
- 1如何在Sublime Test中注册并去掉烦人的更新提示_sublime test 注册码
- 2【使用Neo4j进行图数据可视化】_neo4j 可视化动态
- 3当前最流行的架构设计模式
- 4爆肝三天,我整理了这份春招攻略【针对大三/研二】_大三春招和大四春招区别
- 5消息队列技术选型(Kafka + RocketMQ)_kafka和rocketmq可以同时用嘛
- 6动态规划最多任务工资java_五大常用算法之二:动态规划算法,会用的程序员工资都翻倍了...
- 7数据结构之链表详解_链表数据结构
- 8AliOS-Things--ESP8266 (10)OTA在线升级_alios fota升级版本号的更新
- 9px4在环仿真实践操作_如何用遥控器控制硬件在环仿真
- 10论Oracle 11g安装完成步骤及详解+干净卸载方法_oracle直接安装结束
【论文精读】ECCV2020 - 带有圆平滑标签的定向目标检测_circular smooth label
赞
踩
【论文精读】ECCV2020 - 带有圆平滑标签的定向目标检测
【论文原文】:Arbitrary-Oriented Object Detection with Circular Smooth Label
获取地址:https://arxiv.org/pdf/2003.05597v1.pdf
博主关键词: 旋转检测,角度分类预测,原平滑标签,角度边界,角度周期
推荐相关论文:
-无
- 设计了一种新的旋转检测baseline。设计了基于粗粒度的高精度角度分类,通过将角度预测从回归问题转化为精度损失小的分类任务来解决边界问题;提出了一种圆形光滑标签(CSL)技术来处理角度的周期性。
- 论点:
- 提出现有的基于回归的旋转检测器存在不连续边界问题,边界不连续问题往往是由五参数方法的角周期性和八参数方法的角排序引起的,并证明根本原因是理想的预测超出了定义的范围。
- 边界不连续问题常常使模型在边界处的损失值突然增大。
- 角周期性会导致proposal回归至预测框(或者gt框)的难度增加,回归过程更加复杂(但我还不是特别理解为什么会这样,导致这种情况的具体过程)
- 实现过程:
- 将角度范围(例如180°)分为若干类别,每个类别都包含w°(默认为1°),会造成一定的角度损失,最大为w/2,期望为w/4,但造成的IoU损失很小。对角度按类别进行预测,解决了边界问题,预测的角度不会超出限定的角度类别范围,但使用基于90°回归方法时EoE问题仍然存在,且每个类别的loss相同,对角度差较大的惩罚不够。
- 在角度分类的基础上设计了CSL,在基于90°回归方法时,我的理解是0°和90°接在了一起,避免了EoE问题,且加入g(x),角度相差越大,loss越大。
0. Abstract
定向目标检测因其在航空图像、场景文本和面部识别等方面的重要性,近年来受到越来越多的关注。在本文中,我们证明了现有的基于回归的旋转检测器存在不连续边界问题,这是直接由角周期性或角排序引起的。通过仔细的研究,我们发现其根本原因是理想的预测超出了所定义的范围。我们设计了一种新的旋转检测baseline,通过将角度预测从回归问题转化为精度损失小的分类任务来解决边界问题,从而设计了基于粗粒度的高精度角度分类。我们还提出了一种圆形光滑标签(CSL)技术来处理角度的周期性,并增加对相邻角度的容错性。我们进一步在CSL中引入了四个窗口函数,并探讨了不同窗口半径大小对检测性能的影响。在两个大规模公共数据集上进行广泛的实验和视觉分析,即DOTA,HRSC2016。该代码将在https: //github.com/Thinklab-SJTU/CSL_RetinaNet_Tensorflow上开源。
1. Introduction
目标检测是计算机视觉中的基本任务之一。特别是旋转检测在航空图像[2,4,41,42,44]、场景文本[12,18,19,24,27,49]和面部识别[11,33,34]领域发挥了巨大的作用。旋转检测器能够提供准确的方向和尺度信息,有助于航空图像中的目标变化检测和多方向场景文本中的序列字符识别等应用。
最近,一种由经典检测算法[3,7,20,21,32]发展而来的先进旋转检测器被提出。在这些方法中,基于区域回归的检测器成为主流,通过旋转边界框或四边形来实现多向目标的表示。虽然这些旋转检测器取得了很好的效果,但仍存在一些基本问题。具体地说,我们注意到五参数回归和八参数回归方法都存在不连续边界的问题,这通常是由角周期性或角排序引起的。然而,其固有的原因并不局限于边界框的特定表示。本文认为,基于回归方法的边界问题的根本原因是理想的预测超出了所定义的范围。因此,模型在边界处的损失值突然增加,使得模型无法以最简单、最直接的方式获得预测结果,往往需要额外的更复杂的处理。因此,这些检测器在边界条件下往往具有困难。使用旋转边界框进行检测时,角度预测的准确性至关重要。轻微的角度偏差会导致重要的交叉过联合(IoU)下降,导致不准确的目标检测,特别是在大长宽比的情况下。
有一些工作解决边界问题。例如,IoU-平滑L1 [44]损失引入了IoU因子,modular旋转损失[30]增加了边界约束,消除了边界损失的突然增加,降低了模型学习的难度。但是,这些方法仍然是基于回归的检测方法,仍然没有解决上述的根本原因。
本文旨在寻找一个更基本的旋转检测baseline来解决边界问题。具体来说,我们将目标角度的预测作为一个分类问题,以更好地限制预测结果,然后设计了一个圆形光滑标签(CSL)来解决角度的周期性,增加相邻角度之间的容错性。虽然从连续回归到离散分类的转换,但由于loss的准确性对旋转检测任务的影响可以忽略不计。我们还在CSL中引入了四个窗口函数,并探讨了不同窗口半径大小对检测性能的影响。经过大量的实验和视觉分析,我们发现在不同的检测器和数据集上,基于CSL的旋转检测算法确实是一个比基于角度回归的方法更好的baseline选择。注意后续章节中提到的基于回归和基于CSL的方法是根据角度的预测形式进行划分的。
综上所述,本文的主要贡献有四个方面:
1)我们总结了不同的基于回归的旋转检测方法[2,4,41,42]中的边界问题,并证明了其根本原因是理想的预测超出了所定义的范围。
2)我们设计了一种新的旋转检测baseline,将角度预测从回归问题转化为分类问题。具体来说,据我们所知,我们在旋转检测中设计了第一个基于高精度角度(小于1度)分类的管道,而不是之前的粗分类粒度(约10度)方法[33]。与基于回归的方法相比,该方法的精度损失较小,可以有效地消除边界问题。
3)我们还提出了圆形光滑标签(CSL)技术,作为一个独立的模块,它也可以很容易地重用于现有的基于回归的方法,用分类代替回归,以解决边界条件和具有大高宽比的对象的角预测。
4)在DOTA和HRSC2016上的广泛实验结果显示了我们的探测器的最先进的性能,并且我们的CSL技术作为一个独立组件的有效性已经在不同的探测器上得到了验证。
2. Related Work
Horizontal region object detection.
经典的目标检测方法是检测具有水平边界框的图像中的一般目标,并提出了许多高性能的通用目标检测方法。R-CNN [8]开创了一种基于CNN检测的方法。随后,提出了基于区域的模型,如Fast R-CNN [7]、Faster R-CNN [32]和R-FCN [3],在提高检测速度的同时减少了计算存储。FPN [20]主要研究图像中目标的尺度方差,提出了特征金字塔网络来处理不同尺度下的目标。SSD [23]、YOLO [31]和RetinaNet [21]是具有代表性的单级方法,其单级结构允许它们具有更快的检测速度。与基于锚的方法相比,近年来许多无锚的方法变得非常流行。CornerNet[15]、CenterNet[5]和ExtremeNet[48]试图预测目标的一些关键关键点,如角或极端点,然后将这些关键点分组为边界框。然而,水平检测器并不能提供准确的方向和尺度信息,这在航空图像中的目标变化检测和多方向场景文本中的序列字符的识别等实际应用中提出了问题。
Arbitrary-oriented object detection.
航空图像和场景文本是旋转检测器的主要应用场景。多向目标检测的最新进展主要是经典的目标检测方法使用旋转的边界框或四边形来表示多向目标。由于遥感图像场景的复杂性和大量的小、杂乱和旋转的物体,多级旋转检测器因其鲁棒性仍占主导地位。其中,ICN [2]、ROI-Transformer[4]、SCRDet [41]、R3Det [41]都是最先进的检测器。Gliding Vertex[40]和RSDet [30]通过四边形回归预测实现了更准确的目标检测。对于场景文本检测,RRPN [27]使用旋转的RPN来生成旋转的proposals,并进一步进行旋转的边界框回归。TextBoxes++[18]在SSD上采用顶点回归。RRD [19]分别在旋转不变特征和旋转敏感特征上解耦分类和边界框回归,进一步改进了TextBoxes++。虽然基于回归的定向目标检测方法占据了主流,但我们发现这些方法由于回归位置超出了定义的范围,都存在一些边界问题。因此,我们设计了一种新的旋转检测baseline,通过将角度预测从回归问题转化为精度损失较小的分类问题,基本消除了边界问题。
Classifification for orientation information.
通过分类获得方向信息的方法早期用于任意平面旋转(RIP)角度的多视图人脸检测。[11]采用了分而治之的方法,它使用几个小的神经网络来单独处理小范围的面部外观变化。在[33]中,首先使用一个路由器网络来估计每个候选人脸的RIP角。PCN [34]逐步校准每个候选面孔的RIP方向,并在早期阶段将RIP范围缩小一半。最后,PCN对每个候选人脸做出准确的最终决定,以确定它是否为一个人脸,并预测精确的RIP角。在其他研究领域,[14]采用序数回归或有效的未来运动分类。[43]通过对四面进行分类,获得船舶的方向信息。上述方法都是通过分类获得近似的方向范围,但不能直接应用于需要精确方向信息的场景,如航空图像和场景文本。
3. Proposed Method
我们在Figure. 1概述了我们的方法。本实例是基于RetinaNet[21]的单级旋转检测器。图中显示了一个多任务流程(pipeline),包括基于回归的预测分支和基于CSL的预测分支,便于比较两种方法的性能。从图中可以看出,基于CSL的方法对学习物体的方向和尺度信息更为准确。需要注意的是,本文提出的方法适用于大多数基于回归的方法,这已经在FPN [20]检测器的实验中得到了验证。

3.1. Regression-based Rotation Detection Method.
参数回归是目前常用的旋转目标检测方法,主要包括基于五参数回归的方法[4、12、27、41 42、44]和基于八参数回归的方法[18,25,30,40]。常用的基于五参数回归的方法通过附加一个角度参数θ来实现定向边界框检测。Figure. 2(a)显示了其中一个矩形定义(x, y, w, h, θ),其角范围为90◦,[27,41,42,44],θ表示与x轴的锐角,对于另一侧,我们称之为w。它应该与Figure. 2(b)中所示的另一个定义(x, y, w, h, θ) 有所区别,其角范围为180◦,[4,27],其θ由矩形的长边(h)和x轴决定。基于八参数回归的检测器直接回归目标的四个角(x1, y1, x2, y2, x3, y3, x4, y4),因此预测是一个四边形。四边形回归的关键步骤是提前对四个角点进行排序,如果预测是正确的,可以避免非常大的损失,如Figure. 2(c)所示。
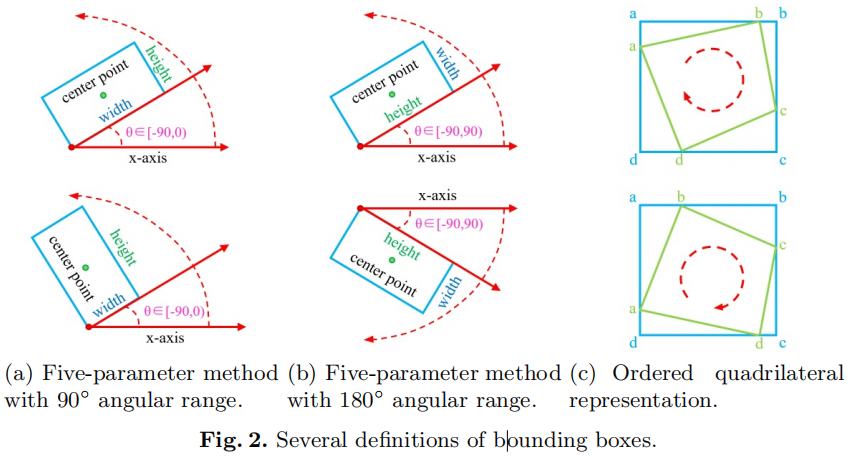
3.2. Boundary Problem of Regression Method.
虽然基于参数回归的旋转检测方法在不同的视觉任务中取得了具有竞争力的性能,并且已经成为许多优秀检测方法的基础,但这些方法本质上存在不连续边界问题[30,44]。边界不连续问题往往是由五参数方法的角周期性和八参数方法的角排序引起的,但无论边界框的表示选择如何,都存在更多的根本原因。
边界不连续问题常常使模型在边界处的损失值突然增大。因此,方法必须采用特殊且通常是复杂的技巧来缓解这个问题。因此,这些检测方法在边界条件下往往不准确。我们根据基于回归方法的三类典型的不同表示形式来描述边界问题(前两种是五参数方法):
1)90° - regression-based method,如Figure. 3(a)所示,它表明,一个理想的回归(蓝色框逆时针旋转至红色框),但这种情况的损失是非常大的,由于角的周期性(PoA)和边缘的互换性(EoE),见Figure. 3(a)和Eqn. 3,4,5的细节。因此,模型必须以其他复杂的形式进行回归(如蓝框在缩放w和h时顺时针旋转到灰框),这增加了回归的难度。
2)180° - regression-based method,如Figure. 3(b)所示,同样,该方法也存在由边界处的PoA造成的损失急剧增加的问题。模型最终将选择顺时针旋转一个大角度,以得到最终的预测边界框。
3)Point-based method,如Figure. 3(c)所示,通过进一步的分析,由于角点的提前排序,在八参数回归方法中仍然存在边界不连续问题。考虑八参数回归的情况下,理想的回归过程应该是{(a→b),(b→c),(c→d),(d→a)},但实际的从蓝色参考框到绿色地面真实框的回归过程是{(a→a),(b→b),(c→c),(d→d)}。事实上,这种情况也属于PoA。相比之下,蓝色到红色边界框的实际和理想回归是一致的。

在上述分析的基础上,提出了一些解决这些问题的方法。例如,IoU-平滑L1 [44]损失引入了IoU因子,modular旋转损失[30]增加了边界约束,以消除边界损失的突然增加,降低了模型学习的难度。然而,这些方法仍然是基于回归的检测方法,并没有从根本原因上给出解决方案。在本文中,我们将从一个新的角度开始,用分类代替回归,以实现更好和更鲁棒的旋转检测器。我们重现了一些基于回归的经典旋转检测器,并在边界条件下对它们进行了可视化比较,如Figure. 4(a)和Figure. 4(e)所示。相比之下,基于CLS的方法没有边界问题,如Figure. 4(i)所示。

3.3. Circular Smooth Label for Angular Classifification.
基于回归方法的边界问题的主要原因是理想的预测超出了所定义的范围。因此,我们将目标角度的预测作为一个分类问题,以更好地限制预测结果。一个简单而直接的解决方案是使用目标角度作为其类别标签,并且类别的数量与角度范围相关。Figure. 5(a)显示了一个标准分类问题(one-hot标签编码)的标签设置。从回归到分类的转换会导致一定的精度损失。以180°角度范围的五参数方法为例,每区间的ω°(默认ω=1°)表示一个类别。我们可以计算出最大精度误差Max(loss)和预期精度误差E(loss):
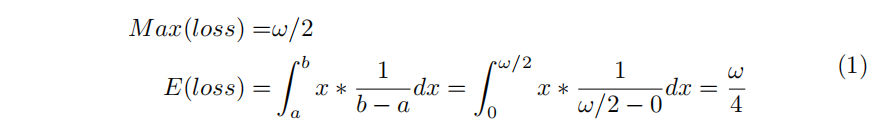
根据上述方程,可以看出旋转检测器的精度误差很小。例如,当两个长宽比为1: 9的矩形相差0.25°和0.5°(默认预期和最大精度误差)时,它们之间的Union的交集(IoU)仅减少0.02和0.05。然而,one-hot标签在旋转检测方面有两个缺点:

1)当边界框使用基于90°回归的方法时,EoE问题仍然存在。另外,基于90°回归的方法有两种不同的边界情况(垂直和水平),而基于180°回归的方法只有垂直边界情况。
2)注意,普通的分类损失与预测标签和地面真实标签之间的角度距离是不可知的,因此不适合于实际的角度预测问题。如Figure. 5(a)所示,当地面真值为0°,分类器的预测结果分别为1°,−90°时,它们的分类预测损失相同。但从检测的角度来看,应该允许有更接近地面真值的预测结果。
因此,我们设计了一种圆形光滑标签(CSL)技术,通过分类获得更稳健的角度预测,而不受EoE和PoA等边界条件情况的影响,从Figure. 5(b)中可以清楚地看出,CSL涉及到一个具有周期性的循环标签编码,并且所分配的标签值是平滑的,具有一定的误差容忍。CSL的表达式如下:
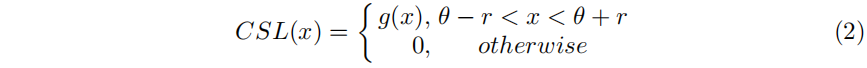
其中 g(x) 是一个窗口函数。r是窗口函数的半径。θ表示当前边界框的角度。需要一个理想的窗口函数g (x)来保持以下属性:
1)Periodicity:g(x) = g(x + kT), k ∈ N. T = 180/ω表示将角度划分为的区间数,默认值为180。
2)Symmetry:0 ≤ g(θ+ε) = g(θ−ε) ≤ 1, |ε| < r. θ是对称的中心。
3)Maximum:g(θ) = 1。
4)Monotonic:0 ≤ g(θ±ε) ≤ g(θ±ς) ≤ 1, |ς| < |ε| < r。该函数从中心点到两侧呈单调的非递增趋势。
我们给出了满足上述三个属性的四个有效的窗口函数:脉冲函数、矩形函数、三角形函数和高斯函数,如Figure. 5(b)所示,注意,标签值在边界处是连续的,并且不会由于CSL的周期性而造成任意的精度误差。此外,当窗口函数为脉冲函数或窗口函数的半径很小时,one-hot等同于CSL。
3.4. Loss Function
我们的多任务流程(pipeline)包含基于回归的预测分支和基于CSL的预测分支,便于两种方法在相同的基础上进行性能比较。边界框的回归情况为:
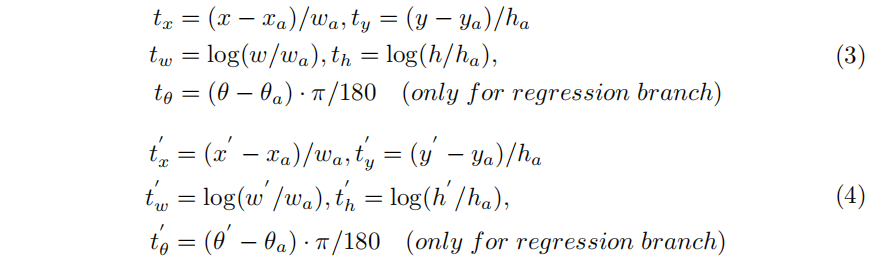
其中,x、y、w、h、θ分别表示方框的中心坐标、宽度、高度和角度。变量x、xa、x' 分别为地面真实框、锚框和预测框(同样是y、w、h、θ)。
使用多任务损失,其定义如下:
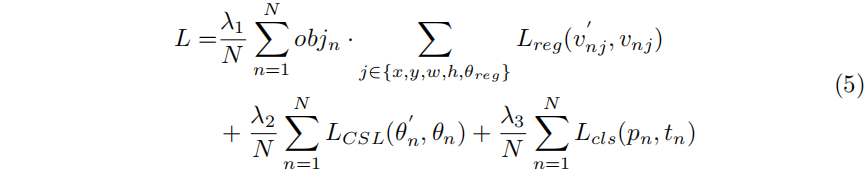
其中N表示锚框的数量,objn是一个二进制值(objn = 1表示前景,objn = 0表示背景,背景没有回归)。v'∗j为预测的偏移向量,v∗j为地面真值的目标向量。θn、θ'n分别表示角度的标签和预测。tn表示目标的标签,pn是由sigmoid函数计算出的各类的概率分布。超参数λ1、λ2、λ3控制权衡,默认情况下设置为{1,0.5,1}。分类损失Lcls和LCSL是focal loss[21]或sigmoid cross-entropy loss。回归损失Lreg是在[7]中使用的平滑的L1损失。
4. Experiments
4.1. Benchmarks and Protocls
DOTA [39]是最大的航空图像检测基准数据集之一。DOTA有两个检测任务:水平边界框(HBB)和定向边界框(OBB)。DOTA包含来自不同传感器和平台的2806张航空图像,图像大小从800×800到4000×4000像素不等。完全注释的DOTA基准数据集包含15个常见的目标类别和188,282个实例,每个实例都用任意的四边形标记。类别的简短名称定义为:飞机(PL)、棒球场(BD)、桥梁(BR)、地面跑道(GTF)、小型车辆(SV)、大型车辆(LV)、船舶(SH)、网球场(TC)、篮球场(BC)、储罐(ST)、足球场(SBF)、环岛(RA)、港口(HA)、游泳池(SP)和直升机(HC)。随机选择一半的原始图像作为训练集,1/6作为验证集,1/3作为测试集。我们将训练和验证图像划分为600×600子图像,重叠150像素,并缩放到800×800。通过所有这些过程,我们获得了大约27,000个补丁。
ICDAR2015 [13]是ICDAR 2015鲁棒阅读竞赛的挑战4,通常用于面向场景的文本检测和定位。该数据集包括1000张训练图像和500张测试图像。在训练中,我们首先使用来自ICDAR 2017 MLT训练和验证数据集的9000张图像来训练我们的模型,然后我们使用1000张训练图像来微调我们的模型。
ICDAR 2017 MLT [28]是一个多语言文本数据集,其中包括7200张训练图像、1800张验证图像和9000张测试图像。该数据集由9种语言的完整场景图像组成,该数据集中的文本区域可以处于任意方向,更加多样化和具有挑战性。
HRSC2016 [26]包含了来自两种场景的图像,包括在海上的船舶和靠近近海的船舶。所有的图像都来自于六个著名的港口。训练、验证和测试集分别包括436、181和444张图像。
所有数据集总共经过20个epoch(每个epoch的图像迭代次数为e)训练,在12个历ch和16个历元的学习率分别降低了10倍。RetinaNet和FPN的初始学习率分别为5e-4和1e-3。DOTA、ICDAR2015、MLT和HRSC2016的e值分别为27k、10k、10k和5k,如果使用数据增强和多规模训练,e值将增加一倍。

4.2. Ablation Study
Comparison of four window functions.
表1显示了在DOTA数据集上的四个窗口函数的性能比较。它还详细说明了在数据集中具有更大高宽比和更多边界情况的五个类别的准确性。我们相信,这些类别可以更好地反映我们的方法的优点。一般来说,高斯窗口函数表现最好,而脉冲函数表现最差,因为它没有学习到任何方向和尺度信息。图4(f)-4(i)显示了这四个窗口函数的可视化情况。从图4(i)-4(j)可以看出,由于基于90°-CSL的方法仍然存在EoE问题,基于180°-CSL的方法明显存在更好的边界预测。图4中的可视化结果与表1中的数据分析结果一致。
Suitable window radius.
高斯窗口形式表现出了最好的性能,而本文研究了窗口函数半径的影响。当半径过小时,窗口函数趋向于脉冲函数。相反,当半径太大时,对所有可预测结果的辨别力就会变小。因此,我们选择了0到8合适的半径范围,表2显示了两个检测器在这个范围内的性能。虽然两种检测器在半径为6时性能最好,但单级检测方法对半径更为敏感。我们推测,两级检测器的实例级特征提取能力(如RoI Pooling[7]和RoI Align [9])强于单级检测器的图像级。因此,两阶段检测方法可以区分两个接近角度之间的差异。图6比较了在不同窗口半径下的可视化效果。当半径为0时,检测器无法学习任何方向和尺度信息,这与上述脉冲函数的性能一致。

当半径变大和最佳时,检测器可以学习任何方向的角度。
Classifification is better than regression.
表3中的三个旋转检测器,包括RetinaNet-H、RetinaNet-R和FPN-H,被用于比较基于CSL的方法和基于回归的方法之间的性能差异。前两种检测器都是单级检测器,其锚定格式有所不同。后者是一种经典的两阶段检测方法。可以清楚地看出,CSL对高宽比和边界条件更大的物体具有更好的检测能力。需要注意的是,CSL是为了解决边界问题,其在整个数据集中的比例相对较小,因此总体性能(mAP)不像所列出的五个类别(5-mAP)那样明显。总的来说,基于CSL的旋转检测算法确实是一个比基于角度回归的方法更好的基线选择。
CSL performance on other datasets.
为了进一步验证基于CSL的方法是一个更好的基线模型,我们还在其他数据集中进行了验证,包括文本数据集ICDAR2015、MLT和另一个遥感数据集HRSC2016。这三个数据集都是单类对象检测数据集,其对象具有较大的长径比。虽然边界条件仍然只占这些数据集的一小部分,但CSL仍然显示出更强的性能优势。如表4所示,在相同的实验配置下,与基于回归的方法相比,基于CSL的方法分别提高了1.21%、0.56%和1.29%(1.4%)。这些实验结果为证明基于CSL的方法的多功能性提供了强有力的支持。
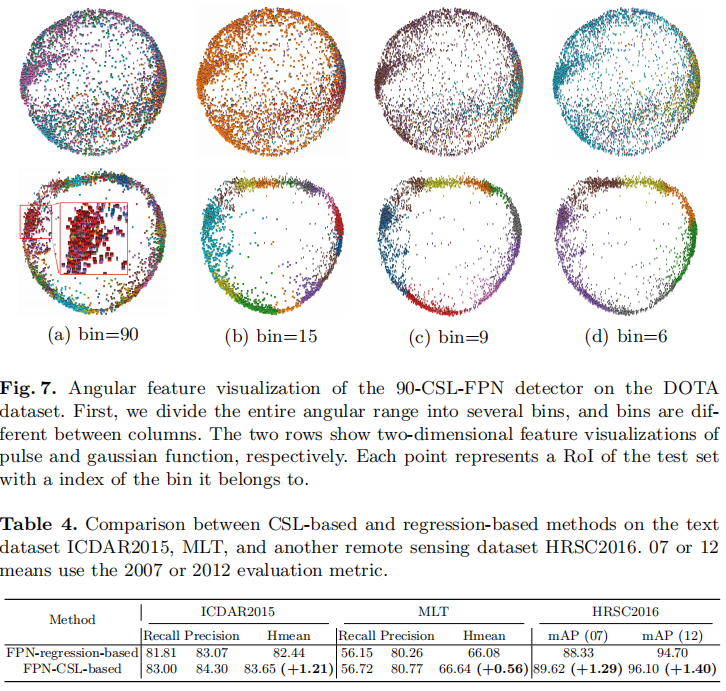
Visual analysis of angular features.
通过放大图4(i)的部分,我们发现边界条件的预测变得连续(例如,同一方向的两个大型车辆分别预测了90°和−88°)。这一现象反映了设计CSL的目的:标签是周期性的(圆形的),对相邻角度的预测具有一定的公差。为了确认角度分类器确实学习到了这一特性,我们通过主成分分析(PCA)[38]对FPN检测器中每个感兴趣区域(RoI)的角度特征进行了可视化分析,如图7所示。当我们使用脉冲窗口函数时,检测器不能很好地学习方向信息。从图7的第一行可以看出,RoI的特征分布相对随机,某些角度的预测结果占绝大多数。对于高斯函数,其特征分布明显为环状结构,相邻角的特征彼此接近,且有一定的重叠。正是这一特性有助于基于CSL的检测器消除边界问题,准确地获取物体的方向和尺度信息。
4.3. Comparison with the State-of-the-Art
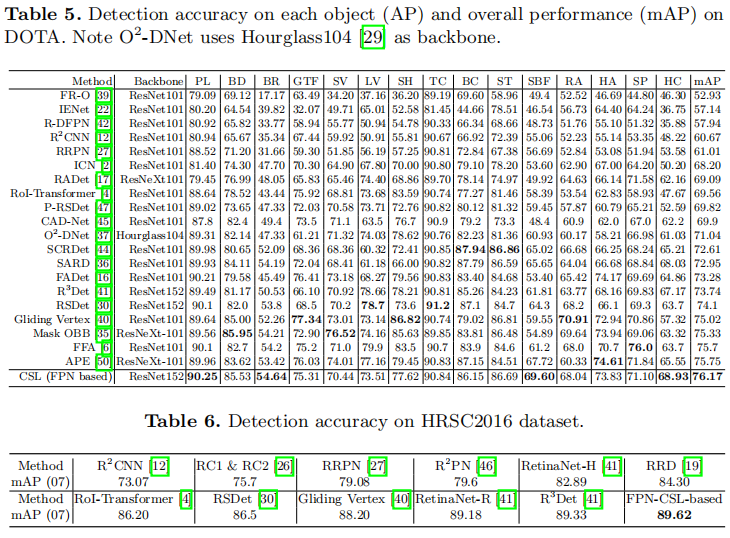
Results on DOTA.
虽然CSL只是对原始的基于回归的旋转检测方法的一个理论改进,但通过广泛使用的数据增强和多规模训练和测试,它仍然可以显示出具有竞争力的性能。我们选择DOTA作为主要的验证数据集,因为遥感图像场景的复杂性,以及大量的小的、杂乱的和旋转的对象。我们的数据增强方法主要包括随机水平、垂直翻转、随机灰化和随机旋转。训练和测试尺度设置为[400、600、720、800、1000、1100]。如表5所示,基于FPN-CSL的方法具有竞争性能,为76.17%。2016年HRSC的研究结果。HRSC2016包含了大量任意方向的大高宽比船舶实例,这对检测器的定位精度提出了巨大的挑战。实验结果表明,该模型达到了目前最好的性能,约为89.62%。
5. Conclusions
本文总结了不同的基于回归的旋转检测方法上的边界问题。基于回归方法的边界问题的主要原因是理想的预测超出了所定义的范围。因此,将目标角度的预测作为一个分类问题,以更好地限制预测结果,然后设计了一个圆形光滑标签(CSL)来适应角度的周期性,提高相邻角度之间的分类公差,且精度损失较小。我们还在CSL中引入了四个窗口函数,并探讨了不同窗口半径大小对检测性能的影响。重要的是,角度高精度分类也是旋转检测中的第一个应用。在不同检测器和数据集上的大量实验和可视化分析表明,基于CSL的旋转检测算法确实是一种有效的基线选择。
【论文精读 | 精选】

论坛地址:https://bbs.csdn.net/forums/paper

