
- 1在Python中使用pyecharts图形画可视化大屏_使用代码制作大屏
- 2桥接模式_抽象与现实分离怎么理解
- 3排序篇(叁)终篇
- 4python3-python中的GUI,Tkinter的使用,抓取小米应用商店应用列表名称_python 获取安卓app界面名称
- 5互斥锁(下):如何用一把锁保护多个资源?_不同变量保护 互斥锁
- 6SpringBoot 实现数据加密脱敏(注解 + 反射 + AOP)_springboot字段加密解密
- 7PostgreSQL pgvector:如何利用向量数据库提升搜索效率和精度_pgsql vector
- 8Git只克隆远程仓库的某一个目录或文件_git可以克隆项目中的一个文件夹吗
- 9Android基础教程(非常详细)从零基础入门到精通,看完这一篇就够了_安卓开发需要学什么
- 10ERROR: JAVA_HOME is not set and could not be found._javahome is not set and could not be found
大模型并行推理的太祖长拳:解读Jeff Dean署名MLSys 2023杰出论文
赞
踩
©作者 | 方佳瑞
单位 | 腾讯
研究方向 | 机器学习系统
来自 | PaperWeekly
听名字就知道,这个会代表了美国 MLSys 的最核心圈子,会议的发起人 Jeff Dean、Fei-Fei Li、Eric Xing、Alex Smola 都来自的 Google、Meta 这些硅谷科技巨头和 UCB、Stanford、CMU 这些老牌系统强校的巨佬。鉴于现在大模型技术还是美国主导的,MLSys 一定程度上也代表着先进生产力的前进方向和最新的思潮发展方向。
今天我们一起来学习一下 MLSys 中关于大模型推理的重量级文章。链接如下,它也是三篇 Outstanding Paper Award 之一,Jeff Dean 尾作署名。

论文标题:
Efficiently Scaling Transformer Inference
论文链接:
https://proceedings.mlsys.org/paper_files/paper/2023/hash/523f87e9d08e6071a3bbd150e6da40fb-Abstract-mlsys2023.html
去年 Dean 署名的文章是 Pathways,也是 22 年的 Outstanding Paper之一。我感觉 Dean 署名论文投稿 MLSys 就类似《求是》杂志发表咱们大领导的文章,起到给全美的 MLSys 工作定调子的作用。言外之意类似:2022 年一整年,经过全美各企业和科研院校的辛勤努力,大模型训练系统研发已取得重要成果。如今,备受瞩目的焦点已转向推理优化。在新的一年里,希望全美各界再接再厉,踔厉奋发,进一步提升推理效率,努力谱写通用人工智能技术的发展新篇章!
推理优化不学此雄文,十倍加速也枉然。可是当你通读此文后,也许会些许失望。文章不就是讲怎么做模型并行么,说的我好像早就知道,没什么花哨的想法,也没什么神奇的结果。话说,金庸小说《天龙八部》有一个片段,天下英雄齐聚聚贤庄和乔峰比武,乔峰打出一套太祖长拳,就折服武林众高手。太祖长拳别成“大宋广播体操”,在宋朝人人皆会,太祖拳法的精要,可说是无人不知。可是乔峰太祖长拳的一招打出,各路高手都还是情不自禁的喝了一声采!同理,这篇文章的效果就好比乔帮主的太祖长拳。
这篇文章好就好在它的朴素直接。常言道,有钱人的生活就是这么朴实无华且无趣,当其他文章争奇斗艳,拿锤找钉,欲盖弥彰地讨好审稿人博出位的时候,一篇文章只告诉你最朴素的道理,只给你最直接结论,如此存粹的文风就像一缕清风,一股清泉让此时此刻的你在这尔虞我诈的花花世界中得到了片刻的安宁。这也是这篇文章美学艺术之所在。
下面咱们进入正式解读部分。

背景
对于 100B+ 规模的稠密大模型(LLM),即非 MoE 结构的 Transformer 模型,其推理实现是极其具有挑战的。比如,在线服务 540B 的 GaLM 的成本是极其高,如果不能把它的成本控制在一定范围内,即使 Pathways 训练出模型也没法普惠到客户,这是 Google 内部遇到的具体问题。
LLM 推理应用的需求有可分两类:1. 在线推理,比如聊天机器人交互式的,需要非常严格的延迟约束,为了这个目标放松成本限制。2. 离线推理,包括用于 Rewards Model 或蒸馏的离线推理任务。它强调高吞吐量和低成本,延迟反而不重要。
大模型推理可以分解为处理 prompt 的的阶段(prefill)和自回归生成输出标记解阶段(Decoding)。二者性质不同,前者是计算密集型的,后者是访存密集型的。尤其是,Decoding 阶段以难以优化而臭名昭著。因为每次只能解码一个 token,计算量本来就很小,还需要访问一个随着解码步数增加而不断累计 KVCache,因此严重受限于加速卡的片上带宽。
由于参数巨大,单个加速卡内存肯定存不下 100B 级别的模型,因此并行推理成为必选项。尤其是对于第一类任务,希望满足推理延迟,必须增加加速卡数目,来提升整体算力和带宽。
推理工程优化是一个多层次、模块化的系统工程。需要算子优化、量化加速、并行策略、内存管理、Batching 策略、Decoding 方法、甚至结合模型改动一起,链路非常长。而本文关注并行策略部分。
它提供一套 engineering principles,来指导 Transformer 结构推理并行策略的优化,从而帮助我们找到在模型大小和特定应用需求下经验性地推到出最佳模型的并行策略。简单来说,将大家脑子中对并行这块多多少少有的模糊概念落笔成文,进行了系统性地阐述,并给出了 Google 一手的实验数据。

方法
在 LLM 推理应用时,我们需要考虑三个指标,延迟、吞吐和成本。延迟就是端到端完成一次推理时间,包括 prefill+decoding两个阶段的延迟总和。吞吐就是单位时间可以处理多少 tokens。成本就是用多少机时,大家常说的 MFU(Model Flops Utilization)指标和成本挂钩。这些指标往往互相矛盾,比如要达到低延迟,可能导致不能打出大 Batch 从而造成低吞吐,也可能需要加芯片导致高成本。
面对这些实际问题,在不同的 Batch Size,模型尺寸,芯片数目情况下,最优的模型切分策略应该是不同的,本文会给一些经验性的结论,比如下面这幅图 Figure 1。图中每条线上的点表示成本与延迟二元目标优化的 Pareto frontier,不同颜色表示不同大小的模型。因为 Decoding 和 Prefilling 的计算性质不同,需要分开观察。左图:Decoding 生成 64 个 token 平均延迟情况。右图:处理 2048 个输入 token Prefilling 的总延迟。Chip count 是 C, batch size 是 B。
这幅图就像手册一样,比如我们可以根据延迟需求,查找最少成本的 B、C 的值和模型类别,从而配置相应地去配置我们的推理服务。一些应用实例:对于 540B 参数的 LLM,在 64 个 TPU v4 芯片上运行时,我们在生成过程中实现了每个标记 29 毫秒的low-batch-size延迟,并在 large-batch-size 处理输入标记时实现了 76% 的 MFU。实现了离线在线应用的两开花的目的。
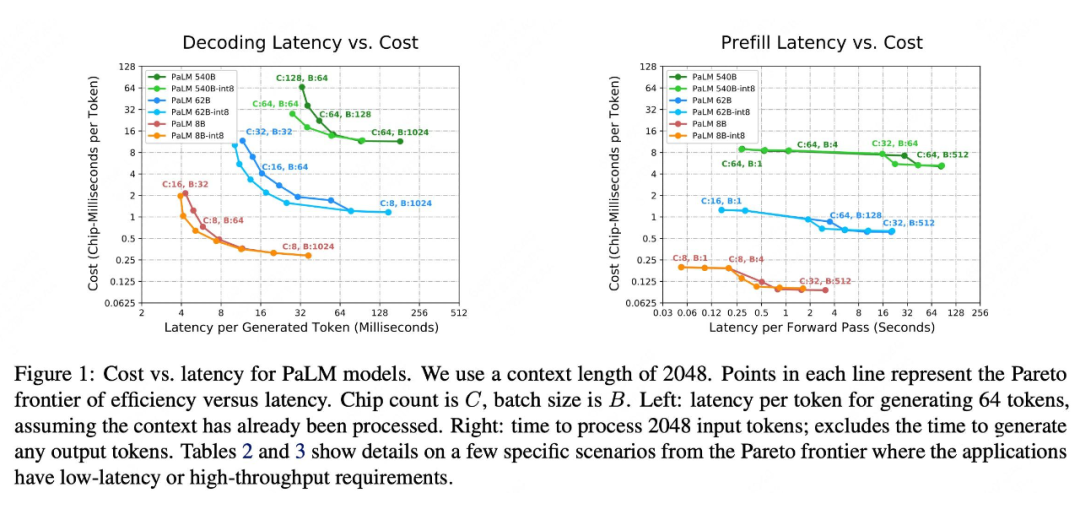
而想做出上面这两幅图,还需要一样法宝,如何对给定 B、C 和模型类别,选择最优的并行策略实现。这也是本文大篇幅讨论的内容。本文提出一个 Partitioning Framework 解决此事。
1. 符号化抽象
Partitioning 就是 Tensor Parallelism。首先,对多个 TPU 组成的硬件集群,可以抽象成一个 N-D 的 device mesh,和 UCB alpa 论文 [1] 里的 device mesh一 样。稍微特殊一点在于,在 TPU v4 集群里,由于网络硬件是 3D torus topology ,非常适合抽象成 X×Y×Z 形式的 3D mesh。
现过一下模型张量维度命名规则:Transformer 模型的(或 embedding)维度为 (或 E),FFN 中间层维度为 (或 F),一般 F=4*E,注意力头数为 (或 H),L 来表示序列长度。
本文最出彩的地方表示并行策略的抽象符号体系。符号化抽象对一套理论的普及至关重要,一个例子是牛顿和莱布尼茨同时发明了微积分,他们独立地发展了微积分的基本原理和符号体系。牛顿使用的是差分法和流数法,而莱布尼茨使用的是微分法和积分法。莱布尼茨提出的微分法和积分法更加简洁、直观且易于使用,所以成为现在的主流。
怎么表示模型并行呢?本质是表示 tensor layout 和 device mesh 的映射,目前有如下几种主流符号体系:
(1)Megatron-LM 式 [2],把矩阵切分写成行列式方式,[Y1, Y2] = [GeLU(XA1), GeLU(XA2)] 表达 row-wise split。表达 1D device mesh 很适合,但是对更复杂的 device mesh 则捉襟见肘。不过 GPU 集群通常 NVLink+IB,3D device mesh属于长尾需求。
(2)oneflow 式 [3],使用 SBP signature,用字母(数字)形式表达并行,字母表示 Tensor layout 方式,括号内数字表达 device mesh 的维度。比如 column-wise TP 矩阵乘表示:(S(0), B) (B, S(1))->(S(0), S(1))。这套体系对 N-D tensor->N-D device 映射还不是很直观。
(3)GSPMD 式 [4],使用一个数组 dims_mapping 表示 tensor->device mesh 映射,devich mesh 不同维度在 dims_mapping 中应该最多出现一次,数组中 -1 表示不存在的映射,它可以表示 tiled, partially tiled, and replicated sharding。尽管这套符号体系支持 N-D mesh 了,但是它真的非常非常抽象,战鹰可以做它的代言人。曾经有一位做 DL 框架 N 年资深巨佬看了半个小时也没看明白原始论文图 1 的意思。
在 GSPMD 基础之上,本文改进了一下它的符号体系,兼顾了直观性和表达能力。通过以下规定表达一个张量的分布式的 layout:
(1)Shard 表示:使用下标来指定被 shard 的张量维度。例如,符号 表示逻辑形状为 BLE 的张量的最后一个维度 E 被分割成 X × Y × Z 个分区,其中 x、y 和 z 表示物理 TPU v4 轴,每个芯片的张量形状为 [B, L, E/(X × Y × Z)]。
(2)Replicated 表示:如果一个张量在轴x上被replicated存储,那么该轴将在符号中被省略。
(3)Partial 表示:后缀 “partialsum-x” 来表示给定的张量已经在每个芯片上 locally 地进行了处理(concate 或 sum),但仍需要在 TPU x 轴上对芯片进行求和才是最终结果。
MPI 式的集合通信可以改变 tensor 分布式的 layout 方式。有关 MPI 集合通信意义可以看我的这篇文章 [5]。我们记住如下规则:allreduce 可以消掉一个 partialsum-x 的下标;allgather=concate,消掉任意一个表示 shard 的下标;reduce-scatter=sum+shard,消掉 partialsum-x 在任意位置增加一个下标;all-to-all= 转置,可以把下标换位置,比如实现 → 。这样,MPI 的集合通信,就可以改变下标的有无和位置,从而实现不同的 layout 转换。
显而易见,all-reduce(x) 作用于 (partialsum-x) 得到 的输出。我们做一个简单的练习,通过 ReduceScatter+Allgather 实现上述操作。
解:Allreduce=ReduceScatter+Allgather。ReduceScatter 相当于sum+shard,reduce-scatter(x) 作用于 (partialsum-x),首先 sum 消掉 x 维度得到 ,之后 shard 可以作用于 B 或者 E 上,得到 或 。allgather(x) 相当于 concate,可以消掉 x 下标,得到 。
因为 reduce-scatter(x),all-gather(x) 这些操作有对应的通信量公式,可以方便计算出并行推理的通信开销。有了这套符号体系,和 MPI 的运算规则,咱们可以看懂论文中的图了。
2. FFN并行方法
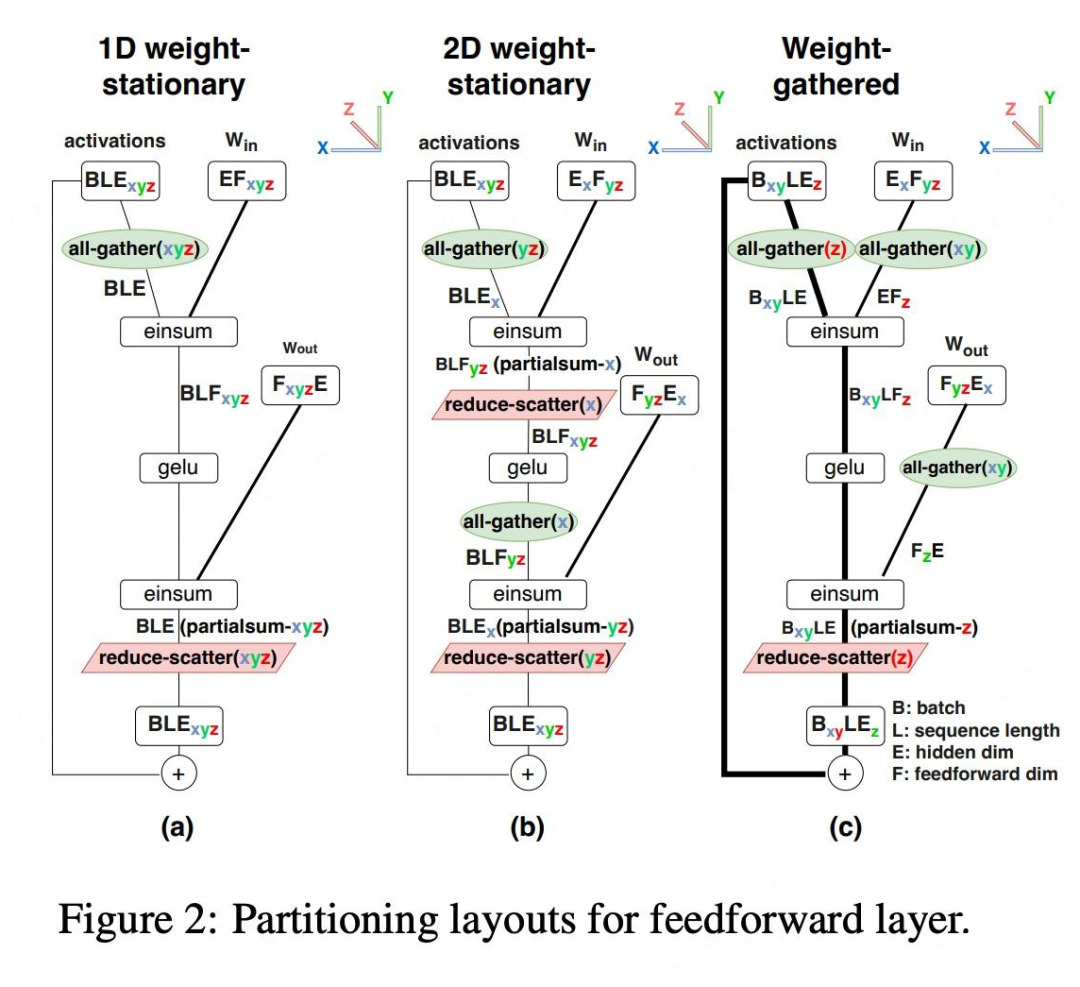
比如 FFN 的两个 Linear 层有三种 Partition 方法,如下图所示,它们的名字分是 1D weight-stationary,2D weight-stationary 和 weight-gather。
1D weight 就是 Megatron-LM 中的 FFN 并行方法,用一个 column-wise+row-wise TP,forward 只需要 Allgather+ReduceScatter 两次通信。
后两者大大家不常见,它对 weight 的两个维度都进行 partition,对 2D 对 activation 最低维度切分,weight-gather 则对最低和最高维度分别切分。值得注意的是,作者对 L 维度没有切分。
3. Attention Layer并行方法
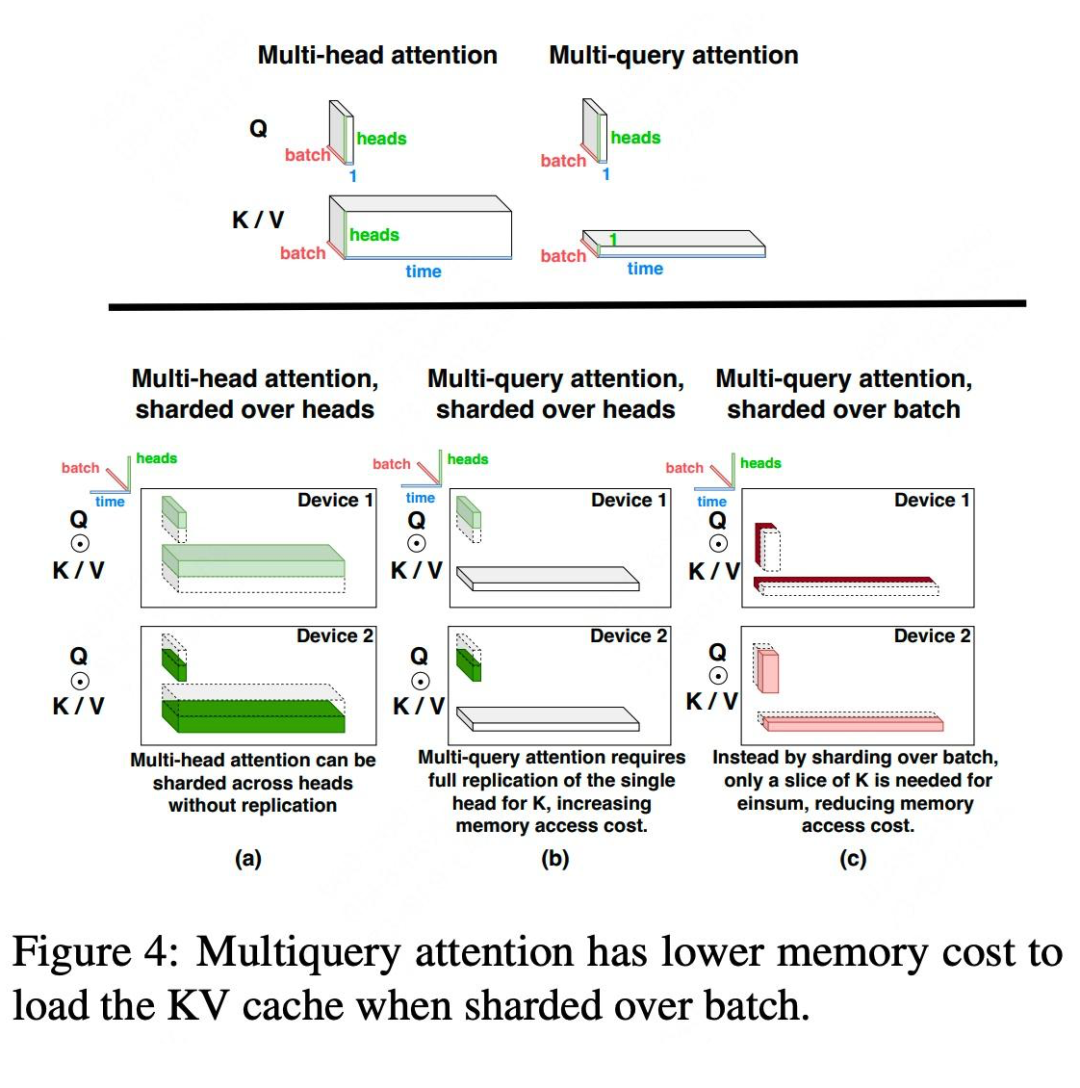
作者设计了针对经典的 MHA(multihead attention)和改进的 MQA(multiquery attention)的并行方案,后者多头共享参数,可以减少 KVCache 读取带宽需求,但是给并行策略设计造成一些麻烦,因为少了 head 维度切分的选择。如 Figure 4 所示,MQA KV Cache 没有 head 维度了。
MHA 的切分和 FFN Partion 类似,只是把 F 维度换成 H,参与切分。如 Figure 4(a)所示,可以只切 H 维度,和 Megatron-LM 类似。需要特殊处理的 H 不能整除处理器数的情况,对于处理器数量大于注意力头数的情况,注意力头部分 partially replicated。如下图 Figure 5(a)是 MHA 的并行方案细节。和 FFN 同行类似,都是等价于一次 AllReduce=ReduceScatter+Allgather。
MQA 的切分比较棘手,如果还切 H 维度,就是如 Figure 4(b)所示方案,K 和 V 张量在所有头部之间共享,但它们必须在每个芯片上市 replicated 的,这导致 MQA 的内存成本节省将会丧失。所以作者采用 Figure 4(c)切分,对 B 维度切分,不过这也要求任务能组比较大的 batch,有切分余地。
具体来说,Q、K 和 V 矩阵在批次 B 维度上分区为 N 个分区。Figure 4(c)显示,这将使每个芯片加载 KV 缓存的内存成本降低 N 倍,从而将访存也降低相同倍数。具体并行细节参考 Figure 5(b),与Figure 5(a)中 MHA 并行策略相比,MQA 需要使用 all-to-all 对进行输入输出激活张量 resharding,从而产生额外的通信成本。可见,MQA 减少了访存,但是增加了并行通信开销。
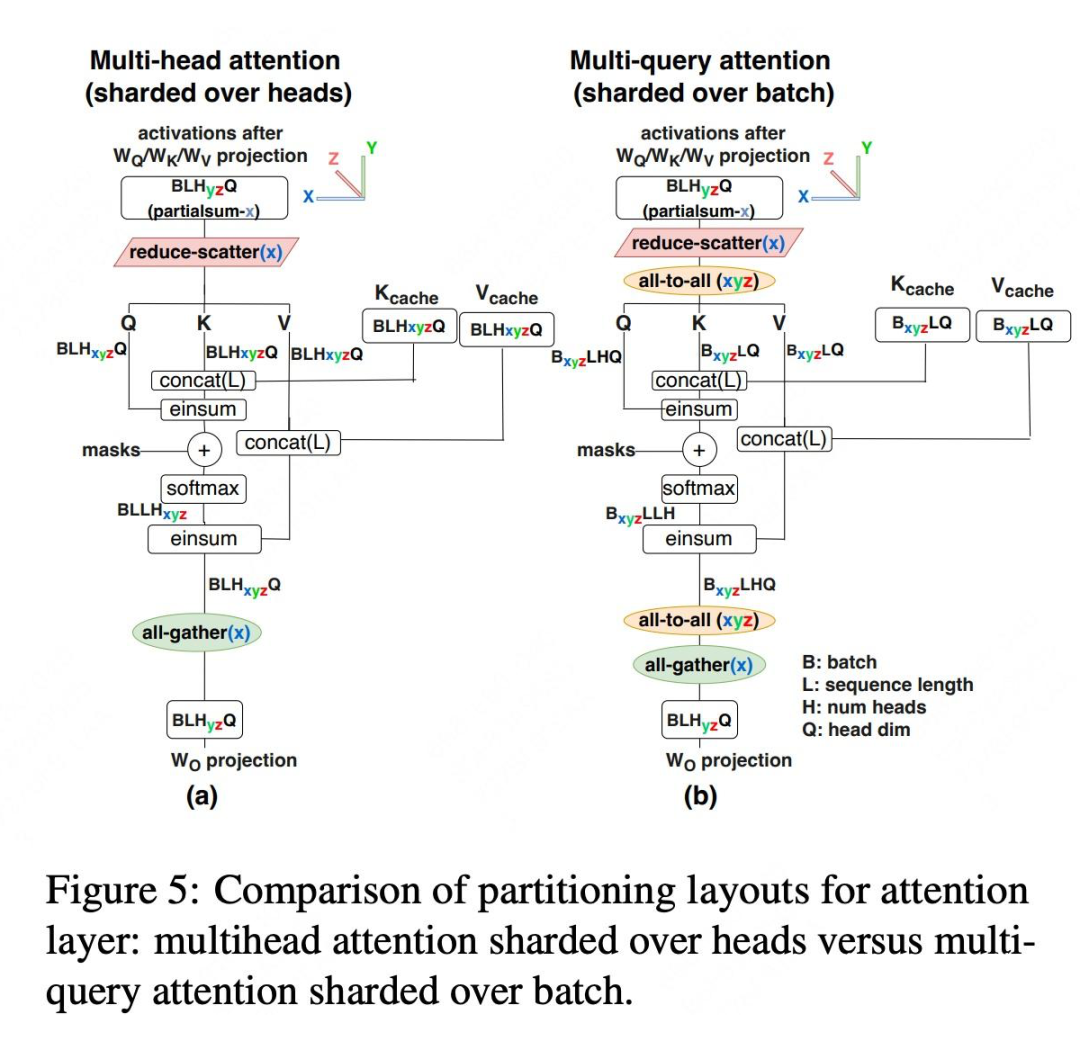
对 Figure 2 和 Figue 5 的五个 workflow,作者在原文中都给出了通信开销。让读者可以直观地感受到通信开销和芯片数量、B、L、E 三个维度的变化关系。建议读者使用时去查阅论文。
其他优化
出了并行策略,文章还有介绍了其他对超大模型推理有裨益的优化。
首先,模型结构微调。和 GPT 结构不同,PaLM 中 FFN 和 Attention Layer 是并行的。区别如下:
GPT: y = MLP(LayerNorm(x + Attn(LayerNorm(x))
PaLM: y = x + MLP(LayerNorm(x)) + Attn(LayerNorm(x))
PaLM 的方式有几个对工程优化的好处。第一,省掉一次 LayerNorm。第二, 有很多矩阵乘法融合增加 FLOPS 的机会了。FFN 的输入矩阵可以与 Attention 的 融合,Attn 的 KV 矩阵 和 可以融合,FFN 的输出矩阵可以与 Attn 的输出投影矩阵 融合。第三,也是对于并行最重要的,它还消除了每个 Transformer 层中用于 dff/nheads 并行性的两个全局归约操作中的一个,将沿着这个轴的通信时间减少了一半。
然后,还有一些 Low-level 优化。
比较值得关注的是 Looped CollectiveEinsum 技术,使通信与计算同时进行。这个技术发表在 ASPLOPS 23 上 [6],值得 highlight 一下,简单来说就是把矩阵乘法和通信分块流式起来,隐藏通信开销。
Google 作者声称这项技术使我们能够部分或完全隐藏 Figure 2和 Figure 5 中大部分 reduce-scatter 和 all-gather 操作的通信时间。因为有 Looped CollectiveEinsum 技术,所以作者对于 Figure 2 和 Figure 5 中的所有 reduce-scatter 操作,可以选择将其 reduce-scatter 到批次或序列维度(B 或 L)或隐藏维度(E 或 F),作者都选择了后者,因为它为循环 CollectiveEinsum 提供了更多有效的机会。
最后,还有内存和量化优化,这里按下不表了。

实验和结论
FFN如何并行结论:
在 Prefilling 阶段,我们根据 batch 中的 token 数量从 weight-stationary and weight-gathered layouts 中进行选择并行策略。在 Decoding 阶段,我们选择 2D weight-stationary,因为 token 的 batch 大小始终很小。
2. Attn如何并行结论:
在 Prefilling 阶段,MQA 和 MHA 产生类似的推理延迟,因为我们并行计算许多 attention queries,并且在注意力矩阵乘法上的计算是受限于计算能力的。
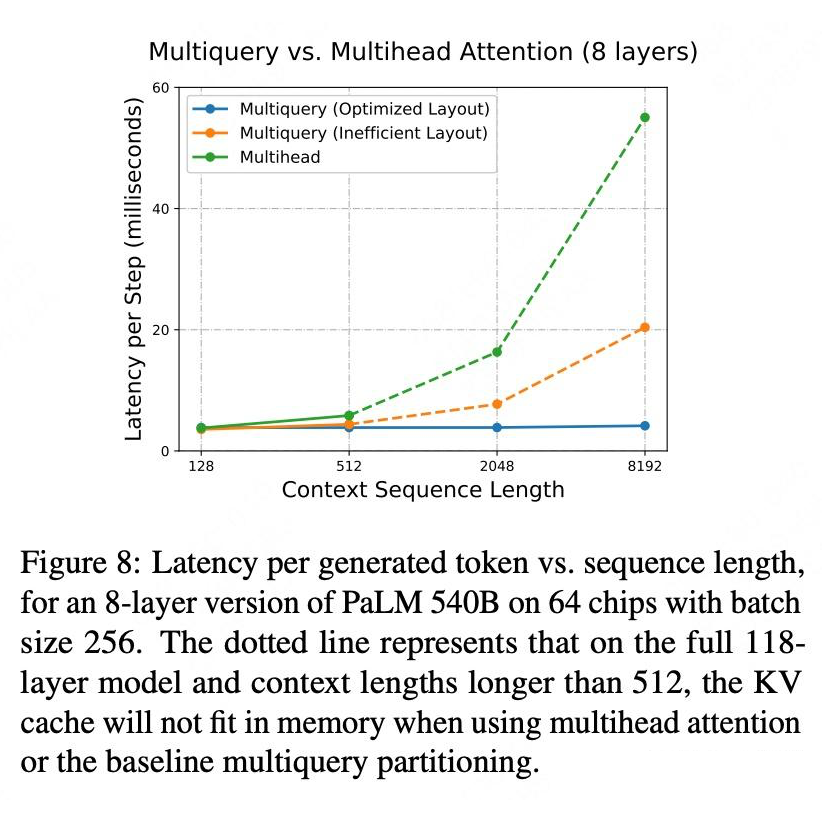
在 Decoding 阶段,MQA 只有一种并行方式了,所以也没得选了。优化的 MQA 布局 Figure 4(a)比 Figure 4(b)提升效率。当上下文长度较短时,速度提升较小,因为几乎所有时间都花在了 FFN 上。随着上下文长度变得更长,加载注意力层中的 KV 缓存所需的时间成为总体推理时间的很大一部分。MQA 可扩展到 8192-32768 个 token 的序列长度(分别为批次大小 512 和 128),attention 仅占总运行时间的 8-31%。如下图所示,MAQ 比 MHA 在长序列时候提升很多。
3. 模型结构微调效果:
在 540B 规模下,Decoding 阶段,串行公式每步的推理延迟比并行版本高 14%,这是主要因为激活的通信时间增加了。在 Prefilling 阶段,这种差异会缩小,因为权重聚集的布局会减少激活通信。
4. 端到端分析
回看 Figure 1,对于具体应用,本质上是在求解 Latency 和 Cost 作为目标的多目标优化问题。图中每一个点都是选择最佳的 FFN 和 Attn 并行策略的结构,我们抽出两个点具体看看,如 Table 2,3 所示。对于低延迟、高吞吐两种需求,Prefill 和 Decoding 两个阶段,最佳的并行策略都不同。

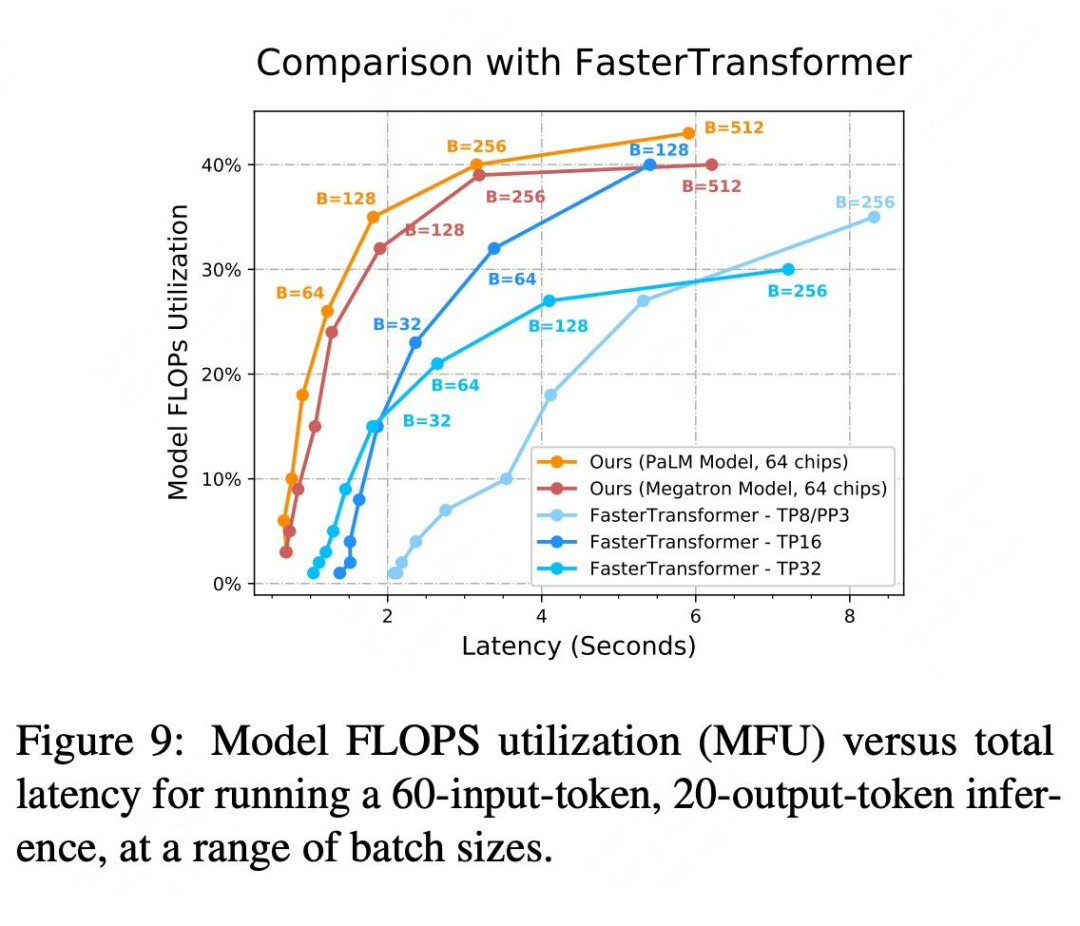
5. 和 FasterTransformer 对比
TPU+ 本文方法和 GPU+FasterTransformers,两套软硬件组合进行了对比。如 Figure 9 所示,大部分情况下,红色系线都优于蓝色系的线。

结论
本文系统性地阐述了稠密 LLM 模型并行推理的目标、方法和规律。在方法部分,比较亮眼的是作者一套简单、有力的符号化抽象,描述了 FFN 和 Attn 不同切分策略,并推导出通信的开销。作者给出了一些规律性的结论:1)Prefill 和 Decoding 的并行策略是不同的;2)Low Latency 和 High Throught场景下并行策略是不同的;3)MQA 和并行 Attn 和 FFN 的模型改进都是大有裨益的。文章里的图画的很精美,信息量很大,细节拉满,可谓一图胜千言之典范。
作者的方法和 Google 内部基建过于耦合,比如 3D Torus 网络更适合 3-D Device Mesh,一些结论在 GPU 集群上还有改变。另外,本文的工作还需要非常强大的 Batching 实现配合才能在真实业务中发挥作用。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


