
- 1Multi Query Attention和 Group Query Attention的介绍和原理
- 2python中sort()函数的详细使用方法_python sort
- 3第十三届蓝桥杯省赛JavaB组真题(Java题解解析)_13届蓝桥杯java组
- 4el-table 列的动态显示与隐藏_el-table-column隐藏
- 5vscode中用node的终端安装模块
- 6文心一言插件开发(第二篇_基于文心一言的模块功能进行二次开发 csdn
- 7使用git pull文件时和本地文件冲突时…(Please commit your changes or stash them before you merge.)_git pull 放弃本地修改
- 8AutoGPT使用教程_autogpt怎么用
- 9基于Tensorflow2.0的简单人脸识别实验_用keras, tensorflow2.0以上版本做个人脸识别
- 10Flask -- (16)Flask中的上下文及实现原理_flask request 上下文 原理
YOLOv8算法改进【NO.93】使用resnet18网络作为主干特征提取网络_yolov8与resnet进行集成
赞
踩
前 言
YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通:第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很值得写,不算是堆积木那种,也可以说是一种新的算法,所以做实验的话建议朋友们优先尝试这种改法。
第二,创新特征融合网络,这个同理第一,比如将原yolo算法PANet结构改进为Bifpn等。
第三,改进主干特征提取网络,就是类似加个注意力机制等。根据个人实验情况来说,这种改进有时候很难有较大的检测效果的提升,乱加反而降低了特征提取能力导致mAP下降,需要有技巧的添加。
第四,改进特征融合网络,理由、方法等同上。
第五,改进检测头,更换检测头这种也算个大的改进点。
第六,改进损失函数,nms、框等,要是有提升检测效果的话,算是一个小的改进点,也可以凑字数。
第七,对图像输入做改进,改进数据增强方法等。
第八,剪枝以及蒸馏等,这种用于特定的任务,比如轻量化检测等,但是这种会带来精度的下降。
...........未完待续
一、创新改进思路或解决的问题
将Backbone网络改为传统的resnet18等timm支持的网络,作为创新改进思路。
二、基本原理
原文链接:
代码链接:https://github.com/StevenLauHKHK/Large-Separable-Kernel-Attention/blob/main/mmsegmentation/van.py
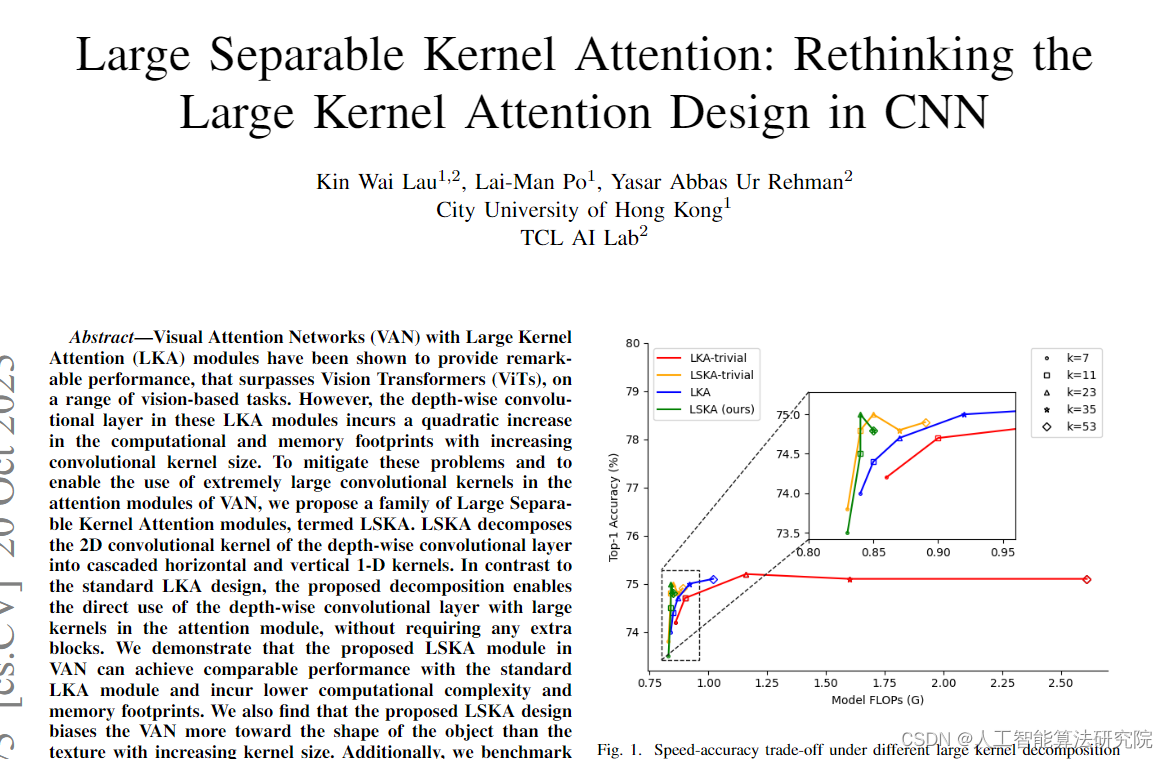 摘要:具有大内核注意力(LKA)模块的视觉注意力网络(VAN)已被证明在一系列基于视觉的任务中提供了超过视觉转换器(ViTs)的可注释性能。然而,随着卷积核大小的增加,这些LKA模块中的深度卷积层导致计算和内存占用的二次增加。为了缓解这些问题,并使超大卷积核能够在VAN的注意力模块中使用,我们提出了一系列大的可分离核注意力模块,称为LSKA。LSKA将深度卷积层的2D卷积核分解为级联的水平和垂直一维核。与标准LKA设计相比,所提出的分解能够在注意力模块中直接使用具有大内核的深度卷积层,而不需要任何额外的块。我们证明了所提出的VAN中的LSKA模块可以实现与标准LKA模块相当的性能,并降低计算复杂度和内存占用。我们还发现,随着内核大小的增加,所提出的LSKA设计使VAN更倾向于对象的形状,而不是纹理。此外,我们在ImageNet数据集的五个损坏版本上对VAN、ViTs和最近的ConvNeXt中的LKA和LSKA的稳健性进行了基准测试,这些版本在以前的工作中基本上未被探索。我们广泛的实验结果表明,随着内核大小的增加,VAN中提出的LSKA模块显著降低了计算复杂度和内存占用,同时在对象识别、对象检测、语义分割和鲁棒性测试方面优于ViTs、ConvNeXt,并提供了与VAN中LKA模块类似的性能。
摘要:具有大内核注意力(LKA)模块的视觉注意力网络(VAN)已被证明在一系列基于视觉的任务中提供了超过视觉转换器(ViTs)的可注释性能。然而,随着卷积核大小的增加,这些LKA模块中的深度卷积层导致计算和内存占用的二次增加。为了缓解这些问题,并使超大卷积核能够在VAN的注意力模块中使用,我们提出了一系列大的可分离核注意力模块,称为LSKA。LSKA将深度卷积层的2D卷积核分解为级联的水平和垂直一维核。与标准LKA设计相比,所提出的分解能够在注意力模块中直接使用具有大内核的深度卷积层,而不需要任何额外的块。我们证明了所提出的VAN中的LSKA模块可以实现与标准LKA模块相当的性能,并降低计算复杂度和内存占用。我们还发现,随着内核大小的增加,所提出的LSKA设计使VAN更倾向于对象的形状,而不是纹理。此外,我们在ImageNet数据集的五个损坏版本上对VAN、ViTs和最近的ConvNeXt中的LKA和LSKA的稳健性进行了基准测试,这些版本在以前的工作中基本上未被探索。我们广泛的实验结果表明,随着内核大小的增加,VAN中提出的LSKA模块显著降低了计算复杂度和内存占用,同时在对象识别、对象检测、语义分割和鲁棒性测试方面优于ViTs、ConvNeXt,并提供了与VAN中LKA模块类似的性能。
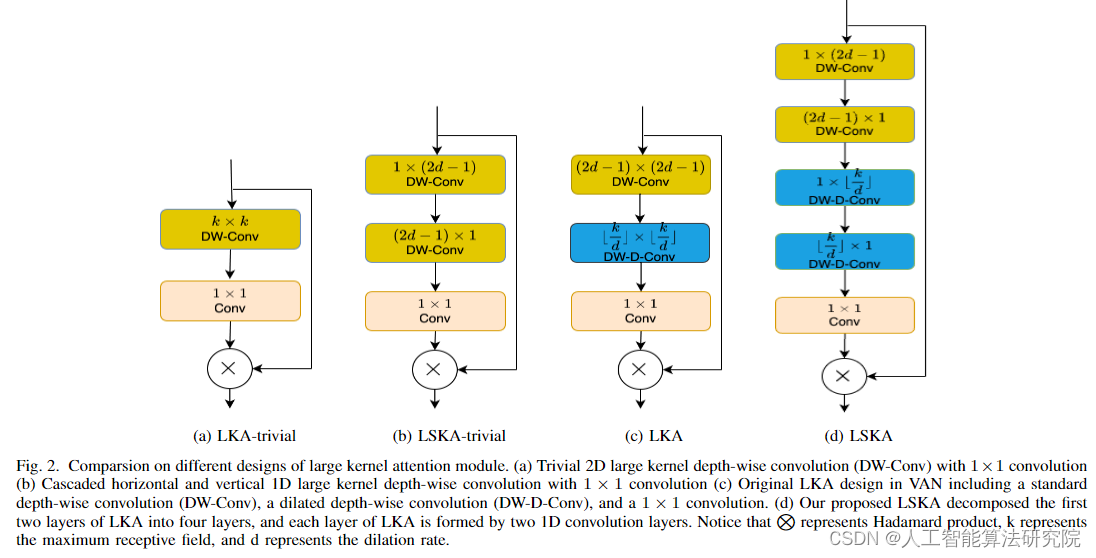
三、添加方法
部分代码如下所示,详细改进代码可私信我获取。
- # Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/413938推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

