
- 1生成 小程序 URL Scheme_小程序生成 url scheme
- 2【Prompting】ChatGPT Prompt Engineering开发指南(3)_prompting gpt
- 3flink设置historyserver_flink historyserver.archive.fs.refresh-interval
- 4Android日历CalendarView当结束日期小于开始日期依旧绘制处理_com.haibin.calendarview.calendarview select_mode
- 5易语言IDE界面美化支持库
- 6Win10使用技巧-如何让Windows Defender停止对某些文件的防护_windows无法隔离文件
- 7推荐一款开源项目: Flask-BookRecommend-Mysql
- 8c/c++常见面试题02_保存被调用函数相同参数的运行结果
- 9面向对象实现一个图书管理的功能——基于Python_属性: 图书馆名称(name) 借书人字典(borrowers) 图书字典(books) 方法: 构
- 102021章节练习基础(案例精选)1-10_5号电动阀门关闭时阀顶
AST详解_ast解析js
赞
踩
文章目录
前言
javascript(以下简称js)的语法是非常灵活的,如果直接用js代码来进行混淆和还原无疑是很麻烦的而且还容易出错。但是把js代码转换成抽象语法树以后(ast),一切就变得简单了。在编译原理里,从源码到机器码经历了一系列的过程。比如:源码通过词法分析器变为记号序列,通过语法分析器变为ast,又通过语义分析器等一系列步骤,最后编译位机器码。所以,ast其实是一个概念性的东西,通过词法分析器和语法分析器,就能把各种语言解析成ast。
要想把js代码解析成ast,可以自己手动去解析,也可以使用现成的解析库。当使用的解析库不一样时,生成的ast或许会有所区别。本文采用的是babel,一个nodejs的包(安装:npm install @babel/core)详细步骤请google it。在用ast自动化处理js代码前,肯定需要对ast的一些api有所了解,本文将着重介绍。
一、ast入门
1.ast的基本结构
js代码经过ast解析后,生成的其实就是一些json元素。经过babel解析以后,通常把里面的一些元素称为节点(nodes),babel也提供了很多方法去操作这些节点。
let obj = {
name: 'demo',
add: function (a, b) {
return a + b + 1000;
},
mul: function (a, b) {
return a * b + 1000;
},
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将上述代码拿到网页(链接: https://astexplorer.net/.)中进行解析。
在网页的上方先选择javascript语言和@babel/parser的解析方式。网页的左边是源码,右边就是解析后的ast。

body里为解析后的主要内容。js源代码里首先声明了个obj对象,然后进行赋值操作 即:let obj = {…},所以点开body节点后先看到一个变量声明节点(variableDeclaration),kind(关键字)为let,declarations是一个数组,因为我们用let,var等关键字声明变量时可同时声明多个变量 如:var a=1,b=2。

上图:declarations中就是我们声明的obj的信息,变量名在id(identifier:标识符)中。
js中可以单独声明变量 如:var a, b, c;
也可以声明变量的同时赋值 如:var a = { a=1; b=2; c=a+b;},这种情况,右边赋的值就在init(初始化值)中。

初始化值中我们定义了三个属性 即:name, add, mul.

上图:点开properties,此属性的type为对象属性,key为此属性的标识符即name,value为此属性的值,类型为stringLiteral。

2.代码的基本结构
ast解析转换代码的基本结构
const fs = require('fs');
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
//在这里对AST进行一系列的操作
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- fs库用来读取文件
- @babel/parser库用来将js代码转换成ast
- @babel/traverse库用来遍历ast节点
- @babel/types库用来判断节点类型和生成新节点
- @babel/generator库用来将ast转换成js代码
二、Babel中的组件
1.parser,generator
parser组件将js代码转换成ast,generator组件将ast转换成js
使用let ast = parser.parse(jscode);即可完成js到ast的转换,parse的第二个参数接收一个对象,可以设置一些解析配置,如下:
let ast = parser.parse(jscode,{
sourceType: "module",
});
- 1
- 2
- 3
当js代码中含有import导入语句的时候直接解析会报错,此时添加上述配置即可。
使用let code = generator(ast).code 即可完成ast至js代码的转换。generator方法也含有第二个参数,同样的也可以设置一些配置。
完整介绍可在babel官方文档中查看,此处只介绍一部分。
let code = generator(ast, {
retainLines: true,
comments: true,
compact: true,
jsescOption: {
minimal: true,
}
}).code;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- retainLines:源代码和解析后的代码是否保留相同的行号
- comments:是否保留注释
- compact:是否压缩代码
- 多个选项间可以配合使用
2.traverse,visitor
traverse用来遍历ast节点,但是单纯的遍历节点没有意义,因此需配合visitor使用。visitor就是一个对象,里面可以定义一些方法来过滤节点。
let visitor = {}
visitor.FunctionExpression = function(path){
console.log('test code!!!')
}
traverse(ast, visitor)
/* 输出
test code!!!
test code!!!
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上述代码中,先声明一个对象,对象名随意,然后再对象中声明一个FunctionExpression的方法,这个是我们想要遍历的类型,如果想要操作identifier则在改visitor对象中再定义个identifier的方法。由于我们的源js代码中有两个FunctionExpression类型的属性(add,mul)所有会输出两次语句。
以下是visitor的其他几种写法,常用的是visitor2.
const visitor1 = { FunctionExpression: function(path){ console.log('test code!!!') } }; const visitor2 = { FunctionExpression(path){ console.log('test code!!!') } }; const visitor3 = { FunctionExpression: { enter(path){ console.log('test code!!!') }, exit(path){ console.log('test code!!!') } } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在visitor3中定义了enter和exit函数,实际上在traverse遍历ast节点的时候,有两次机会来访问这个函数,第一次是进入函数的时候即enter,第二次是推出函数的时候即exit。当有这种需求的时候,则才有visitor3这种方式。
以obj对象内的add属性为例,traverse(ast, visitory)遍历节点的流程如下:
进入FunctionExpression 进入Identifier params[0] 走到尽头 退出Identifier params[0] 进入Identifier params[1] 走到尽头 退出Identifier params[1] 进入BlockStatement body 进入ReturnStatement (body) 进入BinaryExpression (argument) 进入BinaryExpression (left) 进入Identifier (left) 读取name:a,走到头 退出Identifier (left) 读取operator (+) 进入Identifier (right) 读取name:b,走到头 退出Identifier (right) 退出BinaryExpression (left) 读取operator (+) 进入NumericLiteral (right)读取value:1000,走到头 退出NumericLiteral (right) 退出BinaryExpression (argument) 退出ReturnStatement (body) 退出BlockStatement body 退出FunctionExpression
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
由此可见,traverse遍历节点是深度优先的,如果type中有父子节点,enter函数是先访问父节点再访问子节点而exit函数则相反,traverse中默认访问函数使用enter函数,如果要用exit函数则需在visitor中声明。如下:
const visitor = {
FunctionExpression: {
enter(path){
console.log('test code!!!')
},
exit(path){
console.log('test code!!!')
}
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
用“|”符号将多个函数名连接成字符串形式:"FunctionExpression|BinaryExpression"可以将同一个函数应用于多个节点。如下:
const visitor2 = { "FunctionExpression|BinaryExpression"(path){ console.log('test code!!!') } }; traverse(ast, visitor2) /*输出 test code!!! test code!!! test code!!! test code!!! test code!!! test code!!! */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
也可以将多个函数应用于同一个节点,原先是把一个函数赋值给enter函数或者exit函数,现在把enter值改为数组即可。如下:
function a(){ console.log("a!!") } function b(){ console.log("b!!") } const visitor4 = { FunctionExpression: { enter: [a, b] } }; traverse(ast, visitor4) /* 输出 a!! b!! a!! b!! */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
traverse不一定要从头开始遍历ast几点。如下:
const updateParamsNameVisitor = { Identifier(path){ if(path.node.name === this.paramName){ path.node.name = "x"; } } } const visitor = { FunctionExpression(path){ const paramName = path.node.params[0].name; path.traverse(updateParamsNameVisitor, { paramName, }) } } traverse(ast, visitor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
上述代码中visitor对象中使用了path.traverse,在babel中支持遍历当前节点。
3.types组件
该组件用来判断节点类型和生成新的节点。const t = require("@babel/types");,t.isIdentifier(path.node)判断该节点是否是Identifier类型。如下:
traverse(ast, {
enter(path){
if(t.isIdentifier(path.node) && path.node.name == 'n'){
path.node.name = 'x';
}
}
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上述代码也可以写成如下:
traverse(ast, {
enter(path){
if(t.isIdentifier(path.node, {name: 'n'})){
path.node.name = 'x';
}
}
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
想要判断其他类型,只需改变t后面所跟的类型就行了。这些方法还有一种断言方式的版本。如下:
t.assertIdentifier(path.node)
t.assertIdentifier(path.node, {name: 'n'})
- 1
- 2
如果节点不符合要求则直接抛出异常,不会返回true,false。
types组件最常用的还是拿来生成新的节点。如下:
let a = t.identifier('a'); let b = t.identifier('b'); let binExpr2 = t.binaryExpression("+", a, b); let binExpr3 = t.binaryExpression("*", a, b); let retSta2 = t.returnStatement(t.binaryExpression("+", binExpr2, t.numericLiteral(1000))); let retSta3 = t.returnStatement(t.binaryExpression("+", binExpr3, t.numericLiteral(1000))); let bloSta2 = t.blockStatement([retSta2]); let bloSta3 = t.blockStatement([retSta3]); let funcExpr2 = t.functionExpression(null, [a, b], bloSta2); let funcExpr3 = t.functionExpression(null, [a, b], bloSta3); let objProp1 = t.objectProperty(t.identifier('name'), t.stringLiteral('test')); let objProp2 = t.objectProperty(t.identifier('add'), funcExpr2); let objProp3 = t.objectProperty(t.identifier('mul'), funcExpr3); let objExpr = t.objectExpression([objProp1, objProp2, objProp3]); let varDec = t.variableDeclarator(t.identifier('obj'), objExpr); let loaclAst = t.variableDeclaration('let', [varDec]); let code = generator(loaclAst).code; console.log(code); /*输出 let obj = { name: "test", add: function (a, b) { return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在js代码转换过程中,生成的新的节点一般会添加或者替换到已有的节点中。
在上述案例中用到了StringLiteral,NumericLiteral,babel库中还定义了一些其他的字面量:
(alias) function nullLiteral(): NullLiteral
export nullLiteral
(alias) function booleanLiteral(value: boolean): BooleanLiteral
export booleanLiteral
(alias) function regExpLiteral(pattern: string, flags?: string): RegExpLiteral
export regExpLiteral
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
不同的字面量需要不同的方法声明太过麻烦,babel中还提供了valuetonode方法来自动识别字面量的类型。如下:
(alias) const valueToNode: {
(value: undefined): Identifier;
(value: boolean): BooleanLiteral;
(value: null): NullLiteral;
(value: string): StringLiteral;
(value: number): NumericLiteral | ... 1 more ... | UnaryExpression;
(value: RegExp): RegExpLiteral;
(value: readonly unknown[]): ArrayExpression;
(value: object): ObjectExpression;
(value: unknown): Expression;
}
export valueToNode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
下述的两条语句是等价的
let retSta3 = t.returnStatement(t.binaryExpression("+", binExpr3, t.numericLiteral(1000)));
let retSta3 = t.returnStatement(t.binaryExpression("+", binExpr3, t.valueToNode(1000)));
- 1
- 2
若要是使用stringliteral则只需将1000改为”1000“,而不必将numericliteral改为stringliteral了,如下:
let retSta3 = t.returnStatement(t.binaryExpression("+", binExpr3, t.valueToNode("1000")));
- 1
除了原始类型undefined, null, string,number, boolean,还可以是RegExp, ReadonlyArray,object,如下将生成一个数组:
let node = t.valueToNode([1, false, {'x':100, 'y':200}])
let code = generator(node).code
console.log(code)
/*输出
[1, false, {
x: 100,
y: 200
}]
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.path对象详解
1.path与node的区别
如下:
const updateParamNameVisitor = { Identifier(path) { if (path.node.name === this.paramName) { path.node.name = "x"; } console.log(path); path.stop(); } }; const visitor = { FunctionExpression(path) { const paramName = path.node.params[0].name; path.traverse(updateParamNameVisitor, { paramName }); } }; traverse(ast, visitor); /*输出 NodePath {contexts: Array(1), state: Object, opts: Object, _traverseFlags: 0, skipKeys: null, …} _traverseFlags: 0 container: Array(2) [Node, Node] context: TraversalContext {queue: Array(2), priorityQueue: Array(0), parentPath: NodePath, …} contexts: Array(1) [TraversalContext] data: null hub: undefined inList: true key: 0 listKey: "params" node: Node {type: "Identifier", start: 56, end: 57, …} opts: Object {Identifier: Object, _exploded: true, _verified: true} parent: Node {type: "FunctionExpression", start: 46, end: 120, …} parentKey: "params" parentPath: NodePath {contexts: Array(1), state: undefined, opts: Object, …} removed: false scope: Scope {uid: 1, path: NodePath, block: Node, …} shouldSkip: false shouldStop: false skipKeys: null state: Object {paramName: "a"} type: "Identifier" __proto__: Object {findParent: , find: , getFunctionParent: , …} */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
由上代码可看出path对象包含当前的node节点,而node节点就是ast explorer网站中解析的节点结构。node节点是构成at的原料。path.node当前节点加上其他节点(父级节点,同级节点)再加上一些方法共同构成了path对象。
2.path中的方法
1.获取子节点
const visitor = {
// 此二项表达式为a+b+1000
BinaryExpression(path) {
const paramName = path.node.params[0].name; // 在此处打断点
}
};
traverse(ast, visitor);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在上述代码注释处打断点,然后在控制台输出path.node.left,这个left节点就是此二项表达式节点操作符左边的值:a+b,
path.node.left Node {type: "BinaryExpression", start: 100, end: 105, loc: SourceLocation, left: Node, …} end:105 left:Node {type: "Identifier", start: 100, end: 101, …} loc:SourceLocation {start: Position, end: Position, filename: undefined, …} operator:"+" right:Node {type: "Identifier", start: 104, end: 105, …} start:100 type:"BinaryExpression" __proto__:Object {__clone: , constructor: } path.node.left.left.name "a" path.node.left.right.name "b" path.node.left.operator "+"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如果想要得到子节点的path对象,则使用path.get()方法,接收的参数为node节点下的属性名。如下:
path.get("left") // 获取当前节点下字节的的path对象 // 以下为left节点的path对象 NodePath {contexts: Array(0), state: undefined, opts: Object, _traverseFlags: 0, skipKeys: null, …} _traverseFlags:0 container:Node {type: "BinaryExpression", start: 100, end: 112, …} context:TraversalContext {queue: Array(1), priorityQueue: Array(0), parentPath: NodePath, …} contexts:Array(0) [] data:null hub:undefined inList:false key:"left" listKey:undefined node:Node {type: "BinaryExpression", start: 100, end: 105, …} end:105 left:Node {type: "Identifier", start: 100, end: 101, …} end:101 loc:SourceLocation {start: Position, end: Position, filename: undefined, …} name:"a" start:100 type:"Identifier" __proto__:Object {__clone: , constructor: } loc:SourceLocation {start: Position, end: Position, filename: undefined, …} operator:"+" right:Node {type: "Identifier", start: 104, end: 105, …} end:105 loc:SourceLocation {start: Position, end: Position, filename: undefined, …} name:"b" start:104 type:"Identifier" __proto__:Object {__clone: , constructor: } start:100 type:"BinaryExpression" __proto__:Object {__clone: , constructor: } __clone:function () { … } constructor:class Node { … } __proto__:Object {constructor: , __defineGetter__: , __defineSetter__: , …} opts:Object {BinaryExpression: Object, _exploded: true, _verified: true} parent:Node {type: "BinaryExpression", start: 100, end: 112, …} parentKey:"left" parentPath:NodePath {contexts: Array(1), state: undefined, opts: Object, …} removed:false scope:Scope {uid: 1, path: NodePath, block: Node, …} shouldSkip:false shouldStop:false skipKeys:null state:undefined type:"BinaryExpression" __proto__:Object {findParent: , find: , getFunctionParent: , …}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
2.判断path对象的类型
path对象中有一个属性type,与node节点的type基本一致,判断方法如下:
// 当前节点为a+b+1000,right节点为1000(type:NumericLiteral)
path.get("right").isNumericLiteral()
true
path.get("right").isIdentifier()
false
- 1
- 2
- 3
- 4
- 5
3.node节点转js代码
const visitor = {
FunctionExpression(path) {
console.log(generator(path.node).code)
}
};
traverse(ast, visitor);
/*
function (a, b) {
var cc = 11;
return a + b + 1000;
}
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
也可以用path.toString(),path + ‘’,将path对象的当前节点转换为js代码
4.替换节点属性
如下:
const visitor = {
BinaryExpression(path) {
path.node.left = t.identifier("1")
path.node.right = t.identifier("2")
console.log(path.toString())
}
};
traverse(ast, visitor);
/*
原二项表达式为a+b+1000,替换后如下
1 + 2
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.替换节点
path对象中与替换相关的方法有:replaceWith,replaceWithMultiple,replaceInline,replaceWithSourceString
replaceWith,节点一换一,如下:
const visitor = { BinaryExpression(path) { path.replaceWith(t.valueToNode("test!")) } }; traverse(ast, visitor); console.log(generator(ast).code) /* 源码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return 1 + 2; }, mul: function (a, b) { return 1 + 2; } }; 替换后: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return "test!"; }, mul: function (a, b) { return "test!"; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
replaceWithMultiple,节点多换一。如下:
const visitor = { ReturnStatement(path) { path.replaceWithMultiple([ t.expressionStatement(t.valueToNode('replaceWithMultiple!')), t.returnStatement(), ]) path.stop() } }; traverse(ast, visitor); console.log(generator(ast).code) /* 源码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return 1 + 2; }, mul: function (a, b) { return 1 + 2; } }; 替换后: let obj = { n: 'demo', add: function (a, b) { var cc = 11; "replaceWithMultiple!"; return; }, mul: function (a, b) { "replaceWithMultiple!"; return; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
上述代码中将原先的return节点替换成了两条节点,需要注意的是在ReturnStatement(path) {}这个函数中需要在末尾加上path.stop()方法,因为替换后的节点ast也会遍历到,这样的话,替换前有return语句,替换后也有return语句就会造成死循环,需要path.stop()一下。
replaceInline(),这个方法接收一个参数,当参数是数组的时候等同于replaceWithMultiple,当参数为非数组的时候等同于replaceWith.
replaceWithSourceString方法用字符串来替换节点。如下:
const visitor = { ReturnStatement(path) { let argumentPath = path.get('argument') argumentPath.replaceWithSourceString( "123" ) path.stop() } }; traverse(ast, visitor); console.log(generator(ast).code) /* 源码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return 1 + 2; }, mul: function (a, b) { return 1 + 2; } }; 替换后: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return 123; }, mul: function (a, b) { return 123; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
6.删除节点
path.remove()方法,如下:
const visitor = { EmptyStatement(path) { path.remove() } }; traverse(ast, visitor); console.log(generator(ast).code) /* 源码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; }, }; ; ; 替换后: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
EmptyStatement是空节点,上述代码可以看到将原js代码最后两行的空语句(只含;)remove掉了。
7.插入节点
path.insertBefore,path.insertAfter,分别是在当前节点的前后插入节点,如下:
const visitor = { ReturnStatement(path) { path.insertBefore(t.expressionStatement(t.valueToNode('Before!'))) path.insertAfter(t.expressionStatement(t.valueToNode('After!'))) } }; traverse(ast, visitor); console.log(generator(ast).code) /* 源码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; }, }; 替换后: let obj = { n: 'demo', add: function (a, b) { var cc = 11; "Before!"; return a + b + 1000; "After!"; }, mul: function (a, b) { "Before!"; return a * b + 1000; "After!"; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3.父级path
1.parentPath,parent
path对象中有两个属性parentPath,parent,这两个属性的关系就相当于node和nodePath的关系。
2.path.findParent()
path.findParent(),该方法时从当前节点逐层向上遍历父级节点,该方法接收一个回调函数作为参数,当回调函数返回true时,返回当时的path对象。
const visitor = { ReturnStatement(path) { console.log(path.findParent((p)=> p.isObjectExpression()).toString()) } }; traverse(ast, visitor); // console.log(generator(ast).code) /* { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; } } { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; } } */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
上述代码中let obj是对象表达式,则将其转换为js代码输出。
3.path.find()
该方法与findParent()方法一致,不同点在于该方法查找时包含当前节点。
4.path.getFunctionParent()
向上查找与当前节点最接近的父函数,返回的也是一个path对象。
5.path.getStatementParent()
向上查找与当前节点最接近的语句,返回的也是一个path对象。
4.同级path
path对象中的container属性理解
js代码: let obj = { n: 'demo', add: function (a, b) { var cc = 11; return a + b + 1000; }, mul: function (a, b) { return a * b + 1000; }, }; ----ast代码---- const visitor = { ReturnStatement(path) { console.log(path) path.stop() //在此处打断点 } }; traverse(ast, visitor); // console.log(generator(ast).code) /* NodePath {contexts: Array(1), state: undefined, opts: Object, _traverseFlags: 0, skipKeys: null, …} astDemo.js:14 _traverseFlags:0 container:Array(2) [Node, Node] context:TraversalContext {queue: Array(2), priorityQueue: Array(0), parentPath: NodePath, …} contexts:Array(1) [TraversalContext] data:null hub:undefined inList:true key:1 listKey:"body" node:Node {type: "ReturnStatement", start: 85, end: 105, …} opts:Object {ReturnStatement: Object, _exploded: true, _verified: true} parent:Node {type: "BlockStatement", start: 54, end: 112, …} parentKey:"body" parentPath:NodePath {contexts: Array(1), state: undefined, opts: Object, …} removed:false scope:Scope {uid: 1, path: NodePath, block: Node, …} shouldSkip:false shouldStop:false skipKeys:null state:undefined type:"ReturnStatement" __proto__:Object {findParent: , find: , getFunctionParent: , …} */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
上述代码用visitor访问ReturnStatement节点,并将其path对象输出。可见其path对象中有container,key,listkey三个属性。listkey是container容器的名字,key是当前节点在container容器中的位置。此时我们需要结合ast explorer网站中ast解析结构来看。如下:
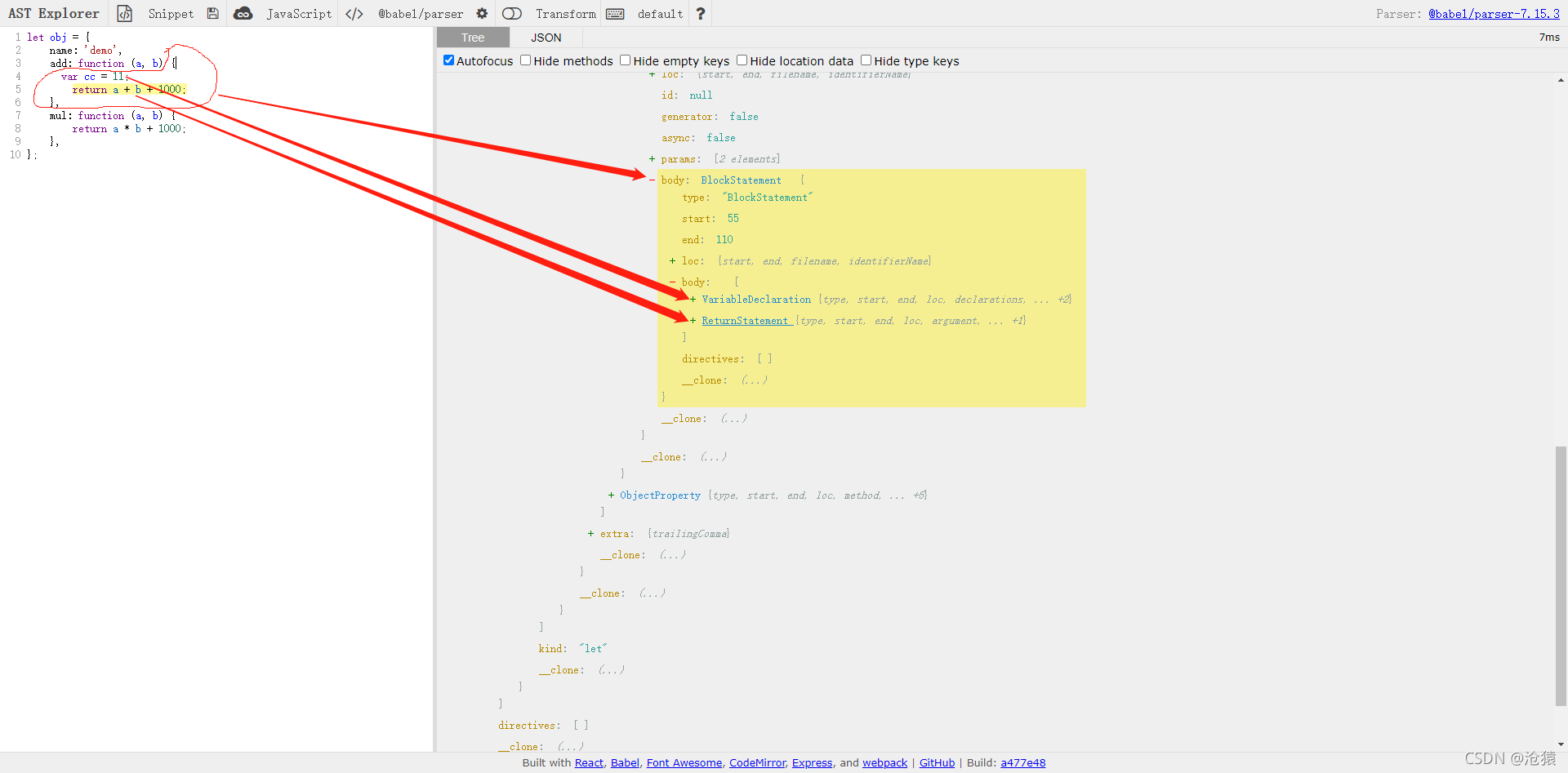
从上图就可以很容易看出我们的ReturnStatement节点在一个blockStatement节点中其名字是body。而ReturnStatement节点在body数组中的第二个。整个body数组就是我们的container容器。
也就是说container容器中的节点的path对象都是我们当前path对象的同级path。
当container不是一个数组而是一个对象的时候说明当前节点不存在同级节点。
1.path.inList
用于判断是否有同级节点。注意:当container容器为数组且只有一个成员的时候,此方法也会返回true。
2.path.container,path.key,path.listKey
path.container:获取容器
path.key:获取当前节点在容器中的索引
path.listKey:获取容器名
3.path.getSibling(index)
获取同级节点的path对象
4.path.unshiftContainer,path.pushContainer
在容器内节点的前后插入节点。如下:
traverse(ast, { ReturnStatement(path) { path.parentPath.unshiftContainer('body', [ t.expressionStatement(t.stringLiteral('Before1')), t.expressionStatement(t.stringLiteral('Before2'))]); console.log(path.parentPath.pushContainer('body', t.expressionStatement(t.stringLiteral('After')))); } }); console.log(generator(ast).code) /* let obj = { n: 'demo', add: function (a, b) { "Before1"; "Before2"; var cc = 11; return a + b + 1000; "After"; }, mul: function (a, b) { "Before1"; "Before2"; return a * b + 1000; "After"; } }; */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
5.scope详解
下文讲解基于以下js代码:
const a = 1000; let b = 2000; let obj = { name: 'demos', add: function (a) { a = 400; b = 300; let e = 700; function demo() { let d = 600; } demo(); return a + a + b + 1000 + obj.name; } }; obj.add(100);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.获取标识符作用域
path.scope.block 获取标识符的作用域。如下:
traverse(ast, { Identifier(path) { if(path.node.name === "e"){ console.log(generator(path.scope.block).code) } } }); // console.log(generator(ast).code) /* function (a) { a = 400; b = 300; let e = 700; function demo() { let d = 600; } demo(); return a + a + b + 1000 + obj.name; } */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可以看到标识符也就是变量e的作用域在整个add函数内。
获取函数的作用域需获取其父级的作用域。如下:
traverse(ast, {
FunctionDeclaration(path) {
console.log(generator(path.scope.parent.block).code)
}
});
- 1
- 2
- 3
- 4
- 5
注意:在js代码中type为FunctionDeclaraion的函数只有demo函数一个,add函数是一个函数表达式本质是一个匿名函数赋值给了add。
2.获取标识符的绑定
path.scope.getBinding(String),接收一个字符串并获取其的绑定。
如果这里传的值是未定义的,或者是当前节点引用不到的则会返回undefined。实例如下:
traverse(ast, { FunctionDeclaration(path) { let bind = path.scope.getBinding("a") console.log(bind) console.log("13") //在此处打断点 } }); // console.log(generator(ast).code) /* Binding {identifier: Node, scope: Scope, path: NodePath, kind: "param", constantViolations: Array(1), …} constant:false constantViolations:Array(1) [NodePath] hasDeoptedValue:false hasValue:false identifier:Node {type: "Identifier", start: 84, end: 85, …} kind:"param" path:NodePath {contexts: Array(0), state: Object, opts: Object, …} referenced:true referencePaths:Array(2) [NodePath, NodePath] references:2 scope:Scope {uid: 1, path: NodePath, block: Node, …} value:null __proto__:Object {constructor: , deoptValue: , setValue: , …} */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Binding中的几个关键属性:
Identifier:就是a标识符的node对象
path:就是a标识符的path对象
kind:表明了a是一个参数,注意它并不代表就是当前demo函数的参数。实际上在js源代码中a是add函数的参数。(当函数中局部变量与全局变量重名时,使用局部变量)
referenced:表示当前标识符是否被引用
references:表示当前标识符被引用的次数
constant:是否是常量
scope:作用域,获取绑定标识符作用域如下:
traverse(ast, {
FunctionExpression(path) {
let bindingA = path.scope.getBinding('a');
let bindingDemo = path.scope.getBinding('demo');
console.log(bindingA.referenced);
console.log(bindingA.references);
console.log(generator(bindingA.scope.block).code);
console.log(generator(bindingDemo.scope.block).code);
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
getOwnBinding,获取当前节点自己的一个绑定,不包含父级。实例代码如下:
traverse(ast, { FunctionExpression(path){ path.traverse({ Identifier(p) { let name = p.node.name; console.log( name, !!p.scope.getOwnBinding(name) ); } }); } }); // console.log(generator(ast).code) /* a true //函数参数 a true //函数参数赋值 b false //全局变量赋值 e true //函数局部变量 demo false //错误 d true //错误 demo true a true a true b false obj false name false */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
使用getOwnBinding会有一些错误无法避免,一般情况下我们使用getBinding来替代getOwnBinding,只需加上作用域判断来只取当前节点的标识符绑定而不取其子函数和子函数标识符的绑定。如下:
function TestOwnBinding(path){
path.traverse({
Identifier(p) {
let name = p.node.name;
let binding = p.scope.getBinding(name);
binding && console.log( name, generator(binding.scope.block).code == path + '' );
}
});
}
traverse(ast, {
FunctionExpression(path){
TestOwnBinding(path);
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.referencePaths与constantViolations
引用标识符的节点全部存放在referencePaths中
修改标识符的节点全部存放在constantViolations中
4.遍历作用域
path.scope.traverse,实例代码如下:
traverse(ast, {
FunctionDeclaration(path) {
let binding = path.scope.getBinding('a');
binding.scope.traverse(binding.scope.block, {
AssignmentExpression(p) {
if (p.node.left.name == 'a')
p.node.right = t.numericLiteral(500);
}
});
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.标识符重命名
用scope.rename将标识符进行重命名,该方法会同时修改引用该标识符的地方。比如将add函数中的b变量改为x,实例代码如下:
traverse(ast, { FunctionExpression(path) { let binding = path.scope.getBinding('b'); console.log(generator(binding.scope.block).code) binding.scope.rename('b', 'x'); console.log('123') // 在此处打断点,并在控制台查看binding对象 } }); // console.log(generator(ast).code) /* js源码: const a = 1000; let b = 2000; let obj = { name: 'demos', add: function (a) { a = 400; b = 300; let e = 700; function demo() { let d = 600; } demo(); return a + a + b + 1000 + obj.name; } }; obj.add(100); 修改后: const a = 1000; let x = 2000; let obj = { name: 'demos', add: function (a) { a = 400; x = 300; let e = 700; function demo() { let d = 600; } demo(); return a + a + x + 1000 + obj.name; } }; obj.add(100); */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
如果硬性的重命名一个标识符的话,可能会引起标识符的冲突。这时候我们可以使用scope.generateUidIdentifier(“uid”);方法。该方法会自动避免标识符命名冲突。实例代码如下:
traverse(ast, {
FunctionExpression(path) {
path.scope.generateUidIdentifier("uid");
// Node { type: "Identifier", name: "_uid" }
path.scope.generateUidIdentifier("uid");
// Node { type: "Identifier", name: "_uid2" }
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
根据这个特性可以简单的实现一个标识符混淆。如下:
traverse(ast, { Identifier(path) { path.scope.rename(path.node.name, path.scope.generateUidIdentifier("abc").name); } }); // console.log(generator(ast).code) /* js源码: const a = 1000; let b = 2000; let obj = { name: 'demos', add: function (a) { a = 400; b = 300; let e = 700; function demo() { let d = 600; } demo(); return a + a + b + 1000 + obj.name; } }; obj.add(100); 标识符混淆后: const _abc = 1000; let _abc15 = 2000; let _abc18 = { name: 'demos', add: function (_abc14) { _abc14 = 400; _abc15 = 300; let _abc9 = 700; function _abc12() { let _abc11 = 600; } _abc12(); return _abc14 + _abc14 + _abc15 + 1000 + _abc18.name; } }; _abc18.add(100); */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
6.scope的其他方法
1.scope.hasBinding(‘a’),查询是否有标识符a的绑定,返回一个boolean值。
2.scope.hasOwnBinding(’'a),查询自己的绑定,返回一个Boolean值
3.scope.getAllBindings(),查询当前节点的所有绑定
注意:绑定的标识符也就是可引用的标识符,换句话说,当前节能引用的标识符其都可以绑定
4.scope.hasReference(‘a’),查询当前节点是否有a的引用。返回一个Boolean 值
5.scope.getBindingIdentifier(‘a’),返回绑定的标识符本身,用处不大

