
- 1安装anaconda后输入conda、python等命令找不到_anaconda3安装无法初始化找不到python
- 2GitHub的使用方式_github怎么用
- 3【2023研电赛】东北赛区一等奖作品:基于FPGA的小型水下无线光通信端机设计
- 4Java的位运算符详解实例——与(&)、非(~)、或(|)、异或(^)_java 或运算
- 5android 中的dumpsys_android dumpsys代码入口
- 6工控领域常用的组态软件有哪些?
- 7kafka如何保证消息的顺序性_kafka消息顺序性
- 8详解挣值管理(EVM)_earned value management
- 9利用开源AI引擎平台:实现企业客户对话分析与优化中的应用|可本地化部署
- 10spring security @EnableWebSecurity自动配置DaoAuthenticationProvider流程_daoauthenticationprovider authprovider = new daoau
成本更低、更可控,云原生可观测新计费模式正式上线
赞
踩
云布道师
在上云开始使用云产品过程中,企业一定遇见过两件“讨厌”事:
难以理解的复杂计费逻辑,时常冒出“这也能收费”的感叹;
某个配置参数调节之后,云产品使用成本不可预估的暴涨。
可观测作为企业 IT 运维必须品,在应对不同可观测场景时提供了非常多产品,以及与之对应的计费模式,供企业灵活选择。但如果产品价格说明不完整且不能有效评估现有业务规模及增长趋势,就会给企业带来非常高的成本规划与选型评估门槛。为解决上述问题,云原生可观测推出「按写入数据量」计费模式,降低不同可观测产品间的计费认知差距,以便更好的理解与管理可观测成本。并提供每月累计 150GB 免费额度(多产品独立额度叠加),进一步压降建设可观测成本。
什么是按写入数据量计费
写入数据量是指通过 ARMS 自研探针、开源探针/SDK、云服务、开源 Exporter 上报到 ARMS 云原生可观测平台,经过清洗、聚合、转化、分析等计算处理后存储的数据量,并具备以下优势:
- 更低可观测成本
同样数据规模下,单位价格下调 70%,部分规格存储时长延长 50%,整体成本更低;
- 成本支出更可控
仅需考虑业务及对应的数据规模,无需担忧增值服务带来的额外成本;
- 评估模型更简单
相较旧计费模式下诸多计费项,新计费模型更简单易懂,无需理解特定语境下计算单位定义及计费项间关联关系。
按写入数据量计费的适用场景
(1)针对 Java 应用的性能监控及链路追踪
ARMS 应用监控:针对分布式、微服务化 Java 应用,提供代码级实时性能监测与全链路分析能力。覆盖云服务器 ECS、Serverless 应用引擎 SAE、容器服务 ACK 等不同应用部署环境,配合丰富的场景分析与全链路明细数据分析功能,随时掌握应用运行状态,梳理服务依赖关系,及时解决性能瓶颈与故障,提高产品可用性。

(2)针对 PHP、Node.js、.NET 等多语言应用的性能监控及链路追踪
可观测链路 OpenTelemetry 版:针对 PHP、C++、Go、Node.js 等多语言应用,提供端到端全链路追踪、应用监控与告警、链路拓扑、日志关联分析能力。并基于 OpenTelemetry 开源标准,兼容 Jaeger、Zipkin、SkyWalking 等开源项目数据上报。快速发现性能瓶颈,缩短错/慢调用根因定位耗时,提高全栈开发与诊断效率。

(3)针对云服务、应用组件、容器、基础设施的指标监控
可观测监控 Prometheus 版:针对业务自定义监控 / 应用组件监控 / 云服务监控 / 容器监控 / 系统监控等场景,提供指标监控与告警能力。并兼容 Prometheus 开源生态,提供一站式指标观测与告警平台,免去日常运维成本。

按写入数据量计费详解
(1)ARMS 应用监控
应用监控新计费模式屏蔽原有基础版、专家版的 Agent * Hour、链路数据存储、指标数据存储等计费项,不再以功能区分计费,以实际写入数据量(GB)进行计费。除了常见的链路、指标数据之外,增加剖析数据。剖析数据指使用 CPU & 内存诊断、应用诊断功能时产生的文件数据,包含内存快照、性能分析火焰图、线程分析的线程状态和调用栈信息数据。
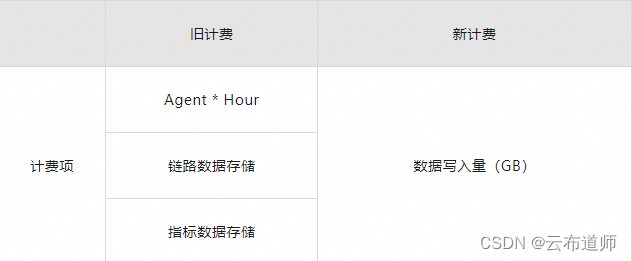
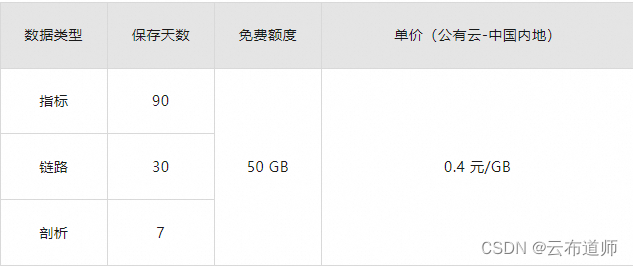
新计费模式单价 & 免费额度:
计算器:https://armsnext.console.aliyun.com/price-gb#/overview
老用户如何基于新计费模式进行成本预估
1)基本条件
1 个 ARMS Java 探针可监测 1 个应用实例(如 1 个 Tomcat 实例,1 个 Java 进程),在标准使用模式下(采样率 10%,接口级别指标开启收敛,不开启在线剖析,24 小时全时使用),每天产生数据约 2GB。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

