
热门标签
热门文章
- 1手把手教你学Python之常见运算符_python 中判断两个数相除为整数和小数
- 2用STM32自制APM四轴飞行器_stm32f103rct6无人机飞控
- 3【免费题库】华为OD机试 - 单词重量(Java & JS & Python & C & C++)
- 4网络安全渗透测试工具AWVS14.6.2的安装与使用(激活)_awvs生成报告
- 5pycharm使用Anaconda中的虚拟环境【我的入门困惑二】_pycharm创建的anaconda虚拟环境,如何进入虚拟环境
- 6winform GridControl 总结
- 7神经网络BP反向传播算法Error Backpropagation_神经网络反向传播算法论文原文
- 8OpenHarmony应用编译 - 如何在源码中编译复杂应用(4.0-Release)
- 9php 用webhook实现git同步服务器代码 2022.8.18_webhook php
- 10hadoop spark jupyterbook 打开过程_hadoop jupyter
当前位置: article > 正文
NLP中数据增强的综述,快速的生成大量的训练数据_nlp的训练模型如何累加数据
作者:Cpp五条 | 2024-04-19 02:02:33
赞
踩
nlp的训练模型如何累加数据
深度学习视觉领域的增强方法可以很大程度上提高模型的表现,并减少数据的依赖,而NLP上做数据增强不像在图像上那么方便,但还是有一些方法的。
与计算机视觉中使用图像进行数据增强不同,NLP中文本数据增强是非常罕见的。这是因为图像的一些简单操作,如将图像旋转或将其转换为灰度,并不会改变其语义。语义不变变换的存在使增强成为计算机视觉研究中的一个重要工具。
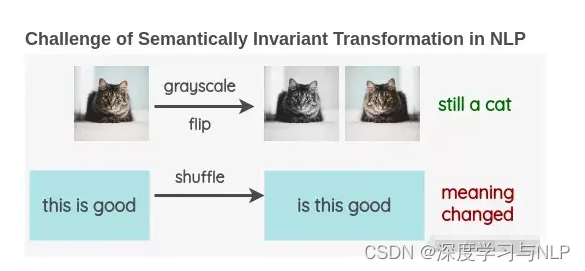
我很好奇是否有人尝试开发NLP的增强技术,并研究了现有的文献。在这篇文章中,我将分享我对当前用于增加文本数据的方法的发现。
方法
1. 词汇替换
这种方法试图在不改变句子主旨的情况下替换文本中的单词。
- 基于词典的替换在这种技术中,我们从句子中随机取出一个单词,并使用同义词词典将其替换为同义词。例如,我们可以使用WordNet的英语词汇数据库来查找同义词,然后执行替换。它是一个手动管理的数据库,其中包含单词之间的关系。
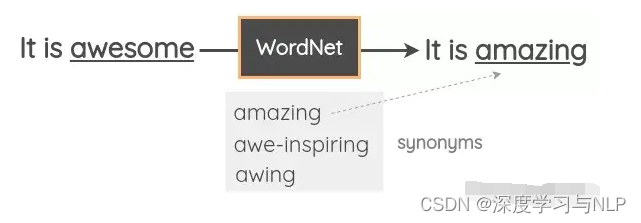
- Zhang et al.在其2015年的论文“Character-level Convolutional Networks for Text Classification”中使用了这一技术。Mueller et al.使用了类似的策略来为他们的句子相似模型生成了额外的10K训练样本。NLTK提供了对WordNet的编程接口。你还可以使用TextBlob API。还有一个名为PPDB的数据库,其中包含数百万条词的解释,你可以通过编程的方式下载和访问它们。
- 基于词向量的替换在这种方法中,我们采用预先训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec,并使用嵌入空间中最近的相邻单词替换句子中的某些单词。Jiao et al.在他们的论文“TinyBert”中使用了这种技术,以提高他们的语言模型在下游任务上的泛化能力。Wang et al.使用它来增加学习主题模型所需的tweet。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/449368
推荐阅读
相关标签

