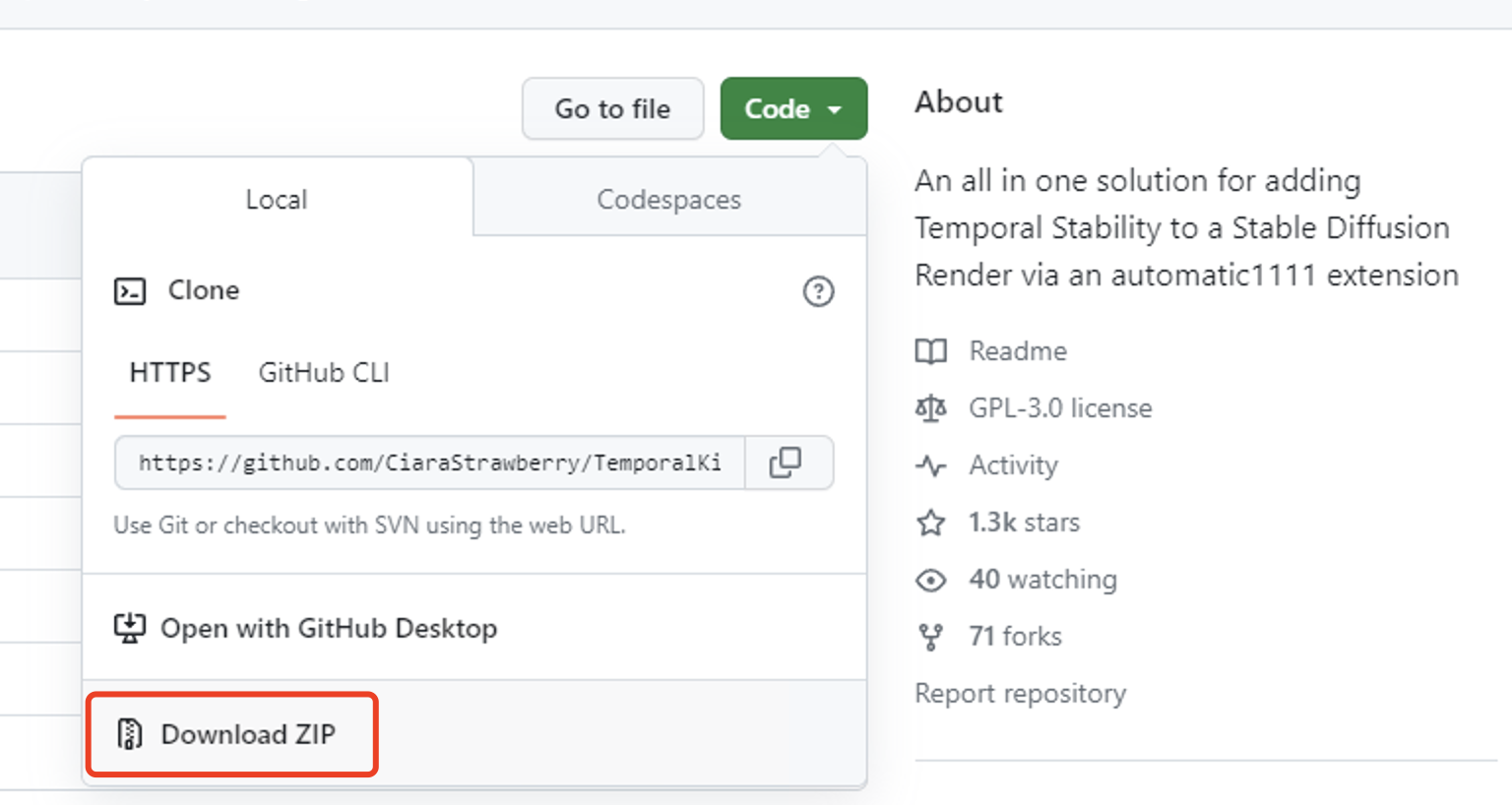
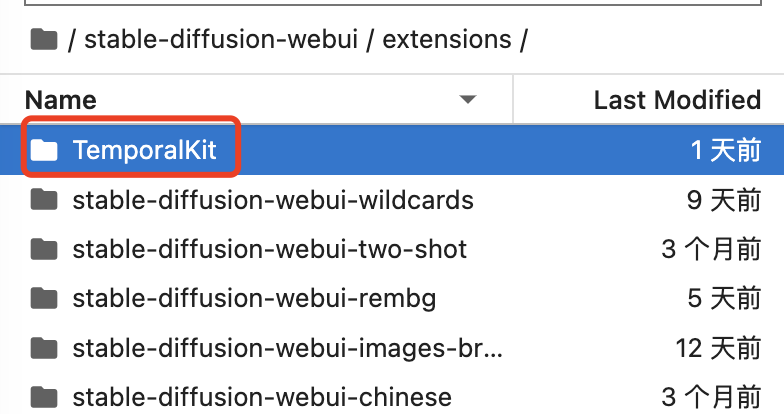
把插件解压后,放到你的SD WebUI的extensions目录中,就像下面图片中这样:
提取关键帧
为什么要提取关键帧?提取关键帧就是把视频中动作变化比较大的画面转成图片,下一步就是对这些图片进行重绘。如果不提取关键帧,而是把视频的每一帧都重绘,一是工作量大,二是重绘的每张图片可能都有点不一样,画面可能闪烁比较严重。
在SD WebUI的主页签中找到 Temporal-Kit,点击打开。然后接着点击“Pre-Processing”,在视频区域这里上传待处理的视频,这是我从抖音上截取的一段(文章最后会提供这个视频的下载地址)。不要马上点击“运行”,还有一些设置,请继续看下文。
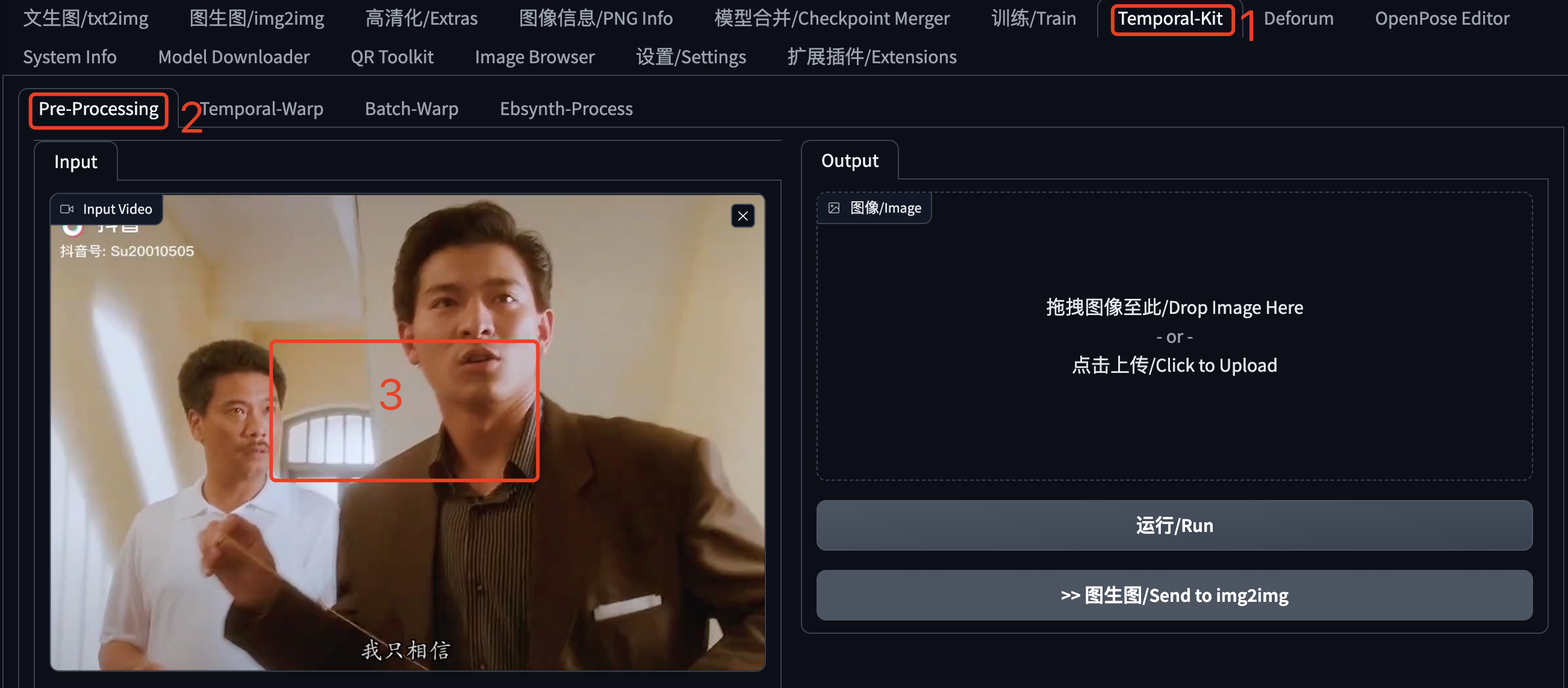
在视频下方可以看到这些设置,这些都是针对提取图片的设置:
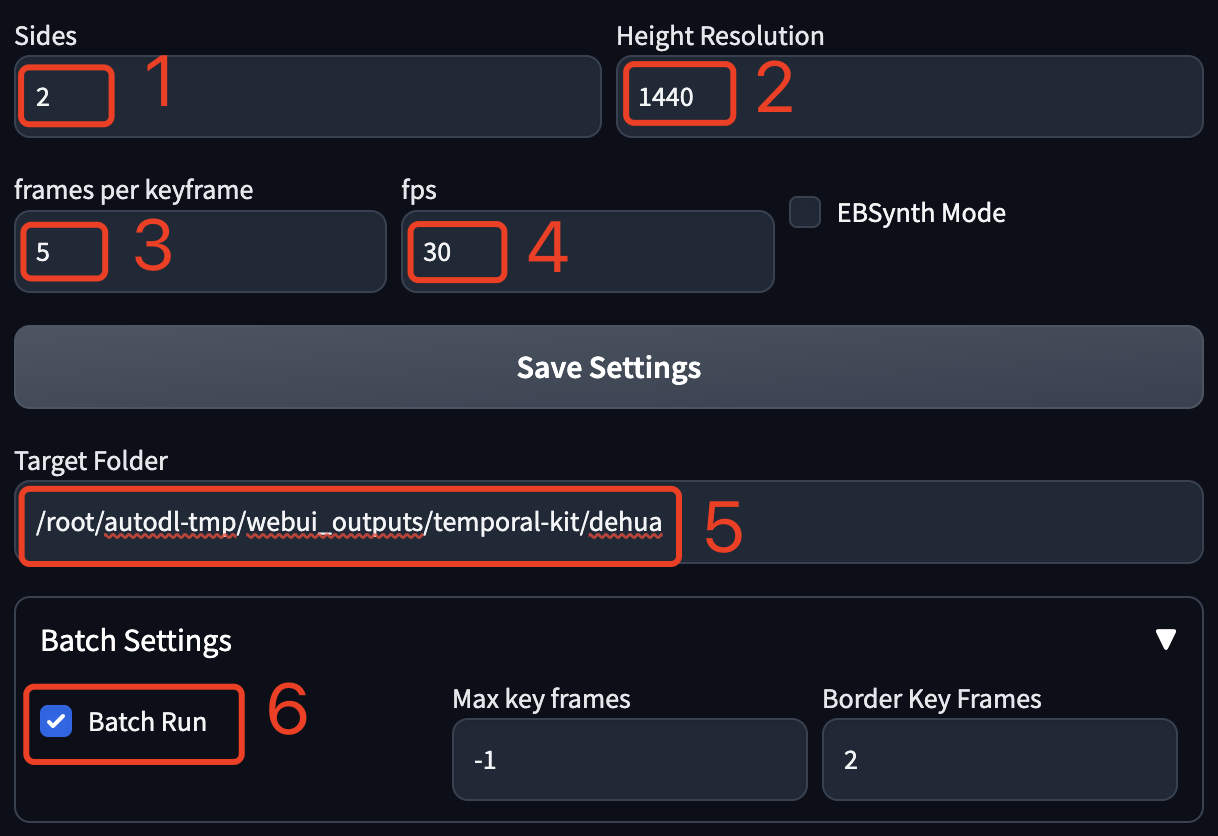
Sides:生成的1张图片的边包含几张视频帧。如果是2就代表4个视频帧,也就是 2*2;如果是3就代表9个视频帧,也就是 3*3;最小设置为1,也就是1张图包含1个视频帧。这个要结合后边的 Height Resolution一起设置。
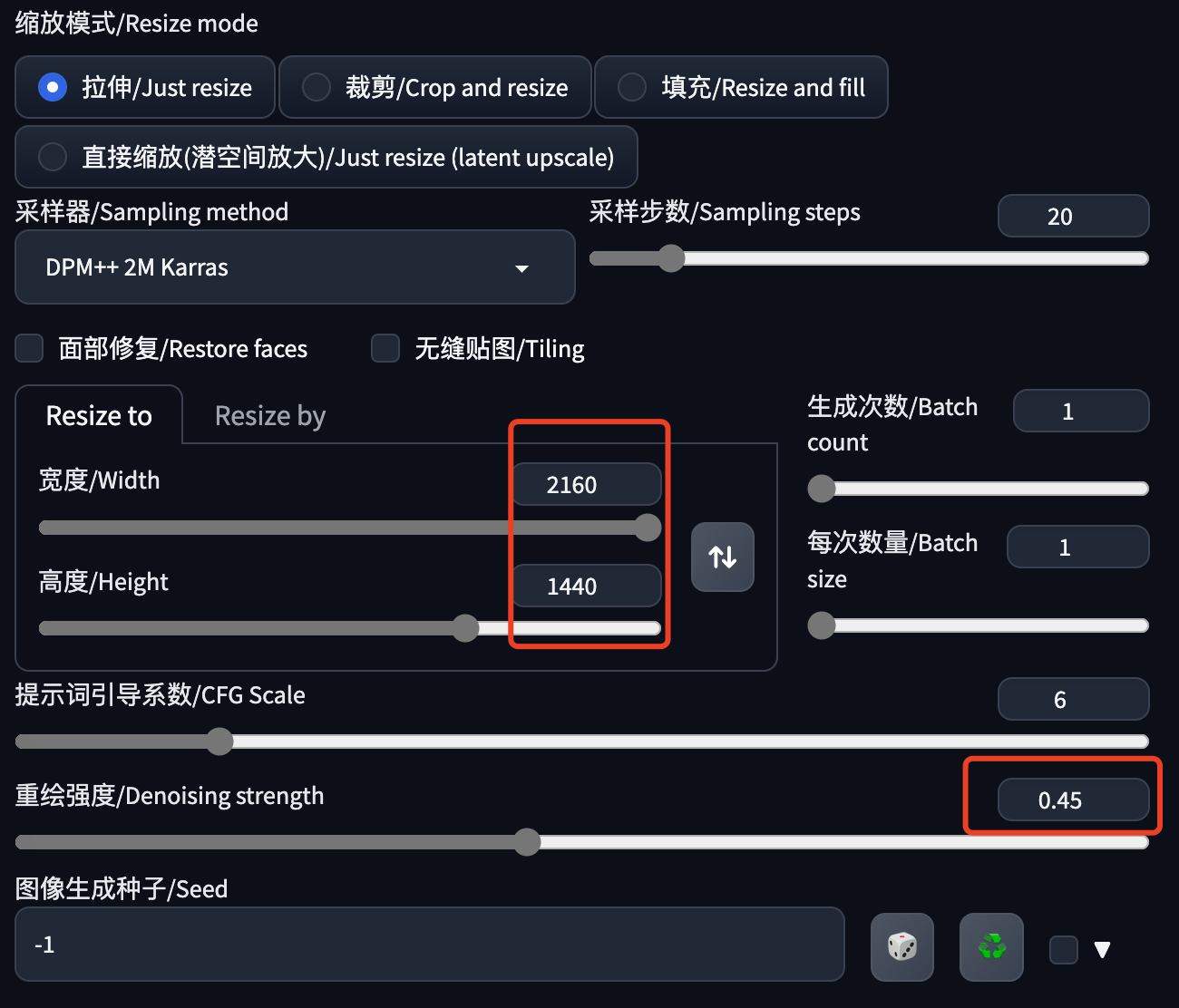
Height Resolution:生成图片的高度的像素值,建议是:视频的高度 * Sides ,比如我这个视频是 1080*720,单个视频帧的高度就是720,但是前边Sides设置的2,所以就是720*2=1440。但是这个公式不是绝对的,你也可以写个720,或者写个2048。这个值需要考虑显卡的性能,如果显卡不太行,不要设置的太高。
frames per keyframe:多少视频帧抽取一个关键帧。
fps:视频每秒包含几帧,在电脑上查看视频详情一般可以获取到。
Target Folder:关键帧图片的输出位置,实际会输出到这个目录下创建的一个input文件夹,后续各种处理的中间文件都在这个文件夹下,相当于一个项目目录,所以建议为每个视频的不同处理创建不同的文件夹。注意如果是云端,这里需要是服务器上的目录。
Batch Settings:因为我们这里需要处理整个视频,所以需要把这个Batch Run勾选上。
参数设置完毕之后,点击页面右侧的“运行”。
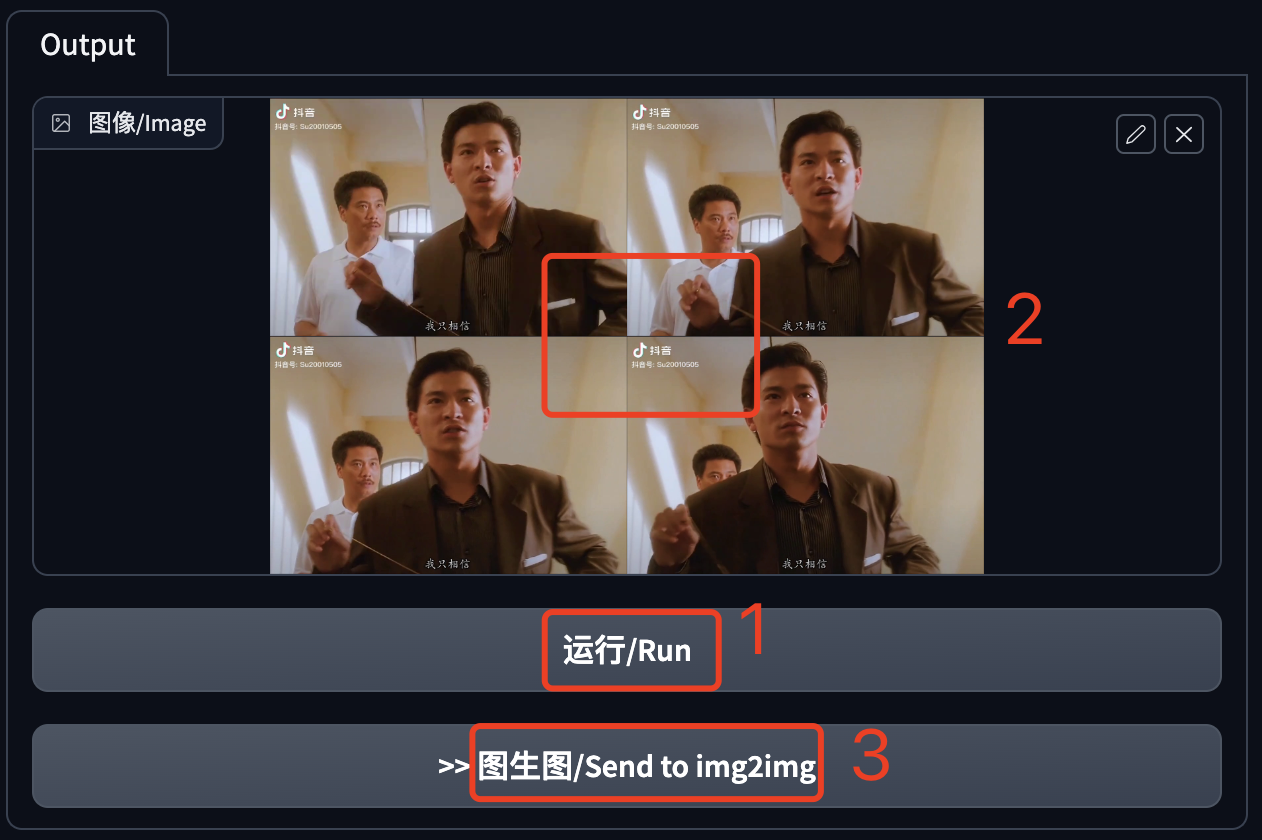
关键帧图片都被提取后,图像这个区域会显示提取的首张图片,我们也可以在文件目录中看到提取的图片。这里以AutoDL的JupyterLab为例。

然后我们就可以点击“图生图”进入下一步了。
转换风格
在上一步点击“图生图”之后,页面就跳转到“图生图”了,并且自动带过来了首张图片。
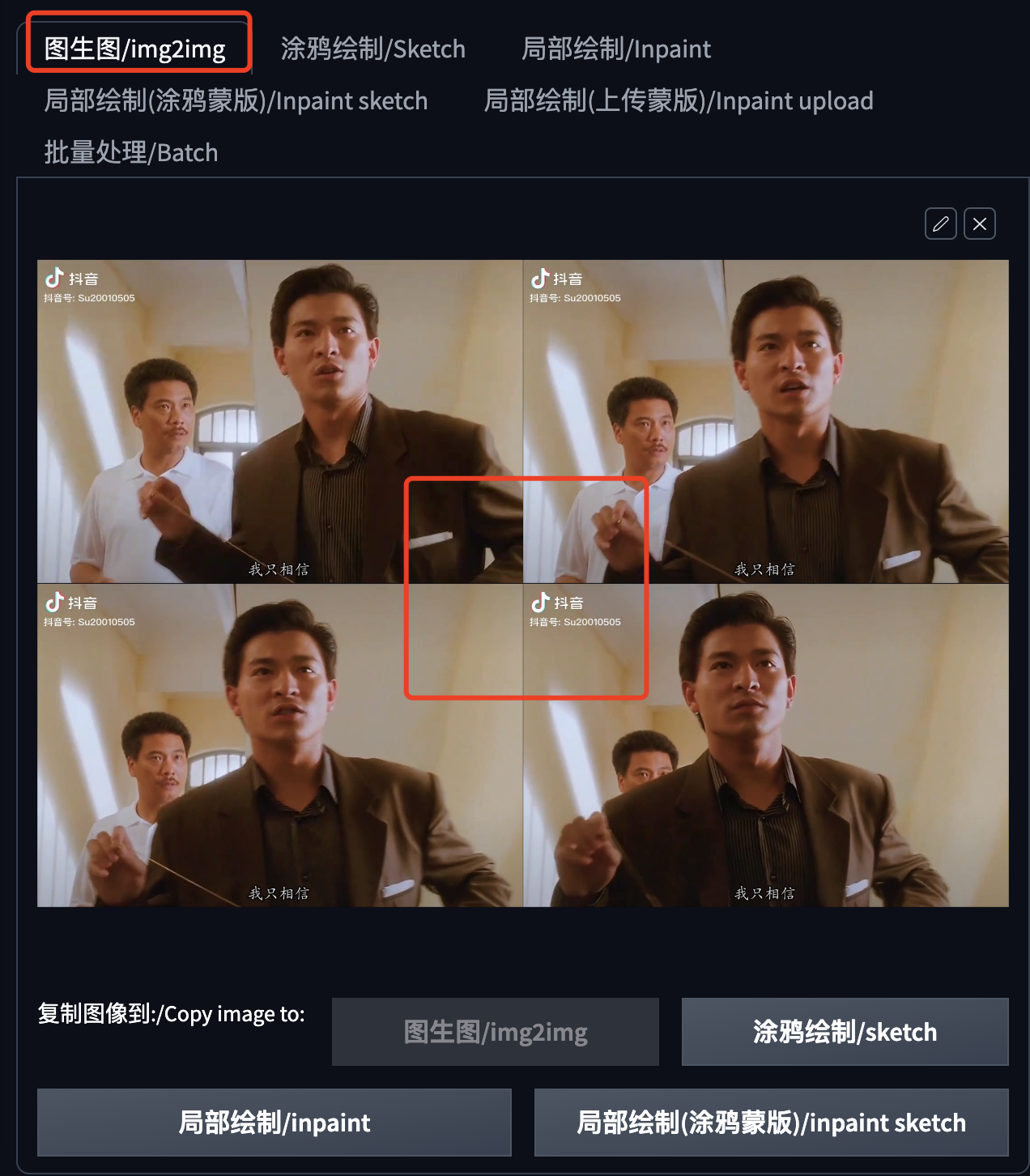
我们需要选择一个模型,填写一些提示词。我这里为了生成水墨画风格,专门加了一个Lora(文章最后会分享我这个Lora的下载地址)。你可以按照自己的需求决定用什么模型和Lora。
这里的贴出来我的提示词,方便复制。
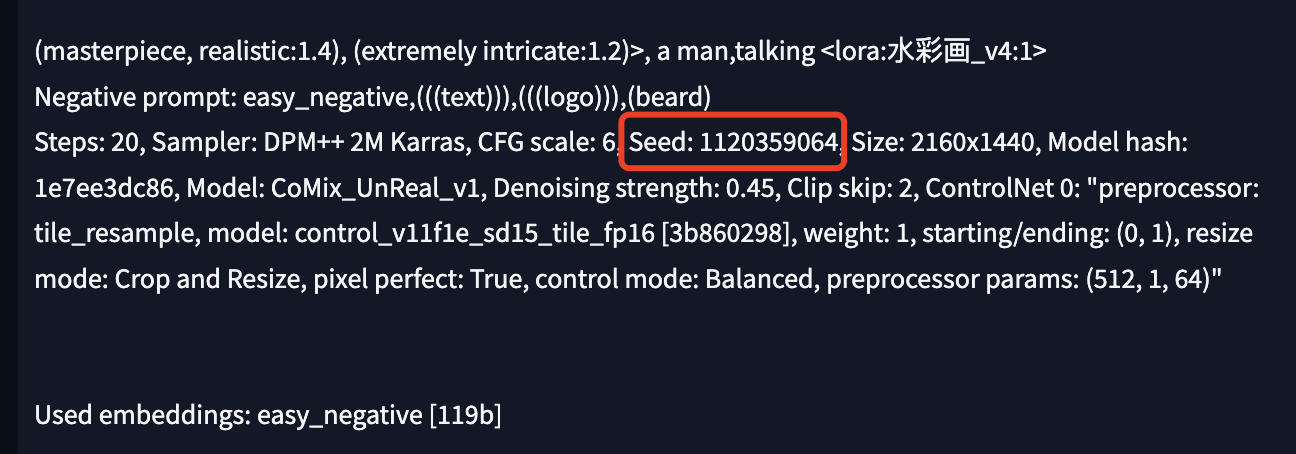
提示词:(masterpiece, realistic:1.4), (extremely intricate:1.2)>, a man,talking <lora:水彩画_v4:1>
反向提示词: easy_negative,(((text))),(((logo))),(beard)

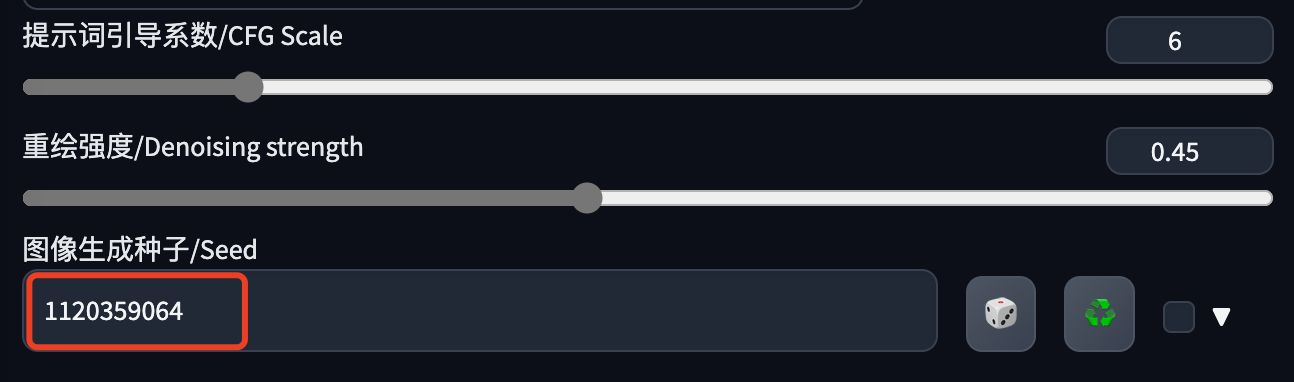
然后是一些参数设置,大家根据实际情况来吧,效果不好就调整下。
注意两点:
- 图片的宽高:这是从提取关键帧的页面带过来的,如果数字太大,建议先调小一点,然后再用超分高清化放大。
- 重绘强度:不要太大,以免重绘的图片相互之间变化太大,不好衔接,出来的视频会比较闪烁。
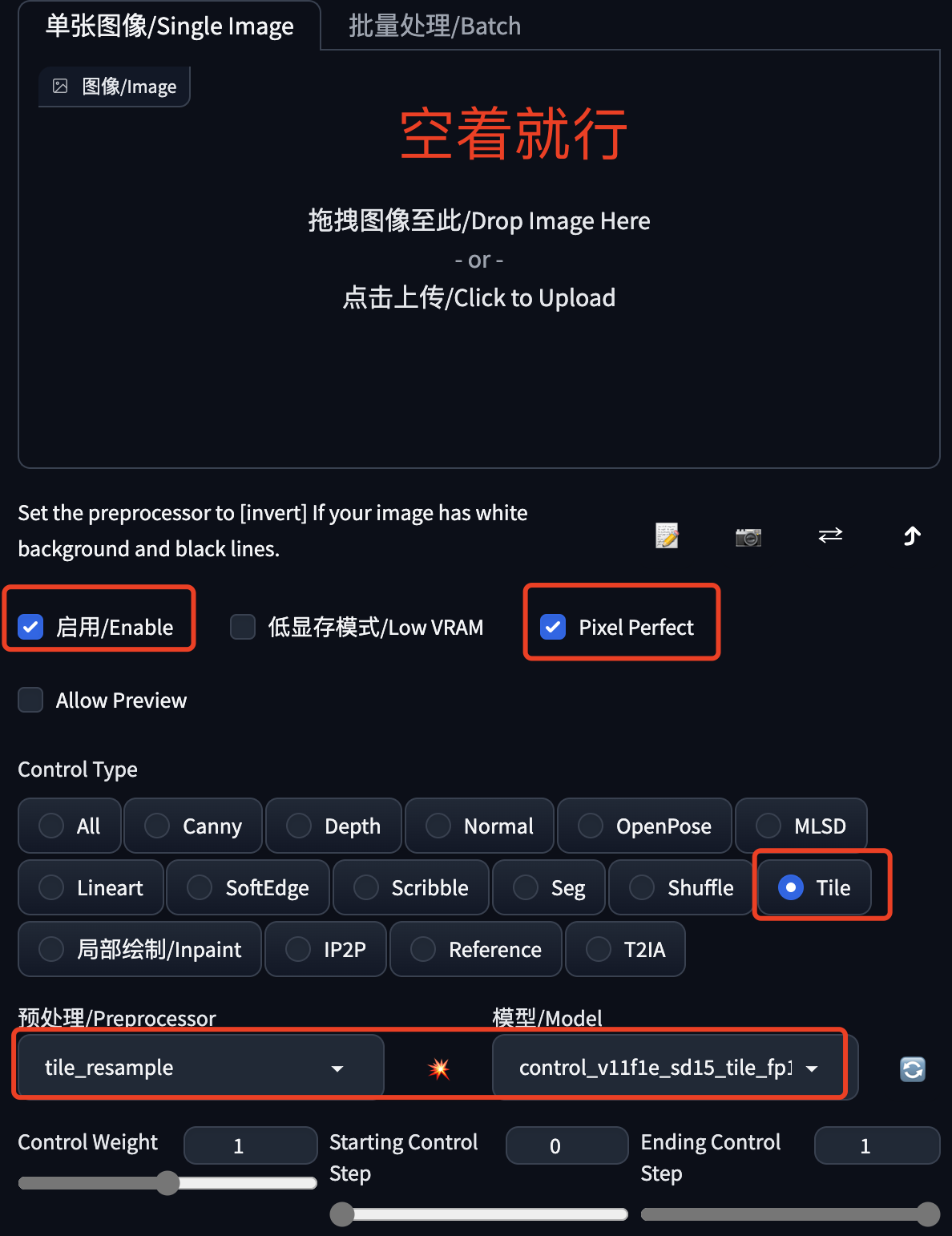
这里一般还需要ControlNet来控一下图,避免重绘的变化太大,也是为了稳定画面。我这里选择的是Tile模型,大家也可以试下SoftEdge、Canny、Lineart等绘线的模型。
然后就是抽卡了,不断的生成图片,直到你满意。
注意记录下满意图片的生成种子,马上就要用到批量生成中。
将图生图切换到“批量处理”,填写两个目录:
- 输入目录:提取关键帧步骤中输出图片的目录。
- 输出目录:重绘图片的保存目录,固定值output,填上就行了。

把满意图片的生成种子填写到这里,网上很多教程提到这个,但是不要期望重绘后的每张图片中的元素都能保持一致,因为视频帧的每张图片都是不一样的,一个种子很难稳定输出图片中的各种元素,大家可以自己体会下。
最后就是点击“生成”按钮,等待批处理完成。
在图片输出区域的下方看到这句话,基本就处理完成了。WebUI的进度有时候更新不及时,大家注意看控制台或者shell的输出。

合成视频
现在进入激动人心的视频合成环节了,这一步需要回到 Temporal-Kit 页面。
批量变换
点击“Batch-Warp”,进入批量变换页面。
在Input Folder中填写完整的项目目录,注意不是 output 目录,也不是 input 目录,是它们的上级目录。
然后点击“read_last_settings”,它会加载源视频和相关参数。注意这里的“output resolution”是需要手动设置的,默认1024,建议改成源视频的分辨率,以保持一致。其它参数使用自动加载的就行了。
最后点击“run”,开启视频合成。

这个视频合成的原理是根据关键帧生成中间的序列帧,然后又拼合起来生成视频,可以在result这个目录中看到中间生成的这些图片。
5秒的视频,AutoDL上的A5000显卡大概需要10分钟左右,合成成功后会在 Batch-Warp 页面的右侧展示视频,可以直接播放,也可以下载。

生成的视频还是有些闪烁和不连贯,我这个视频选择的不是很好。
这里合成的视频默认是没有声音的,我们可以在剪映APP中把原视频的声音合成进来,这里发不了视频,打开网盘看我这个效果:
https://www.aliyundrive.com/s/pMjyYGtkE7x
单张变换
Temporal-Kit还提供了一个“Temporal-Warp”的工具,实测它可以实现单张重绘图片转视频,一个比较短的小视频。
结合EBSynth合成视频
这个步骤也比较多,下一篇专门介绍。

