
热门标签
热门文章
- 1MySQL - 左连接、右连接、内连接、完全外连接、交叉连接 & 一对多、多对一、多对多 & 联合连接_mysql左连接语句
- 2联盛德 HLK-W806 (十二): Makefile组织结构和编译流程说明_foreach bin
- 3Android ANR 问题和流程排查详解_android线程阻塞查看
- 4secure boot(三)secure boot的签名和验签方案_芯片boot验签
- 5【C++MiNiSTL项目开发笔记】
- 6python 安装openai的踩坑史_openai 需要python什么版本
- 7C-构造类型-共用体-枚举
- 8Python3 如何反编译EXE_python exe 反编译
- 9第二章Linux集群(1)
- 10实例讲解如何使用Jekyll搭建一个静态网站_jekyll教程
当前位置: article > 正文
Flink1.9.1,scala2.12连接kafka2.11_2.40实例_can't resolve address: flink:9092
作者:Cpp五条 | 2024-05-22 04:46:43
赞
踩
can't resolve address: flink:9092
1.添加相关依赖
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka_2.12</artifactId>
- <version>1.9.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-scala_2.12</artifactId>
- <version>1.9.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-scala_2.12</artifactId>
- <version>1.9.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-core</artifactId>
- <version>1.9.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.13</artifactId>
- <version>2.4.0</version>
- </dependency>

2.创建scala类,并开发代码
- package com.vincer
-
- import java.util.Properties
-
- import org.apache.flink.api.common.serialization.SimpleStringSchema
-
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
- // flatMap和Map需要引用的隐式转换
- import org.apache.flink.api.scala._
-
- /**
- * @Package com.vincer
- * @ClassName conkafka
- * @Author Vincer
- * @Date 2020/01/13 22:31
- * @ProjectName kafka-flink
- */
- object conkafka {
-
- def main(args: Array[String]): Unit = {
- val kafkaProps = new Properties()
- //kafka的一些属性
- kafkaProps.setProperty("bootstrap.servers", "hadoop100:9092")
- //所在的消费组
- kafkaProps.setProperty("group.id", "group_test")
- //获取当前的执行环境
- val evn = StreamExecutionEnvironment.getExecutionEnvironment
- //kafka的consumer,test1是要消费的topic
- val kafkaSource = new FlinkKafkaConsumer[String]("test1", new SimpleStringSchema, kafkaProps)
- //设置从最新的offset开始消费
- //kafkaSource.setStartFromLatest()
- //自动提交offset
- kafkaSource.setCommitOffsetsOnCheckpoints(true)
-
- //flink的checkpoint的时间间隔
- evn.enableCheckpointing(5000)
- //添加consumer
- val stream = evn.addSource(kafkaSource)
- stream.setParallelism(3)
- val text = stream
-
-
- text.print()
- //启动执行
- evn.execute("kafkawd")
- }
- }
3.启动zookeeper,kafka
(过程免)
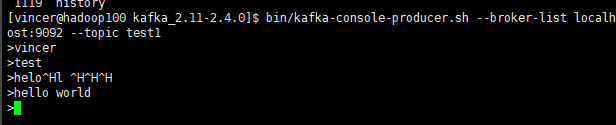
4.启动kafka的Client生产数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1
5.运行代码

6.在kafka上生产数据,打印到IDEA的控制台

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/606392
推荐阅读
相关标签

