
- 1C++使用namespace解决命名冲突_using namespace解决重名问题
- 2idea项目提交到github 怎么去除.idea文件和target文件_gitlab怎么设置不把target和.idea文件上传
- 33万字细说数据仓库体系(建议收藏)
- 4ERROR: KeeperErrorCode = NoNode for /hbase/master 问题
- 5stable-diffusion-webui手动安装详细步骤(AMD显卡)_stable-diffusion-webui-directml
- 6python基础篇-for循环_python for循环
- 7RTSP/Onvif视频安防监控平台EasyNVR调用接口返回匿名用户名和密码的原因排查
- 8springboot高校大学生学科竞赛管理系统的设计与实现 计算机毕设源码53135_学科竞赛管理系统 的设计与实现
- 9蓝桥杯上岸考点清单 (冲刺版)!!!_蓝桥杯考前冲刺
- 10【darknet-yolo系列】在colab上训练yolo模型(详细操作流程)_在colab中训练好的模型放在哪里
YOLOv9改进策略 | 细节创新篇 | 迭代注意力特征融合AFF机制创新RepNCSPELAN4_注意力aff
赞
踩
一、本文介绍
本文给大家带来的改进机制是AFF(迭代注意力特征融合),其主要思想是通过改善特征融合过程来提高检测精度。传统的特征融合方法如加法或串联简单,未考虑到特定对象的融合适用性。iAFF通过引入多尺度通道注意力模块(我个人觉得这个改进机制就算融合了注意力机制的求和操作),更好地整合不同尺度和语义不一致的特征。该方法属于细节上的改进,并不影响任何其它的模块,非常适合大家进行融合改进,单独使用也是有一定的涨点效果。欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
推荐指数:⭐⭐⭐⭐
涨点效果:⭐⭐⭐⭐
目录
二、AFF的基本框架原理

官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转

iAFF的主要思想在于通过更精细的注意力机制来改善特征融合,从而增强卷积神经网络。它不仅处理了由于尺度和语义不一致而引起的特征融合问题,还引入了多尺度通道注意力模块,提供了一种统一且通用的特征融合方案。此外,iAFF通过迭代注意力特征融合来解决特征图初始整合可能成为的瓶颈。这种方法使得模型即使在层数或参数较少的情况下,也能取得到较好的效果。
iAFF的创新点主要包括:
1. 注意力特征融合:提出了一种新的特征融合方式,利用注意力机制来改善传统的简单特征融合方法(如加和或串联)。
2. 多尺度通道注意力模块:解决了在不同尺度上融合特征时出现的问题,特别是语义和尺度不一致的特征融合问题。
3. 迭代注意力特征融合(iAFF):通过迭代地应用注意力机制来改善特征图的初步整合,克服了初步整合可能成为性能瓶颈的问题。

这张图片是关于所提出的AFF(注意力特征融合)和iAFF(迭代注意力特征融合)的示意图。图中展示了两种结构:
(a) AFF: 展示了一个通过多尺度通道注意力模块(MS-CAM)来融合不同特征的基本框架。特征图X和Y通过MS-CAM和其他操作融合,产生输出Z。
(b) iAFF: 与AFF类似,但添加了迭代结构。在这里,输出Z回馈到输入,与X和Y一起再次经过MS-CAM和融合操作,以进一步细化特征融合过程。
(这两种方法都是文章中提出的我仅使用了iAFF也就是更复杂的版本,大家对于AFF有兴趣的可以按照我的该法进行相似添加即可)
三、AFF的核心代码
该代码的使用方式需要两个图片,有人去用其替换Concat操作,但是它的两个输入必须是相同shape,但是YOLOv9中我们Concat一般两个输入在图像宽高上都不一样,所以我用其替换Bottlenekc中的残差相加操作,算是一种比较细节上的创新。
- import torch
- import torch.nn as nn
- import numpy as np
-
- __all__ = ['RepNCSPELAN4_AFF']
-
- class AFF(nn.Module):
- '''
- 多特征融合 AFF
- '''
-
- def __init__(self, channels=64, r=2):
- super(AFF, self).__init__()
- inter_channels = int(channels // r)
-
- self.local_att = nn.Sequential(
- nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
- nn.BatchNorm2d(inter_channels),
- nn.ReLU(inplace=True),
- nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
- nn.BatchNorm2d(channels),
- )
-
- self.global_att = nn.Sequential(
- nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
- nn.BatchNorm2d(inter_channels),
- nn.ReLU(inplace=True),
- nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
- nn.BatchNorm2d(channels),
- )
-
- self.sigmoid = nn.Sigmoid()
-
- def forward(self, x, residual):
- xa = x + residual
- xl = self.local_att(xa)
- xg = self.global_att(xa)
- xlg = xl + xg
- wei = self.sigmoid(xlg)
-
- xo = 2 * x * wei + 2 * residual * (1 - wei)
- return xo
-
-
- class RepConvN(nn.Module):
- """RepConv is a basic rep-style block, including training and deploy status
- This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
- """
- default_act = nn.SiLU() # default activation
-
- def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
- super().__init__()
- assert k == 3 and p == 1
- self.g = g
- self.c1 = c1
- self.c2 = c2
- self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
-
- self.bn = None
- self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
- self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
-
- def forward_fuse(self, x):
- """Forward process"""
- return self.act(self.conv(x))
-
- def forward(self, x):
- """Forward process"""
- id_out = 0 if self.bn is None else self.bn(x)
- return self.act(self.conv1(x) + self.conv2(x) + id_out)
-
- def get_equivalent_kernel_bias(self):
- kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
- kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
- kernelid, biasid = self._fuse_bn_tensor(self.bn)
- return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
-
- def _avg_to_3x3_tensor(self, avgp):
- channels = self.c1
- groups = self.g
- kernel_size = avgp.kernel_size
- input_dim = channels // groups
- k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
- k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
- return k
-
- def _pad_1x1_to_3x3_tensor(self, kernel1x1):
- if kernel1x1 is None:
- return 0
- else:
- return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
-
- def _fuse_bn_tensor(self, branch):
- if branch is None:
- return 0, 0
- if isinstance(branch, Conv):
- kernel = branch.conv.weight
- running_mean = branch.bn.running_mean
- running_var = branch.bn.running_var
- gamma = branch.bn.weight
- beta = branch.bn.bias
- eps = branch.bn.eps
- elif isinstance(branch, nn.BatchNorm2d):
- if not hasattr(self, 'id_tensor'):
- input_dim = self.c1 // self.g
- kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
- for i in range(self.c1):
- kernel_value[i, i % input_dim, 1, 1] = 1
- self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
- kernel = self.id_tensor
- running_mean = branch.running_mean
- running_var = branch.running_var
- gamma = branch.weight
- beta = branch.bias
- eps = branch.eps
- std = (running_var + eps).sqrt()
- t = (gamma / std).reshape(-1, 1, 1, 1)
- return kernel * t, beta - running_mean * gamma / std
-
- def fuse_convs(self):
- if hasattr(self, 'conv'):
- return
- kernel, bias = self.get_equivalent_kernel_bias()
- self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
- out_channels=self.conv1.conv.out_channels,
- kernel_size=self.conv1.conv.kernel_size,
- stride=self.conv1.conv.stride,
- padding=self.conv1.conv.padding,
- dilation=self.conv1.conv.dilation,
- groups=self.conv1.conv.groups,
- bias=True).requires_grad_(False)
- self.conv.weight.data = kernel
- self.conv.bias.data = bias
- for para in self.parameters():
- para.detach_()
- self.__delattr__('conv1')
- self.__delattr__('conv2')
- if hasattr(self, 'nm'):
- self.__delattr__('nm')
- if hasattr(self, 'bn'):
- self.__delattr__('bn')
- if hasattr(self, 'id_tensor'):
- self.__delattr__('id_tensor')
-
- def autopad(k, p=None, d=1): # kernel, padding, dilation
- # Pad to 'same' shape outputs
- if d > 1:
- k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
- if p is None:
- p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
- return p
-
-
- class Conv(nn.Module):
- # Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
- default_act = nn.SiLU() # default activation
-
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
- super().__init__()
- self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
- self.bn = nn.BatchNorm2d(c2)
- self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
-
- def forward(self, x):
- return self.act(self.bn(self.conv(x)))
-
- def forward_fuse(self, x):
- return self.act(self.conv(x))
-
-
- class RepNBottleneck_AFF(nn.Module):
- # Standard bottleneck
- def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = RepConvN(c1, c_, k[0], 1)
- self.cv2 = Conv(c_, c2, k[1], 1, g=g)
- self.add = shortcut and c1 == c2
- self.AFF = AFF(c2)
- def forward(self, x):
- if self.add:
- results = self.AFF(x, self.cv2(self.cv1(x)))
- else:
- results = self.cv2(self.cv1(x))
- return results
-
-
- class RepNCSP(nn.Module):
- # CSP Bottleneck with 3 convolutions
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv(c1, c_, 1, 1)
- self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
- self.m = nn.Sequential(*(RepNBottleneck_AFF(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
-
- def forward(self, x):
- return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
-
-
- class RepNCSPELAN4_AFF(nn.Module):
- # csp-elan
- def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- self.c = c3//2
- self.cv1 = Conv(c1, c3, 1, 1)
- self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))
- self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
- self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
-
- def forward(self, x):
- y = list(self.cv1(x).chunk(2, 1))
- y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
- return self.cv4(torch.cat(y, 1))
-
- def forward_split(self, x):
- y = list(self.cv1(x).split((self.c, self.c), 1))
- y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
- return self.cv4(torch.cat(y, 1))
-
-
- if __name__ == '__main__':
- x1 = torch.randn(1, 32, 16, 16)
- x2 = torch.randn(1, 32, 16, 16)
- model = AFF(32)
- x = model(x1, x2)
- print(x.shape)

四、手把手教你添加AFF
4.1 AFF添加步骤
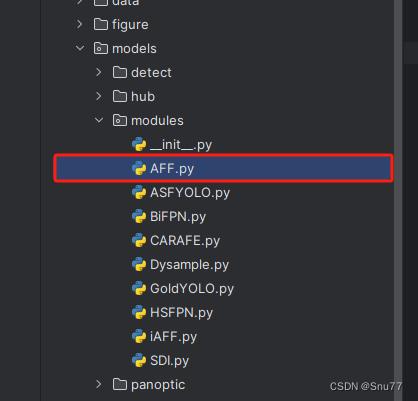
4.1.1 修改一
首先我们找到如下的目录'yolov9-main/models',然后在这个目录下在创建一个新的目录然后这个就是存储改进的仓库,大家可以在这里新建所有的改进的py文件,对应改进的文件名字可以根据你自己的习惯起(不影响任何但是下面导入的时候记住改成你对应的即可),然后将AFF的核心代码复制进去。
4.1.2 修改二
然后在新建的目录里面我们在新建一个__init__.py文件(此文件大家只需要建立一个即可),然后我们在里面添加导入我们模块的代码。注意标记一个'.'其作用是标记当前目录。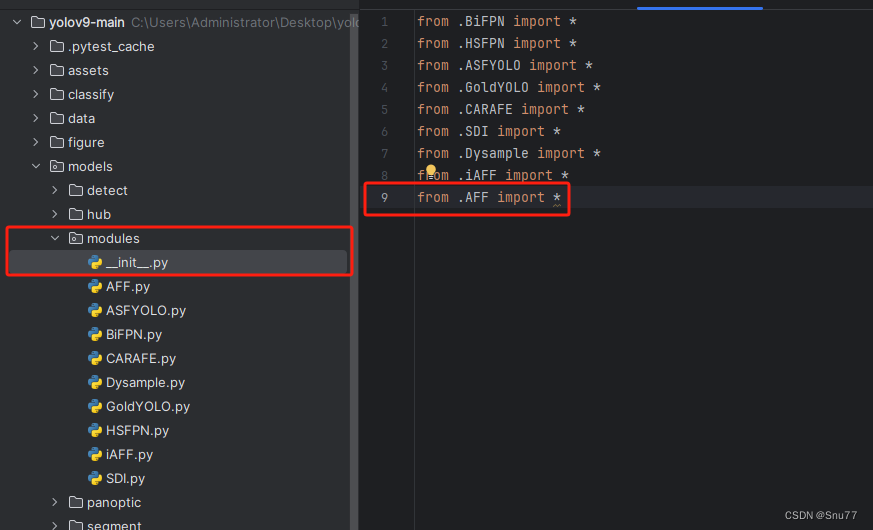
4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

4.1.4 修改四
然后我们找到''models/yolo.py''文件中的parse_model方法,按照如下修改->
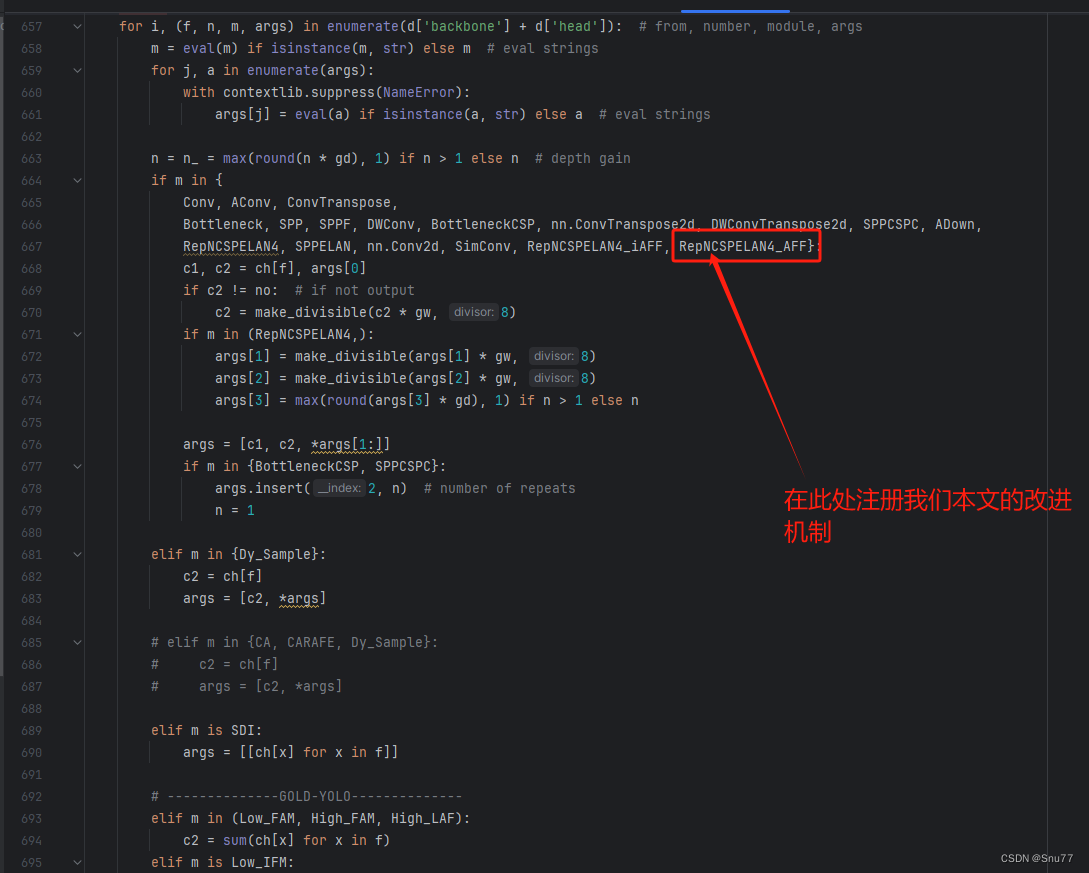
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 AFF的yaml文件
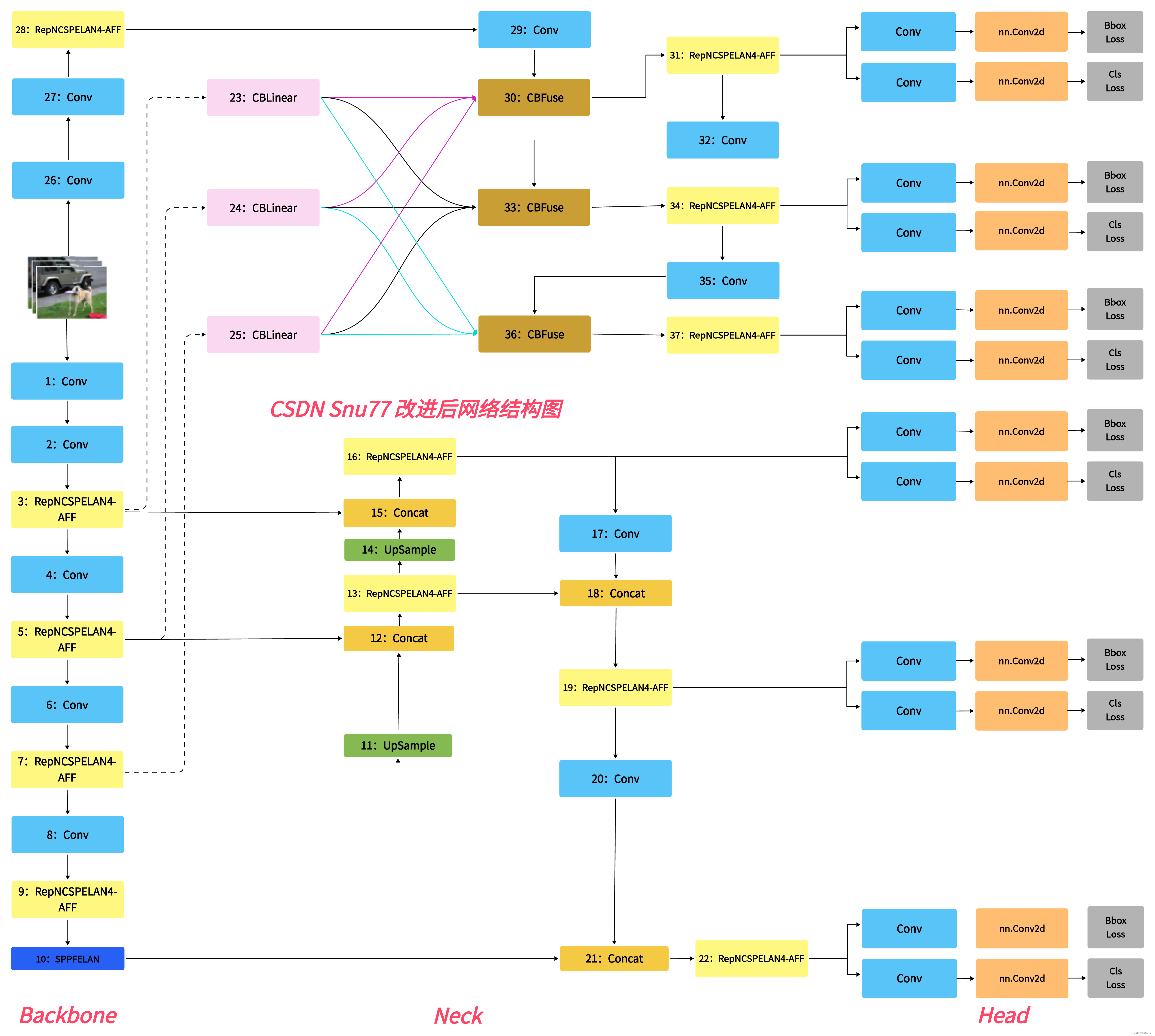
因为其只能在进行残差的时候求和,所以我们只需要替换主干上的C3即可。
- # YOLOv9
-
- # parameters
- nc: 80 # number of classes
- depth_multiple: 1 # model depth multiple
- width_multiple: 1 # layer channel multiple
- #activation: nn.LeakyReLU(0.1)
- #activation: nn.ReLU()
-
- # anchors
- anchors: 3
-
- # YOLOv9 backbone
- backbone:
- [
- [-1, 1, Silence, []],
- # conv down
- [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 2-P2/4
- # elan-1 block
- [-1, 1, RepNCSPELAN4_AFF, [256, 128, 64, 1]], # 3
- # conv down
- [-1, 1, Conv, [256, 3, 2]], # 4-P3/8
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 256, 128, 1]], # 5
- # conv down
- [-1, 1, Conv, [512, 3, 2]], # 6-P4/16
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 7
- # conv down
- [-1, 1, Conv, [512, 3, 2]], # 8-P5/32
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 9
- ]
-
- # YOLOv9 head
- head:
- [
- # elan-spp block
- [-1, 1, SPPELAN, [512, 256]], # 10
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 7], 1, Concat, [1]], # cat backbone P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 13
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 5], 1, Concat, [1]], # cat backbone P3
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [256, 256, 128, 1]], # 16 (P3/8-small)
-
- # conv-down merge
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, 13], 1, Concat, [1]], # cat head P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 19 (P4/16-medium)
-
- # conv-down merge
- [-1, 1, Conv, [512, 3, 2]],
- [[-1, 10], 1, Concat, [1]], # cat head P5
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 22 (P5/32-large)
-
- # routing
- [5, 1, CBLinear, [[256]]], # 23
- [7, 1, CBLinear, [[256, 512]]], # 24
- [9, 1, CBLinear, [[256, 512, 512]]], # 25
-
- # conv down
- [0, 1, Conv, [64, 3, 2]], # 26-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 27-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4_AFF, [256, 128, 64, 1]], # 28
-
- # conv down fuse
- [-1, 1, Conv, [256, 3, 2]], # 29-P3/8
- [[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 256, 128, 1]], # 31
-
- # conv down fuse
- [-1, 1, Conv, [512, 3, 2]], # 32-P4/16
- [[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 34
-
- # conv down fuse
- [-1, 1, Conv, [512, 3, 2]], # 35-P5/32
- [[25, -1], 1, CBFuse, [[2]]], # 36
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4_AFF, [512, 512, 256, 1]], # 37
-
- # detect
- [[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
- ]
4.3 iAFF的训练过程截图
大家可以看下面的运行结果和添加的位置所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的)。
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
希望大家阅读完以后可以给文章点点赞和评论支持一下这样购买专栏的人越多群内人越多大家交流的机会就更多了。


