
- 1仿百度文库方案[openoffice.org 3+swftools+flexpaper](七) 之 使用iText将jpg、jpeg、png转换为pdf...
- 2第八讲_ArkTS装饰器(五)_arkts 装饰器
- 3深度学习新星:GAN的基本原理、应用和走向_fsrcnn和gan
- 4docker小白采坑---启动失败---空间不足
- 5【使用 BERT 的问答系统】第 5 章 :BERT模型应用:问答系统_faq问答系统bert模型
- 6区块链达摩院落地 国研政情·经信研究:夜总会走出来阿里先锋
- 7【STM32学习笔记】(5)—— STM32工程添加源文件和头文件_stm32怎么添加头文件
- 8高效实用|ChatGPT指令/提示词/prompt/AI指令大全,基础版_让chatgpt修改文章的prompt
- 9MATLAB 自定义均值滤波 (53)
- 10西南科技大学数字电子技术实验二(SSI逻辑器件设计组合逻辑电路及FPGA实现 )FPGA部分_ssi组合逻辑电路实验
redis实现消息队列的两种方式_redis做私信队列
赞
踩
目前在redis想要实现消息队列的功能有如下的两种方案:
- 1:基于List的lpush和rpop
- 2:Streams
这里不将pub/sub考虑在内,因为其不具备持久化的能力,消息会丢失。
其中1是利用其有的先进先出特性实现,2是redis为了实现消息队列专门在redis5版本中定义的一种新的数据结构,这里注意,其也是一种数据结构,和String,Set等处于同等位置的数据结构,只不过内部增加了一些针对消息队列的一些特有操作来实现消息队列的功能,后续我们会详细分析其用法。
1:消息队列需要满足哪些要求
消息保序
即要保证消息发送的顺序和消费的顺序是一致的,不一致的话可能会导致业务上的错误。
重复消息处理
消息的重复处理,准确来说是应该通过消费者自身来实现的,在应用程序内部实现这些逻辑,但是对于消息中间件来说也要有此类机制,即对于一个已经被消费的消息(已经收到ACK)不能再次被消费。
消息可靠性
换句话说,要具有持久化的能力,避免消息丢失,这样当消费者异常宕机导致再次重启后需要重新消费消息时可以再次获取。
接下来我们先来看下使用List如何实现消息队列。
2:List实现消息队列
生产消息我们可以使用lpush,消费消息可以使用rpop,如下图生产和消费消息的过程:
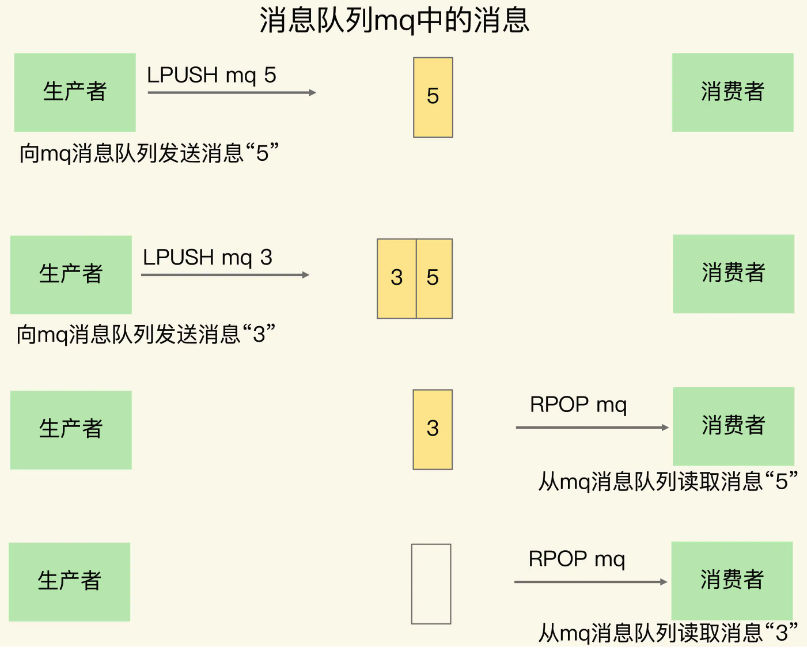
但是注意,这里我们使用rpop消费消息时,如果没有消息则会直接返回, 且有新消息时也不会通知,此时就需要通过诸如while(true),for(;;)之类的死循环来不断查询,这样就会不断的消耗CPU资源,造成不必要的CPU资源浪费,为了解决这个问题,redis提供了rpop阻塞版本命令brpop,其中bblock就代表了阻塞的特性,当有消息可以消费时,这样就解决了浪费CPU资源的问题。
到这里,对于消息中间件的3个需求,List都满足哪些呢?首先第一个消息保序,是天然支持的,对于重复消息处理List本身是不支持的,但是我们在前面也分析了,这准确来说更应该是消费者本身来实现的,因此,生产者在生产消息时只要给每一个消息一个唯一的标识,然后消费者通过此来避免消息重复处理就可以了,比如LPUSH mq "101030001:stock:5",其中的101030001就是其唯一标识。最后是消息可靠性,为了满足消息可靠性,redis进一步对rpop进行了增强,提供了BRPOPLPUSH命令,消息弹出后,会重新压到一个新的队列中,这样当消费者异常重启后就可以从这里重新消费消息了,如下图:
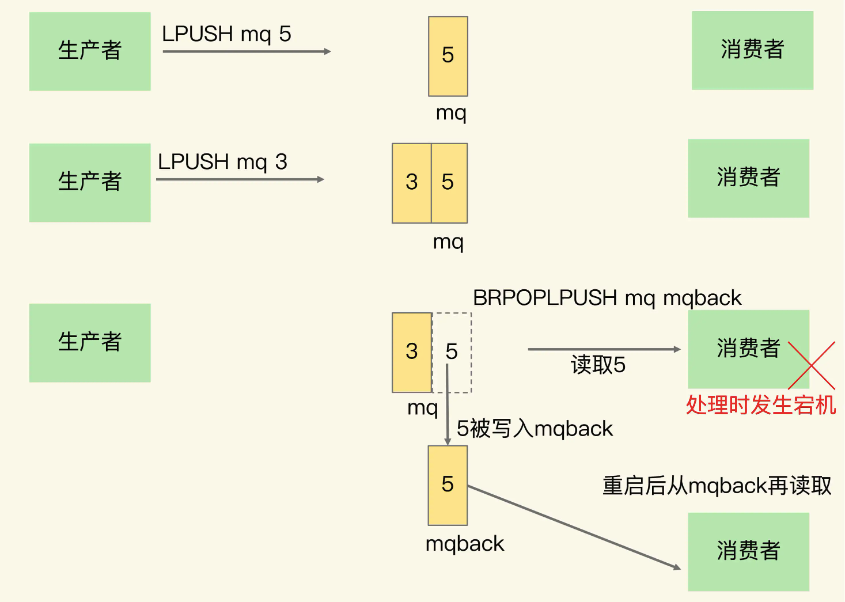
到这里,List在一定程序上都满足了消息中间件需要满足的3个条件,这里还需要考虑另外一种情况,即当消费者的消费能力严重不足,或者是生产者生产的消息量非常大,即生产能力远大于消费能力的时候List就没有什么办法了,因为其只能一个一个的弹出消息,对于这个问题就需要依靠redis专门针对消息队列的场景实现的新数据结构Streams,注意这也是一种新的数据结构。
3:Streams
我们前面说了,Streams是一种redis专门为消息队列定义的一种数据结构,所以自然的我们是先要看如何定义这种数据结构了,和其它的数据结构一样,我们不需要显式的创建,在执行第一次数据添加的时候自动创建,添加数据的命令是XADD,语法格式是XADD key ID field value [field value ...],参数说明如下:
- key:redis的key
- ID:消息的唯一标识,可以指定,也可以设置为*,设置为*时id会自动生成,id是递增
- field value:消息的字段和值
如下生产(创建)若干条消息:

其中XLEN用来查看消息的个数,XRANGE用来通过范围查询基于递增ID获取消息,-相当于是负无穷,+相当于是正无穷,即获取所有消息。我们接着再来看下其它一些命令。
3.1:XDEL
根据ID删除消息,如下测试:
3.2:XLEN
获取消息的数量,语法格式xlen key,如下:
- redis> XADD mystream * item 1
- "1601372563177-0"
- redis> XADD mystream * item 2
- "1601372563178-0"
- redis> XADD mystream * item 3
- "1601372563178-1"
- redis> XLEN mystream
- (integer) 3
- redis>
- 123456789
3.3:XRANGE
查询指定范围的消息,语法格式XRANGE key start end [COUNT count],解释如下:
- key :队列名
- start :开始值, - 表示最小值
- end :结束值, + 表示最大值
- count :数量
- 1234
测试如下:
3.4:XREVRANGE
从后往前获取消息,语法格式XREVRANGE key end start [COUNT count],解释如下:
- key :队列名
- end :结束值, + 表示最大值
- start :开始值, - 表示最小值
- count :数量
- 1234
实例如下:
3.5:XREAD
以阻塞或者是非阻塞的方式获取消息,即消费消息的命令,语法格式XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...],解释如下:
- count :数量
- milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
- key :队列名
- id :消息 ID
- 1234
测试如下:
3.6:XGROUP CREATE
创建消费者组,使用消费者可以对消息进行并发的消费,解决消费者消费能力不足的问题,语法格式为XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername],解释如下:
- key :队列名称,如果不存在就创建
- groupname :组名。
- $ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
如下从头开始消费:
XGROUP CREATE mystream consumer-group-name 0-0 如下从尾部开始消费:
XGROUP CREATE mystream consumer-group-name $在实际的场景中我们可以通过设置多个消费者组的不同开始消费的位置来实现并发消费的效果,此时可能如下图:
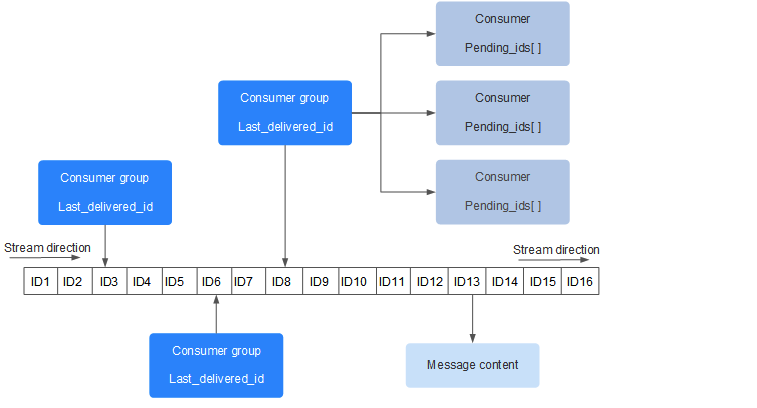
图中主要元素解释如下:
- 每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
3.7:XREADGROUP GROUP
读取消费者组中的消息,语法格式如下:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]解释如下:
- group :消费组名
- consumer :消费者名。
- count : 读取数量。
- milliseconds : 阻塞毫秒数。
- key : 队列名。
- ID : 消息 ID。
- 123456
如下测试:
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >符号>标识从第一条尚未被消费的消息开始消费。
-
- XADD mystream * name Sara surname OConnor
-
-
-
- XGROUP CREATE mystream consumer-group-name 0-0
-
-
-
- XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >
写在后面
参考文章列表:

