
- 1Android精美登录界面设计
- 2使用 Calendar 计算时间_calendar 时间计算
- 3redis在linux的安装及redis常用指令的使用_linux 通过命令增加redis内存
- 4rabbitMQ知识概括_rabbitmq 端口
- 5模仿dcloudio/uni-preset-vue 自定义基于uni-app的小程序框架
- 6python断言assert实例求素数_Python单元测试框架之pytest -- 断言
- 7数字图像处理、计算机图形学相关的名词解释和解答题(二)
- 8使用vscode进行rebase拉取_vscode rebase
- 9翻译:Face-Sensitive Image-to-Emotional-Text Cross-modal Translation for Multimodal Aspect-based Sentim
- 10为什么java会发生溢出,java – 为什么这个乘法整数溢出导致零?
CUDA编程入门教程
赞
踩
CUDA编程入门教程
前言
我们身处在这个大数据时代,我们的一切无时无刻都被数据所记录,大数据甚至已经变成了另一种形式的自我个体。对于传统的计算机而言,以往很多巧妙的算法,面对海量数据也会失去光彩,变得无能为力。因为,计算机CPU总是在“单打独斗”,一个CPU的力量就算再强大,也抵不过千军万马。正如武侠小说中那样,每个时代总会有盖世英雄,但一个身怀绝技的大侠,也许面对些许敌人不足为惧,但是如果所有敌人都群拥而上,那估计他也要挂了。CPU就是一个时代中的佼佼者,他们不仅身怀绝技而且心怀天下,但是,这样的CPU总是稀少的;而GPU就不一样,虽然他们个人没有强大的能力,但是,GPU多呀,人多力量大,三个臭皮匠顶个诸葛亮。如果CPU和GPU齐心合力,便能解决这世间更多难题,CPU再也不会势单力薄了(老夫甚感欣慰),哈哈哈哈哈,扯远了~。
言归正传,本文就来讲讲如何基于CUDA编程,来利用GPU进行大量的并行计算。
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
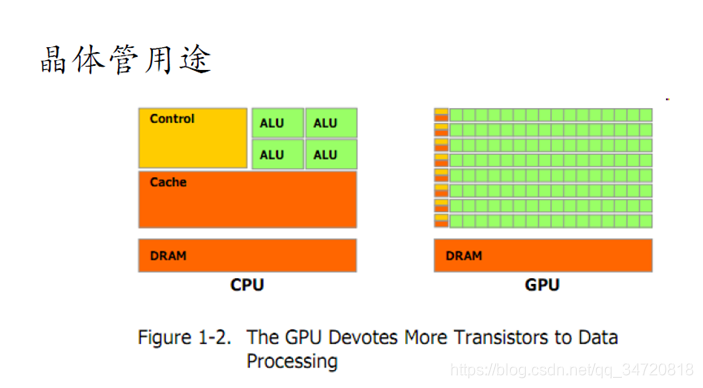
一、CPU与GPU硬件构造区别
CPU把大量的空间用来放置逻辑控制和缓存的晶体管,而真正的ALU(算术逻辑单元(计算单元))却很少;GPU中用来放置控制和缓存的晶体管空间比较小,将节省下来的空间用来放置更多的轻量级计算单元(多达上万),这样GPU就有更多的计算单元可以同时进行计算。
二、CUDA框架下GPU线程组织方式
- GPU中有大量可以用来计算的单元,就像一个大公司一样,公司内有很多的员工,那么要对每个员工进行编号,就需要有一定的组织和层次,一般公司会分很多部门,而部门内部又会分很多小组,每个小组由若干员工组成,通过这样组织方式,就能从大量的员工中很容易的找到公司里的某个员工。
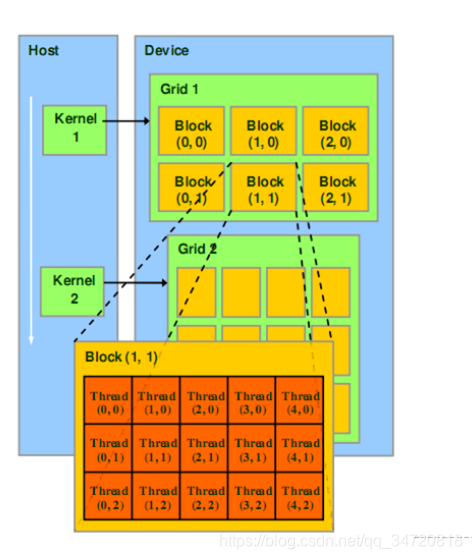
- GPU的线程组织方式和一个大公司的组织方式类似,首先一个Grid下包括多个block,每个block下包括多个warp,每个warp由32个线程组成。其中,Grid和Block既可以是以一维,也可以是以二维或者三维组织。如下图所示,Grid1是以2行3列的二维形式组织,Block是以3行5列的二维形式组织。
- 其实,对于Grid和Block的组织维度,可以理解为排队方式,如果Grid是一维,那block就是一排,如果Grid是二维,那block就以多排进行排队,如果Grid是三维,那block就是不同楼层的多排排队。就像一群员工排队一样,可以是直接排成一排(一维),也可以是排成多排(二维),也可以是每个楼层都有员工排队(三维)。block的维度和Grid维度类似。
根据以上CUDA的GOU线程组织方式,CUDA提供以下编程方式来确定每个线程的唯一标识。 - CUDA中包括几个内置变量gridDim;blockDim;blockIdx;threadIdx,用来确定线程索引。
- gridDim用来指定一个grid中,在各个方向上有几个block。gridDim.x指定一个grid中在x方向有几个block;gridDim.y指定一个grid中在y方向有几个block;gridDim.z指定一个grid中在z方向有几个block;
- blockDim用来指定一个block中,在各个方向上有几个线程。blockDim.x指定一个块中x方向有几个线程;blockDim.y指定一个块中y方向有几个线程;blockDim.z指定一个块中z方向有几个线程;
- blockIdx用来指定当前执行任务的block在各个方向上的索引。blockIdx.x指当前block在x方向上的索引值;blockIdx.y指当前block在y方向上的索引值;blockIdx.z指当前block在z方向上的索引值;
- threadIdx用来指定当前执行任务的thread在各个方向上的索引值。threadIdx.x指当前thread在x方向上的索引值;threadIdx.y指当前thread在y方向上的索引值;threadIdx.z指当前thread在z方向上的索引值;
- 以二维grid,一维block为例,计算黑圈标识处线程的索引标识。
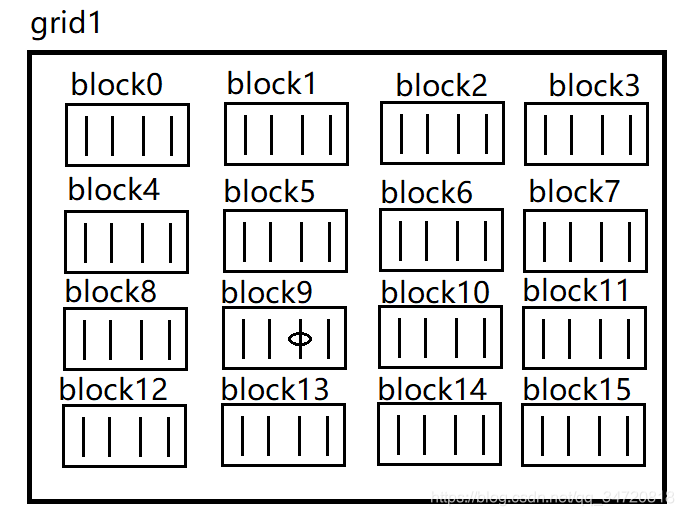
下图标识出grid在x,y方向上的索引。
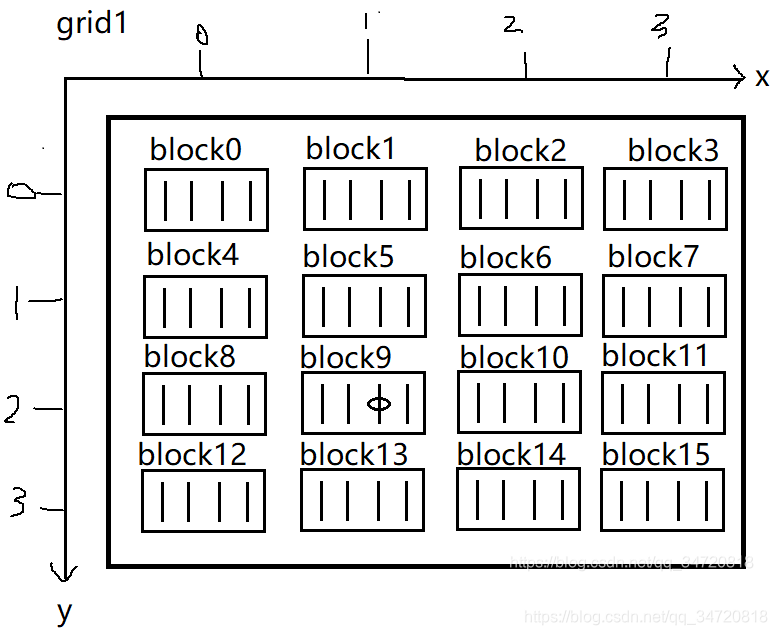
由上图可知:
gridDim.x=4,即每个grid在x方向有4个block;gridDim.y=4,即每个grid在y方向有4个block;
blockDim.x=4,即每个block在x方向上有4个线程;
上图黑圈标识的线程索引应该是,第10个block中的第3个线程,将其展开为一排(一维),因为一个block包含4个线程,那么9个block包含9 * 4=36个线程,黑圈标识出的线程索引为第9 * 4+3=39个线程。
将数字用CUDA内置变量进行表示,即为:第blockId.y* blockDim.x+blockId.x个block中的第threadIdx.x个线程,将其展开为一排(一维),即为第blockDimx*(blockId.y*blockDim.x+blockId.x)+threadIdx.x个线程。
线程的索引计算时CUDA编程的基础,必须要琢磨清楚。就比如你有很多的员工,但如果你不记得员工的编号(类似工牌号,姓名等),你就没有办法指定某个编号的员工去做某件事情。
三、CUDA框架下GPU逻辑组织与物理硬件映射关系

GPU在逻辑上的组织关系:最小的单元为一个线程(Thread),多个线程(Thread)组成一个块(Block),多个块组成一个网格(Grid)
GPU在物理上的组织关系:最小的单元为一个CUDA Core(ALU,算术逻辑运算单元)又称为SP(流处理器),多个CUDA Core组成一个SM(多流处理器),多个SM组成设备Device
由CUDA中GPU在软硬件上的组织关系可以得到映射关系为:一个线程对应一个CUDA Core,一个Block对应一个SM,一个Grid对应一个Device
四、CUDA框架下GPU内存和线程的关系

- CUDA框架下CPU和GPU是由各自独立的内存单元,CPU内存单元和GPU内存单元通过PCI-e进行数据传输。
- 在GPU中内存包括寄存器(registers)、本地内存(local memory)、共享内存(shared memory)、全局内存(global memory)、常量内存(constant memory)、纹理内存(texture memory)
- 每个网格(grid)分配一个可被整个GPU线程和外界CPU 读写全局内存,以及可被整个GPU线程和外界CPU读取常量内存和纹理内存。
- 每个块(block)分配一个块内所有线程可读写的共享内存。
- 每个线程(thread)分配一个可读写的寄存器和本地内存。
- 全局内存、常量内存、纹理内存就比如是整个公司的食堂一样,整个公司的人都可以去访问;共享内存就比如每个部门内的打印机一样,只能自己部门的是人使用;寄存器和本地内存就比如每个员工自己的办公桌和电脑一样,只能自己使用。
- 理解GPU中各个内存的作用和范围,才能更好的优化GPU算法。
五、CUDA术语
- Host,即主机端,通常指CPU端(采用ANSI标准C语言编程)
- Device,即设备端,通常指GPU端(数据可并行,采用ANSI标准C的扩散语言编程)
- 上文也讲过,Host和Device拥有各自的存储器,因此,CUDA编程包括两部分,一部分是主机端的代码,另一部分是数据并行执行的设备端代码。
- Kernel,又称核函数,它是在GPU端执行的数据并行处理函数,kernel函数设计算法的不同,在性能上会有很大的区别,因此,只有设计出最优化的GPU核函数,才能充分利用GPU的资源。
六、CUDA编程模式
int main(void) { //1.确定数据分块方案,确定网格大小,块大小 //2.定义CPU和GPU端数据变量 //3.cudaMalloc函数为GPU端变量分配内存大小;malloc函数为CPU端变量分配内存大小 //4.初始化CPU端变量 //5.cudaMemcpy函数将CPU端数据变量拷贝到GPU端变量 //6.kernel函数(核函数名<<<网格配置,块配置>>>(参数变量)) //7.cudaMemcpy函数将GPU端计算结果数据拷贝到CPU端 //8.cudaFree函数释放GPU端变量内存,free释放CPU端内存 }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上面第1和第6步是设计高效CUDA程序的关键。
七、CUDA函数声明

- 以__global__关键标识的函数,是GPU代码的入口函数。
- __global__和__device__函数应注意以下几点:1.尽量少用递归;2.不要用静态变量;3.少用malloc;4.小心通过指针实现的函数调用。因为,GPU端带的代码都是大量线程同时并行运算的,一不小心就可能导致内存溢出或者指针混乱等。
八、CUDA内存传输(模型)
CUDA中CPU和GPU有各自独立的存储器,CPU通过GPU中的全局内存、常量内存和纹理内存与GPU进行数据传输,以下是CUDA进行数据传输的接口:
- cudaMalloc(),在设备端全局内存上分配内存,示例如下:
float *MD
int size = dataSize * sizeof(float)
cudaMalloc((void**)&MD, size)
- 1
- 2
- 3
- cudaFree(),释放在设备端申请的内存,示例如下:
cudaFree(MD)
- 1
- cudaMemcpy(),内存数据传输,示例如下:
cudaMemcpy(MD,MH,size,cudaMemcpyHostToDevice);//将CPU端的数据变量MH拷贝传输到GPU端变量MD上
cudaMemcpy(MH,MD,size,cudaMemcpyDeviceToHost);//将GPU端的数据变量MD拷贝传输到CPU端变量MH上
- 1
- 2
九、块内线程同步
- 块内的线程都是同步执行,如果需要块内所有线程都执行完成后,再执行下一步指令,就需要用到块内同步技术。
- CUDA编程中块内同步使用__syncthreads函数,该函数会阻塞一个线程执行该函数下面的语句,直至所有的线程都执行到该函数。示例代码如下:
MDs[i]=MD[j];
__syncthreads();//直到所有的线程都执行到这条语句,才继续执行该语句的吓一跳指令
func(MDs[i],MDs[i+1]);
- 1
- 2
- 3
- 对于线程同步要注意防止线程死锁的问题,如下代码示例,有可能导致if等不到else,else也等不到if,导致死锁
if(someFunc())
{
__syncthreads();
}
else
{
__syncthreads();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
十、上下文存储空间
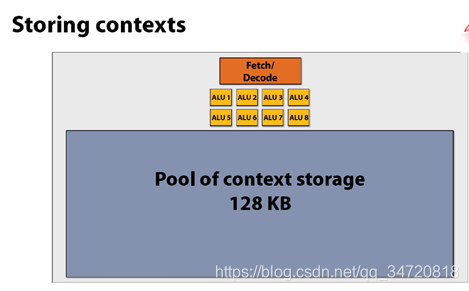
上下文存储池中的内存被分隔为越多的小上下文(执行任务),越有利延迟掩藏。什么是延迟掩藏?就是让一个计算单元不能闲着,在一个计算单元中事先放置很多的任务,一件任务不能做,就给换另一件任务做,直至最后计算单元一刻不停的将所有任务都做完。
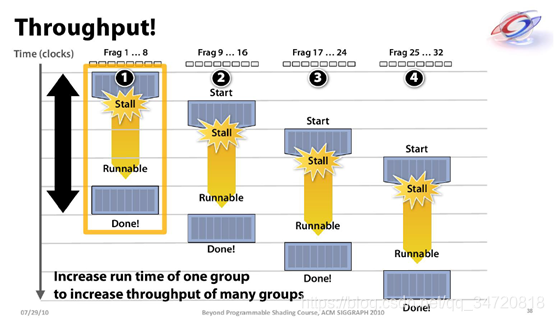
延迟隐藏就好比公司里的老板,老板总不希望一个员工有任何闲着的时候, 如果老板让员工去去取快递,员工说快递还没到;这种情况下,老板会说那你先去把技术报告整理一下发我;如果员工说,电脑还没开机,那老板可能说,你先擦擦桌子;等等等等,总之,不停的给你任务,不会让你闲着,这就是延迟隐藏,通过不停的切换任务,让计算单元一直在计算状态中。

如上图,第一个任务不能做的时候,去做第二个任务,第二个任务也不能做的时候,那就去做第三个任务,第三个任务还不能做,那就去干第四个任务,第四个任务还不能做,也许第一个任务就能做了,依次类推,达到block不会闲着无事可做的状态。

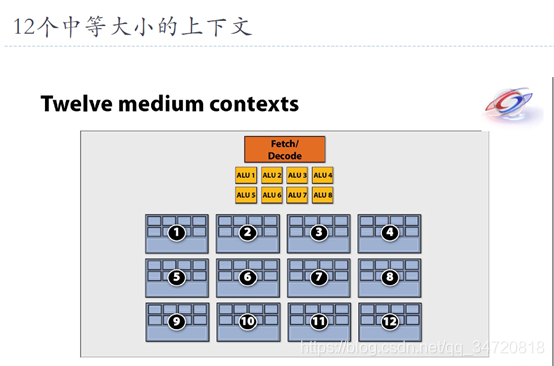
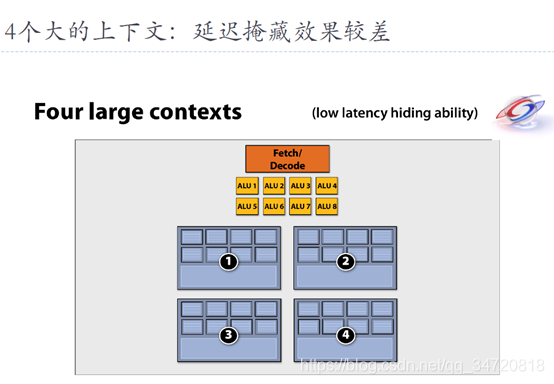
十一、线程调度
1.根据硬件的参数,应该要计算出CUDA中线程的组织情况。如GT200的GPU:
- 30个SMs
- 每个SM包含8个SPs
- 每个SM驻扎多达8个block或者1024个线程
- 因此同时执行的block最多为30 * 8=240个;同时执行的线程最多为30 * 1024=30720个
2.线程调度的基本单位是warp,warp是块内的一组线程,每个warp由块内32个连续的线程组成,warp运行与同一个SM上,且每个warp内的线程执行同样的指令。如果warp内部线程沿不同分支执行,会导致线程串行执行,如下图所示案例,只有x>0的情况处理完成后,处理x<0的线程才会执行。
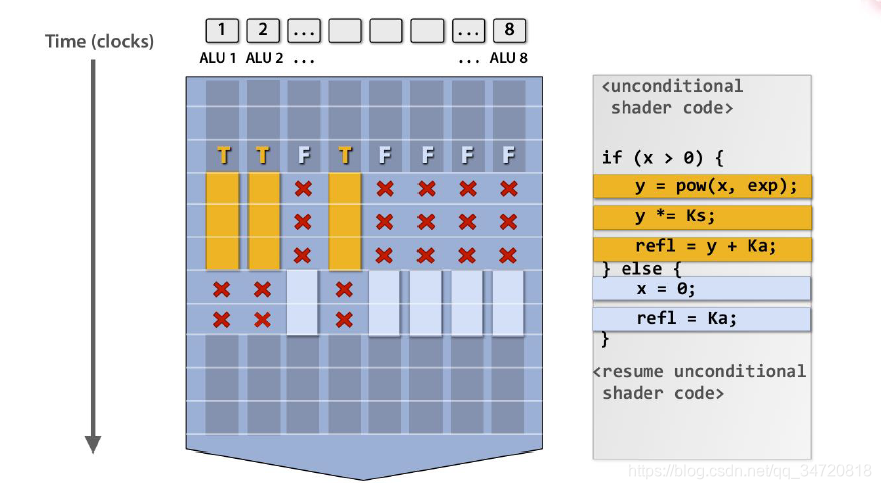
3.每个warp含32个线程,但如果每个SM只有8个SPs,如何分配SP来执行各个线程相应的指令?
- 分配方案如下:
- 首先每个线程上的指令已经预备
- 在第一个时钟周期,8个线程进入SPs
- 在第二、三、四个周期再各进入8个线程
- 因此,分发一个warp需要4个时钟周期
4.来几道计算题
- 如果一个SM分配了3个block,其中每个block含256个线程,总共有多少个warp?答:256/32*3=24个warp;
- GT200型号的GPU中,一个SM最多可以驻扎1024个线程,相当于多少个warp?答:1024/32=32个warp
- 一个kernel包含1次对global memory的读写操作(200 时钟周期)以及4次独立的加减操作(每次操作需要4个时钟周期),那么需要多少个warp才可以隐藏内存延迟?答:每个warp包含4次加减操作,需要4*4=16个时钟周期,我们需要覆盖200个读取数据时钟周期,因此需要200/16=12.5个warp,向上取整,即需要13个warps。
十二、内存模型
1. 寄存器Registers
- 每个线程有专用的寄存器,它的读写速度最快,内存大小一般很小。
- 对于G80型号的GPU而言,每个SM有多达768个线程,每个SM有8k(1k=210=1024)个的寄存器,因此每个线程可以分到8k/768=10个寄存器。
- 如果每个寄存器分配超过10个寄存器,那么线程数将因为block的减少而减少。例如,每个线程用到11个寄存器,并且每个block包含256个线程
- 那么一个SM可以驻扎多少个线程?答:一个block有256个线程,那么768个线程,共有768/256=3个block;但是因为每个线程需要11个寄存器,那么768个线程需要768*11=8448个寄存器,但实际只有8192个寄存器,因此,只能装配2个block,用到256 * 2 * 11=5632个寄存器,剩余的2560个寄存器因为不够装配一个block(装配一个block需要256 * 11=2816个寄存器),只能空闲着,这就造成资源浪费。
- 那么一个SM可以驻扎多少个warp?答:一个SM共有2 * 256 = 512个线程,每个warp包含32个线程,因此一个SM可以驻扎512/32=16个warp。
2. 局部存储器Local Memory
局部寄存器实质上是存储于global memory,因此,读写速度慢,作用域是每个线程,通常用于存储自动变量数组。
3. 共享存储器Shared Memory
- 每个block上都有自己的共享内存,它读写速度快,内存大小一般很小。
- 以G80为例,每个SM包含多达8个blocks,16KB共享内存,那么每个block分配多少KB的共享内存?答:16/8=2KB
- 但如果每个block用5KB,一个SM可以驻扎多少block?答:16/5=3个。block数目的减少将导致可用线程数的下降,造成资源浪费。
4. 全局存储器Global Memory
全局存储器可被所有block读写,并且可被Host读写,内存容量大,但是其读写速度慢,延时长(大概100周期左右)
5. 常量存储器Constant Memory
常量存储器,短延时,高带宽,当所有线程访问同一位置时只读;存储于global memory但是有缓存;Host主机端可读写;内存容量小,大多64KB
十三、CUDA程序优化
CUDA程序优化需要兼顾两个方面才能达到最优性能。一个方面是有效的数据并行算法,另一个是针对GPU框架特性的优化。
1. 基本优化
1.1 warp分隔
- Block被划分为以32位单元的线程组称为warp,即一个Block有多个warp组成,warp是最基本的调度单元,它一直执行相同的指令(SIMT),每个线程只能执行自己的代码路径。Fermi SM 有2个warp调度器,其它们之间切换没有时间代价,许多warp在一起可以隐藏访存延迟(一个warp停滞,其它warp可以继续处理其它指令)
- warp分隔的原则是threadIdx连续增加的一组形成一个warp。
- 一维Block warp分隔原则:第n个warp的起始线程ID为32n,结尾线程ID为32(n+1)-1。如果块大小不是32的倍数,最后一个warp将被填充(填充的线程并不执行任务,仅仅占个位置而已,导致最后一个warp的并行度下降)

- 二维Block warp分隔原则:增长threadIdx.x,始于行threadIdx.y==0,然后依次展开为一维,再按照一维的原则进行warp分隔,如下图
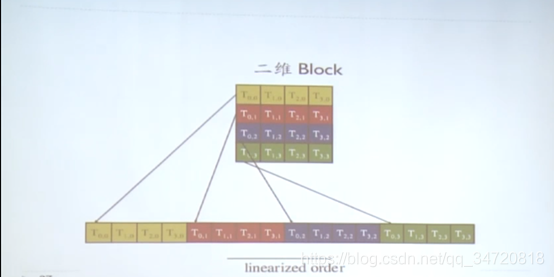
- 三维Block warp分隔原则:始于threadIdx.z=0,分隔为二维Block,再按照二维Block的分隔原则进行warp分隔,重复增长threadIdx.z
- 根据以上warp分隔原则,在实际编写核函数的时候,应尽量保证线程连续增长,这样保证每个warp能够尽快完工;不要出现以一定步长或者随机乱跳使用线程,这样会使得很多warp被占用而不能完工,但实际上每个warp内的线程又没有全部被利用上,造成资源浪费,性能降低。
1.2数据预读
在一次global memory 读操作和实际用到这个数据的语句中间,插入独立于以上数据的指令,可以隐藏访存延迟。示例如下:
float m = Md[i];//数据预读
float f = a * b * c;//中间执行独立语句,掩藏m读取的时间
float f2 = m * f;//在此之前已经预读m
- 1
- 2
- 3
1.3指令吞吐量优化
CUDA中有些指令的疏忽也会造成程序的性能下降,如为float常量添加f(10.0f)可以避免float自动像double类型转换;CUDA还提供两种运行时数学库函数,func()精度高,速度慢,__func()精度低,速度快,如sin(x)的精度高,计算速度慢, __sin(x)的精度低,但计算速度快。
1.4循环展开




2. 存储优化
2.1 CPU与GPU数据传输最小化
- Host<—>Device数据传输带宽远低于global memory;因此应该尽量减少传输(中间数据直接在GPU分配、操作、释放;有时更适合在GPU进行重复计算;如果没有减少数据传输的话,将CPU代码移植到GPU可能无法提升性能);组团传输(大块传输好于小块);内存传输与计算时间重叠(双缓存,即一边计算一边读取)
2.2 Global Memory合并访存
-
就是global Memory规则访存,一个线程访问对应索引数据,相邻线程访问相邻数据,这样访问全局内存,才会获得最优的访存性能。合并访存如下图所示:

-
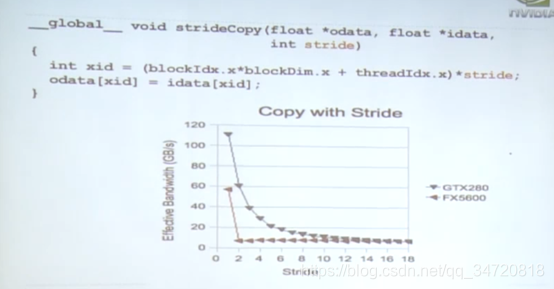
如果每个线程访问数据出现偏移或者步长,则会造成带宽性能下降,下图是偏移为1的线程访存示例

由下图可以看出,偏移会导致带宽性能有所下降

-
下图是以步长为2跳动访问内存示例

由下图可以看出,以一定步长跳动访问数据,会是带宽性能急剧下降
2.3 使用共享内存(shared memory)来解决不能合并访存的问题
- 对于一些必须以一定步长跳动访问数据的情况,如何降低其带宽性能低的情况呢?可以通过Shared memory避免。
- 共享内存比全局内存访问要快上百倍;可以通过缓存数据减少全局内存的访问次数;并且线程可以通过共享内存进行协作,因为共享内存被块内所有线程共享和相互通信。因此,可以用来避免不满足合并条件的访存(读入共享内存重新排序,从而支持合并寻址)
2.4 减少共享内存(shared memory)中的bank冲突
- 共享内存被划分为很多连续的bank,每个bank大小为32bit=1byte;
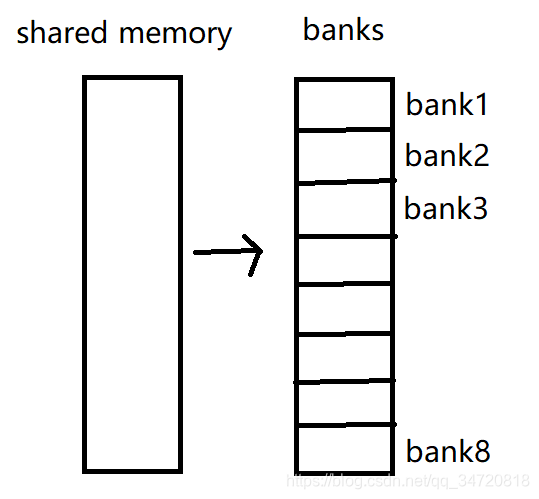
- 每个bank每个周期仅可以响应一个地址
- 对同一个bank进行多个并发访存将导致bank冲突,造成并行线程串行化,即多个线程只能一个一个访问该bank
- 下图是没有bank冲突的示例
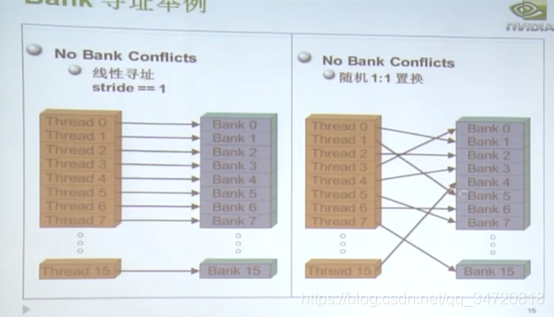
- 下图是有2路和8路bank冲突的示例
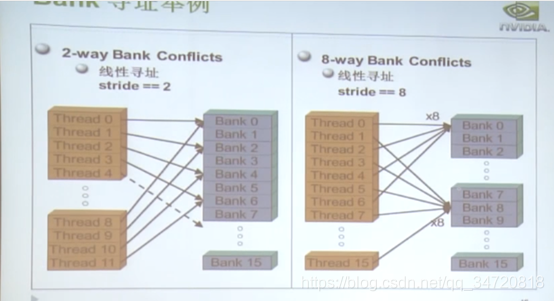
3. 总结
如果遵循一些简单的原则,GPU硬件在数据可并行计算问题上,可以达到很好的性能:
1.有效利用并行性
2.尽可能合并内存访问
3.合理高效的利用shared memory
4.减少bank冲突
十四、设计并行处理程序和系统


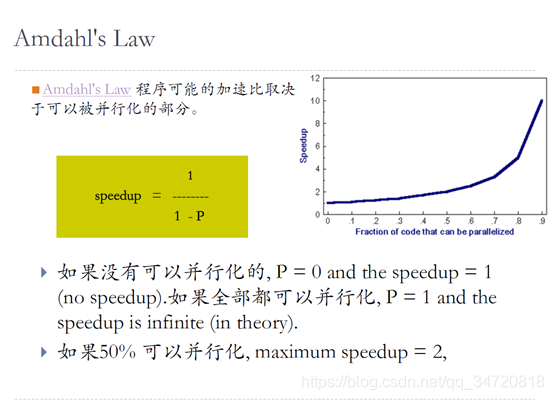

并行化的可扩展性有极限,及达到极限后,无论你的物理核数再增加多少,并行效率不再提高



