
- 1MySQL约束(Constraint)_mysql约束名是什么
- 2经典实例分割模型Mask RCNN原理与测试
- 32023-2024年中国人工智能计算力发展评估
- 4Mysql配置_mysql怎么配置
- 5MAGNet:Meta文本音乐生成工具,吉他摇滚、电子音乐都能搞定_meta 唱歌ai
- 6【Python】Python中assert语句的用法
- 7Android13系统导航栏添加隐藏导航栏功能按钮_we may show taskbar on the default display for lar
- 8服务发现:Zookeeper vs etcd vs Consul_consulratelimit kvloader
- 9头歌——一维数组和二维数组全对答案秒过_头歌二维数组右上部分求和
- 10go mod常用命令 以及 常见问题_go.mod already exists
VRPTW问题的Solomon标准测试数据集介绍_solomn数据集
赞
踩
Solomon 标准测试数据集
在 CVRPLIB 中,带时间窗的 VRPTW 是一类场景且经典的问题,而其中常用的标准测试数据有 Solomon(1987)和Homberger&Gehring(1999)两个,后者的样例规模更大。
Solomon 标准测试数据中,带有一个起始点(CUST NO.==0)和100个客户点。其中的所有常量都为整数,K 表示可以派遣最大车辆数,Q 表示每辆车的最大载重量,XCOORD, YCOORF 是起始点与客户点的横纵坐标,为简便计算,将节点之间的距离视为节点之间的运输成本;DEMAND 为节点处的需求量,起始点 depot 的需求量为0;READY TIME 表示在起始点和客户点处服务的最早开始时间;DUE TIME 则表示服务截止时间,对于起始点而言,该值表示全部车辆最晚必须返回的时间点;SERVICE TIME 表示在各节点处服务的持续时间。
具体格式如下图。

如果想进一步地控制问题规模,可以随机地在 Solomon 测试数据的100个节点中取25、50、75个节点以做实验(之所以这个比例划分是由于 solomon 数据集的时间窗的分布特点)。
Solomon 数据集的结构特点
Solomon 数据集按两个维度分为6大组的数据:R1, C1, RC1, R2, C2, RC2。
1. 节点分布差异
在 R1,R2 类数据集中,节点的坐标位置随机生成,较为分散;在 C1,C2 类数据集中,节点的坐标位置有明显的聚簇;而 RC1,RC2 类数据集则混合了随机和聚簇的特点。



如上图所示,R 类数据集坐标点分散且均匀,C 类数据集明显地存在节点簇,RC 类数据集则既有分散的部分,也有聚集的部分。
2. 调度时间差异
在 R1,C1,RC1 类数据集中,各个节点的时间窗(READY TIME, DUE TIME)的时间间隔显著小于 R2,C2,RC2 类的数据集。这就导致前者每辆车辆在一次调度中,所负责的客户数量较少,平均每辆车负责 5~10 个客户点的需求配送,而后者平均每辆车能负责 30 多个的客户点配送。
以 C104 和 C204 两份数据为例:前者所有节点的平均时间窗大小为 856.73,后者的为 2501.47。
3. 时间窗的分布差异
同一类问题的坐标信息是一致的,但是不同的测试数据的节点的时间窗口较窄的客户点百分比,以及时间窗口的松紧程度都是有差异的。
以下是 C104 数据和 C109 数据的时间窗分布差异(横坐标表示时间窗的长度)。
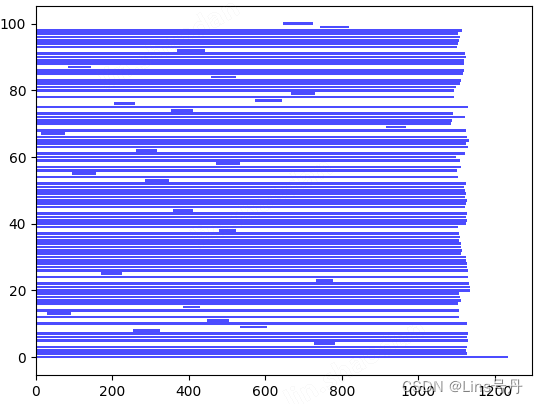
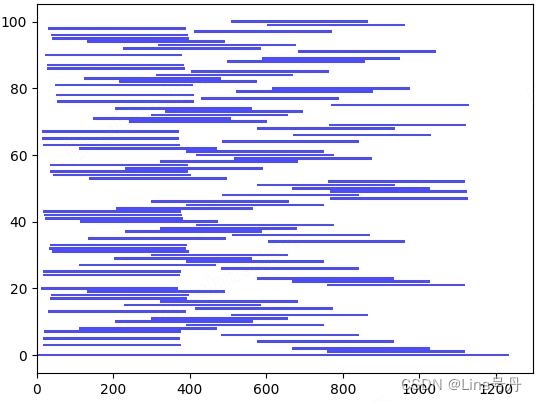
Solomon 数据集下载
Solomon 标准测试数据下载链接。上述画图代码如下。
import pandas as pd import matplotlib.pyplot as plt import numpy as np # 读取数据文件 file_path = 'C109.txt' # 请替换为实际文件路径 with open(file_path, 'r') as file: data0 = file.read() # 将数据转换为DataFrame data = [] for line in data0.strip().split('\n'): data.append(line.split()) columns = ["CUST", "XCOORD.", 'YCOORD.', 'DEMAND', 'READY', 'DUE', 'SERVICE'] df = pd.DataFrame(data[9:], columns=columns) # 将字符型列转换为数字 numeric_cols = ['CUST', 'XCOORD.', 'YCOORD.', 'DEMAND', 'READY', 'DUE', 'SERVICE'] df[numeric_cols] = df[numeric_cols].apply(pd.to_numeric, errors='coerce') df['sum'] = df['DUE'] - df['READY'] print(np.mean(df['sum'])) """画时间窗分布图""" plt.barh(df.index, df['DUE'] - df['READY'], left=df['READY'], color='blue', alpha=0.7) # 显示图形 plt.show() """画散点图:运行时去掉注释""" # # 绘制散点图 # plt.scatter(df.loc[1:, 'XCOORD.'], df.loc[1:, 'YCOORD.'], label='Customers', marker='o', color='blue') # plt.scatter(df.loc[0, 'XCOORD.'], df.loc[0, 'YCOORD.'], label='Depot', marker='x', color='red') # # 添加标签 # for i, row in df.iterrows(): # plt.annotate(row['CUST'], (row['XCOORD.'], row['YCOORD.']), textcoords="offset points", xytext=(0, 5), ha='center') # # 添加标题和轴标签 # plt.title(f'Customer and Depot Locations of {file_path}') # plt.xlabel('X Coordinate') # plt.ylabel('Y Coordinate') # # 显示图例 # plt.legend() # # 显示图形 # plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

