
- 1xray的使用教程_xray使用教程
- 2RabbitMQ ---- 死信队列_mq死信队列
- 3如何使用sourcetree + git将一个分支的最新推送变基到另一个分支上_sourcetree仓库分支推送到另外一个新仓库
- 4软开企服开源的JVS开发套件(V2.1.3)产品说明书_jvsbcom
- 5uniapp时间选择器
- 6Apollo 7周年大会:百度智能驾驶的展望与未来
- 7Llama-X开源!呼吁每一位NLPer参与推动LLaMA成为最先进的LLM
- 8kafka全部经验总结(待补充)_kafka实验一的总结
- 9Visual Studio2022中使用水晶报表
- 10超越NumPy和Pandas:3个鲜为人知的Python库_dask和pandas
时间序列预测模型实战案例(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测_时间序列 lstm 案例
赞
踩

论文地址->TPA-LSTM论文地址
项目地址-> TPA-LSTM时间序列预测实战案例

本文介绍
本文通过实战案例讲解TPA-LSTM实现多元时间序列预测,在本文中所提到的TPA和LSTM分别是注意力机制和深度学习模型,通过将其结合到一起实现时间序列的预测,本文利用有关油温的数据集来进行训练模型,同时将模型保存到本地,进行加载实现多步长预测,本文所利用的数据集也可以替换成你个人的数据集来进行预测(修改个人的数据集的地方本文也进行了标注),同时本文会对TPA和LSTM分别进行概念的讲解帮助大家理解其中的运行机制原理(包括个人总结已经论文内容)。
LSTM介绍
在开始实战讲解之前先来简单理解一下LSTM,其原理在我的另一篇博客中已经详细的讲解过了,这里只是简单的回顾,如果大家想要更深入的理解可以观看我的另一篇博客,地址如下->时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
LSTM的概念
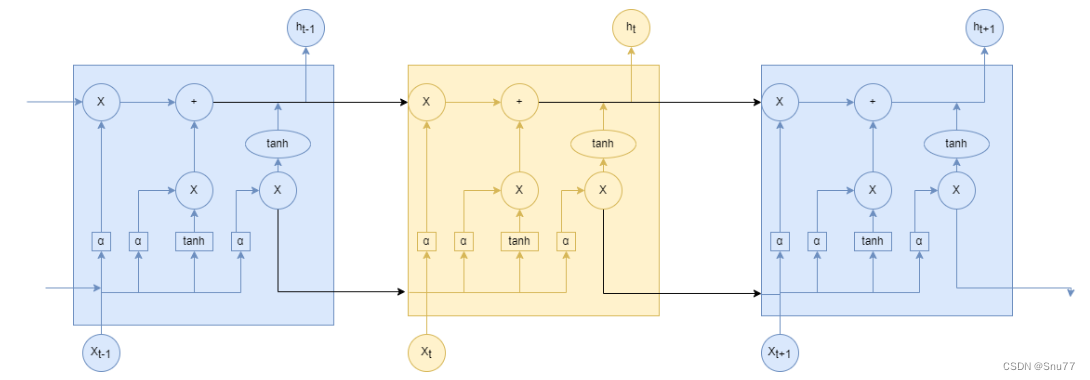
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。相对于普通的RNN,LSTM引入了门控机制,能够更有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一,LSTM的网络结构图如下图所示。
TPA机制介绍
本文主要介绍的是TPA注意力机制,LSTM在之前的文章中已经介绍过了,下面先来介绍一下其工作原理。
TPA的概念
TPA(Temporal Pattern Attention)注意力机制是一种用于处理时间序列数据的注意力机制。它的工作原理是在传统的注意力机制的基础上引入了时间模式的概念,以更好地捕捉时间序列中的重要模式和特征。
TPA的的工作步骤
TPA注意力机制的主要步骤如下:
1. 输入数据准备:给定一个时间序列数据,将其表示为X = {x1, x2, ..., xt},其中xi表示时间i处的观测值。
2. 特征提取:通过使用卷积神经网络,从时间序列中提取特征。这些特征可以是局部模式、全局趋势等。
3. 时间模式编码:将提取的特征序列传递给时间模式编码器。时间模式编码器通过学习时间序列中的重要模式和特征,生成一个编码向量序列。
4. 注意力计算:在时间模式编码器的输出上应用注意力机制。传统的注意力机制计算注意力权重,用于选择与当前时间步相关的信息。而TPA注意力机制通过计算注意力权重,选择与当前时间步相关的重要时间模式。
5. 上下文向量生成:根据注意力权重和时间模式编码器的输出,计算上下文向量。上下文向量是根据选择的重要时间模式加权求和的结果。
6. 预测生成:将上下文向量与其他信息(例如隐藏状态)进行拼接,然后通过适当的操作(如矩阵乘法)生成最终的预测结果。
如果大家觉得文字的描述不够直观,我们来看下图通过分析图片的形式来理解其工作原理。
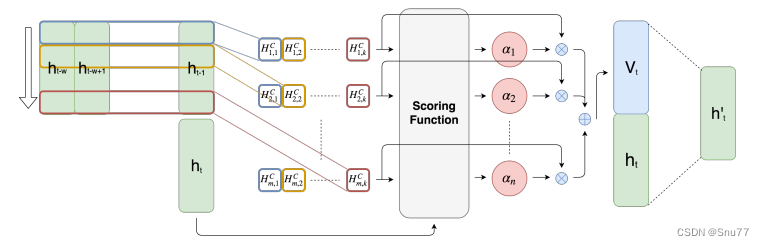
上图显示了TPA注意力机制从输入到输出的过程工作流程,其中表示时间步
处RNN的隐藏状态。有
个长度为
的
(注意是1维的并不像图像处理的2维或三维)滤波器,用不同颜色的矩形表示。然后,每个滤波器在
个隐藏状态特征上进行卷积,并生成一个具有
行和
列的矩阵
。接下来,评分函数通过与当前隐藏状态ht进行比较,为
的每一行计算一个权重。然后,权重进行归一化,
的行按照对应的权重进行加权求和,生成
。最后,我们将
、
进行拼接,并进行矩阵乘法生成
,用于创建最终的预测值。
个人总结->TPA注意力机制的关键创新点在于引入了时间模式编码和基于时间模式的注意力计算。这使得模型能够更好地理解和捕捉时间序列数据中的重要模式和特征,从而提高预测性能。
实战讲解
讲过上文中的简单介绍,大家对于LSTM和TPA机制应该有了一个简单的了解,本文是实战案例讲解,主要部分还是代码部分的应用,所以下面来进行实战案例的讲解。
项目结构构成
先来看一下我们的文件目录结构构成。
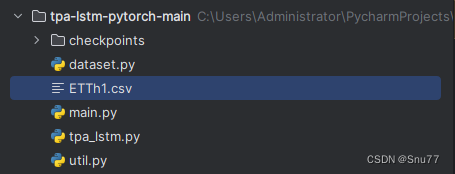
其中main.py文件为程序入口,dataset.py文件为数据处理的一些操作,tpa-lstm.pyp文件定义了我们的模型结构,util.py为定义的一些工具包,checkpoints为模型文件的保存文件夹,ETTh1.csv文件为数据集。
项目完整代码
为了方便讲解我把上面提到的几个代码先放到这里,文章的开头已经提供下载地址给大家了,如果大家不愿意下载可以按照项目结构构成复制即可。
main.py文件如下
- import lightning.pytorch as pl
- import matplotlib.pyplot as plt
- import pandas as pd
- from lightning.pytorch.callbacks import ModelCheckpoint
- from dataset import ElectricityDataModule
- from tpa_lstm import TPALSTM
-
-
- data_df = pd.read_csv('ETTh1.csv', index_col=['date'])
- num_features = data_df.shape[1]
-
-
- data_splits = {
- "train": 0.7,
- "val": 0.15,
- "predict": 0.15
- }
-
- pred_horizon = 4
-
- elec_dm = ElectricityDataModule(
- dataset_splits=data_splits,
- batch_size=128,
- window_size=24,
- pred_horizon=pred_horizon,
- data_style="custom"
- )
-
- run_name = f"{pred_horizon}ts-kbest30"
-
- hid_size = 64
- n_layers = 1
- num_filters = 3
-
-
- name = f'{run_name}-TPA-LSTM'
- checkpoint_loss_tpalstm = ModelCheckpoint(
- dirpath=f"checkpoints/{run_name}/TPA-LSTM",
- filename=name,
- save_top_k=1,
- monitor="val/loss",
- mode="min"
- )
-
- tpalstm_trainer = pl.Trainer(
- max_epochs=10,
- # accelerator='gpu',
- callbacks=[checkpoint_loss_tpalstm],
- strategy='auto',
- devices=1,
- # logger=wandb_logger_tpalstm
- )
-
- tpa_lstm = TPALSTM(
- input_size=num_features,
- hidden_size=hid_size,
- output_horizon=pred_horizon,
- num_filters=num_filters,
- obs_len=24,
- n_layers=n_layers,
- lr=1e-3
- )
-
- tpalstm_trainer.fit(tpa_lstm, elec_dm)
-
-
- elec_dm.setup("predict")
- run_to_load = run_name
- model_path = f"checkpoints/{run_to_load}/TPA-LSTM/{name}.ckpt"
- tpa_lstm = TPALSTM.load_from_checkpoint(model_path)
-
- pred_dl = elec_dm.predict_dataloader()
- y_pred = tpalstm_trainer.predict(tpa_lstm, pred_dl)
-
- batch_idx = 0
- start = 0
- end = 5
- for i, batch in enumerate(pred_dl):
- if start <= i <= end:
- inputs, labels = batch
- X, ytrue = inputs[batch_idx][:, -1], labels[batch_idx].squeeze()
- ypred = y_pred[i][batch_idx].squeeze()
-
- X = X.cpu().numpy()
- ytrue = ytrue.cpu().numpy()
- ypred = ypred.cpu().numpy()
-
- plt.figure(figsize=(8, 4))
- plt.plot(range(0, 24), X, label="Input")
- plt.scatter(range(24, 24 + pred_horizon), ytrue, color='cornflowerblue', label="True-Value")
- plt.scatter(range(24, 24 + pred_horizon), ypred, marker="x", color='green', label="TPA-LSTM pred")
- plt.legend(loc="lower left")
- plt.savefig("preds")
- plt.show()
- elif i > end:
- break
dataset.py文件如下 ->
- import math
- import pandas as pd
- import torch
- from torch.utils.data import Dataset, DataLoader
- import lightning.pytorch as pl
-
-
- class ElectricityDataset(Dataset):
- def __init__(
- self,
- mode,
- split_ratios,
- window_size,
- pred_horizon,
- data_style,
- ):
- self.w_size = window_size
- self.pred_horizon = pred_horizon
-
- if data_style == "pca":
- self.raw_dataset = pd.read_csv('ETTh1.csv',index_col=['date'])
- elif data_style == "kbest":
- self.raw_dataset = pd.read_csv('ETTh1.csv',index_col=['date'])
- elif data_style == "custom":
- self.raw_dataset = pd.read_csv('ETTh1.csv',index_col=['date'])
- else:
- print("Invalid dataset type")
- self.raw_dataset = None
-
- self.train_frac = split_ratios['train']
- self.val_frac = split_ratios['val']
- self.test_frac = split_ratios['predict']
-
- self.train_lim = math.floor(self.train_frac * self.raw_dataset.shape[0])
- self.val_lim = math.floor(self.val_frac * self.raw_dataset.shape[0]) + self.train_lim
-
- if mode == "train":
- self.dataset = self.raw_dataset[:self.train_lim]
- if mode == "val":
- self.dataset = self.raw_dataset[self.train_lim:self.val_lim]
- if mode == "predict":
- self.dataset = self.raw_dataset[self.val_lim:]
-
- self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- data_array = self.dataset.values
- # self.X = torch.tensor(self.dataset[:, :-1], dtype=torch.float32).to(self.device)
- self.X = torch.tensor(data_array, dtype=torch.float32).to(self.device)
- self.y = torch.tensor(data_array[:, -1], dtype=torch.float32) \
- .unsqueeze(1).to(self.device)
-
- def __getitem__(self, idx):
- return (
- self.X[idx:idx + self.w_size, :],
- self.y[idx + self.w_size: idx + self.w_size + self.pred_horizon]
- )
-
- def __len__(self):
- # TODO Check this is correct
- return len(self.dataset) - (self.w_size + self.pred_horizon)
-
- def get_input_size(self):
- return self.dataset.shape[1]
-
-
- class ElectricityDataModule(pl.LightningDataModule):
- def __init__(
- self,
- dataset_splits,
- batch_size=64,
- window_size=24,
- pred_horizon=1,
- data_style="pca"
- ):
- super().__init__()
- self.batch_size = batch_size
- self.dataset_splits = dataset_splits
- self.window_size = window_size
- self.pred_horizon = pred_horizon
- self.data_style=data_style
-
-
- def setup(self, stage):
- if stage == "fit":
- self.data_train = ElectricityDataset(
- mode="train",
- split_ratios=self.dataset_splits,
- window_size=self.window_size,
- pred_horizon=self.pred_horizon,
- data_style=self.data_style
- )
- self.data_val = ElectricityDataset(
- mode="val",
- split_ratios=self.dataset_splits,
- window_size=self.window_size,
- pred_horizon=self.pred_horizon,
- data_style=self.data_style
-
- )
- elif stage == "predict":
- self.data_pred = ElectricityDataset(
- mode="predict",
- split_ratios=self.dataset_splits,
- window_size=self.window_size,
- pred_horizon=self.pred_horizon,
- data_style=self.data_style
- )
-
- def train_dataloader(self):
- return DataLoader(self.data_train, batch_size=self.batch_size, shuffle=False)
-
- def val_dataloader(self):
- return DataLoader(self.data_val, batch_size=self.batch_size, shuffle=False)
-
- def predict_dataloader(self):
- return DataLoader(self.data_pred, batch_size=self.batch_size, shuffle=False)
tpa_lstm.py文件如下->
- import torch
- from torch import nn, optim
- import lightning.pytorch as pl
-
- from util import RMSE, RSE, CORR
-
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-
- class TPALSTM(pl.LightningModule):
-
- def __init__(self, input_size, output_horizon, num_filters, hidden_size, obs_len, n_layers, lr=1e-3):
- super(TPALSTM, self).__init__()
- self.hidden = nn.Linear(input_size, 24)
- self.relu = nn.ReLU()
- self.lstm = nn.LSTM(input_size, hidden_size, n_layers, \
- bias=True, batch_first=True) # output (batch_size, obs_len, hidden_size)
- self.hidden_size = hidden_size
- self.filter_num = num_filters
- self.filter_size = 1 # Don't change this - otherwise CNN filters no longer 1D
- self.output_horizon = output_horizon
- self.attention = TemporalPatternAttention(self.filter_size, \
- self.filter_num, obs_len - 1, hidden_size)
- self.mlp_out = nn.Sequential(
- nn.Linear(hidden_size, hidden_size // 2),
- self.relu,
- nn.Dropout(p=0.2),
- nn.Linear(hidden_size // 2, output_horizon)
- )
- self.linear = nn.Linear(hidden_size, output_horizon)
- self.n_layers = n_layers
-
- self.lr = lr
- self.criterion = nn.MSELoss()
-
- self.save_hyperparameters()
-
-
- def forward(self, x):
- batch_size, obs_len, f_dim = x.size()
-
- H = torch.zeros(batch_size, obs_len - 1, self.hidden_size).to(device)
- ht = torch.zeros(self.n_layers, batch_size, self.hidden_size).to(device)
- ct = ht.clone()
- for t in range(obs_len):
- xt = x[:, t, :].view(batch_size, 1, -1)
- out, (ht, ct) = self.lstm(xt, (ht, ct))
- htt = ht.permute(1, 0, 2)
- htt = htt[:, -1, :]
- if t != obs_len - 1:
- H[:, t, :] = htt
- H = self.relu(H)
-
- # reshape hidden states H
- H = H.view(-1, 1, obs_len - 1, self.hidden_size)
- new_ht = self.attention(H, htt)
- ypred = self.linear(new_ht).unsqueeze(-1)
- # ypred = self.mlp_out(new_ht).unsqueeze(-1)
-
- return ypred
-
-
- def training_step(self, batch, batch_idx):
- inputs, label = batch
-
- outputs = self.forward(inputs)
- loss = self.criterion(outputs, label)
- corr = CORR(outputs, label)
- rse = RSE(outputs, label)
-
- self.log("train/loss", loss, prog_bar=True, on_epoch=True, on_step=False)
- self.log("train/corr", corr, prog_bar=True, on_epoch=True, on_step=False)
- self.log("train/rse", rse, prog_bar=True, on_epoch=True, on_step=False)
-
- return loss
-
- def validation_step(self, batch, batch_idx):
- inputs, label = batch
-
- outputs = self.forward(inputs)
- loss = self.criterion(outputs, label)
- corr = CORR(outputs, label)
- rse = RSE(outputs, label)
-
- self.log("val/loss", loss, prog_bar=True, on_epoch=True, on_step=False)
- self.log("val/corr", corr, prog_bar=True, on_epoch=True, on_step=False)
- self.log("val/rse", rse, prog_bar=True, on_epoch=True, on_step=False)
-
- def predict_step(self, batch, batch_idx):
- inputs, label = batch
- pred = self.forward(inputs)
-
- return pred
-
- def configure_optimizers(self):
- optimiser = optim.Adam(
- self.parameters(),
- lr=self.lr,
- amsgrad=False,
- # weight_decay=1e-4,
- )
- return optimiser
-
-
- class TemporalPatternAttention(nn.Module):
-
- def __init__(self, filter_size, filter_num, attn_len, attn_size):
- super(TemporalPatternAttention, self).__init__()
- self.filter_size = filter_size
- self.filter_num = filter_num
- self.feat_size = attn_size - self.filter_size + 1
- self.conv = nn.Conv2d(1, filter_num, (attn_len, filter_size))
- self.linear1 = nn.Linear(attn_size, filter_num)
- self.linear2 = nn.Linear(attn_size + self.filter_num, attn_size)
- self.relu = nn.ReLU()
-
- def forward(self, H, ht):
- _, channels, _, attn_size = H.size()
- new_ht = ht.view(-1, 1, attn_size)
- w = self.linear1(new_ht) # batch_size, 1, filter_num
- conv_vecs = self.conv(H)
-
- conv_vecs = conv_vecs.view(-1, self.feat_size, self.filter_num)
- conv_vecs = self.relu(conv_vecs)
-
- # score function
- w = w.expand(-1, self.feat_size, self.filter_num)
- s = torch.mul(conv_vecs, w).sum(dim=2)
- alpha = torch.sigmoid(s)
- new_alpha = alpha.view(-1, self.feat_size, 1).expand(-1, self.feat_size, self.filter_num)
- v = torch.mul(new_alpha, conv_vecs).sum(dim=1).view(-1, self.filter_num)
-
- concat = torch.cat([ht, v], dim=1)
- new_ht = self.linear2(concat)
- return new_ht
util.py文件如下->
- #!/usr/bin/python 3.6
- #-*-coding:utf-8-*-
-
- '''
- Utility functions
- '''
- import torch
- import numpy as np
- import os
- import random
-
- def get_data_path():
- folder = os.path.dirname(__file__)
- return os.path.join(folder, "data")
-
- def RSE(ypred, ytrue):
- if isinstance(ypred, np.ndarray):
- rse = np.sqrt(np.square(ypred - ytrue).sum()) / \
- np.sqrt(np.square(ytrue - ytrue.mean()).sum())
- else:
- rse = torch.sqrt(torch.square(ypred - ytrue).sum()) / \
- torch.sqrt(torch.square(ytrue - ytrue.mean()).sum())
- return rse
-
- def RMSE(ypred, ytrue):
- return torch.sqrt(torch.mean(torch.sum(torch.square(ypred - ytrue), dim=1)))
-
- def CORR(ypred, ytrue):
- if isinstance(ypred, np.ndarray):
- vx = ypred - np.mean(ypred)
- vy = ytrue - np.mean(ytrue)
- return np.sum(vx * vy) / (np.sqrt(np.sum(vx ** 2)) * np.sqrt(np.sum(vy ** 2)))
- else:
- vx = ypred - torch.mean(ypred)
- vy = ytrue - torch.mean(ytrue)
- return torch.sum(vx * vy) / (torch.sqrt(torch.sum(vx ** 2)) * torch.sqrt(torch.sum(vy ** 2)))
-
- def quantile_loss(ytrue, ypred, qs):
- '''
- Quantile loss version 2
- Args:
- ytrue (batch_size, output_horizon)
- ypred (batch_size, output_horizon, num_quantiles)
- '''
- L = np.zeros_like(ytrue)
- for i, q in enumerate(qs):
- yq = ypred[:, :, i]
- diff = yq - ytrue
- L += np.max(q * diff, (q - 1) * diff)
- return L.mean()
-
- def SMAPE(ytrue, ypred):
- ytrue = np.array(ytrue).ravel()
- ypred = np.array(ypred).ravel() + 1e-4
- mean_y = (ytrue + ypred) / 2.
- return np.mean(np.abs((ytrue - ypred) \
- / mean_y))
-
- def MAPE(ytrue, ypred):
- ytrue = np.array(ytrue).ravel() + 1e-4
- ypred = np.array(ypred).ravel()
- return np.mean(np.abs((ytrue - ypred) \
- / ytrue))
-
- def train_test_split(X, y, train_ratio=0.7):
- num_ts, num_periods, num_features = X.shape
- train_periods = int(num_periods * train_ratio)
- random.seed(2)
- Xtr = X[:, :train_periods, :]
- ytr = y[:, :train_periods]
- Xte = X[:, train_periods:, :]
- yte = y[:, train_periods:]
- return Xtr, ytr, Xte, yte
-
- class StandardScaler:
-
- def fit_transform(self, y):
- self.mean = np.mean(y)
- self.std = np.std(y) + 1e-4
- return (y - self.mean) / self.std
-
- def inverse_transform(self, y):
- return y * self.std + self.mean
-
- def transform(self, y):
- return (y - self.mean) / self.std
-
- class MaxScaler:
-
- def fit_transform(self, y):
- self.max = np.max(y)
- return y / self.max
-
- def inverse_transform(self, y):
- return y * self.max
-
- def transform(self, y):
- return y / self.max
-
-
- class MeanScaler:
-
- def fit_transform(self, y):
- self.mean = np.mean(y)
- return y / self.mean
-
- def inverse_transform(self, y):
- return y * self.mean
-
- def transform(self, y):
- return y / self.mean
-
- class LogScaler:
-
- def fit_transform(self, y):
- return np.log1p(y)
-
- def inverse_transform(self, y):
- return np.expm1(y)
-
- def transform(self, y):
- return np.log1p(y)
-
-
- def gaussian_likelihood_loss(z, mu, sigma):
- '''
- Gaussian Liklihood Loss
- Args:
- z (tensor): true observations, shape (num_ts, num_periods)
- mu (tensor): mean, shape (num_ts, num_periods)
- sigma (tensor): standard deviation, shape (num_ts, num_periods)
- likelihood:
- (2 pi sigma^2)^(-1/2) exp(-(z - mu)^2 / (2 sigma^2))
- log likelihood:
- -1/2 * (log (2 pi) + 2 * log (sigma)) - (z - mu)^2 / (2 sigma^2)
- '''
- negative_likelihood = torch.log(sigma + 1) + (z - mu) ** 2 / (2 * sigma ** 2) + 6
- return negative_likelihood.mean()
-
- def negative_binomial_loss(ytrue, mu, alpha):
- '''
- Negative Binomial Sample
- Args:
- ytrue (array like)
- mu (array like)
- alpha (array like)
- maximuze log l_{nb} = log Gamma(z + 1/alpha) - log Gamma(z + 1) - log Gamma(1 / alpha)
- - 1 / alpha * log (1 + alpha * mu) + z * log (alpha * mu / (1 + alpha * mu))
- minimize loss = - log l_{nb}
- Note: torch.lgamma: log Gamma function
- '''
- batch_size, seq_len = ytrue.size()
- likelihood = torch.lgamma(ytrue + 1. / alpha) - torch.lgamma(ytrue + 1) - torch.lgamma(1. / alpha) \
- - 1. / alpha * torch.log(1 + alpha * mu) \
- + ytrue * torch.log(alpha * mu / (1 + alpha * mu))
- return - likelihood.mean()
-
- def batch_generator(X, y, num_obs_to_train, seq_len, batch_size):
- '''
- Args:
- X (array like): shape (num_samples, num_features, num_periods)
- y (array like): shape (num_samples, num_periods)
- num_obs_to_train (int):
- seq_len (int): sequence/encoder/decoder length
- batch_size (int)
- '''
- num_ts, num_periods, _ = X.shape
- if num_ts < batch_size:
- batch_size = num_ts
- t = random.choice(range(num_obs_to_train, num_periods-seq_len))
- batch = random.sample(range(num_ts), batch_size)
- X_train_batch = X[batch, t-num_obs_to_train:t, :]
- y_train_batch = y[batch, t-num_obs_to_train:t]
- Xf = X[batch, t:t+seq_len]
- yf = y[batch, t:t+seq_len]
- return X_train_batch, y_train_batch, Xf, yf
项目网络结构
本项目的网络结构图如下所示在控制台输出了大家如果想要修改可以在其中的对应的位置添加或删除都可以。

代码讲解
训练部分
我们首先来看main.py文件我也只会讲解这一个文件,(因为代码很多,如果大家有需要我后期会出视频带着大家过一遍其中的代码),;
main.py文件的内容不是很多,首先最上面的模块导入部分,我不讲解了,前面有我应用的版本,大家如果有一些版本报错的话可以参考。
- data_df = pd.read_csv('ETTh1.csv', index_col=['date'])
- num_features = data_df.shape[1]
这两行代码就是数据的读取操作,以及获取数据的特征数,因为我们是多元预测,数据肯定不只一列,所以我们要告诉模型我们的输入有多少列模型好做多少列的预测。
- data_splits = {
- "train": 0.7,
- "val": 0.15,
- "predict": 0.15
- }
这几行是数据集的一个划分,大家应该都明白。这里训练集划分为模型的0.7、验证集为0.15、测试集为0.15。
pred_horizon = 4
这个参数就是你预测未来数据的长度,假设你数据集的时间是按照小时来划分,那么如果输入4就是未来四小时的一个情况。
- elec_dm = ElectricityDataModule(
- dataset_splits=data_splits,
- batch_size=128,
- window_size=24,
- pred_horizon=pred_horizon,
- data_style="custom"
- )
这个部分是一个数据加载器定义的一个过程,其中我们的data_splits上面讲过了,batch_size就是你往模型里面一次输入的数据长度,window_size是你用多少条数据预测未来一条数据,pred_horizon上面也讲过了,custom是你数据加载器定义的形式这里大家不用理会。
- hid_size = 64
- n_layers = 1
- num_filters = 3
这三个参数是定义模型的参数,其中hid_size是隐藏层的单元数如果不理解可以看前面提到的LSTM讲解博客,n_layers是其中LSTM的层数,num_filters是TPA注意力机制中卷积的一个形状。
- name = f'{run_name}-TPA-LSTM'
- checkpoint_loss_tpalstm = ModelCheckpoint(
- dirpath=f"checkpoints/{run_name}/TPA-LSTM",
- filename=name,
- save_top_k=1,
- monitor="val/loss",
- mode="min"
- )
这一部分是模型保存部分不进行讲解了,大家有兴趣可以自己debug看看就是保存模型文件。
- tpalstm_trainer = pl.Trainer(
- max_epochs=10,
- # accelerator='gpu',
- callbacks=[checkpoint_loss_tpalstm],
- strategy='auto',
- devices=1,
- # logger=wandb_logger_tpalstm
- )
这一部分定义了一些训练中的参数,其中max_epochs就是训练10轮的意思。
- tpa_lstm = TPALSTM(
- input_size=num_features,
- hidden_size=hid_size,
- output_horizon=pred_horizon,
- num_filters=num_filters,
- obs_len=24,
- n_layers=n_layers,
- lr=1e-3
- )
这一部分就是定义的一些参数前面定义的全部输入到模型里面。
tpalstm_trainer.fit(tpa_lstm, elec_dm)这个就是模型训练的操作,执行到这里模型就开始训练了。
预测部分
上一小节讲解的是训练的过程,现在开始详解预测的过程,代码也是在main.py文件中。
- elec_dm.setup("predict")
- run_to_load = run_name
- model_path = f"checkpoints/{run_to_load}/TPA-LSTM/{name}.ckpt"
- tpa_lstm = TPALSTM.load_from_checkpoint(model_path)
我们先选择预测模式,然后下载上一小节训练的模型,
- pred_dl = elec_dm.predict_dataloader()
- y_pred = tpalstm_trainer.predict(tpa_lstm, pred_dl)
这一部分就是进行预测,其中第一行为数据加载器,如果大家感兴趣可以看看dataset.py文件其中有注释。然后我们调用了前面加载的模型其中的predict方法进行预测 ,运行之后我们的预测结果就保存到了y_pred中了已经。
结果分析
- batch_idx = 0
- start = 0
- end = 5
- for i, batch in enumerate(pred_dl):
- if start <= i <= end:
- inputs, labels = batch
- X, ytrue = inputs[batch_idx][:, -1], labels[batch_idx].squeeze()
- ypred = y_pred[i][batch_idx].squeeze()
-
- X = X.cpu().numpy()
- ytrue = ytrue.cpu().numpy()
- ypred = ypred.cpu().numpy()
-
- plt.figure(figsize=(8, 4))
- plt.plot(range(0, 24), X, label="Input")
- plt.scatter(range(24, 24 + pred_horizon), ytrue, color='cornflowerblue', label="True-Value")
- plt.scatter(range(24, 24 + pred_horizon), ypred, marker="x", color='green', label="TPA-LSTM pred")
- plt.legend(loc="lower left")
- plt.savefig("preds")
- plt.show()
- elif i > end:
- break
这一部分就是画图功能了,最后我们预测结果全部会以图片的形式输出出来,因为我输入的数据形状是7列这里就生成了七张图片,如下所示->

总结
到此本文就全部讲解结束了,希望能够帮助大家,最后推荐几篇我的其它时间序列实战案例
其它时间序列预测模型的讲解!
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析
时间序列预测模型实战案例(五)基于双向LSTM横向搭配单向LSTM进行回归问题解决
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!


