
- 1Hive——Hive安装全流程_hive 数据库的 安装操作
- 2JAVA常见报错和异常_java报错
- 3idea将新项目推送到gitlab上_idea 新项目推送到gitlab
- 4navicat设置MySQL字段int类型的长度INT(M)_navicat int长度改不了
- 5python1_turtlependown的作用
- 6SpringBoot启动过程探究及配置文件优先级解析_bootstrapregistryinitializer
- 7Arduino ESP32Web配网(二)_esp32 web配网
- 8C#调用python脚本_c# 调用py脚本
- 92024华为OD面试手撕代码真题目录_华为od手撕代码
- 10Python MD5加密方式_pythonmd5加密
国内最大开源模型发布,无条件免费商用!参数650亿,基于2.6万亿token训练
赞
踩
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
国内规模最大的开源大模型来了:
参数650亿、基于2.6-3.2万亿token训练。
排名仅次于“猎鹰”和“羊驼”,性能媲美GPT3.5,现在就能无条件免费商用。
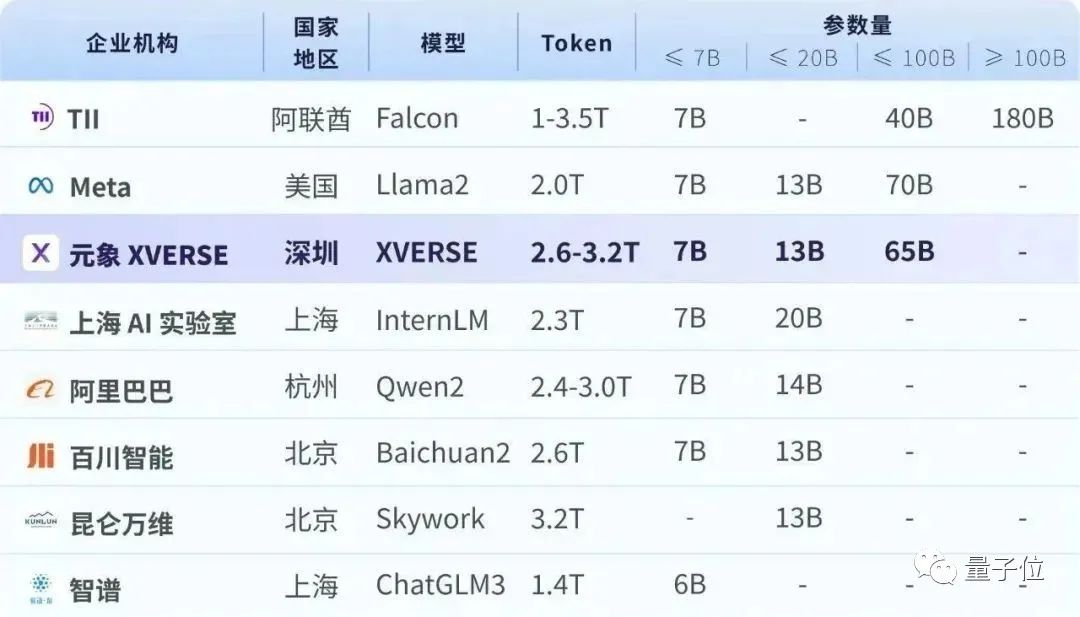
它就是来自深圳元象公司的XVERSE。
根据算力、资源限制和具体任务需求的不同,我们能对它进行任何自由修改或蒸馏。
除了规模大,它还具有16k上下文,支持40多种语言,并还有7B、13B两个版本可选。
具体什么来头?
国内规模最大的可商用大模型来了
研究表明,参数量越高,高质量训练数据越多,大模型性能才能不断提升。
而业界普遍共识是达到500到600亿参数门槛,大模型才能“智能涌现” ,在多任务中展现强大性能。
但训练此量级模型成本高昂,技术要求较高,目前主要为闭源付费提供。
在国外开源生态中,Llama2-70B和Falcon-180B等标杆模型为“有条件”开源,设置了月活跃用户数或收入等商用上限,并因缺乏训练数据在中文能力上有明显短板。
在此,为推动国产大模型开源生态与产业应用发展,元象XVERSE公司宣布开源650亿参数高性能通用大模型XVERSE-65B,无条件免费商用。13B模型则全面升级,提高“小”模型能力上限。
元象XVERSE创始人姚星表示:“面对研发时间紧、算力持续短缺等挑战,团队在三个月内研发出多款高性能7B、13B模型,并最早为社区献上一个‘大有可为’的65B模型。”
XVERSE-65B底座模型在2.6万亿Tokens的高质量数据上从头训练,上下文窗口扩展至16K,支持中、英、俄、法等40多种语言。
显著提升了三方面能力:
一、理解、生成、推理和记忆等基础能力,到模型的多样性、创造性和精度表现,从优异到强大;
二、扩展了工具调用、代码解释、反思修正等能力,为构建智能体(AI Agent)奠定技术基础,提高模型实用性;
三、显著缓解7B、13B中常见且可能很严重的幻觉问题,减少大模型“胡说八道”,提高准确性和专业度。
元象大模型系列均为全自研,涵盖多项关键技术与研发创新:
1、复杂分布式系统设计:
借鉴团队研发腾讯围棋AI“绝艺”、王者荣耀AI“绝悟”等大系统上的丰富经验,自研高效算子、显存优化、并行调度策略、数据-计算-通信重叠、平台与框架协同等关键技术,打造高效稳定的训练系统, 千卡集群峰值算力利用率达58.5%,位居业界前列。
2、全面提升性能:
65B训练中采用 FlashAttention2加速计算, 3D并行基础上采用虚拟流水线(virtual pipeline)技术,降低较长流水线产生过高气泡率,提升计算推理效率;上下文窗口长度从8K逐步提升到16K,使其不仅能出色完成复杂任务,包括长文理解、长文生成和超长对话,还拓展了工具调用、代码解释及反思修正能力,能更好构建智能体(AI Agent)。
3、极致提升训练稳定性:
因计算量庞大,通信拥塞、芯片过热或计算节点故障成为65B训练常态,初期出现过一周最高八次故障的情况。
通过集群基础设施运营、资源调度、训练框架和调度平台协同等持续优化,元象打造出高稳定、低中断、强容错的训练系统,将每周有效训练率提升至98.6%。
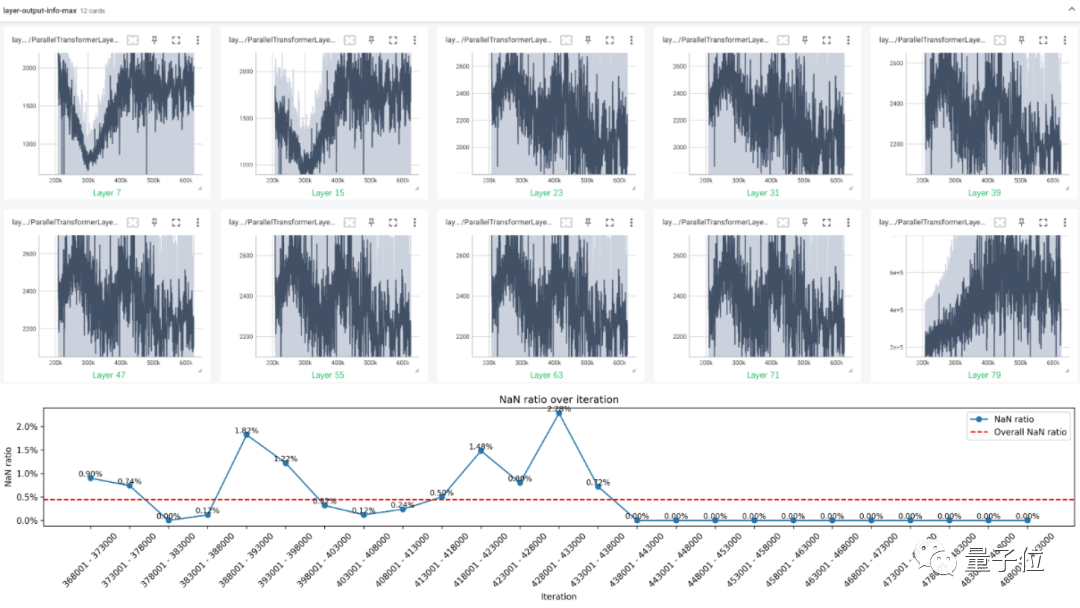
此外,在接近1.6万亿Tokens的模型训练中期,损失函数产生了NaN值,可能导致训练中断。
通常情况下,业界一般会在分析后删除与之相关的数据区间。
而团队根据经验判定这是模型自然演化,选择不删除数据,直接跳过相关参数更新,最终 NaN值 问题解决。
后期对参数值、激活值、梯度值等中间状态的进一步分析表明,该问题可能与模型最后一层transformer block激活值的最大值变化有关,并会随最大值的逐渐降低而自行解决。
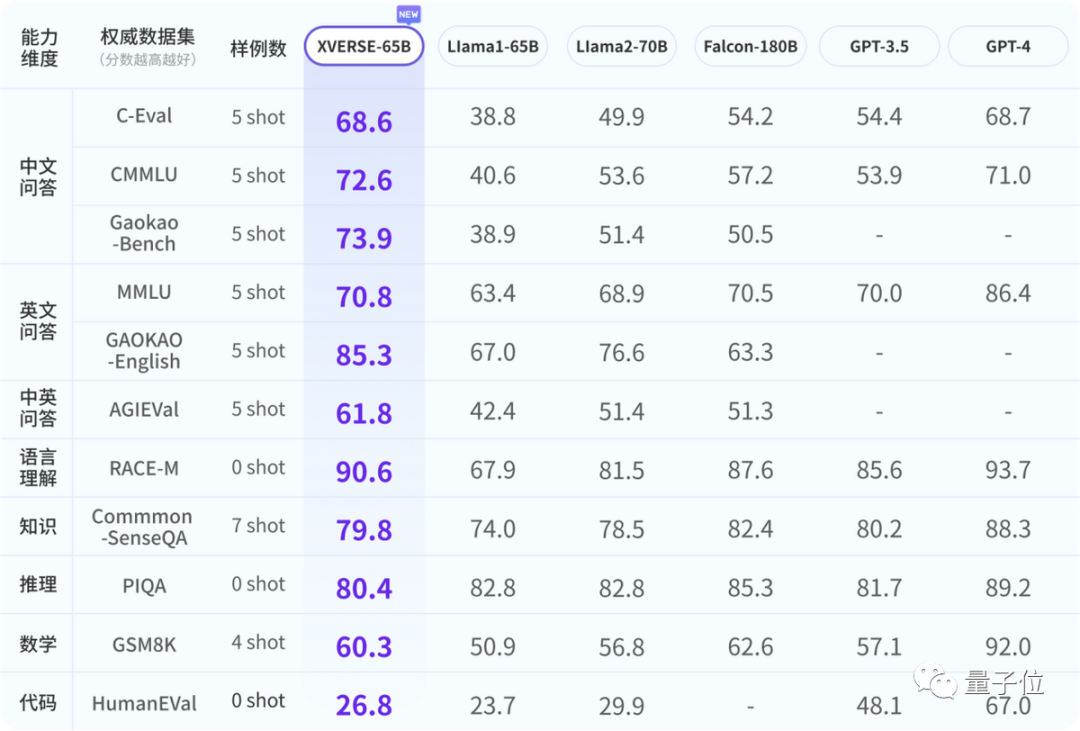
性能媲美GPT3.5
为确保业界能对元象大模型性能有全面、客观、长期认知,研究人员参考了一系列权威学术测评,制定了涵盖问答、理解、知识、推理、数学、代码等六个维度的11项主流权威测评标准,将持续使用并迭代。
XVERSE-65B在国内尚无同量级模型可对比,在与国外标杆对比测评中,部分指标超越、综合性能媲美GPT3.5;全面超越开源标杆Llama2-70B 和Falcon-180B;与GPT4仍有差距。
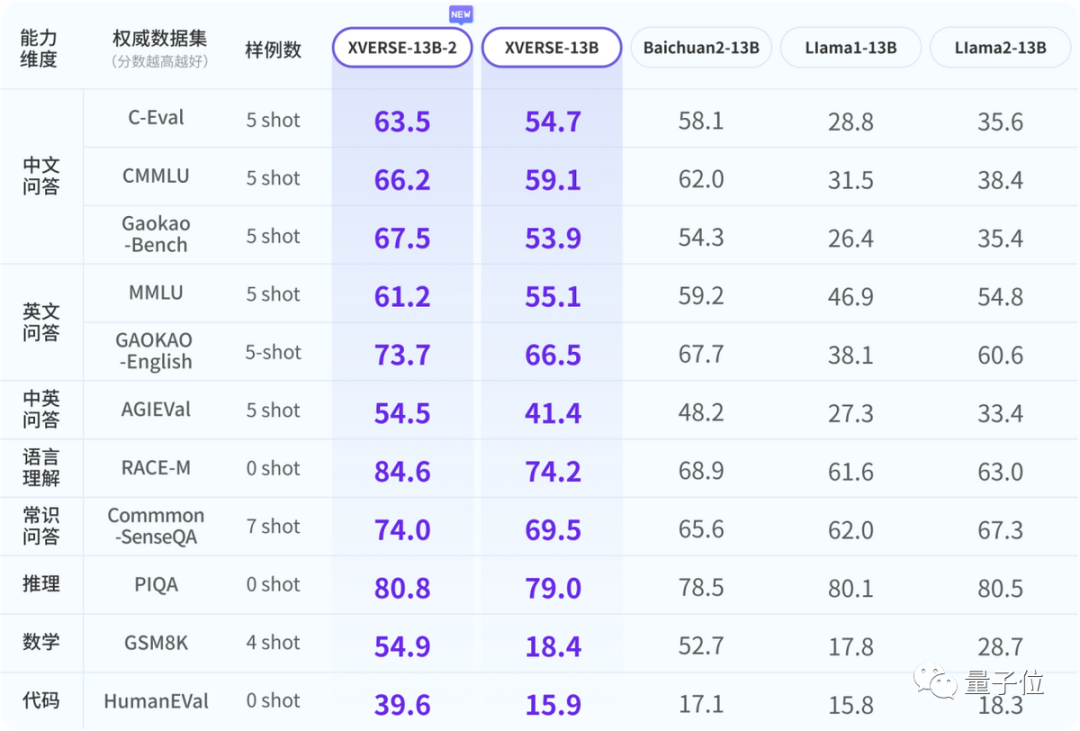
全面升级的XVERSE-13B-2,比同尺寸模型增加大量高质量数据,训练数据高达3.2万亿, 极大提升了“小”模型的能力上限。
它文理兼修,保持了文科优势,问答提升18%,理科长足进步, 代码提升149%、数学提升198%,在测评中全面超越了Llama2、Baichuan2等国内外开源标杆。
现在,元象大模型可在Github、Hugging Face、魔搭ModelScope等多平台搜索“XVERSE”下载,简单登记后即可无条件免费商用,能满足中小企业、科研机构和个人开发者绝大部分的应用与迭代需求。
元象同时提供模型训练、推理、部署、精调等全方位技术服务,赋能文娱、金融、医疗等各行各业,帮助在智能客服、创意写作、精准推荐等多场景打造行业领先的用户体验。
2023年10月, 腾讯音乐率先宣布与元象大模型建立战略合作 ,共同推出lyraXVERSE加速大模型、全面升级其音乐助手“AI小琴”,未来还将持续探索AI与3D前沿技术。
关于元象
元象XVERSE于2021年初在深圳成立,主营AI与3D技术。
累计融资金额超过2亿美元,投资机构包括腾讯、高榕资本、五源资本、高瓴创投、红杉中国、淡马锡和CPE源峰等。
元象创始人姚星是前腾讯副总裁和腾讯AI Lab创始人、国家科技部新一代人工智能战略咨询委员会成员。
— 完 —
「量子位2023人工智能年度评选」开始啦!
今年,量子位2023人工智能年度评选从企业、人物、产品/解决方案三大维度设立了5类奖项!欢迎扫码报名
MEET 2024大会已启动!点此了解详情。

点这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

