
热门标签
热门文章
- 1电子电器架构 —— 诊断数据DTC起始篇(上)
- 2美团技术总结:Java中9种常见的CMS GC问题分析与解决
- 3以太坊智能合约balanceof的正确用法_如何获取智能合约中的balanceof
- 4LaMDA: Language Models for Dialog Applications
- 5Docker安装Memcached+Python调用
- 6使用SpringBoot实现增删改查
- 7自动化领域(控制领域)主要期刊汇总整理(SCI和EI)_控制领域sci水刊
- 8浅学一下Redis_redis能否存储null
- 9NLP自然语言处理-Pytorch情感分析简介_pytorch rnn 情感分析
- 10Hadoop HA集群的搭建_nameservice
67108864 指定ha
当前位置: article > 正文
自然语言处理——分词系统(正向最大匹配法)
作者:Cpp五条 | 2024-04-06 22:54:31
赞
踩
正向最大匹配
算法分析
正向最大匹配法,对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。正向最大匹配法是基于词典的分词方法,其分词原理是:单词的颗粒度越大,所能表示的含义越确切。该算法主要分两个步骤:
该算法主要分为两个步骤:
1、一般从一个字符串的开始位置,选择一个最大长度的词长的
片段,如果序列不足最大词长,则选择全部序列。
2、首先看该片段是否在词典中,如果是,则算为一个分出来的词,如果不是,则从右边开始,减少一个字符,然后看短一点的这个片段是否在词典中,依次循环,逐到只剩下一个字。
3、序列变为第2步骤截取分词后,剩下的部分序列
接下来通过一个实力给大家讲解具体操作。
形象化演示
首先我们需要选取一个最大的截取长度,通常我们选取词典中单个分词的最大长度,在如下案例中,最长的分词为(中国人)长度为三,那我们每次就取三个字符来进行分词

从左侧开始选中前三个字符进入带分序列

判断此时该序列是否存在于给定的词典中。很遗憾“我是中”不在词典中,那么从右侧开始将最后一个字符从待分序列中删去

很遗憾,“我是”依然不在分词词典中,继续从右侧删去字符

如上图所示,若待分序列的长度为1,则判定为单个词,将其存入已分列表中,并从待分序列中删除,在剩余的序列中重新组建待分序列,继续下一轮分词

经过几轮循环,所有待分序列长度为零,得到了一个分词结果,如下图所示

代码实现
dict.txt文件(在这里只是展示了简单版的词典,可以自己制作任意词组或者从网站下载)
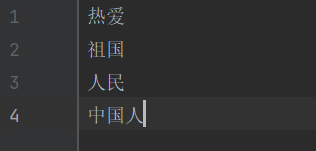
#创建字典列表 dic = [] def init(): """ 读取词典文件 载入词典 :return: """ with open("dict.txt", encoding="utf8") as dic_input: for word in dic_input: dic.append(word.strip()) #实现正向最大匹配法 def cut_words(raw_sentence, word_dic): #统计词典种最长的词(若小于待切分总长度,则每次从未匹配处找这么长的字符串开始匹配) max_length = max(len(word) for word in dic) sentence = raw_sentence.strip() #移除字符串内的空格 #统计序列长度 words_length = len(sentence) #存储切分好的词语 cut_word = [] while words_length > 0: max_cut_length = min(max_length, words_length) #创建待分序列sub sub = sentence[0 : max_cut_length] #进行一轮分词,在左侧切出一个词 while max_cut_length > 0: if sub in dic: #若待切分的词在词典中,则将其加入已分列表,跳出循环 cut_word.append(sub) break elif max_cut_length == 1: #剩下单个字,将其切分,并跳出循环 cut_word.append(sub) break else: #都不符合则从右侧去掉一个词,重新分词 max_cut_length = max_cut_length - 1 sub = sub[0 : max_cut_length] #将切掉的单词删去 sentence = sentence[max_cut_length:] words_length = words_length - max_cut_length words = "/".join(cut_word) return words def main(): """ 于用户交互接口 :return: """ init() while True: print("请输入您要分词的序列") input_str = input() if not input_str: break result = cut_words(input_str, dic) print("分词结果:") print(result) if __name__ == '__main__': main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
效果展示
输入序列:我是中国人,我热爱我的祖国
分词结果:我/是/中国人/,/我/热爱/我/的/祖国/和/人民

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/374842
推荐阅读
相关标签

