
- 1Java 内存分析工具 Arthas 介绍与示例讲解
- 2【常用传感器】DS18B20温度传感器原理详解及例程代码_ds18b20温度传感器工作原理
- 3算法学习笔记(一):时间复杂度、冒泡排序、选择排序和二分排序_二分算法 冒泡算法时间复杂度、
- 4el-table-column列表中展示图片_el-table-column 图片
- 5【网络与系统安全实验】拒绝服务攻击及防御_拒绝服务攻击对象
- 6Django | 基于pycharm的django配置52张全流程截图,红星给你一步一步的男妈妈式教学_给下载的项目配置django
- 7Dockerfile构建镜像详解与案例_docker制作镜像经典案例
- 8基于java+springboot+vue实现的民宿租赁系统(文末源码+Lw)23-182_java 民宿 百度网盘
- 9【人工智能】大模型平台新贵——文心千帆_通用人工智能大模型平台 是什么意思
- 10使用Python操作excel单元格——在单元格中插入公式_python怎么向excel表格插入公式
yolov5人脸识别(yolov5-facenet-svm)_yolov5 人脸识别
赞
踩
yolov5出来的这段时间,挺火,自己试着跑了以下,速度精度确实不错,相比yolov3性能要高,相比yolov4这个咱不敢说。以下用yolov5做一个人脸识别的demo。
本文章项目代码github地址https://github.com/BlackFeatherQQ/FaceRecognition
一、yolov5
yolov5的原理这个就不介绍了,网上一查一大堆,github官方源码地址https://github.com/ultralytics/yolov5
现在来谈谈yolov5在这个人来能识别demo中的作用(框出人脸):
怎么才能框出人脸呢,yolov5官方预训练权重只能框出整个人,要想框出人脸只能在其基础之上再训练,训练走起:
1)数据从哪里来:
开源人脸数据celeba与wideface,本人选择使用的是celeba,原因:简单、易于训练、人脸识别项目精度已经够用了
2)怎么训练:
具体请看yolov5训练详解
3)获取人脸的框
二、facenet
FaceNet亮点:
1. 利用DNN直接学习到从原始图片到欧氏距离空间的映射,从而使得在欧式空间里的距离的度量直接关联着人脸相似度;
2. 引入triplet损失函数,使得模型的学习能力更高效。
具体原理在此不再介绍,百度可以找到很多,我们在此介绍它的应用。
下载facenet预训练权重https://github.com/davidsandberg/facenet
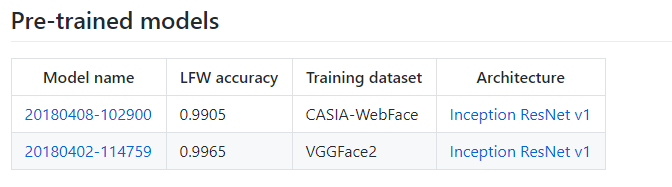
代码不需要下载,太繁杂,如果你想要训练的话可以下载,此处我们只使用facenet.py已经够用了。
三、SVM
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
需要我们去实现吗?当然不需要,sklearn内置,直接调用即可
四、数据制作
(1)人脸数据

此处做了一点数据增强(镜像、高斯模糊等)

每个文件夹的名称对应每个人的名字(注意文件名不要使用中文(opencv暂不支持中文编码,编译器等可能也会报错误或者出现乱码问题))
(2)人脸特征提取保存
picture_path = "D:/code_data/face_recognition/images" #用户图片数据
model_path = "D:/code_data/facenet/20180402-114759" #facenet模型权重
database_path = "D:/code_data/face_recognition/npz/Database.npz" #打包成npz文件
face2database(picture_path,model_path,database_path) #step1
- 1
- 2
- 3
- 4
def face2database(picture_path, model_path, database_path, batch_size=90, image_size=160): # 提取特征到数据库 # picture_path为人脸文件夹的所在路径 # model_path为facenet模型路径 # database_path为人脸数据库路径 with tf.Graph().as_default(): with tf.Session() as sess: dataset = facenet.get_dataset(picture_path) paths, labels = facenet.get_image_paths_and_labels(dataset) print('Number of classes: %d' % len(dataset)) print('Number of images: %d' % len(paths)) # Load the model print('Loading feature extraction model') facenet.load_model(model_path) # Get input and output tensors images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0") embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0") phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0") embedding_size = embeddings.get_shape()[1] # Run forward pass to calculate embeddings print('Calculating features for images') nrof_images = len(paths) nrof_batches_per_epoch = int(math.ceil(1.0 * nrof_images / batch_size)) emb_array = np.zeros((nrof_images, embedding_size)) for i in range(nrof_batches_per_epoch): start_index = i * batch_size end_index = min((i + 1) * batch_size, nrof_images) paths_batch = paths[start_index:end_index] images = facenet.load_data(paths_batch, False, False, image_size) feed_dict = {images_placeholder: images, phase_train_placeholder: False} emb_array[start_index:end_index, :] = sess.run(embeddings, feed_dict=feed_dict) np.savez(database_path, emb=emb_array, lab=labels) print("数据库特征提取完毕!") # emb_array里存放的是图片特征,labels为对应的标签

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
(3)训练SVM分类器
picture_path = "D:/code_data/face_recognition/images" #用户图片数据
model_path = "D:/code_data/facenet/20180402-114759" #facenet模型权重
SVCpath = "D:/code_data/face_recognition/pkl/SVCmodel.pkl" #通过SVM训练保存到pkl
ClassifyTrainSVC(database_path,SVCpath) #step2
- 1
- 2
- 3
- 4
def ClassifyTrainSVC(database_path, SVCpath): # database_path为人脸数据库 # SVCpath为分类器储存的位置 Database = np.load(database_path) name_lables = Database['lab'] embeddings = Database['emb'] name_unique = np.unique(name_lables) labels = [] for i in range(len(name_lables)): for j in range(len(name_unique)): if name_lables[i] == name_unique[j]: labels.append(j) print('Training classifier') model = SVC(kernel='linear', probability=True) model.fit(embeddings, labels) with open(SVCpath, 'wb') as outfile: pickle.dump((model, name_unique), outfile) print('Saved classifier model to file "%s"' % SVCpath)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
五、识别
整理一下思路:
数据库中的人脸数据处理:通过fanet提取特征保存在Database.npz中,利用特征训练SVM分类器保存在SVCmodel.pkl中。
yolov5通过训练celeba数据集可以框出图像中的人脸,我们把框出的人脸拿出来丢到facenet中会生成人脸特征,把人脸特征和我们数据库中的进行对比(SVM或者直接计算特征距离)算出相似度。
把yolov5与facenet代码关联起来,如下面的代码(支持图片、文件夹、视频,自动判别文件类型)
def setOPT(): # 文件配置 # ******************************************************* parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default='D:/py/FaceRecognition/weights/last.pt', help='model.pt path') parser.add_argument('--source', type=str, default='C:/Users/lieweiai/Desktop/video/26321934-1-192.mp4', help='source') # file/folder, 0 for webcam parser.add_argument('--output', type=str, default='../inference/output', help='output folder') # output folder parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.3, help='object confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS') parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)') parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--view-img', action='store_true', help='display results') parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') parser.add_argument('--classes', nargs='+', type=int, help='filter by class') parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') parser.add_argument('--augment', action='store_true', help='augmented inference') parser.add_argument('--facenet-model-path',type=str,default='D:/code_data/facenet/20180402-114759',help='miss facenet-model') parser.add_argument('--svc-path', type=str, default='D:/code_data/face_recognition/pkl/SVCmodel.pkl', help='miss svc') parser.add_argument('--database-path', type=str, default='D:/code_data/face_recognition/npz/Database.npz', help='miss database') opt = parser.parse_args() opt.img_size = check_img_size(opt.img_size) print(opt) return opt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
def detect(opt, save_img=False): out, source, weights, view_img, save_txt, imgsz, facenet_model_path, svc_path, database_path = \ opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, opt.facenet_model_path, opt.svc_path, opt.database_path webcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt') # Initialize device = torch_utils.select_device(opt.device) if os.path.exists(out): shutil.rmtree(out) # delete output folder os.makedirs(out) # make new output folder half = device.type != 'cpu' # half precision only supported on CUDA # Load model google_utils.attempt_download(weights) model = torch.load(weights, map_location=device)['model'].float() # load to FP32 # torch.save(torch.load(weights, map_location=device), weights) # update model if SourceChangeWarning # model.fuse() model.to(device).eval() if half: model.half() # to FP16 # Second-stage classifier classify = False if classify: modelc = torch_utils.load_classifier(name='resnet101', n=2) # initialize modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weights modelc.to(device).eval() # Set Dataloader vid_path, vid_writer = None, None if webcam: view_img = True cudnn.benchmark = True # set True to speed up constant image size inference dataset = LoadStreams(source, img_size=imgsz) else: save_img = True dataset = LoadImages(source, img_size=imgsz) # Get names and colors names = model.names if hasattr(model, 'names') else model.modules.names colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))] # Run inference t0 = time.time() img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img _ = model(img.half() if half else img) if device.type != 'cpu' else None # run once # ************************************************************************ with tf.Graph().as_default(): with tf.Session() as sess: # Load the model print('Loading feature extraction model') facenet.load_model(facenet_model_path) with open(svc_path, 'rb') as infile: (classifymodel, class_names) = pickle.load(infile) print('Loaded classifier model from file "%s"' % svc_path) # Get input and output tensors images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0") embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0") phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0") embedding_size = embeddings.get_shape()[1] Database = np.load(database_path) corpbbox = None # ************************************************************ for path, img, im0s, vid_cap in dataset: img = torch.from_numpy(img).to(device) img = img.half() if half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # Inference t1 = torch_utils.time_synchronized() pred = model(img, augment=opt.augment)[0] # Apply NMS pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms) t2 = torch_utils.time_synchronized() # Apply Classifier if classify: pred = apply_classifier(pred, modelc, img, im0s) # Process detections for i, det in enumerate(pred): # detections per image if webcam: # batch_size >= 1 p, s, im0 = path[i], '%g: ' % i, im0s[i].copy() else: p, s, im0 = path, '', im0s # ****************************** image = Image.fromarray(cv2.cvtColor(im0, cv2.COLOR_BGR2RGB)) image = np.array(image) img_size = np.array(image.shape)[0:2] # ******************************** save_path = str(Path(out) / Path(p).name) s += '%gx%g ' % img.shape[2:] # print string gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh if det is not None and len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round() # Print results for c in det[:, -1].unique(): n = (det[:, -1] == c).sum() # detections per class s += '%g %ss, ' % (n, names[int(c)]) # add to string # Write results for *xyxy, conf, cls in det: if save_txt: # Write to file xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view( -1).tolist() # normalized xywh with open(save_path[:save_path.rfind('.')] + '.txt', 'a') as file: file.write(('%g ' * 5 + '\n') % (cls, *xywh)) # label format if save_img or view_img: # Add bbox to image # *************************************************** x1 = np.maximum(int(xyxy[0]) - 16, 0) y1 = np.maximum(int(xyxy[1]) - 16, 0) x2 = np.minimum(int(xyxy[2]) + 16, img_size[1]) y2 = np.minimum(int(xyxy[3]) + 16, img_size[0]) crop_img = image[y1:y2, x1:x2] scaled = np.array(Image.fromarray(crop_img).resize((160, 160))) # scaled = misc.imresize(crop_img, (160, 160), interp='bilinear') img = load_image(scaled, False, False, 160) img = np.reshape(img, (-1, 160, 160, 3)) feed_dict = {images_placeholder: img, phase_train_placeholder: False} embvecor = sess.run(embeddings, feed_dict=feed_dict) embvecor = np.array(embvecor) # 利用SVM对人脸特征进行分类 predictions = classifymodel.predict_proba(embvecor) best_class_indices = np.argmax(predictions, axis=1) tmp_lable = class_names[best_class_indices] best_class_probabilities = predictions[ np.arange(len(best_class_indices)), best_class_indices] print(class_names, predictions) if best_class_probabilities < 0.95: tmp_lable = "others" print(tmp_lable) # *************************************************** # label = '%s %.2f' % (names[int(cls)], conf) label = '%s %.2f' % (tmp_lable, best_class_probabilities) plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3) # Print time (inference + NMS) print('%sDone. (%.3fs)' % (s, t2 - t1)) cv2.imshow("",im0) cv2.waitKey(5) # *********************************************************** # ************************************************************************ # Stream results if view_img: cv2.imshow(p, im0) if cv2.waitKey(1) == ord('q'): # q to quit raise StopIteration # Save results (image with detections) if save_img: if dataset.mode == 'images': cv2.imwrite(save_path, im0) else: if vid_path != save_path: # new video vid_path = save_path if isinstance(vid_writer, cv2.VideoWriter): vid_writer.release() # release previous video writer fps = vid_cap.get(cv2.CAP_PROP_FPS) w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*opt.fourcc), fps, (w, h)) vid_writer.write(im0) if save_txt or save_img: print('Results saved to %s' % os.getcwd() + os.sep + out) if platform == 'darwin': # MacOS os.system('open ' + save_path) print('Done. (%.3fs)' % (time.time() - t0)) def face2database(picture_path, model_path, database_path, batch_size=90, image_size=160): # 提取特征到数据库 # picture_path为人脸文件夹的所在路径 # model_path为facenet模型路径 # database_path为人脸数据库路径 with tf.Graph().as_default(): with tf.Session() as sess: dataset = facenet.get_dataset(picture_path) paths, labels = facenet.get_image_paths_and_labels(dataset) print('Number of classes: %d' % len(dataset)) print('Number of images: %d' % len(paths)) # Load the model print('Loading feature extraction model') facenet.load_model(model_path) # Get input and output tensors images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0") embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0") phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0") embedding_size = embeddings.get_shape()[1] # Run forward pass to calculate embeddings print('Calculating features for images') nrof_images = len(paths) nrof_batches_per_epoch = int(math.ceil(1.0 * nrof_images / batch_size)) emb_array = np.zeros((nrof_images, embedding_size)) for i in range(nrof_batches_per_epoch): start_index = i * batch_size end_index = min((i + 1) * batch_size, nrof_images) paths_batch = paths[start_index:end_index] images = facenet.load_data(paths_batch, False, False, image_size) feed_dict = {images_placeholder: images, phase_train_placeholder: False} emb_array[start_index:end_index, :] = sess.run(embeddings, feed_dict=feed_dict) np.savez(database_path, emb=emb_array, lab=labels) print("数据库特征提取完毕!") # emb_array里存放的是图片特征,labels为对应的标签 def ClassifyTrainSVC(database_path, SVCpath): # database_path为人脸数据库 # SVCpath为分类器储存的位置 Database = np.load(database_path) name_lables = Database['lab'] embeddings = Database['emb'] name_unique = np.unique(name_lables) labels = [] for i in range(len(name_lables)): for j in range(len(name_unique)): if name_lables[i] == name_unique[j]: labels.append(j) print('Training classifier') model = SVC(kernel='linear', probability=True) model.fit(embeddings, labels) with open(SVCpath, 'wb') as outfile: pickle.dump((model, name_unique), outfile) print('Saved classifier model to file "%s"' % SVCpath) # 图片预处理阶段 def to_rgb(img): w, h = img.shape ret = np.empty((w, h, 3), dtype=np.uint8) ret[:, :, 0] = ret[:, :, 1] = ret[:, :, 2] = img return ret def prewhiten(x): mean = np.mean(x) std = np.std(x) std_adj = np.maximum(std, 1.0 / np.sqrt(x.size)) y = np.multiply(np.subtract(x, mean), 1 / std_adj) return y def crop(image, random_crop, image_size): if image.shape[1] > image_size: sz1 = int(image.shape[1] // 2) sz2 = int(image_size // 2) if random_crop: diff = sz1 - sz2 (h, v) = (np.random.randint(-diff, diff + 1), np.random.randint(-diff, diff + 1)) else: (h, v) = (0, 0) image = image[(sz1 - sz2 + v):(sz1 + sz2 + v), (sz1 - sz2 + h):(sz1 + sz2 + h), :] return image def flip(image, random_flip): if random_flip and np.random.choice([True, False]): image = np.fliplr(image) return image def load_image(image_old, do_random_crop, do_random_flip, image_size, do_prewhiten=True): if image_old.ndim == 2: image_old = to_rgb(image_old) if do_prewhiten: image_old = prewhiten(image_old) image_old = crop(image_old, do_random_crop, image_size) image_old = flip(image_old, do_random_flip) return image_old
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
【提示】github上的代码不包含yolov5训练那一块,recognition/test.py是用来做人脸识别的入口,在里面你可以更改相应配置。
我的数据库只做了胡歌、刘亦菲、刘德华的数据,未在数据库中的会显示为others,附几张效果图吧



