
- 1教您如何三分钟搞定EasyExcel导入与导出功能_easyexcel 导出
- 2学习资源分享_kafka 核心技术与实战百度网盘
- 3php表白情话,情商高的聊天语句900句 表白情话最暖心一段话
- 4OAuth2与JWT的区别JWT的适用场景及好处(九)_jwt和oauth2哪个好
- 5Node.js -- 包管理工具
- 6【算法|贪心算法系列No.4】leetcode55. 跳跃游戏 & 45. 跳跃游戏 II
- 7Docker的网络模式之host模式_docker run --host
- 8Kafka核心技术与实战 15 消费者组
- 9Kimi创始人套现4000万美元疑云|「商汤」大模型一体机可节约80%推理成本,完成云端边全栈布局|中国AI活化石,熬成AIGC第一股| 谁在制造小米汽车?_商汤 kimi
- 10Unity 之 NGUI UIRoot 的屏幕适配问题_ngui 适配
Spark RDD的分区与依赖关系
赞
踩
Spark RDD的分区与依赖关系
RDD分区
RDD,Resiliennt Distributed Datasets,弹性式分布式数据集,是由若干个分区构成的,那么这每一个分区中的数据又是如何产生的呢?这就是RDD分区策略所要解决的问题,下面我们就一道来学习RDD分区相关。
RDD数据分区
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数。
分区的决定,就是在宽依赖的过程中才有,窄依赖因为是一对一,分区确定的,所以不需要指定分区操作。
1)Partitioner:在Spark中涉及RDD的分区策略的抽象类为Partitioner,其继承体系如图-27所示,有两个核心的子类实现,一个HashPartitioner,一个RangePartitioner。
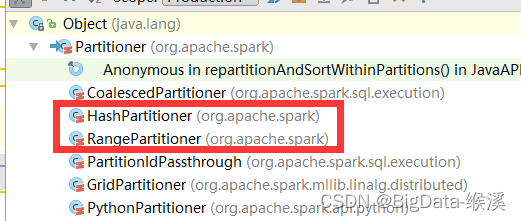
图-27 spark Partitioner继承体系
Spark中数据分区的主要工具类(数据分区类),主要用于Spark底层RDD的数据重分布的情况中,主要方法两个,如图-28所示:

图-28 Partitioner抽象类
2)HashPartitioner:Spark中非常重要的一个分区器,也是默认分区器,默认用于90%以上的RDD相关API上。
功能:依据RDD中key值的hashCode的值将数据取模后得到该key值对应的下一个RDD的分区id值,支持key值为null的情况,当key为null的时候,返回0;该分区器基本上适合所有RDD数据类型的数据进行分区操作;但是需要注意的是,由于JAVA中数组的hashCode是基于数组对象本身的,不是基于数组内容的,所以如果RDD的key是数组类型,那么可能导致数据内容一致的数据key没法分配到同一个RDD分区中,这个时候最好自定义数据分区器,采用数组内容进行分区或者将数组的内容转换为集合。HashPartitioner代码如下:
- def main(args: Array[String]): Unit = {
- val conf: SparkConf = new SparkConf().setAppName("demo").setMaster("local[*]")
- val sc = new SparkContext(conf)
- sc.setLogLevel("WARN")
- //加载数据
- val rdd = sc.parallelize(List((1,3),(1,2),(2,4),(2,3),(3,6),(3,8)),8)
- //通过Hash分区
- val result: RDD[(Int, Int)] = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
- //获取分区方式
- println(result.partitioner)
- //获取分区数
- println(result.getNumPartitions)
- }
RDD自定义分区
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略,这两种分区策略在很多情况下都适合我们的场景。但是有些情况下,Spark内部不能符合我们的需求,这时候我们就可以自定义分区策略。
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
1)numPartitions: Int:返回创建出来的分区数。
2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
3)equals():Java判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
案例一:模拟实现HashPartitioner。
- class CustomerPartitoner(numPartiton:Int) extends Partitioner{
-
- // 返回分区的总数
-
- override def numPartitions: Int = numPartiton
-
- // 根据传入的Key返回分区的索引
-
- override def getPartition(key: Any): Int = {
-
- key.hashCode()%numparts
-
- }
-
- }
-
- object CustomerPartitoner {
-
- def main(args: Array[String]): Unit = {
-
- val sparkConf = new SparkConf()
-
- .setAppName("CustomerPartitoner").setMaster("local[*]")
-
- val sc = new SparkContext(sparkConf)
-
- //zipWithIndex该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。
-
- val rdd = sc.parallelize(0 to 10,1).zipWithIndex()
-
- val func = (index:Int,iter:Iterator[(Int,Long)]) =>{
-
- iter.map(x => "[partID:"+index + ", value:"+x+"]")
-
- }
-
- val r = rdd.mapPartitionsWithIndex(func).collect()
-
- for (i <- r){
-
- println(i)
-
- }
-
- val rdd2 = rdd.partitionBy(new CustomerPartitoner(5))
-
- val r1 = rdd2.mapPartitionsWithIndex(func).collect()
-
- println("----------------------------------------")
-
- for (i <- r1){
-
- println(i)
-
- }
-
- println("----------------------------------------")
-
- sc.stop()
-
- }
-
- }

总结:
1)分区主要面对KV结构数据,Spark内部提供了两个比较重要的分区器,Hash分区器和Range分区器。
2)hash分区主要通过key的hashcode来对分区数求余,hash分区可能会导致数据倾斜问题,Range分区是通过水塘抽样的算法来将数据均匀的分配到各个分区中。
3)自定义分区主要通过继承partitioner抽象类来实现,必须要实现两个方法:numPartitions 和 getPartition(key: Any)。
RDD依赖关系
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
依赖关系
图-29是源码中的一张图,可以发现一个问题Dependency(依赖)的意思可以发现ShuffleDependency是其子类(即宽依赖),NarrowDependency是其子类(即窄依赖)。

图-29 Dependency体系
1)宽窄依赖:所谓窄依赖,指的是子RDD一个分区中的数据,来自于上游RDD中一个分区。所谓宽依赖,指的是子RDD一个分区中的数据,来自于上游RDD所有的分区。
宽窄依赖关系示例如图-30所示:

图-30 宽窄依赖示例图
2)血统Lineage:RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。关于linage说明示意图如图-31所示:
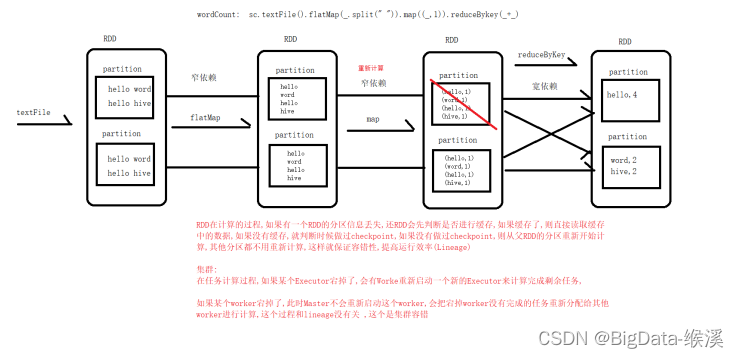
图-31 lineage示例图
3)DAG有向无环图:如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图。有向图中一个点经过两种路线到达另一个点未必形成环,因此有向无环图未必能转化成树,但任何有向树均为有向无环图。通俗的来说就是有方向,没有回流的图可以称为有向无环图,示意图如图-32所示。
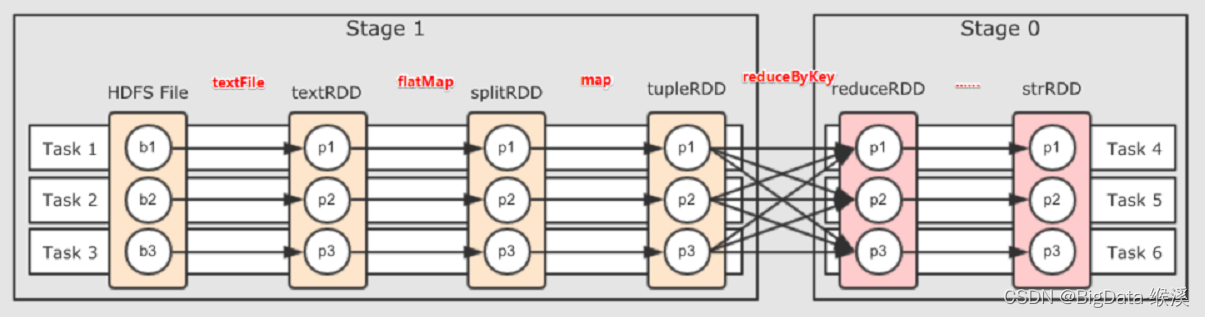
图-32 有像无环图
4)RDD任务的切分:对于RDD的任务切分,可以很形象的如图-33所示。
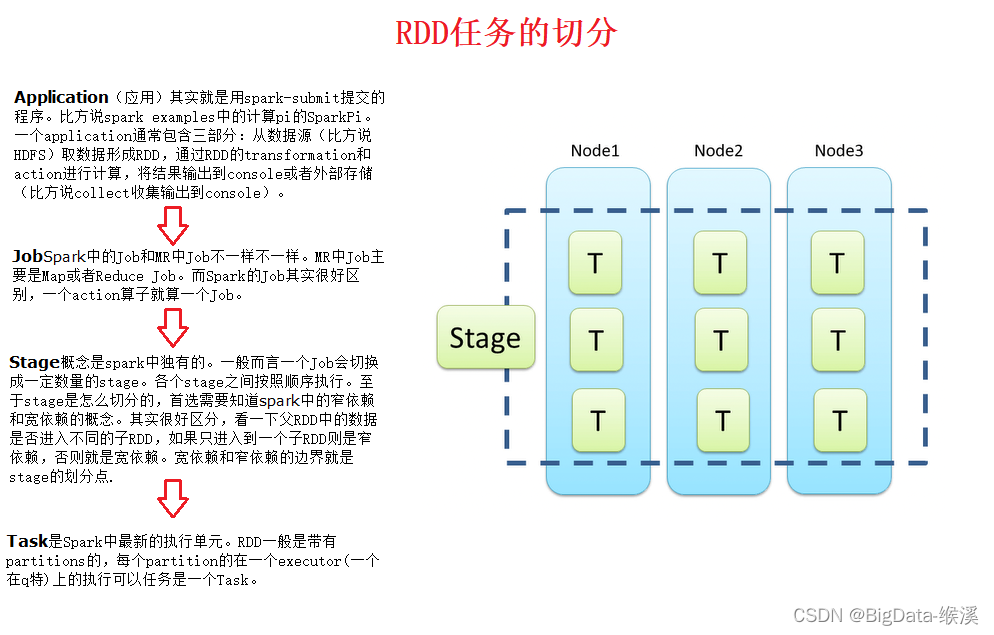
图-33 RDD任务的切分
并行度:程序同一时间执行作业的线程个数。
原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,如图-34所示。
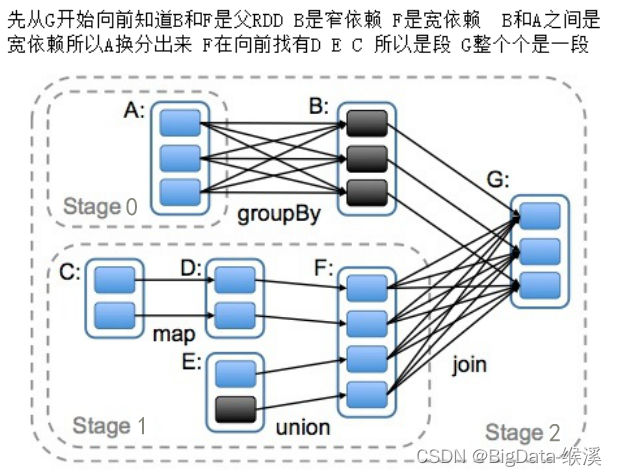
图-34 RDD stage的切分
对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的重要依据。Stage阶段计算过程如图所示-35所示。
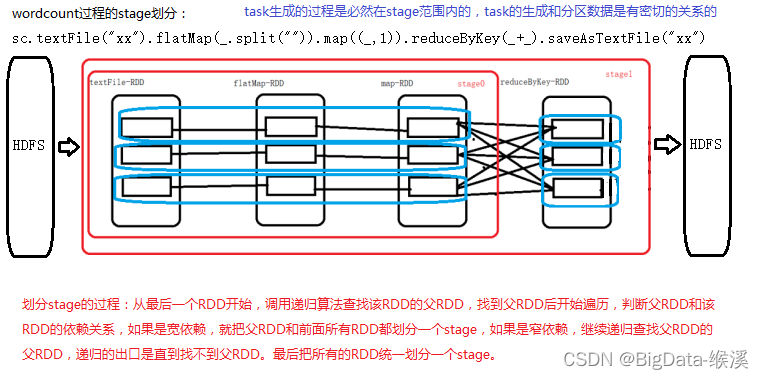
图-35 RDD stage阶段计算过程
任务生成和提交的四个阶段
Spark任务生产和提交的四个步骤可以归纳如下:
1)构建DAG:用户提交的job将首先被转换成一系列RDD并通过RDD之间的依赖关系构建DAG,然后将DAG提交到调度系统。
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算。
DAG是有边界的:开始(通过sparkcontext创建的RDD),结束(触发action,调用runjob就是一个完整的DAG形成了,一旦触发action,就形成了一个完整的DAG)。
一个RDD描述了数据计算过程中的一个环节,而一个DAG包含多个RDD,描述了数据计算过程中的所有环节。
一个spark application可以包含多个DAG,取决于具体有多少个action。
2)DAGScheduler:将DAG切分stage(切分依据是shuffle),将stage中生成的task以taskset的形式发送给TaskScheduler
为什么要切分stage?
一个是复杂业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)。
如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,下一个阶段的计算依赖上一个阶段的数据。
在同一个stage中,会有多个算子,可以合并到一起,我们很难称其为pipeline(流水线,严格按照流程、顺序执行)。
3)TaskScheduler:调度task(根据资源情况将task调度到Executors).
4)Executors:接收task,然后将task交给线程池执行。
具体可以简化为如图-38所示。
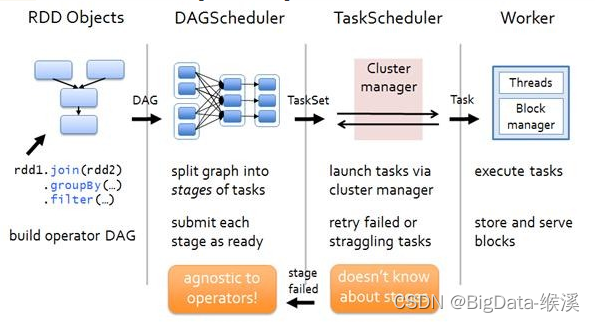
图-38 spark任务生成和提交图
排序
TopN
topN就是上述sortBy/sortByKey之后执行action操作take(N),或者直接takeOrderd(N),建议使用后者,效率高于前者。具体操作省略。
二次排序
所谓二次排序,指的是排序字段不唯一,有多个,共同排序,仍然使用上面的数据,对学生的身高和年龄一次排序。
- object SecondSortOps {
-
- def main(args: Array[String]): Unit = {
-
- val conf = new SparkConf()
-
- .setAppName(s"${SecondSortOps.getClass.getSimpleName}")
-
- .setMaster("local[2]")
-
- val sc = new SparkContext(conf)
-
- //sortByKey 数据类型为k-v,且是按照key进行排序
-
- val personRDD:RDD[Person] = sc.parallelize(List(
-
- Person(1, "吴轩宇", 19, 168),
-
- Person(2, "彭国宏", 18, 175),
-
- Person(3, "随国强", 18, 176),
-
- Person(4, "闫 磊", 20, 180),
-
- Person(5, "王静轶", 18, 168)
-
- ))
-
- personRDD.map(stu => (stu, null)).sortByKey(true, 1).foreach(p => println(p._1))
-
- sc.stop()
-
- }
-
- }
-
- case class Person(id:Int, name:String, age:Int, height:Double) extends Ordered[Person] {
-
- //对学生的身高和年龄依次排序
-
- override def compare(that: Person) = {
-
- var ret = this.height.compareTo(that.height)
-
- if(ret == 0) {
-
- ret = this.age.compareTo(that.age)
-
- }
-
- ret
-
- }
-
- }

