
- 1JS表单验证(用正则表达式,用字符串验证)_在泛微表单上 用正则表达式进行判断
- 2web漏洞-xml外部实体注入(XXE)_xml external entity injection
- 3YOLOv3通道+层剪枝,参数压缩98%,砍掉48个层,提速2倍_通道剪枝yolov3
- 4100% 展示 MySQL 语句执行的神器-Optimizer Trace
- 5[图解]SysML和EA建模住宅安全系统-07 to be块定义图
- 6移动端YOLOv5压缩与蒸馏:高效且轻量级的物体检测方案
- 7【UE Niagara】制作星光飘落效果_unreal niagara 流星
- 8html修改value的值,javascript怎么改变input的值?
- 99个免费的AI辅助编程工具,智能自动编写和生成代码_辅助开发ai工具
- 10Excel + Python,飞速搞定数据分析与处理_从excel到python,数据分析
ECCV2020 收录论文汇总(持续更新中)附打包下载_hongwei yong, jianqiang huang, deyu meng, xian-she
赞
踩
2020极市计算机视觉开发者榜单已于2020年7月20日开赛,8月31日截止提交,基于火焰识别、电动车头盔识别、后厨老鼠识别、摔倒识别四个赛道,47000+数据集,30万奖励等你挑战!点击这里报名
极市平台(微信公众号ID:extrememart):专注计算机视觉前沿资讯和技术干货。本文由极市平台首发,转载需获授权。
ECCV 2020论文已公布,本届 ECCV 共收到有效投稿5025篇,接收1361篇,其中Oral论文 104 篇,仅占 2%。
ECCV2020全部论文打包下载
ECCV2020论文开放下载后,极市第一时间进行了下载打包,由于官网下载的论文文件没有用论文名进行命名,为了方便大家学习,我们整理了所有论文名称索引:
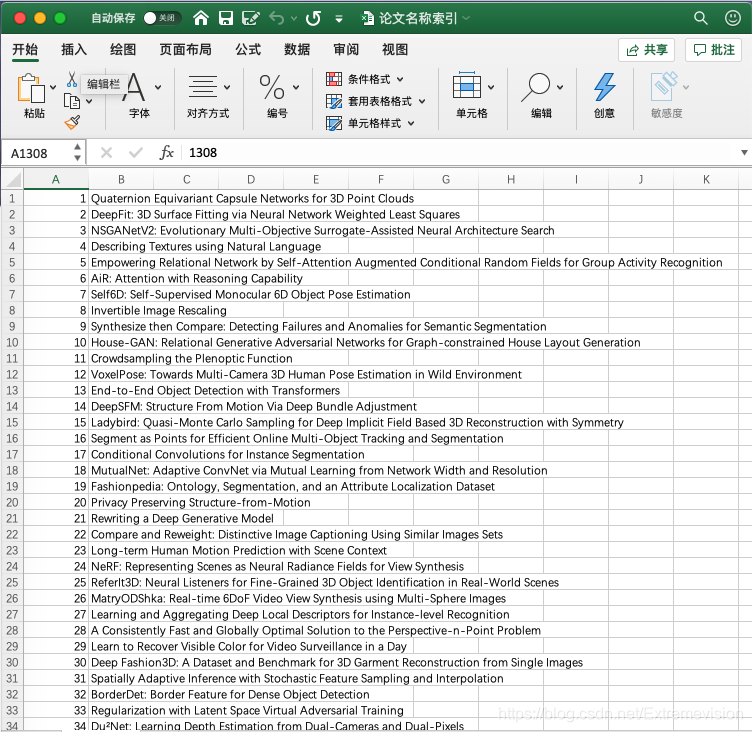
ECCV2020全部论文下载
在极市平台公众号后台回复ECCV2020,即可获取论文打包下载链接

ECCV2020 Oral论文汇总
本文汇总截止今日所有Oral 论文,其中已经公布完整论文的有 47篇,按照研究方向进行了初步分类。
这些论文中有二十几篇已经公布了代码,也一并列出了。
比较有意思的是,本文列出的第一篇论文 Quaternion Equivariant Capsule Networks for 3D Point Clouds 曾被 ICLR 2020 拒稿(https://openreview.net/forum?id=B1xtd1HtPS),ECCV 2020 却给了个Oral。
下载Oral论文请点击下方链接:
https://pan.baidu.com/s/1Kd39idXZN4baUGnQrEo7hg 提取码: iyiv
后续会持续更新。
** 3D点云( 3D Point Clouds)**
[1].Quaternion Equivariant Capsule Networks for 3D Point Clouds
作者 | Yongheng Zhao, Tolga Birdal, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas, Federico Tombari
单位 | Univ. Padova, TU Munich;斯坦福大学;多特蒙德工业大学等
论文 | https://arxiv.org/abs/1912.12098v2
点云补全和分类
[2].SoftpoolNet: Shape Descriptor for Point Cloud Completion and Classification
点云插值
[3].Intrinsic Point Cloud Interpolation via Dual Latent Space Navigation
作者 | Marie-Julie Rakotosaona, Maks Ovsjanikov
单位 | 巴黎综合理工学院
论文 | https://arxiv.org/abs/2004.01661
** 神经架构搜索(NAS)**
[4].MoSaNAS: Multi-Objective Surrogate-Assisted Neural Architecture Search
[5].S2DNAS: Transforming Static CNN Model for Dynamic Inference via Neural Architecture Search
作者 | Zhihang Yuan, Bingzhe Wu, Zheng Liang, Shiwan Zhao, Weichen Bi, Guangyu Sun
单位 | 北大;IBM Research
论文 | https://arxiv.org/abs/1911.07033
** 动作识别(Activity Recognition)**
[6].Empowering Relational Network by Self-Attention Augmented Conditional Random Fields for Group Activity Recognition
** 动作定位**
[7].Learning to Localize Actions from Moments
** 语义分割(Semantic Segmentation)**
[8].Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
作者 | Yingda Xia, Yi Zhang, Fengze Liu, Wei Shen, Alan Yuille
单位 | 约翰斯霍普金斯大学
论文 | https://arxiv.org/abs/2003.08440
场景解析-scene parsing
[25].Semantic Flow for Fast and Accurate Scene Parsing
作者 | Xiangtai Li, Ansheng You, Zhen Zhu, Houlong Zhao, Maoke Yang, Kuiyuan Yang, Yunhai Tong
单位 | 北大;华中科技大学;DeepMotion
论文 | https://arxiv.org/abs/2002.10120
代码 | https://github.com/donnyyou/torchcv
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l7Gcwa3D-1594205060580)(https://bbs.cvmart.net/uploads/images/202007/08/11/gDgz6lop3D.png?imageView2/2/w/1240/h/0)]
弱监督语义分割
[26].Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
作者 | Guolei Sun, Wenguan Wang, Jifeng Dai, Luc Van Gool
单位 | 苏黎世联邦理工学院;商汤
论文 | https://arxiv.org/abs/2007.01947
代码 | https://github.com/GuoleiSun/MCIS_wsss(尚未)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GdhXiAhi-1594205060581)(https://bbs.cvmart.net/uploads/images/202007/08/11/mDuOnOfB4V.png?imageView2/2/w/1240/h/0)]
** 生成对抗网络(GAN)**
[9].House-GAN: Relational Generative Adversarial Networks for Graph-constrained House Layout Generation
作者 | Nelson Nauata, Kai-Hung Chang, Chin-Yi Cheng, Greg Mori, Yasutaka Furukawa
单位 | 西蒙弗雷泽大学;Autodesk Research
论文 | https://arxiv.org/abs/2003.06988
代码 | https://github.com/ennauata/housegan
[10].ForkGAN: Seeing into the Rainy Night
重写深度生成模型
[11].Rewriting a Deep Generative Model
[12].Aligning and Projecting Images to Class-conditional Generative Networks
无监督草图到照片的图像合成
[13].Unsupervised Sketch-to-Photo Synthesis
作者 | Runtao Liu, Qian Yu, Stella Yu
单位 | 北大;北航/伯克利;伯克利/ICSI
论文 | https://arxiv.org/abs/1909.08313
代码 | https://github.com/rt219/Unpaired-Sketch-to-Photo-Translation
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iBTylzY9-1594205060583)(https://bbs.cvmart.net/uploads/images/202007/08/11/kpup1J8Vkr.png?imageView2/2/w/1240/h/0)]
[14].TopoGAN: A Topology-Aware Generative Adversarial Network
** 运动捕捉**
[15].Motion Capture from Internet Videos
数据集 | https://github.com/zju3dv/iMoCap_dataset(即将)
** 人体姿态估计( Human Pose Estimation****)**
3D人体姿态估计
[16].End-to-End Estimation of Multi-Person 3D Poses from Multiple Cameras
作者 | Hanyue Tu ,Chunyu Wang ,Wenjun Zeng
单位 | 微软亚洲研究院
论文 | https://www.microsoft.com/en-us/research/publication/end-to-end-estimation-of-multi-person-3d-poses-from-multiple-cameras/
** 目标检测( Object Detection****)**
[17].End-to-End Object Detection with Transformers
作者 | Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
单位 | Facebook AI
论文 | https://arxiv.org/abs/2005.12872
代码 | https://github.com/facebookresearch/detr
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jb5nKtHO-1594205060584)(https://bbs.cvmart.net/uploads/images/202007/08/11/tfAqZwnRkL.png?imageView2/2/w/1240/h/0)]
[18].Suppress and Balance: A Simple Gated Network for Salient Object Detection
代码 | https://github.com/Xiaoqi-Zhao-DLUT/GateNet-RGB-Saliency(即将)
[19].BorderDet: Border Feature for Dense Object Detection
** 三维重建( 3D Reconstruction****)**
[20].Ladybird: Deep Implicit Field Based 3D Reconstruction with Sampling and Symmetry
[21].Coherent full scene 3D reconstruction from a single RGB image
3D人体重建
[22].Combining Implicit Function Learning and Parametric Models for 3D Human Reconstruction
** 多目标跟踪与分割( MOTS****)**
[23].Segment as Points for Efficient Online Multi-Object Tracking and Segmentation
作者 | Zhenbo Xu, Wei Zhang, Xiao Tan, Wei Yang, Huan Huang, Shilei Wen, Errui Ding, Liusheng Huang
单位 | 中国科学技术大学;百度
论文 | https://arxiv.org/abs/2007.01550
代码 | https://github.com/detectRecog/PointTrack
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MBPMZiaS-1594205060585)(https://bbs.cvmart.net/uploads/images/202007/08/11/LWnriNBaju.png?imageView2/2/w/1240/h/0)]
** 实例分割( Instance Segmentation****)**
[24].Conditional Convolutions for Instance Segmentation
作者 | Zhi Tian, Chunhua Shen, Hao Chen
单位 | 阿德莱德大学
论文 | https://arxiv.org/abs/2003.05664
代码 | https://github.com/aim-uofa/AdelaiDet
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sWEmKf9M-1594205060586)(https://bbs.cvmart.net/uploads/images/202007/08/11/YG9cImrxLn.png?imageView2/2/w/1240/h/0)]
** 视频目标分割**
[27].Learning What to Learn for Video Object Segmentation
作者 | Goutam Bhat, Felix Järemo Lawin, Martin Danelljan, Andreas Robinson, Michael Felsberg, Luc Van Gool, Radu Timofte
单位 | 苏黎世联邦理工学院;林雪平大学
论文 | https://arxiv.org/abs/2003.11540
** 数据集( Dataset ****)**
[28].Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
作者 | Menglin Jia, Mengyun Shi, Mikhail Sirotenko, Yin Cui, Claire Cardie, Bharath Hariharan, Hartwig Adam, Serge Belongie
单位 | 康奈尔大学;Cornell Tech;谷歌;Hearst Magazines
论文 | https://arxiv.org/abs/2004.12276
数据集 | https://fashionpedia.github.io/home/index.html
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KgP78j8q-1594205060589)(https://bbs.cvmart.net/uploads/images/202007/08/11/SQJc0C8aHN.png?imageView2/2/w/1240/h/0)]
[29].Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single-view Images
作者 | Heming Zhu, Yu Cao, Hang Jin, Weikai Chen, Dong Du, Zhangye Wang, Shuguang Cui, Xiaoguang Han
单位 | 香港中文大学;深圳市大数据研究院;浙江大学;西安电子科技大学;腾讯-美国
论文 | https://arxiv.org/abs/2003.12753
主页 | https://kv2000.github.io/2020/03/25/deepFashion3DRevisited/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pJnB41ij-1594205060589)(https://bbs.cvmart.net/uploads/images/202007/08/11/w3Z740OMnc.png?imageView2/2/w/1240/h/0)]
[30].SIZER: A Dataset and Model for Parsing 3D Clothing and Learning Size Sensitive 3D Clothing
[31].Mapillary Planet-Scale Depth Dataset
带有阅读理解功能的图像字幕数据集
[32].TextCaps: a Dataset for Image Captioning with Reading Comprehension
作者 | Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, Amanpreet Singh
单位 | FAIR;伯克利
论文 | https://arxiv.org/abs/2003.12462
代码 | https://github.com/facebookresearch/mmf/tree/project
/m4c/projects/M4C_Captioner
主页 | https://textvqa.org/textcaps
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wK8iUgNZ-1594205060590)(https://bbs.cvmart.net/uploads/images/202007/08/11/ThazwWgcjM.png?imageView2/2/w/1240/h/0)]
** 图像字幕( Image Captioning **)
[33].Compare and Reweight: Distinctive Image Captioning Using Similar Images Sets
** 人体运动预测( Human Motion Prediction ****)**
[34].Long-term Human Motion Prediction with Scene Context
作者 | Zhe Cao , Hang Gao , Karttikeya Mangalam , Qi-Zhi Cai , Minh Vo , and Jitendra Malik
单位 | 伯克利;南京大学;Facebook Reality Lab
论文 | https://people.eecs.berkeley.edu/~zhecao/hmp/preprint.pdf
主页 | https://people.eecs.berkeley.edu/~zhecao/hmp/index.html
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oFwszsgt-1594205060591)(https://bbs.cvmart.net/uploads/images/202007/08/11/q8pfPd1r3F.png?imageView2/2/w/1240/h/0)]
** 场景识别**
[35].ReferIt3D: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes
** 视图合成**
[36].NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
作者 | Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng
单位 | 伯克利;谷歌;加利福尼亚大学圣迭戈分校
论文 | https://arxiv.org/abs/2003.08934
代码 | https://github.com/bmild/nerf
主页 | https://www.matthewtancik.com/nerf
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HLlubLOL-1594205060592)(https://bbs.cvmart.net/uploads/images/202007/08/11/l28xOrEaKY.png?imageView2/2/w/1240/h/0)]
6DoF视频视图合成
[37].MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
** 深度估计(Depth Estimation)**
[38].Du^2Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels
作者 | Yinda Zhang, Neal Wadhwa, Sergio Orts-Escolano, Christian Häne, Sean Fanello, Rahul Garg
单位 | 谷歌
论文 | https://arxiv.org/abs/2003.14299
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9JNK7Kc1-1594205060592)(https://bbs.cvmart.net/uploads/images/202007/08/11/WqF4nSuFU4.png?imageView2/2/w/1240/h/0)]
** 少样本学习(Few-Shot learning)**
[39].Model-Agnostic Boundary-Adversarial Sampling for Test-Time Generalization in Few-Shot learning
[40].Prototype Rectification for Few-Shot Learning
作者 | Jinlu Liu, Liang Song, Yongqiang Qin
单位 | 创新奇智
论文 | https://arxiv.org/abs/1911.10713
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XYoZDCiZ-1594205060594)(https://bbs.cvmart.net/uploads/images/202007/08/11/DQF8fijCPj.png?imageView2/2/w/1240/h/0)]
** 无监督学习(Unsupervised learning)**
[41].Content-Aware Unsupervised Deep Homography Estimation
作者 | Jirong Zhang, Chuan Wang, Shuaicheng Liu, Lanpeng Jia, Jue Wang, Ji Zhou
单位 | 电子科技大学
论文 | https://arxiv.org/abs/1909.05983
代码 | https://github.com/JirongZhang/DeepHomography
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yXFqsR1z-1594205060595)(https://bbs.cvmart.net/uploads/images/202007/08/11/OTadBZzWgT.png?imageView2/2/w/1240/h/0)]
[42].Visual Memorability for Robotic Interestingness Prediction via Unsupervised Online Learning
作者 | Chen Wang, Wenshan Wang, Yuheng Qiu, Yafei Hu, Sebastian Scherer
单位 | 卡内基梅隆大学
论文 | https://arxiv.org/abs/2005.08829v1
视频 | https://www.youtube.com/watch?v=Gy15Hx6qiGE
在线视频:
https://v.qq.com/x/page/f3111e7f5ci.html?start=1
** 监督学习/自监督/半监督**
[43].Learning Feature Descriptors using Camera Pose Supervision
作者 | Qianqian Wang, Xiaowei Zhou, Bharath Hariharan, Noah Snavely
单位 | 康奈尔大学;Cornell Tech;浙江大学
论文 | https://arxiv.org/abs/2004.13324
主页 | https://qianqianwang68.github.io/DescfromPose/
实时互动演示视频:
https://v.qq.com/x/page/o3111tx6o1h.html
方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ToDDd0I3-1594205060596)(https://bbs.cvmart.net/uploads/images/202007/08/11/ZJhZq9W6cj.png?imageView2/2/w/1240/h/0)]
结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZxxHfyoS-1594205060597)(https://bbs.cvmart.net/uploads/images/202007/08/11/8Q4nVOwk15.png?imageView2/2/w/1240/h/0)]
[44].Appearance Consensus Driven Self-Supervised Human Mesh Recovery
[45].TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning
** 人物交互(Human-Object Interaction)**
[46].Forecasting Human-Object Interaction: Joint Prediction of Motor Attention and Actions in First Person Video
作者 | Miao Liu, Siyu Tang, Yin Li, James Rehg
单位 | 佐治亚理工学院;威斯康星大学麦迪逊分校等
论文 | https://arxiv.org/abs/1911.10967
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VfDfGqG6-1594205060599)(https://bbs.cvmart.net/uploads/images/202007/08/11/1iz1XWPyVT.png?imageView2/2/w/1240/h/0)]
** 人员重识别(Person Re-Identification )**
[47].Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification
[48].Appearance-Preserving 3D Convolution for Video-based Person Re-identification
** 车辆重识别(Vehicle Re-Identification )**
[49].Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
** 视觉问答(VQA )**
[50].A Competence-aware Curriculum for Visual Concepts Learning via Question Answering
作者 | Qing Li, Siyuan Huang, Yining Hong, Song-Chun Zhu
单位 | 加州大学洛杉矶分校
论文 | https://arxiv.org/abs/2007.01499
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwooWVKB-1594205060600)(https://bbs.cvmart.net/uploads/images/202007/08/11/p6ILuVLG39.png?imageView2/2/w/1240/h/0)]
** 视频压缩(Video Compression )**
[51].Improving Deep Video Compression by Resolution-adaptive Flow Coding
[52].Content Adaptive and Error Propagation Aware Deep Video Compression
作者 | Guo Lu, Chunlei Cai, Xiaoyun Zhang, Li Chen, Wanli Ouyang, Dong Xu, Zhiyong Gao
单位 | 上海交通大学;悉尼大学;悉尼大学/商汤CV研究小组
论文 | https://arxiv.org/abs/2003.11282
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iGGFDnmK-1594205060601)(https://bbs.cvmart.net/uploads/images/202007/08/11/KTChgaNmWX.png?imageView2/2/w/1240/h/0)]
** 图像恢复(Image Restoration)**
[53].Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation
作者 | Xingang Pan, Xiaohang Zhan, Bo Dai, Dahua Lin, Chen Change Loy, Ping Luo
单位 | 香港中文大学;南洋理工大学 ;香港大学
论文 | https://arxiv.org/abs/2003.13659
代码 | https://github.com/XingangPan/deep-generative-prior
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k7tsWj40-1594205060605)(https://bbs.cvmart.net/uploads/images/202007/08/11/QaYxsSoX5V.png?imageView2/2/w/1240/h/0)]
** 图像修复(inpainting)**
[54].Rethinking image inpainting via a mutual encoder-decoder with feature equalization
代码 | https://github.com/KumapowerLIU/ECCV2020oralRethinking-Image-Inpainting-via-a-Mutual-Encoder-Decoder-with-Feature-Equalizations(尚未)
** 图像检索(Image Retrieval)**
[55].ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
对抗学习 + 图像检索
[56].Targeted Attack for Deep Hashing based Retrieval
作者 | Jiawang Bai, Bin Chen, Yiming Li, Dongxian Wu, Weiwei Guo, Shu-tao Xia, En-hui Yang
单位 | 清华大学;鹏城实验室;Vivo;滑铁卢大学
论文 | https://arxiv.org/abs/2004.07955
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-emjM4RaQ-1594205060605)(https://bbs.cvmart.net/uploads/images/202007/08/11/vSMGEtIxaO.png?imageView2/2/w/1240/h/0)]
图像检索,深度局部特征聚合
[57].Learning and aggregating deep local descriptors for instance-level recognition
** 遥感与航空影像处理与识别**
[58].Synthesis and Completion of Facades from Satellite Imagery
** 计算成像**
成像技术
[59].Diffraction Line Imaging
光场重建
[60].Deep Spatial-angular Regularization for Compressive Light Field Reconstruction over Coded Apertures
** 光流估计**
[61].RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
作者 | Zachary Teed, Jia Deng
单位 | 普林斯顿大学
论文 | https://arxiv.org/abs/2003.12039
代码 | https://github.com/princeton-vl/RAFT
[62].What Matters in Unsupervised Optical Flow
作者 | Rico Jonschkowski, Austin Stone, Jonathan T. Barron, Ariel Gordon, Kurt Konolige, Anelia Angelova
单位 | 谷歌
论文 | https://arxiv.org/abs/2006.04902
代码 | https://github.com/google-research/google-research/tree/master/uflow
** PnP问题求解**
[63].Solving the Blind Perspective-n-Point Problem End-To-End With Robust Differentiable Geometric Optimization
[64].A Consistently Fast and Globally Optimal Solution to the Perspective-n-Point Problem
** 网络剪枝、量化、加速**
深度神经网络的训练后分段线性量化
[65].Post-Training Piecewise Linear Quantization for Deep Neural Networks
作者 | Jun Fang, Ali Shafiee, Hamzah Abdel-Aziz, David Thorsley, Georgios Georgiadis, Joseph Hassoun
单位 | 三星;微软
论文 | https://arxiv.org/abs/2002.00104
网络剪枝
[66].EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
作者 | Bailin Li, Bowen Wu, Jiang Su, Guangrun Wang, Liang Lin
单位 | Dark Matter AI Inc;中山大学
论文 | https://arxiv.org/abs/2007.02491
代码 | https://github.com/anonymous47823493/EagleEye
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-stl64kZN-1594205060609)(https://bbs.cvmart.net/uploads/images/202007/08/11/Lq1ljc25NC.png?imageView2/2/w/1240/h/0)]
网络推断加速,使用采样-插值方法减少CNN空间信息冗余
[67].Spatially Adaptive Inference with Stochastic Feature Sampling and Interpolation
作者 | Zhenda Xie, Zheng Zhang, Xizhou Zhu, Gao Huang, Stephen Lin
单位 | 清华大学;微软亚洲研究院;中国科学技术大学
论文 | https://arxiv.org/abs/2003.08866
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T7jQp2ap-1594205060609)(https://bbs.cvmart.net/uploads/images/202007/08/11/f5dcN6g8pS.png?imageView2/2/w/1240/h/0)]
** 网络优化、正则化**
优化技术
[68].Gradient Centralization: A New Optimization Technique for Deep Neural Networks
作者 | Hongwei Yong, Jianqiang Huang, Xiansheng Hua, Lei Zhang
单位 | 香港理工大学;阿里达摩院
论文 | https://arxiv.org/abs/2004.01461
代码 | https://github.com/Yonghongwei/Gradient-Centralization
深度神经网络的逐层条件分析
[69].Layer-wise Conditioning Analysis in Exploring the Learning Dynamics of DNNs
作者 | Lei Huang, Jie Qin, Li Liu, Fan Zhu, Ling Shao
单位 | IIAI
论文 | https://arxiv.org/abs/2002.10801
代码 | https://github.com/huangleiBuaa/LayerwiseCA
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1eaVVMFd-1594205060611)(https://bbs.cvmart.net/uploads/images/202007/08/11/6KHHH1BZqi.png?imageView2/2/w/1240/h/0)]
[70].Regularization with Latent Space Virtual Adversarial Training
** Structure-from-Motion**
[71].DeepSFM: Structure From Motion Via Deep Bundle Adjustment
作者 | Xingkui Wei, Yinda Zhang, Zhuwen Li, Yanwei Fu, Xiangyang Xue
单位 | 复旦大学;谷歌;Nuro, Inc
论文 | https://arxiv.org/abs/1912.09697
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zXpn6faN-1594205060613)(https://bbs.cvmart.net/uploads/images/202007/08/11/U9hwmlz3uU.png?imageView2/2/w/1240/h/0)]
[72].Privacy Preserving Structure-from-Motion
** 局部特征提取**
局部特征提精
[73].Multi-View Optimization of Local Feature Geometry
作者 | Mihai Dusmanu, Johannes L. Schönberger, Marc Pollefeys
单位 | 苏黎世联邦理工学院;微软
论文 | https://arxiv.org/abs/2003.08348
代码 | https://github.com/mihaidusmanu/local-feature-refinement
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0e1fw0bI-1594205060613)(https://bbs.cvmart.net/uploads/images/202007/08/11/uJAFFDfw1J.png?imageView2/2/w/1240/h/0)]
局部特征描述
[74].Online Invariance Selection for Local Feature Descriptors
** 人脸**
基于模型的密集人脸配准技术
[75].“Look Ma, no landmarks!” - Unsupervised, model-based dense face alignment
人脸老化
[76].Hierarchical Face Aging through Disentangled Latent Characteristics
** 自动驾驶**
人类活动预测
[77].Adversarial Generative Grammars for Human Activity Prediction
运动预测
[78].Learning Lane Graph Representations for Motion Forecasting
自动驾驶
车辆通信的联合感知与预测
[79].V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
作者主页 | https://zswang666.github.io/#(未公布)
轨迹预测
[80].It is not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction
作者 | Karttikeya Mangalam, Harshayu Girase, Shreyas Agarwal, Kuan-Hui Lee, Ehsan Adeli, Jitendra Malik, Adrien Gaidon
单位 | 伯克利;丰田;斯坦福大学
论文 | https://arxiv.org/abs/2004.02025
主页 | https://karttikeya.github.io/publication/htf/
代码 | 即将
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ycuu3dg8-1594205060614)(https://bbs.cvmart.net/uploads/images/202007/08/11/4WBfMha6o9.png?imageView2/2/w/1240/h/0)]
** 立体匹配**
[81].Domain-invariant Stereo Matching Networks
作者 | Feihu Zhang, Xiaojuan Qi, Ruigang Yang, Victor Prisacariu, Benjamin Wah, Philip Torr
单位 | 牛津大学;百度;香港中文大学
论文 | https://arxiv.org/abs/1911.13287
代码 | https://github.com/feihuzhang/DSMNet
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kfyaqk0a-1594205060615)(https://bbs.cvmart.net/uploads/images/202007/08/11/IFpYMu26wA.png?imageView2/2/w/1240/h/0)]
** 单RGB图像的手部网格建模**
[82].DeepHandMesh: Weakly-supervised Deep Encoder-Decoder Framework for High-fidelity Hand Mesh Modeling from a Single RGB Image
** 流式图像理解**
[83].Towards Streaming Image Understanding
作者 | Mengtian Li, Yu-Xiong Wang, Deva Ramanan
单位 | 卡内基梅隆;Argo AI
论文 | https://arxiv.org/abs/2005.10420
主页 | https://www.cs.cmu.edu/~mengtial/proj/streaming/
https://v.qq.com/x/page/j31110iijxz.html
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-taHI5Bmy-1594205060615)(https://bbs.cvmart.net/uploads/images/202007/08/11/lhzFJXPrAY.png?imageView2/2/w/1240/h/0)]
** 度量保留的可变形3D形状表示**
[84].LIMP: Learning Latent Shape Representations with Metric Preservation Priors
作者 | Luca Cosmo, Antonio Norelli, Oshri Halimi, Ron Kimmel, Emanuele Rodolà
单位 | 罗马大学;University of Lugano;以色列理工学院
论文 | https://arxiv.org/abs/2003.12283
** 开放集识别**
[85].Hybrid Models for Open Set Recognition
作者 | Hongjie Zhang, Ang Li, Jie Guo, Yanwen Guo
单位 | 南京大学;DeepMind
论文 | https://arxiv.org/abs/2003.12506
** 3D表面拟合**
[86].DeepFit: 3D Surface Fitting by Neural Network Weighted Least Squares
作者 | Yizhak Ben-Shabat, Stephen Gould
单位 | 澳大利亚国立大学
论文 | https://arxiv.org/abs/2003.10826
** 6D物体姿态估计(6D Object Pose Estimation)**
[87].Self6D: Self-Supervised Monocular 6D Object Pose Estimation
作者 | Gu Wang, Fabian Manhardt, Jianzhun Shao, Xiangyang Ji, Nassir Navab, Federico Tombari
单位 | 清华大学;慕尼黑工业大学;谷歌
论文 | https://arxiv.org/abs/2004.06468
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OO1KVd9h-1594205060620)(https://bbs.cvmart.net/uploads/images/202007/08/11/Urtjh2t9pg.png?imageView2/2/w/1240/h/0)]
** 图像缩放 (Image Rescaling)**
[88].Invertible Image Rescaling
作者 | Mingqing Xiao, Shuxin Zheng, Chang Liu, Yaolong Wang, Di He, Guolin Ke, Jiang Bian, Zhouchen Lin, Tie-Yan Liu
单位 | 北大;微软亚洲研究院;多伦多大学
论文 | https://arxiv.org/abs/2005.05650
代码 | https://github.com/pkuxmq/Invertible-Image-Rescaling(即将)
解读 | https://zhuanlan.zhihu.com/p/150340687
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XzQCErOO-1594205060622)(https://bbs.cvmart.net/uploads/images/202007/08/11/4JVzUxpVP9.png?imageView2/2/w/1240/h/0)]
** 远程生理信号监控**
远程生理测量:通过交叉验证特征解耦的方法
[89].Video-based Remote Physiological Measurement via Cross-verified Feature Disentangling
** 网络结构设计**
自适应网络宽度和分辨率学习
[90].MutualNet: Adaptive ConvNet via Mutual Learning from Network Width and Resolution
作者 | Taojiannan Yang, Sijie Zhu, Chen Chen, Shen Yan, Mi Zhang, Andrew Willis
单位 | 北卡罗来纳大学夏洛特分校;密歇根州立大学
论文 | https://arxiv.org/abs/1909.12978
代码 | https://github.com/taoyang1122/MutualNet
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WKVZDvRc-1594205060623)(https://bbs.cvmart.net/uploads/images/202007/08/11/0vjYl2kRAg.png?imageView2/2/w/1240/h/0)]
** 其它**
[91].In-Home Daily-Life Captioning Using Radio Signals
[92].Self-Challenging Improves Cross-Domain Generalization
作者 | Zeyi Huang, Haohan Wang, Eric P. Xing, Dong Huang
单位 | 卡内基梅隆大学
论文 | https://arxiv.org/abs/2007.02454
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ts4vCBOT-1594205060624)(https://bbs.cvmart.net/uploads/images/202007/08/11/hMPjuMkAk1.png?imageView2/2/w/1240/h/0)]
多任务学习增强对抗鲁棒性
[93].Multi-task Learning Increases Adversarial Robustness
[94].Efficient Model Fitting by Combining Lifted Optimization with Phong Surface Models
从单图像学习立体信息
[95].Learning Stereo from Single Images
[96].Towards Automated Testing and Robustification by Semantic Adversarial Data Generation
持续学习-Continual Learning
[97].Greedy Sampler and Dumb Learner: A Surprisingly Effective Approach for Continual Learning
可解释CNN
[98].Training Interpretable Convolutional Neural Networks by Differentiating Class-specific Filters
跨域级联深度翻译
[99].Cross-Domain Cascaded Deep Translation
使神经网络能够抵抗各种图像损坏的简单方法
[100].A simple way to make neural networks robust against diverse image corruptions
使用自然语言描述纹理
[101].Describing Textures using Natural Language
具有推理能力的注意力模型
[102].AiR: Attention with Reasoning Capability
代码 | https://github.com/szzexpoi/AiR
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x1jQfOdY-1594205060625)(https://bbs.cvmart.net/uploads/images/202007/08/11/aqrrzj7Cj5.png?imageView2/2/w/1240/h/0)]
[103].Crowdsampling the Plenoptic Function
[104].恢复视频监控的可见光颜色
Learn to Recover Visible Color for Video Surveillance in a Day
文章来源: OpenCV中文网@微信公众号

