
- 1什么是CI/CD?让你的项目变得更加敏捷!_github cicd
- 2用python实现球球大作战_球球大作战 python
- 3python机器学习应用于农田疾病检测:保卫农作物的智能卫士_基于机器学习实现的农作物病虫害识别系统源码+数据(python).zip
- 4PAM安全配置-用户密码锁定策略_配置密码尝试失败锁定策略
- 5Hadoop 中HDFS、MapReduce体系结构
- 6PotatoPie 4.0 实验教程(26) —— FPGA实现摄像头图像拉普拉斯锐化
- 7物联网温湿度显示控制项目(网页、Android双端显示&搭载linux平台网关&MQTT通信)_android温湿度监控 mqtt
- 8Redis面试常见问题和性能监控_sync_partial_err
- 9吐槽下csdn的C币_csdn c币多少钱一个
- 10[已解决]mysql关闭SSL功能和永久关闭SSL设置_mysql禁用ssl
深入解析自注意力机制(Self-Attention):深度学习中的关键创新
赞
踩
深入解析自注意力机制(Self-Attention):深度学习中的关键创新
自注意力机制(Self-Attention),也称为内部注意力,是一种允许模型在序列内部的不同位置间直接建立关系的机制。这一技术已经彻底改变了自然语言处理(NLP)等领域的模型架构,特别是在Transformer模型的推动下,自注意力机制成为了近年来深度学习研究的热点之一。本篇博客将详细介绍自注意力机制的起源、工作原理、数学表达和在现代深度学习中的应用。
自注意力机制的起源
自注意力机制首次获得广泛关注是在2017年,由Google的研究团队在论文《Attention is All You Need》中提出。在此之前,多数基于注意力的模型侧重于在序列任务如机器翻译中将注意力用于源和目标序列之间的关系。自注意力的提出标志着注意力机制的一个重大转变,即注意力也可以有效地应用于序列内部的元素之间,从而直接捕捉序列内的依赖关系。
自注意力机制的工作原理
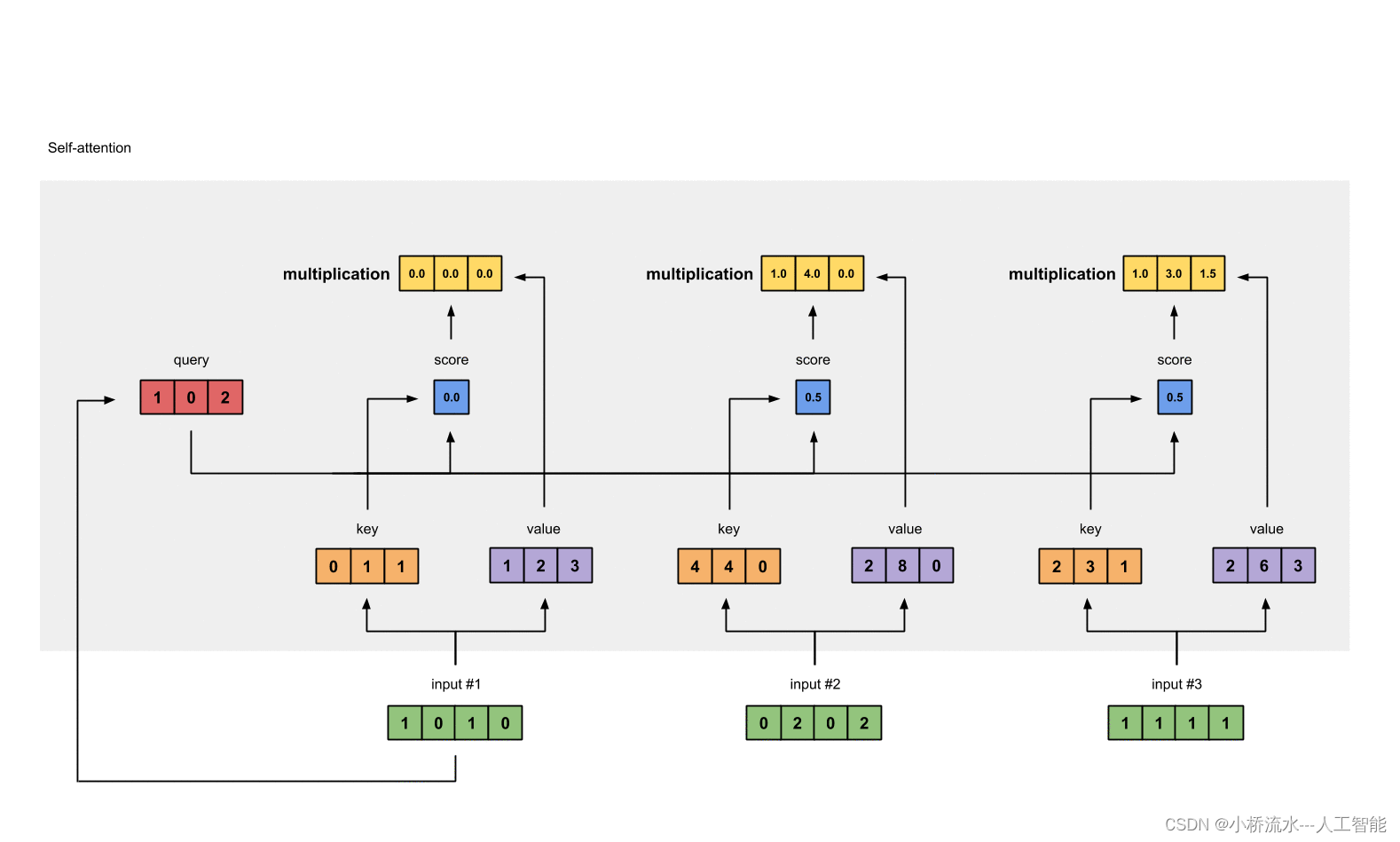
自注意力机制通过计算序列中每个元素对于其他元素的注意力分数来工作,这允许模型在不同位置间直接捕捉到相关性。这种机制特别适合处理那些输入和输出之间关系复杂或者序列很长的任务。
关键组件
自注意力机制主要包含以下几个步骤:
- 输入表示:序列中的每个元素被编码为一个固定大小的向量。
- 查询(Query)、键(Key)、值(Value)计算:对于序列中的每个元素,使用不同的权重矩阵将其转换成查询向量、键向量和值向量。
- 注意力分数计算:对于序列中的每个元素,计算它与序列中所有元素(包括自己)的点积,得到注意力分数。
- 权重计算:使用softmax函数对注意力分数进行归一化,得到每个元素对其他元素的注意力权重。
- 输出表示:将权重应用于对应的值(Value)向量,并对它们进行加权求和,得到该元素的输出表示。
公式表达
假设有一个序列的元素集
X
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
X = \{x_1, x_2, ..., x_n\}
X={x1,x2,...,xn},每个元素
x
i
x_i
xi 都通过线性变换得到对应的查询 ( Q )、键 ( K ) 和值 ( V ):
Q
=
X
W
Q
,
K
=
X
W
K
,
V
=
X
W
V
Q = XW^Q, \quad K = XW^K, \quad V = XW^V
Q=XWQ,K=XWK,V=XWV
其中
W
Q
W^Q
WQ,
W
K
W^K
WK,
W
V
W^V
WV 是可学习的权重矩阵。
注意力分数
a
i
j
a_{ij}
aij 计算为:
a
i
j
=
e
x
p
(
Q
K
T
)
i
j
∑
k
=
1
n
e
x
p
(
Q
K
T
)
i
k
a_{ij} = \frac{exp(QK^T)_{ij}}{\sum_{k=1}^n exp(QK^T)_{ik}}
aij=∑k=1nexp(QKT)ikexp(QKT)ij
即元素 ( i ) 对元素 ( j ) 的注意力权重是 ( i ) 的查询向量与 ( j ) 的键向量的点积,通过softmax归一化后得到。
最后,输出向量
z
i
z_i
zi 是所有值向量的加权和:
z
i
=
∑
j
=
1
n
a
i
j
v
j
z_i = \sum_{j=1}^n a_{ij} v_j
zi=j=1∑naijvj
自注意力机制的应用
自注意力机制已被广泛应用于多个领域,尤其在自然语言处理领域,它已成为新一代模型架构的核心,如Transformer及其衍生模型BERT、GPT等。这些模型在机器翻译、文本摘要、情感分析等任务中设置了新的性能基准。
此外,自注意力机制也开始被应用于非NLP任务,如图像处理领域的图像分类、对象检测等,以及视频处理和音频信号处理等领域。
结论
自注意力机制通过其高效的内部序列建模能力,为处理复杂的序列数据问题提供了强大的工具。 它不仅提高了模型的性能,也大大增强了模型处理长距离依赖的能力。随着深度学习技术的不断进步,我们可以预期自注意力机制将在更多的领域发挥重要作用。

