
- 1flutter知识点---手势识别原理
- 2python 学习之 request 库的基本使用_python request
- 3项目经理的基本能力和素质要求,你具备了吗_基本素质pmp
- 4如何下载GitHub一部分文件(一部分目录、某个文件夹、某个文件)_github下载部分文件
- 5_016_信号
- 6欧莱雅校招负责人张泽宇:拥抱Z世代,探索新玩法
- 7带你玩转Visual Studio(八)——带你跳出坑爹的Runtime Library坑_vc++2008 runtime libraries
- 8io.lettuce.core.RedisConnectionException: Unable to connect to 127.0.0.1:6379
- 9SQL Server数据库 -- 表的创建与管理_sql创建表
- 10第7章 HBase操作_hbase创建学生表
文献翻译:Social LSTM: Human Trajectory Prediction in Crowded Spaces
赞
踩
这是我阅读的有关轨迹预测的第一篇文献,其内容和使用的模型相对简单,是比较适合的入门篇,我在此把原文翻译分享出来,便于大家交流学习。
Abstract
行人遵循不同的轨迹,以避开障碍物并容纳同行的行人。任何在这种场景中航行的自动车辆都应该能够预见行人的未来位置,并相应地调整其路径以避免碰撞。这个轨迹预测的问题可以看作是一个序列生成任务,我们感兴趣的是根据人过去的位置来预测人未来的轨迹。继最近循环神经网络(RNN)模型在序列预测任务中的成功之后,我们提出了一个LSTM模型,它可以学习一般的人类运动并预测他们未来的轨迹。这与传统方法形成对比,传统方法使用手工制作的函数,如社会力量。我们在几个公共数据集上展示了我们的方法的性能。我们的模型在一些数据集上优于最先进的方法。我们还分析了由我们的模型预测的轨迹,以展示由我们的模型学习的运动行为。
1. Introduction
人类有与生俱来的互相“阅读”的能力。当人们走在拥挤的公共空间,如人行道、机场候机楼或购物中心时,他们遵守大量(不成文的)常识规则,并遵守社会习俗。例如,当他们考虑下一步去哪里时,他们尊重个人空间,并让出通行权。建立这些规则的模型并使用它们来理解和预测复杂现实世界环境中的人类运动的能力在广泛的应用当中是非常有价值——从部署具有社会意识的机器人[41]到设计智能环境中的智能跟踪系统[43]。

然而,在考虑这种常识性行为的同时预测人类的运动是一个极具挑战性的问题。这需要理解在拥挤的空间里人们之间发生的复杂而微妙的相互作用。最近在计算机视觉方面的研究已经成功地解决了其中的一些挑战。Kitani et .艾尔。[32]已经证明,与忽略场景信息的模型相比,关于静态环境语义的推断知识(例如,人行道的位置、草地区域的延伸等)有助于更准确地预测未来时刻行人的轨迹。[24,50,35]的开创性工作还提出了模拟人与人之间的相互作用(通常称为“社会力量”)的方法,以提高多目标跟踪问题的鲁棒性和准确性。
在这次工作中,我们提出了一种方法,可以通过一种新的数据驱动架构来预测未来人类轨迹,从而解决这两个挑战。最近,长短期记忆网络(LSTM)在不同的序列预测任务中取得了成功,例如手写[20]和语音[21]生成,受此启发,我们将它们扩展到人类轨迹预测。虽然LSTMs具有学习和复制长序列的能力,但它们不能捕捉多个相关序列之间的相关性。
我们通过一种新颖的结构来解决这个问题,这种结构连接了对应于附近序列的LSTMs。特别是,我们引入了一个“社会”池化层,它允许空间上最接近的序列相互共享它们的隐藏状态。这种架构,我们称之为“Social-LSTM”,它可以自动学习发生在时间重合的轨迹之间的典型交互。该模型利用现有的人类轨迹数据集,而不需要任何额外的注释来学习人类在社交空间中遵守的常识规则和惯例。
最后,我们证明了我们的Social-LSTM能够在两个公开可用的数据集上比最先进的方法更准确地预测行人的轨迹:ETH[49]和UCY [39]。我们还分析了由我们的模型生成的轨迹模式,以理解从轨迹数据集学习到的社会约束。
2. Related work
人与人的互动 赫尔宾和莫尔纳尔的开创性工作[24]提出了一个具有吸引力和排斥力的行人运动模型,称为社会结构模型。即使在现代行人数据集上,这也被证明可以获得有竞争力的结果[39,49]。这个方法后来被扩展到机器人学[41]和活动理解[43,73,50,38,37,9,10]。
类似的方法已经被用来模拟人类与人类的互动,并具有很强的模型先验性。Treuille[62]使用连续体动力学,Antonini等人[2]王等提出离散选择框架。[69],Tay等人。[59]使用高斯过程。这样的函数也曾被用来研究固定群[74,48]。这些工作以平滑的运动路径为目标,不处理与离散化相关的问题。
另一项工作使用精心设计的特征和属性来改进跟踪和预测。Alahi[1]通过从人群中的hu-man轨迹中学习它们的相对位置来呈现社会亲和特征,而Yu[74]提出使用人的属性来改进密集人群中的预测。他们还使用类似于[6]的基于代理的模型。Rodriguez[54]分析高密度人群的视频,以跟踪和统计人数。
这些模型大多基于特定场景的相对距离和规则提供手工制作的能量势。相比之下,我们提出了一种以更通用的数据驱动方式学习人机交互的方法。
活动预测 活动预测模型试图预测视频中人要执行的移动或动作。大量的工作通过聚类轨迹来学习运动模式[26,30,46,77]。更多的方法可以在[45,52,34,3,16,33]中找到。Kitani在[32]中,使用反向强化学习来预测静态场景中的人类路径。他们通过模拟人与空间的相互作用来推断场景中可行走的路径。Walker等人在[68]中预测了在给定大量视频的视觉场景中一般智能体(例如,虚拟代理)的行为。Ziebart等人[78,23]提出了一种基于规划的方法。
图雷克等人[63,40]使用了类似的想法来识别场景的功能图。像[27,19,42,36]这样的其他方法展示了使用场景语义来预测人类航行的目标和路径。场景语义学也被用来预测多物体运动[17,36,34,28]。这些工作大多局限于使用静态场景信息来预测人体运动或活动。在我们的工作中,我们专注于为路径预测建模动态人群交互。
最近的工作也试图预测未来人类的行为。尤其是Ryoo等人[55,8,71,67,44,58]预测流式视频中的动作。与我们的工作更相关的是使用RNN mdoel来预测视频中未来事件的想法[53,57,66,56,31]。沿着类似的路线,我们预测场景中的未来轨迹。
RNN models for sequence prediction 最近,循环神经网络(RNN)及其变体,包括长短期记忆(LSTM) [25]和门控递归单元[12]已被证明在序列预测任务中非常成功:语音识别[21,11,13],字幕生成[64,29,75,15,72],机器翻译[4],图像/视频分类[7,22,70,47],人类动力学[18]等等。RNN模型也被证明对具有密集连接数据的任务是有效的,例如语义分割[76],场景解析[51],甚至作为卷积神经网络的替代[65]。这些工作表明,RNN模型能够学习空间相关数据(如图像像素)之间的相关性。这促使我们将Graves 等人[20]的序列生成模型扩展到我们的环境中。特别是,Graves等人[20]预测孤立的手写序列;而在我们的工作中,我们共同预测与人类轨迹相对应的多个相关序列。
3. Our model
在拥挤的场景中移动的人根据周围其他人的行为调整他们的运动。例如,一个人可以完全改变他/她的道路,或者暂时停下来适应一群向他走来的人。这种轨迹的偏差不能通过单独观察这个人来预测。不能用简单的“排斥”或“吸引”函数来预测(传统的社会力量模型[24,43,73,50])
这促使我们建立一个模型,该模型可以解释一个区域内其他人的行为,同时预测一个人的路径。在这一节中,我们描述了我们基于池化的LSTM模型(图2),它共同预测了场景中所有人的轨迹。我们称之为“社会”LSTM模式。

Problem formulation 我们假设首先对每个场景进行预处理,以获得所有人在不同时刻的空间坐标。以前的工作也遵循这个惯例[41,1]。在任何时刻t,场景中的第i个人由他/她的xy坐标(xt,yt)表示。我们观察所有人从时间1到Tobs的位置,并预测他们在时间Tobs+1到Tpred的位置。这个任务也可以看作是一个序列生成问题[20],其中输入序列对应于一个人的观察位置,我们有兴趣生成一个输出序列,表示他/她在不同时刻的未来位置。
3.1. Social LSTM
每个人都有不同的运动模式:他们以不同的速度、加速度运动,并有不同的步态。我们需要一个模型,它能够从与人相对应的有限的一组初始观察中理解和学习这种特定于人的运动特性。
长期短期记忆(LSTM)网络已被证明能够成功地学习和生成孤立序列的特性,如手写[20]和语音[21]。受此启发,我们也为我们的轨迹预测问题开发了一个基于LSTM的模型。特别是,在一个场景中,我们每个人都有一个LSTM。这个LSTM学习人的状态,并预测他们的未来位置,如图2所示。LSTM权重在所有序列中共享。
然而,每人仅仅使用一个LSTM模型并没有捕捉到邻里之间的互动。普通的LSTM不知道其他序列的行为。我们通过图3、2中显示的一种新的池化策略来连接相邻的LSTMs,从而解决了这个限制。

Social pooling of hidden states 个体通过隐含地推理周围人的运动来调整他们的路径。这些邻居反过来会受到周围其他人的影响,并随着时间的推移改变他们的行为。我们期望LSTM的隐藏状态能够捕捉这些随时间变化的运动特性。为了在多人之间共同推理,我们在相邻的LSTMs之间共享状态。这带来了一个新的挑战:每个人都有不同数量的邻居,在非常密集的人群中,这个数字可能会高得惊人。
因此,我们需要一个紧凑的表示,它结合了来自所有邻近状态的信息。我们通过引入如图2所示的“社交”池化层来处理这个问题。在每一个时间步长,LSTM单元从邻居的LSTM单元接收汇集的隐藏状态信息。在汇集信息的同时,我们试图通过基于网格的汇集来保存空间信息,如下所述。
LSTM在时间t的隐藏状态捕捉到了那个瞬间场景中那个人的潜在表现。我们通过建立一个“社会”隐态张量来与邻居共享这种表示。给定一个隐态维数D和邻域大小No,我们为轨迹构造一个No× No× D张量:
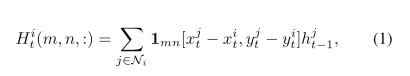
其中ht-1是对应于t1处的jthperson的LSTM的隐藏状态,1mn[x,y]是检查(x,y)是否在网格的(m,n)单元中的指示函数,Niis是对应于人I的邻居集合。该汇集操作在图3中可视化。(对于公式符号乱码问题,请参考原文)
我们将汇集的社会隐藏状态张量嵌入到一个向量中,并将坐标嵌入到et i中。这些嵌入被连接起来,并在时间t用作相应轨迹
的LSTM单元的输入。这引入了以下递归:
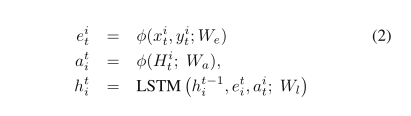
其中φ(·)是一个具有ReLU非线性的嵌入函数,We 和 Wa 是嵌入权重。LSTM权重用Wi表示。
Position estimation t时刻的隐藏状态用于预测t+1时刻的轨迹位置(x,y)的分布。与Graves等人[20]类似,我们假设一个双变量高斯分布,由均值μi t+1= (μx,μy)i t+1、标准差σi t+1= (σx,σy)I t+1和相关系数ρi t+1参数化。这些参数由一个具有5 × D权重矩阵Wp的线性层预测。时间t的预测坐标(xi t,yi t)由下式给出
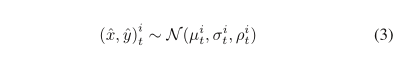
LSTM模型的参数是通过最小化负对数似然损失来学习的:
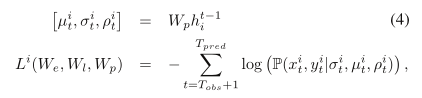
我们通过最小化训练数据集中所有轨迹的损失来训练模型。请注意,我们的“社交”池层没有引入任何附加参数。
与传统LSTM的一个重要区别是,多个LSTMs的隐藏状态由我们的“Social” pooling layer 耦合,我们在每个时间步长通过场景中的多个LSTMs 联合反向传播。
Occupancy map pooling “社会”LSTM模型可用于汇集相邻轨迹的任何特征集。为简化起见,我们还试验了一个只汇集邻居坐标的模型(在试验4部分中称为O-LSTM坐标).这是原始模型的简化,并且在训练期间不需要跨所有轨迹的联合反向传播。该模型仍然可以学习重新定位轨迹,以避免与邻居直接碰撞。然而,在缺乏来自邻近人的更多信息的情况下,该模型将不能平滑地改变路径以避免未来的碰撞。
对于一个人i,我们修改了张量H,在时间t作为一个以人的位置为中心的的No×No矩阵,称之为占用率图。所有邻居的位置都汇集在这个图中。映射的m,n元素简单地由下式给出:
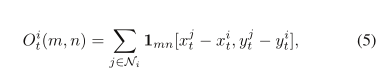
这里1mn[·]是前面定义的指标函数。这也可以看作是Eq.1.中社会张量的简化,其中隐藏状态向量由指示相应单元中邻居的存在或不存在的常数值代替。
&emsp矢量化的占位图用于代替Hi t 在 Eq2,同时学习这个更简单的模型。
Inference for path prediction 在测试期间,我们使用训练好的Social-LSTM 模型来预测测试者的未来第i人的位置(Xt,Yt)。从时间Tobs+1到Tpred,我们使用来自先前的Social-LSTM单元的预测位置(xi t,yi t)代替等式2中的真实坐标(xi t,yi t)。预测的位置也用于在构建社会隐藏状态张量Hi 时替换实际坐标在Eq1中或占用图Oi 在Eq5中。
3.2. Implementation details
在将空间坐标用作LSTM的输入之前,我们使用64的嵌入维数。我们将空间池大小设置为不超过32,并使用一个没有重叠的8×8总和池窗口大小。我们对所有LSTM模型使用了128的固定隐藏状态维度。此外,在使用隐藏状态特征计算隐藏状态张量之前,我们还在合并的隐藏状态特征上使用了具有ReLU(校正线性单位)非线性的嵌入层。超参数是基于合成数据集的交叉验证选择的。这种合成是使用实现社会力量模型的模拟生成的。这些合成数据包含数百个场景的轨迹,平均人群密度为每帧30人。我们使用0.003的学习率和均方根值来训练模型。Social-LSTM 模型是在一个单独的图形处理器上训练出来的,并有一个模拟实现。
4. Experiments
在这一部分,我们介绍了两个公开的人类轨迹数据集的实验:ETH [49]和UCY [39]。ETH数据集包含两个场景,每个场景有750个不同的行人,并分为两组(ETH和酒店)。UCY数据集包含两个786人的场景。该数据集有3个组成部分:ZARA-01、ZARA02和UCY。总之,我们在5组数据上评估我们的模型。这些数据集代表了真实世界拥挤的环境,有成千上万条非线性轨迹。如[49]所示,这些数据集还涵盖了具有挑战性的群体行为,如情侣一起散步、群体相互交叉以及群体在某些场景中形成和分散。
我们用三种不同的度量来报告预测误差。类似于Pellegrini等人[49],我们使用:
1.平均位移误差——轨迹所有估计点和真实点的均方误差。这是在Pellegirini等人[49]中介绍的。
2.最终位移误差-预测周期结束时预测的最终目的地和真实最终目的地之间的距离。
3.平均非线性位移误差——这是轨迹非线性区域的均方误差。由于大多数轨迹预测误差发生在人与人相互作用产生的非线性转弯过程中,我们明确评估了这些区域周围的误差。我们在二阶导数的范数上设置一个启发式阈值来识别非线性区域。
为了在训练我们的模型时充分利用数据集,我们使用了留一法。我们在4个集合上训练和验证我们的模型,并在剩下的集合上进行测试。我们对所有5组重复这一步骤。我们还对用于比较的其他基线方法使用相同的培训和测试程序。
在测试期间,我们观察3.2秒的轨迹,并预测接下来4.8秒的路径。在0.4的帧速率下,这对应于观察8帧并预测接下来12帧。这类似于[49,39]使用的设置。在表4中,我们用最先进的方法和多种控制设置来比较我们模型的性能:
线性模型(Lin)我们使用现成的卡尔曼滤波器来推断假设线性加速度的轨迹。
防撞(LTA)。我们报告了社会力量[73]模型的简化版本的结果,该模型仅使用碰撞回避能量,通常称为线性轨迹回避。
社会力量(SF)。我们使用了[73]中的社会力量模型的实现,其中对群体亲和力和预测目的地等几个因素进行了建模。
迭代高斯过程(IGP)。我们使用[61]中IGP的实现。与其他基线不同,IGP还使用关于一个人最终目的地的附加信息。
我们的Vanilla LSTM (LSTM)。这是我们模型的一个简化设置,其中我们移除了“社交”池层,并将所有轨迹视为彼此独立。
我们的LSTM,配有occupancy maps (O-LSTM)。我们展示了我们模型的一个简化版本的性能(在第3节中介绍)。.提醒一下,该模型在每个时间实例中只汇集邻居的坐标。
原始线性模型产生高预测误差,从平均非线性位移误差来看,非线性区域周围的预测误差更明显。Vanilla LSTM优于这种线性基线,因为它可以外推非线性曲线,如Graves等人[20]所示。然而,这个简单的LSTM明显比社会力量和IGP模型更糟糕,后者明确地模拟了人与人之间的相互作用。这表明需要考虑这种相互作用。
 表1 .所有数据集上所有方法的定量结果。我们将性能指标表示如下:前6行是平均位移误差,第7行到第12行是非线性区域的平均位移误差,最后6行是最终位移误差。所有方法都预测4.8秒的固定时间段的轨迹。(*)请注意,与其他方法不同,IGP在测试期间使用人的预期地面真实目的地。
表1 .所有数据集上所有方法的定量结果。我们将性能指标表示如下:前6行是平均位移误差,第7行到第12行是非线性区域的平均位移误差,最后6行是最终位移误差。所有方法都预测4.8秒的固定时间段的轨迹。(*)请注意,与其他方法不同,IGP在测试期间使用人的预期地面真实目的地。
我们基于LSTM和LSTM的社会统筹在几乎所有数据集上都优于精心设计的社会力量和IGP模型。特别是,与联邦理工学院相比,UCY数据集的误差减少更为显著。这可以用两个数据集中不同的人群密度来解释:UCY包含更多的人群区域,总共有32K个非线性区域,而人口更稀少的ETH场景只有15K个非线性区域。
在更拥挤的UCY场景中,与线性路径的偏离更多地由人与人之间的相互作用主导。因此,在UCY数据集上,我们捕捉邻域交互的模型获得了更高的增益。行人到达某一目的地的意愿在交通出行数据集上起着更为主导的作用。因此,在测试期间知道真实最终目的地的IGP模型在该数据集的部分中实现了较低的误差。
在ETH的情况下,我们还观察到占用率和社会LSTM误差彼此相当,并且总体上优于社会力模型。同样,在更拥挤的UCY数据集上,我们的社会LSTM优于LSTM。这显示了汇集整个隐藏状态以捕捉密集人群中复杂交互的优势。
4.1. Analyzing the predicted paths
我们在第4节中的定量评估表明,在标准数据集上,学习的Social-LSTM模型优于最先进的方法。在本节中,我们试图获得更多关于我们的模型在不同人群环境中的实际行为的见解。我们定性地研究了我们的Social-LSTM方法在个人以特定模式相互作用的社会场景中的表现。
我们在图4中展示了一个由四个人占据的示例场景。我们将模型预测的路径在不同时刻的分布可视化。图4中的第一行和第三行显示了每个人的当前位置以及他们的真实轨迹(实线代表未来路径,虚线代表过去)。第二行和第四行显示了我们对未来12.4秒的社会LSTM预测。在这些场景中,我们观察到三个人(2,3,4)走得很近,第四个人(1)走得更远。
我们的模型预测了人(1)在任何时候的线性路径。人(1)的分布在时间上是相似的,表明人的速度是恒定的。
我们可以在三人组的预测轨迹中观察到更有趣的模式。特别是,我们的模型做出了明智的路线选择,为他人让步,并防止未来的冲突。例如,在时间步长2、4和5,我们的模型预测人(3)和人(4)的线性路径的偏差,甚至在实际转弯开始之前。在第3步和第4步,我们注意到Social-LSTM预测人(3)会“停下来”,以便为人(1)让步。有趣的是,在时间步骤4,停止点的位置被更新以匹配路径中的真实转折点。在下一个时间步,通过更多的观察,模型能够正确地预测锚定在那个点的完整转弯。
 图4。我们将场景中4个人在6个时间步长内移动的预测路径的概率分布可视化。子标题描述了我们的模型预测的内容。在每个时间步长:第1、3行中的实线代表地面真实的未来轨迹,虚线表示在该时间步长之前观察到的位置,点表示在该时间步长的位置。我们注意到,我们的模型经常在具有非线性运动的挑战性环境中正确预测未来路径。我们在第4.1节中更详细地分析了这些数字。请注意,T代表时间,id (1到4)表示个人id。补充材料中提供了更多的例子。
图4。我们将场景中4个人在6个时间步长内移动的预测路径的概率分布可视化。子标题描述了我们的模型预测的内容。在每个时间步长:第1、3行中的实线代表地面真实的未来轨迹,虚线表示在该时间步长之前观察到的位置,点表示在该时间步长的位置。我们注意到,我们的模型经常在具有非线性运动的挑战性环境中正确预测未来路径。我们在第4.1节中更详细地分析了这些数字。请注意,T代表时间,id (1到4)表示个人id。补充材料中提供了更多的例子。
在图5中,我们展示了我们的Social-LSTM预测结果,SF模型[49]和一个ETH数据集的线性基线。当人们成群结队或像一对夫妇一样行走时,我们的模型能够共同预测他们的轨迹。有趣的是,不像社会力量[73],我们没有明确地为群体行为建模。然而,我们的模型更擅长以整体方式预测分组轨迹。在图5的最后一行,我们展示了一些失败的例子,即当我们的预测比以前的工作更糟糕的时候。我们要么预测一条直线路径(第二列),要么比需要的更早减速(第一列和第三列)。尽管在这些情况下,轨迹不符合基本事实,但我们的社会LSTM仍然输出“似是而非”的轨迹,即人类可能采取的轨迹。例如,在第一列和第三列中,我们的模型减速以避免与前面的人发生潜在的碰撞。
 图5。说明我们的Social-LSTM方法预测轨迹。在前3行,我们展示了一些例子,其中我们的模型成功地预测了具有小误差(在位置和速度方面)的轨迹。我们还展示了其他方法,如社会力量[73]和线性方法。最后一行代表故障情况,例如,人减速或走直线路径。然而,我们的社会LSTM方法预测了一条看似合理的道路。结果显示在ETH数据集上[49]。
图5。说明我们的Social-LSTM方法预测轨迹。在前3行,我们展示了一些例子,其中我们的模型成功地预测了具有小误差(在位置和速度方面)的轨迹。我们还展示了其他方法,如社会力量[73]和线性方法。最后一行代表故障情况,例如,人减速或走直线路径。然而,我们的社会LSTM方法预测了一条看似合理的道路。结果显示在ETH数据集上[49]。
5. Conclusions
我们已经提出了一个基于LSTM的模型,它可以跨多个个体联合推理来预测场景中的人类轨迹。我们对每个轨迹使用一个LSTM,并通过引入一个新的社会统筹层在各大物流中心之间共享信息。我们称由此产生的模型为“社会”LSTM。我们提出的方法在两个公开可用的数据集上优于最先进的方法。此外,我们定性地表明,我们的社会LSTM成功地预测了由社会互动产生的各种非线性行为,例如一群人一起移动。未来的工作将把我们的模型扩展到多类设置,其中几个对象,如自行车、滑板、手推车和行人共享同一个空间。每个对象在占用图中都有自己的标签。此外,可以在我们的框架中通过将局部静态场景图像作为LSTM的附加输入来模拟人与空间的交互。这可以允许在同一框架中联合建模人-人和人-空间的相互作用。

