
- 1从商品图到海报生成 京东广告AIGC创意技术应用_商品图生成展示背景 算法
- 2Linux系统有哪些解压文件的方式?详解_linux解压
- 3GitLab服务器重新设置IP后无法访问_gitlab改端口后打不开网页
- 4python 网络_python获取网络时间和本地时间
- 5Video组件的使用_前端video
- 620240514金融读报:超长期特别国债&金融消费者保护服务平台&数据资产与AI&RPA流程
- 7【MySQL进阶-05】深入理解mvcc机制(详解)
- 8Mybatis常见查询总结,仅限于初级程序员阅读_mybatis 只查询某一列
- 9Spring Boot 整合 Camunda 实现工作流
- 10每周分享第 52 期
探索 StableDiffusion:生成高质量图片学习及应用
赞
踩

本文主要介绍了 StableDiffusion在图片生成上的内容,然后详细说明了StableDiffusion 的主要术语和参数,并探讨了如何使用 prompt 和高级技巧(如图像修复、训练自定义模型和图像编辑)来生成高质量的图片。

介绍StableDiffusion
▐ StableDiffusion是什么
Stable Diffusion是一种潜在的文本到图像扩散模型,能够生成逼真的图像,只需任何文本输入,就可以自主自由创造漂亮的图像,使众多不会拍照的人在几秒钟内创造出惊人的图片。StableDiffusion可以生成不同的图片风格,比如:Anime 动画,realistic 写实,Landscape 风景,Fantasy 奇幻,Artistic 艺术。 还有很多其他的风格,都可以在网上看到。
▐ StableDiffusion主要术语
有一些图示来直观理解StableDiffusion,比较深奥,不过多解释:
https://zhuanlan.zhihu.com/p/599887666
模型
https://stable-diffusion-art.com/models/
网上可以下载到的StableDiffusion模型非常多。只需要记得这些都是SD模型的微调版本即可,这些不同版本的StableDiffusion模型都是基于相同的算法和原理,并且都可以用于生成高质量的图像、音频、视频等数据。具体选择哪个版本取决于应用场景和具体需求。
以下是常见模型,以及说明:

也可以自己做模型的合并,在StableDiffusion的GUI界面如下操作即可:
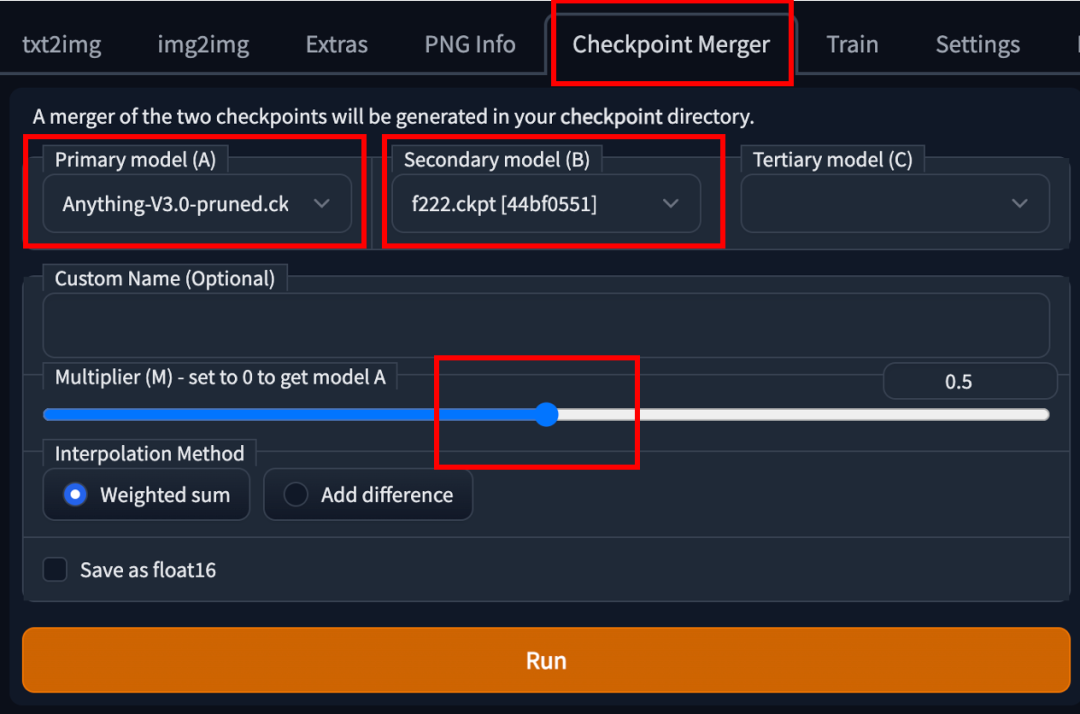
使用 AUTOMATIC1111 GUI 合并两个模型,转到 Checkpoint Merger 选项卡,在 Primary model (A) 和 Secondary model (B) 中选择要合并的两个模型。
调整乘数 (M) 来调整两个模型的相对权重。将其设置为 0.5 将以相等重要性合并两个模型。
按下运行按钮后,新合并的模型就可以用了。
微调模型:Embedding && Lora && Hypernetwork
CheckPoint:这些是真正稳定的扩散模型。它们包含生成图像所需的所有内容,不需要额外的文件。它们通常很大,大小为2-7 GB。本文的主题是它们。
Embedding:也称为Textual inversions。它们是定义新关键词以生成新对象或样式的小文件。通常为10-100 KB。您必须与CheckPoint模型一起使用。
LoRA:它们是用于修改样式的检查点模型的小补丁文件。它们通常为10-200 MB。您必须与CheckPoint模型一起使用。也是用于给先有模型做一些微小的改变;可以对原有模型做补丁,然后通过关键词触发风格,人物。
Hypernetwork:它们是添加到CheckPoint模型的附加网络模块。它们通常为5-300 MB。您必须与CheckPoint模型一起使用。
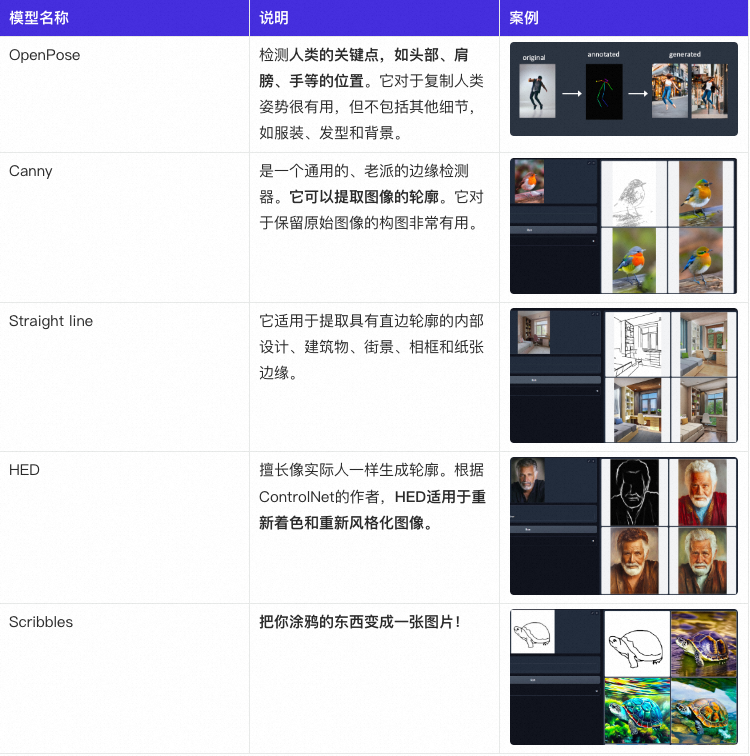
ControlNet 控制姿势
ControlNet是一种稳定的扩散模型,可以复制作品和人体姿势。想要使用的话再扩展中安装sd-webui-controlnet扩展即可。
正常情况下我们想要控制人物的姿势是十分困难的,并且姿势随机,而ControlNet解决了这个问题。它强大而多功能,可以与任何扩散模型一起使用。
主要作用:
边缘检测,家具摆放等
人体姿势复制
可用的模型以及说明:
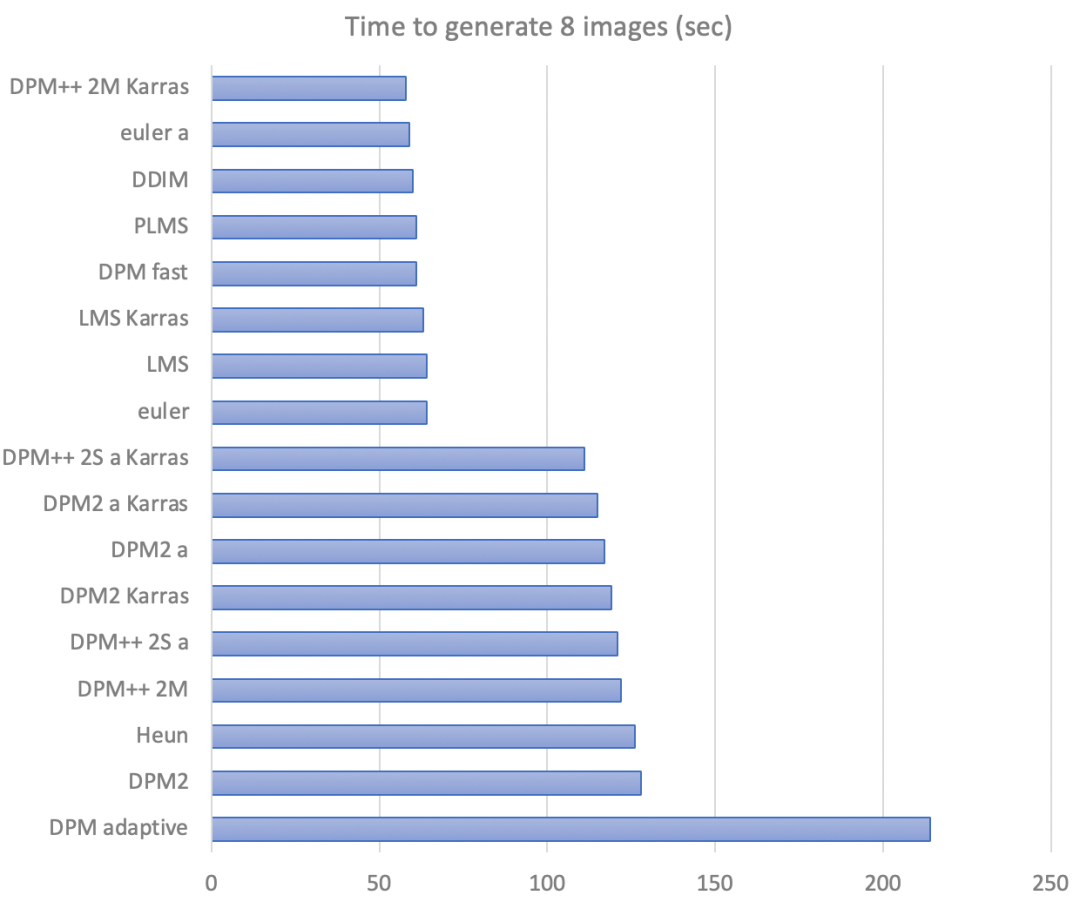
抽样算法
不同抽样算法的生成时间对比:
使用不同的抽样算法生成的图片:
a busy city street in a modern city

Stable Diffusion 主要参数列表
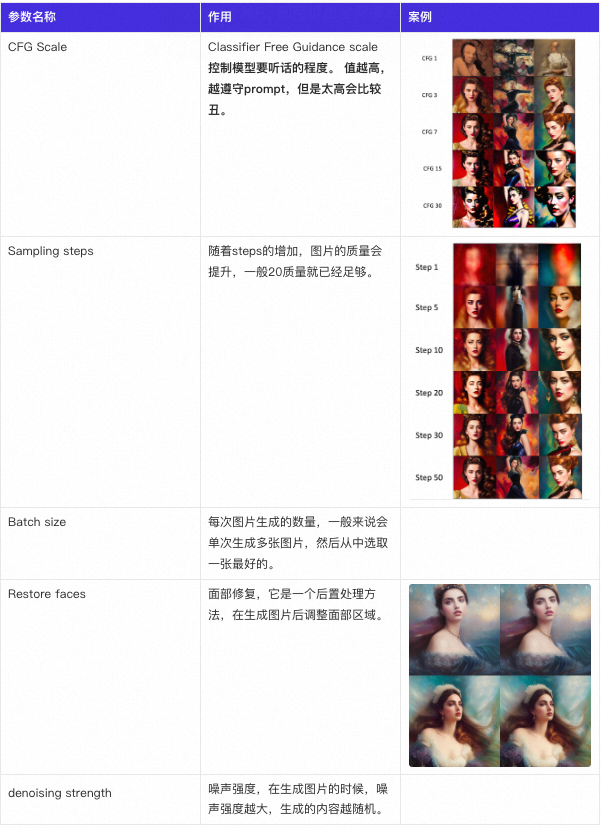
https://stable-diffusion-art.com/know-these-important-parameters-for-stunning-ai-images/#Sampling_methods

如何生成高质量的图片
▐ 什么是prompt?
在StableDiffusion中,"prompt"是指为GPT模型提供输入的文本段落或句子。它是用来引导模型生成有意义、准确的响应的关键因素之一。
好的Prompt结构
Subject (required) 主体
Medium 艺术类别
Style 艺术风格
Artist 艺术家
Website 艺术流派
Resolution 清晰度
Additional details 额外的细节
Color 色彩
同时可以考虑满足以下的条件:
在描述主题时要详细和具体。
使用多个括号()来增强其强度,使用[]来降低。
艺术家的名字是一个非常强的风格修饰符,使用的时候要知道这个是什么风格。
Prompt风格参考
如果不确定要用什么风格,可以去下面的两个地址搜一下对应的风格
关键词检索(laion-aesthetic-6pls):https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
艺术风格汇总list of artists for SD:https://rentry.org/artists_sd-v1-4
prompt查询参考:https://stablediffusionweb.com/prompts
查找Tag:https://aitag.top/
摄影大师:https://docs.google.com/spreadsheets/d/16KKh1FQmd-r98K9aWPBux5m9lc9PCV_T1AWgU54qXm8/htmlview

Prompt调整权重
使用()增加权重,使用[]降低权重;

a (word) - 将对单词的权重增加1.1倍
a ((word)) - 将对单词的权重增加1.21倍(= 1.1 * 1.1)
a [word] - 将对单词的权重减少1.1倍
a (word:1.5) - 将对单词的权重增加1.5倍
a (word:0.25) - 将对单词的权重减少4倍(= 1 / 0.25)
a
word - 在提示中使用字面上的()字符,转义,不使用权重
prompt也可以从某个点位开始考虑生成指定的内容:
[from:to:when]
示例:
a [fantasy:cyberpunk:16] landscape
开始时,模型将绘制一幅fantasy景观。
在第16步之后,它将切换到绘制一幅cyberpunk:景观,继续从fantasy停止的地方绘制。
另外一种语法:
[cow|horse] in a field
第1步,提示是“cow”。第2步是“horse”。第3步是“cow”,以此类推。
一些参考prompt
negtive提示符:
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur, distorted face
((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck)))
如何想出好的prompt:https://stable-diffusion-art.com/how-to-come-up-with-good-prompts-for-ai-image-generation/#Some_good_keywords_for_you
负面提示符:https://stable-diffusion-art.com/how-to-use-negative-prompts/#Negative_prompt_with_Stable_Diffusion_v15
▐ 生成高质量的图片进阶?
图片修复 (inpaiting)
https://stable-diffusion-art.com/inpainting-remove-extra-limbs/
下载inpaiting模型;
可以生成图片后点击send img2img,也可以自己上传到img2img;
用刷子进行绘制想要修改的区域,刷完之后,重新生成。

其中的一些参数:

模型记得选择SDv1.5修复模型(sd-v1-5-inpainting.ckpt)。
训练自己的模型?
可以直接在Colab云端训练,本地也不用配置环境,训练也很快:
https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-LoRA-dreambooth.ipynb#scrollTo=WNn0g1pnHfk5
想在本地训练:
参考:https://github.com/bmaltais/kohya_ss
训练教程:https://stable-diffusion-art.com/dreambooth/
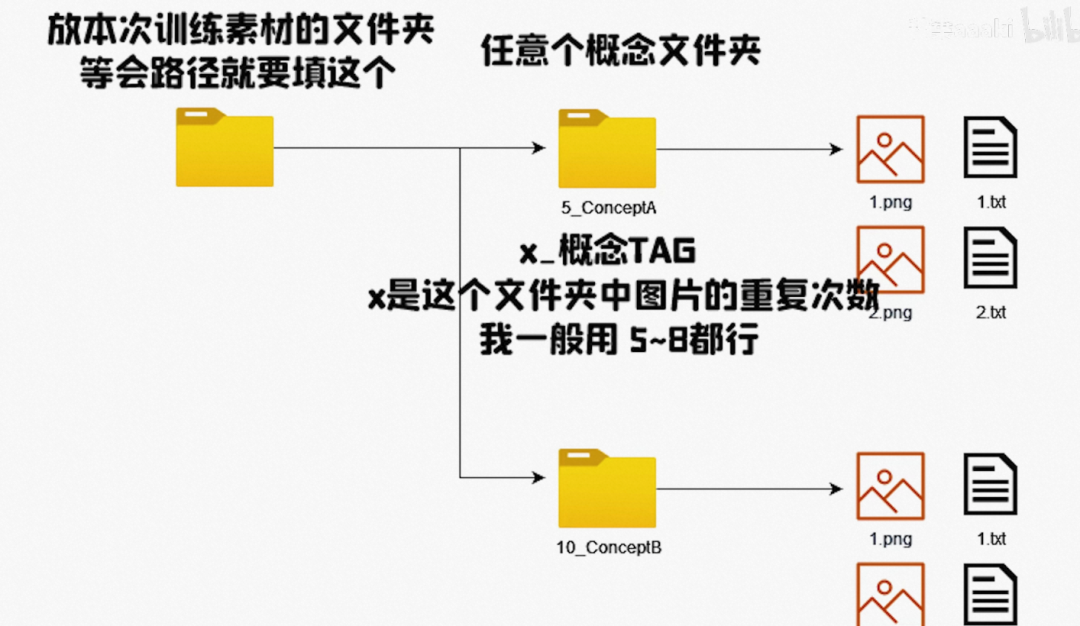
确定要训练模型的唯一标识(起个名字),以及这个模型所对应的类型(class);
比如如果想要训练一个狗的模型,那么狗就是对应的类型(class),然后可以给这个狗起一个名字。名字尽量不要太容易重复;
准备把图片制作有有固定尺寸,创建一个目录:
<repeat count>_<class>一次可以训练多个概念开始训练、选择在colab上训练是最方便的方式,本地就省去了很多配置。
以上要准备的内容简单说就是:图片、类型、唯一名字
https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-LoRA-dreambooth.ipynb#scrollTo=kh7CeDqK4l3Y
按照colab正常操作就行;最终会输出一份训练的模型到你的Google Driver中。然后自己在本地测试:
prompt:a woman, hitokomoru , with a cat on her head <lora:hito_komoru_test:1>
negtive: (worst quality:2), (low quality:2),disfigured, ugly, old, wrong finger
使用自己的Lora VS 不使用Lora

还有一次可以训练多个概念,把文件件组织好就行了
图片编辑 pix2pix
编辑配置文件configs/instruct-pix2pix.yaml,改为如下内容:
- use_ema: true // 默认为false
- load_ema: true
denoising 改为1.0, 抽样使用Euler a算法;
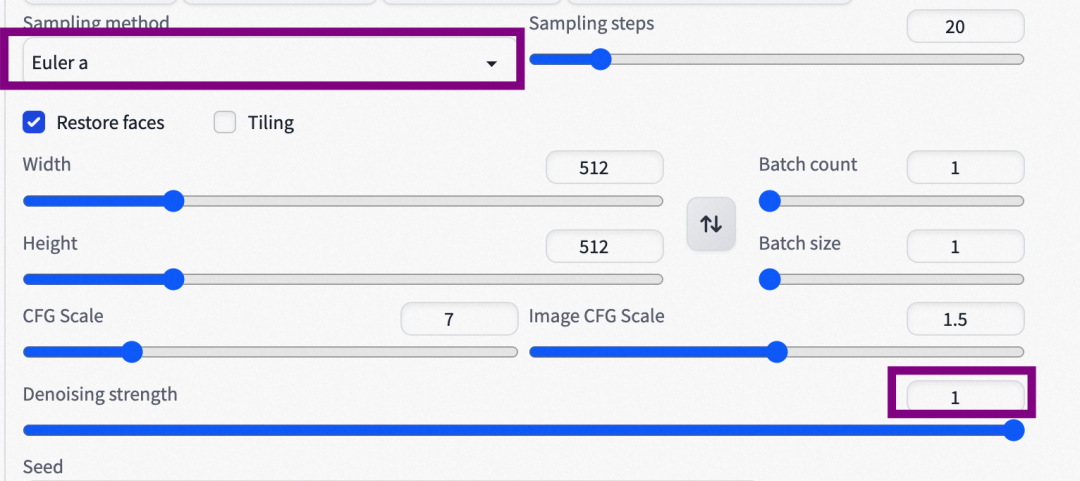
常用参数:
text cfg: 越大代表生成的内容越接近我们的文字描述
image cfg: 越大代表越接近我们的原始图片,越小代表可以越不按照原始图片生成

下面是一些常用的指令模板:
Change the Style to (an artist or style name)
Have her/him (doing something)
Make her/him look like (an object or person)
Turn the (something in the photo) into a (new object)
Add a (object)
Add a (object) on (something in the photo)
Replace the (object) with (another object)
Put them in (a scene or background)
Make it (a place, background or weather)
Apply (a emotion or something on a person)
有时候重新表达指令可以改善结果(例如,“turn him into a dog”与“make him a dog”与“as a dog”)。
增加steps的值有时可以改善结果。
人脸看起来奇怪?Stable Diffusion自编码器在图像中人脸较小的情况下会有问题。尝试:裁剪图像,使人脸在画面中占据更大的部分。
资料地址:
模型下载地址:https://huggingface.co/timbrooks/instruct-pix2pix/resolve/main/instruct-pix2pix-00-22000.ckpt
线上体验地址:https://huggingface.co/spaces/timbrooks/instruct-pix2pix
使用脚本
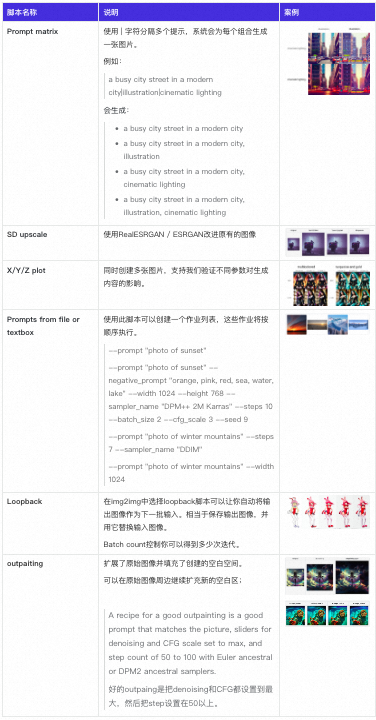
Stable Diffusion的webUI中默认有一些脚本,可以方便我们尝试一些不同的生成方式。

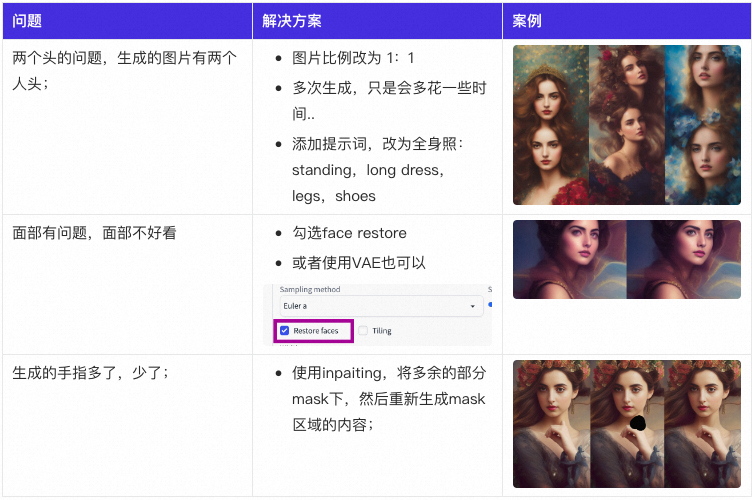
常见生成人物问题与处理
▐ StableDiffusion生成图片演示
水底美女文字生成 text2img
水下摄影肖像,iu1,裙子,美丽的详细女孩,极其详细的眼睛和脸,美丽的详细眼睛,闭着嘴,黑色的头发,锁骨,裸露的肩膀,长睫毛,飘逸的头发,气泡,阳光穿过水面,逼真,照片般的真实感,由泰德·格兰博拍摄,最高品质。
正面提示:underwater photography portrait, iu1, dress, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed eyes, closed mouth, black hair, collarbone, bare shoulders, longeyelashes, floating hair, bubbles, sun light breaking through water surface, realistic, photorealistic, by ted grambeau, best quality
<lora:iu_V35:0.8>
反面提示:(worst quality:2), (low quality:2), (normal quality:2) , goggles, sun glasses, hand, extra fingers, fewer fingers, strange fingers, bad hand

参数 | 值 | 参数说明 |
CFG scale | 8 | 值越大,越符合你的prompt,范围为1~30;默认为7. 个人测试: 5以下看起来不好看 |
Sampling steps | 20 | 理论上越大,图片质量越高,但是可能会带来模糊 |
Image size | 512×512 | |
Seed | -1 | |
Face restoration | Codeformer | 勾选面部修复 |
Sampling method | DPM++ 2M Karas | |
Model | F222 | 默认是SD模型,可以下载这个模型,F222主要用在女性身材生成上比较擅长: https://huggingface.co/acheong08/f222/blob/main/f222.ckpt |
微调模型 | Lora iu https://civitai.com/models/11722/iu | 默认是SD模型,可以下载这个模型,F222主要用在女性身材生成上比较擅长: https://huggingface.co/acheong08/f222/blob/main/f222.ckt |
我做的事情:
下载并使用F222模型;
参考其他水底美女提示符,修改人物生成要用的人物;
微调提示符,多次生成;
西湖风景后期处理 img2img
原始照片:

生成prompt:
第一张prompt: ((Sunset)) , (Lake Gold) , Boat Center, Mountain, Tree in left, realistic, photorealistic, , 8K,Wide-angle, (expansive:1.5) , a combination of red, orange, pink, and purple.
negtive: (worst quality:2), (low quality:2)
第二张:a sunset over a body of water with a tree branch hanging over it and the sun reflecting in the water, a photo, Arthur Pan, dau-al-set, tranquil
第三张:two ducks swimming in a pond with fish in the water and a fish in the water behind them,, an impressionist painting, Emperor Huizong of Song, cloisonnism, tone mapping
第四张:a field of colorful flowers with green stems and yellow and red flowers in the middle of the field,, a jigsaw puzzle, Bob Thompson, color field, rich vivid colors

人像卡通化测试 img2img
prompt:a young man holding a durian fruit in his hand , portrait ,detailed eyes, hyperrealistic
negtive prompt: (worst quality:2), (low quality:2),disfigured, ugly, old
模型:AnythingV3;
Denoising strength从0.1依次升高,第一张为原图;

Denoising strength: 0.4~0.7(可以看到从0.5的噪声强度开始,AI已经开始自由发挥了,虽然也会参考原图)

Denoising strength: 0.8~0.9 (基本完全自由发挥)

依旧是上个原图,换为midjourney v4模型,Denoising strength测试0.2, 0.4, 0.6, 0.8
相同的提示词,换个模型之后整体风格大变;

图片编辑测试 pix2pix
TextCFG固定:7.5,调整ImageCFG;
Put him in beach


控制人物姿势 ControlNet
提示:A girl, showing her muscles, detailed face , realistic ,8k <lora:chilloutmixss30_v30:1>
negtive prompht: (worst quality:2), (low quality:2),disfigured, ugly, old,nsfw
除了控制姿势,还可以控制人物的表情,这里我们只是控制人物的姿势;


图片Inpaiting测试 img2img

给“模特”戴项链:
A girl, (necklace:1.5), showing her muscles, detailed face , realistic ,8k <lora:chilloutmixss30_v30:1>

给“模特”戴墨镜:
A girl, (sunglasses:1.5), showing her muscles, detailed face , realistic ,8k <lora:chilloutmixss30_v30:1>


StableDiffusion在实际应用中的案例
▐ 个人应用
娱乐,头像、图片加工(不同风格处理)、创作新的场景(尝试一些场景,然后告诉SD)
快速创建艺术作品、设计产品原型
▐ 商业应用
设计工具,帮助设计师快速创建产品原型、样式和艺术作品
营销工具,帮助企业快速创建逼真的广告海报、产品展示图、电影场景等,提高营销效果。
个性化定制,个性化定制平台中,帮助消费者快速创建个性化产品,例如定制T恤、鞋子等
教育上,创新教育,虚拟实验,只需要有想象力就可以生成对应的图片

探讨StableDiffusion与AIGC未来的发展趋势
将概念扩大不仅是生成图片,而是人工智能生成内容的话,参开ChaGPT的回答,在未来人工智能技术可能的发展方向和影响;
▐ 媒体行业和广告行业
人工智能内容生成技术可以用于新闻、报道、评论等方面,帮助媒体机构更快速、高效地生成内容。同时,它也可以用于广告创意、广告文案等方面,帮助广告公司更好地推广产品和服务。
▐ 游戏行业和教育行业
人工智能内容生成技术可以用于游戏角色、游戏关卡等方面,帮助游戏公司更好地设计和开发游戏。此外,它还可以用于教学资源的生成和个性化教学,例如生成教材、课件、试题等。
▐ 金融行业和医疗行业
人工智能内容生成技术可以用于金融报告、分析和预测,例如生成金融新闻报道、投资报告等。在医疗行业中,它可以用于医疗报告和病历记录,例如生成病历记录、医学报告等。
▐ 法律行业和建筑行业
人工智能内容生成技术可以用于法律文件和合同的生成,例如生成合同、法律文书等。在建筑行业中,它可以用于建筑设计和规划,例如生成建筑设计图纸、规划方案等。
▐ IT行业
人工智能内容生成技术在IT行业中的应用非常广泛,可以将其分为以下几个子类别:
内容创作
人工智能内容生成技术可以用于互联网内容的自动化生成,例如自动化生成新闻报道、博客文章、社交媒体内容等,从而提高效率和质量。
搜索引擎
人工智能内容生成技术可以用于搜索引擎的优化和改进,例如生成更好的搜索结果、提高搜索的准确性和速度等。
个性化推荐
人工智能内容生成技术可以用于个性化推荐系统的优化和改进,例如生成更符合用户兴趣和需求的推荐内容。
聊天机器人
人工智能内容生成技术可以用于聊天机器人的开发和优化,例如生成更自然、流畅的对话内容,提升用户体验。
数据分析
人工智能内容生成技术可以用于大数据分析和处理,例如自动生成数据报告、分析结果等。
软件开发
人工智能内容生成技术可以用于自动生成代码、文档、测试用例等,从而提高软件开发的效率和质量。
安全领域
人工智能内容生成技术可以用于网络安全和数据安全领域,例如自动生成安全报告、分析网络攻击等。
人机交互
人工智能内容生成技术可以用于改善人机交互体验,例如自动生成UI界面、语音交互内容等。
云计算
人工智能内容生成技术可以用于优化云计算服务,例如自动生成云计算资源规划、监控报告等。

总结
这里主要介绍了 StableDiffusion在图片生成上的内容,然后详细说明了StableDiffusion 的主要术语和参数,并探讨了如何使用 prompt 和高级技巧(如图像修复、训练自定义模型和图像编辑)来生成高质量的图片。最后设想了一些 StableDiffusion 在个人和商业领域的实际应用案例,讨论了它在媒体、游戏、金融、法律、IT 等行业的未来发展趋势。
最后,我们正处于 AIGC的时代,这些新技术正在改变我们的生活和工作方式,为我们带来前所未有的机遇和挑战。积极拥抱这些新技术,抓住时代的机遇,不断学习和适应新的变化。不管以后什么行业,AIGC 技术都将发挥越来越重要的作用。尽早探索未知的领域,开创更好的未来!

相关资源
免费的SD网站:https://stable-diffusion-art.com/free-ai-image-generator-sites/
stable diffusion webui:https://github.com/AUTOMATIC1111/stable-diffusion-webui
关键词检索(laion-aesthetic-6pls):https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
艺术风格汇总list of artists for SD:https://rentry.org/artists_sd-v1-4
艺术家作品列表:https://docs.google.com/spreadsheets/d/16KKh1FQmd-r98K9aWPBux5m9lc9PCV_T1AWgU54qXm8/htmlview
提示语辅助生成promptoMANIA:https://promptomania.com/
Textual Inversion Embeddings:https://cyberes.github.io/stable-diffusion-textual-inversion-models/
AIGC 掀起的商业浪潮:https://grow.alibaba-inc.com/course/4800013996045603
Stable Diffusion特性官方介绍:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
AI作品参考:
Playground AI:https://playgroundai.com/
Lexica:https://lexica.art/
krea:https://www.krea.ai/
模型下载:
-
Civitai:https://civitai.com/
Hugging Face:https://huggingface.co/models

团队介绍
大淘宝技术用户运营平台技术团队是一支最懂用户,技术驱动的年轻队伍,以用户为中心,通过技术创新提升用户全生命周期体验,持续为用户创造价值。
团队以创新为核心价值观之一,鼓励团队成员在工作中不断探索、实验和创新,以推动业界技术的进步和用户体验的提升。我们不仅关注当前业界领先的技术,更注重未来技术的预研和应用。团队成员会积极参与学术研究和技术社区,不断探索新的技术方向和解决方案。
团队立足体系化打造业界领先的用户增长基础设施,以媒体外投平台、ABTest平台、用户运营平台为代表的基础设施赋能阿里集团用户增长,日均处理数据量千亿规模、调用QPS千万级。在用户增长技术团队,我们提供“增长黑客”极客氛围和丰富的岗位选择,欢迎业界贤才加入。
¤ 拓展阅读 ¤

