
- 1软件测试之-软件缺陷管理 _bug处理流程图
- 2关于MPU6050姿态解算的一阶互补滤波方法(从原理到代码实现)_互补滤波系数公式
- 3简单易懂的Docker下载安装教程:快速上手容器化应用
- 4GPU在外卖场景精排模型预估中的应用实践_大模型训练场景gpu需求量如何评估
- 5报告 | 腾讯知文,从0到1打造下一代智能问答引擎【CCF-GAIR】
- 6Mybatis中对象关系映射_mybatis映射对象
- 7【WSN定位】基于chan算法、fang算法、taylor算法和最小二乘定位算法lsm实现目标定位matlab源码_chan算法和最小二乘法
- 8LDA主题模型及Python实现_python lda模型主题分析
- 9using-aws-s3-buckets-cloudfront-distribution-with-craft-cms_yxokd
- 10在群晖NAS部署_开源在线项目任务管理工具【dooTask】
AIGC——ADD具有对抗学习和知识提炼功能的扩散模型
赞
踩
1. 介绍
扩散模型作为一类生成模型,已经因其在生成高质量图像和视频方面的显著成就而受到广泛关注。它们以卓越的图像质量和丰富的多样性脱颖而出。不过,扩散模型在图像生成过程中需要执行大量的采样步骤,这使得整个估计过程变得相对缓慢。
与此同时,生成对抗网络(GANs)以其简洁的单步生成和快速采样能力而闻名。尽管已有尝试将GANs应用于更广泛的数据集,但在样本质量方面,它们往往无法与扩散模型相媲美。此外,GANs在生成图像多样性方面也存在局限。
本文旨在结合扩散模型的高样本质量和GANs的快速采样优势。为此,提出了一种融合两种训练目标的新方法:
- 对抗性损失(Adversarial Loss)
- 与分馏采样(Seeded Distillation Sampling, SDS)相匹配的蒸馏损失(Distillation Loss)
通过引入鉴别器,对抗性损失能够比较真实图像与生成图像,有效避免了其他蒸馏技术中常见的模糊和伪影问题。而蒸馏损失则利用了一个预先训练好的(静态的)扩散模型作为“教师”,借助其丰富的知识库,以一种高效的方式进行知识传递。
这里提出的方法在性能上超越了现有的最先进扩散模型SOTA SDXL,能够在仅需一到四个采样步骤的情况下生成高保真的实时图像。这标志着生成模型领域的一个重大进步,为未来生成任务的效率和质量提供了新的可能性。
论文地址:https://arxiv.org/pdf/2311.17042.pdf
源码地址:https://github.com/cumulo-autumn/streamdiffusion
2.模型架构
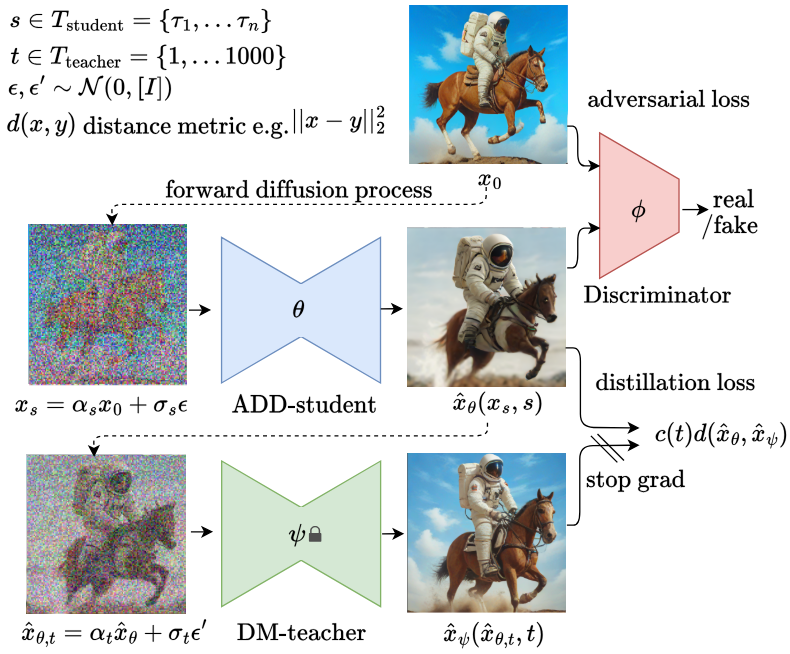
2.1 训练程序
训练过程如上图所示,其中主模型 ADD-student由三个预先训练过的权重为 θ 的扩散模型(UNet-DM)、一个可训练权重为 j 的判别器和一个权重为 ψ 的 DM-Teacher (扩散模型)组成。使用的模型
对于对抗损失,生成的样本 x ^ θ \hat{x}_\theta x^θ 和实际图像 x 0 x_0 x0 被传递给一个判别器来区分它们。 下一节将详细介绍判别器和对抗损失的设计。 为了从 DM-Teacher 中提炼知识,ADD-学生样本 x ^ θ \hat{x}_\theta x^θ 被扩散到教师(DM-Teacher)的前瞻过程 x ^ θ , t \hat{x}_{\theta,t} x^θ,t 和提炼损失 L d i s t i l l L_{distill} Ldistill,并使用教师的去噪预测 x ^ ψ ( x ^ θ , t , t ) \hat{x}_\psi(\hat{x}_{\theta,t},t) x^ψ(x^θ,t,t) 作为重建目标。详情将在下一节给出。
整体损失函数如下
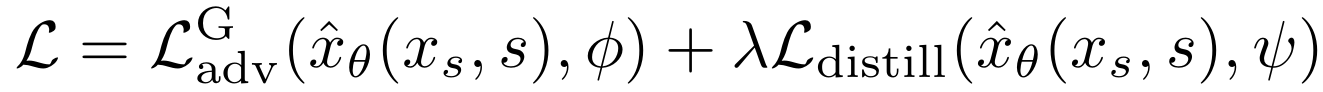
2.2 敌对损失和标识符
在判别器方面,使用了 Stylegan-t 的结构和设置(Sauer et al, 2023)。这是一个固定的预训练特征网络 F 和一组可训练的轻量级判别头 D ( j , k ) D_{(j, k)} D(j,k)。对于特征网络 F,将在下一节中研究视觉转换器(ViT)和模型大小的不同选择,因为 Sauer 等人发现视觉转换器(ViT)效果很好。可训练的判别头应用于特征网络不同层中的特征 Fk。
判别器 L a d v D L_{adv}^D LadvD 和主要模型 L a d v G L_{adv}^G LadvG 的损失如下。
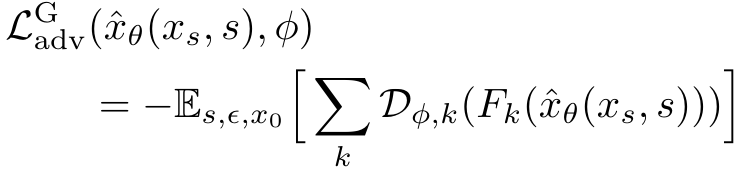
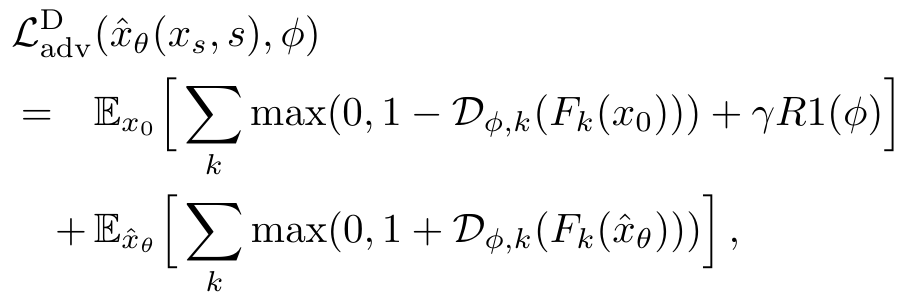
其中 R1 表示 R1 梯度惩罚。不计算像素值的梯度惩罚,而是在每个判别头 ǫ ( D ( ϕ , k ) ) ǫ( D_{(ϕ, k)}) ǫ(D(ϕ,k)) 的输出端计算梯度惩罚。如果输出分辨率大于 128 × 128 128 \times 128 128×128 像素,R1 惩罚就特别有用。
2.3 分馏损失
馏分损失的计算公式如下
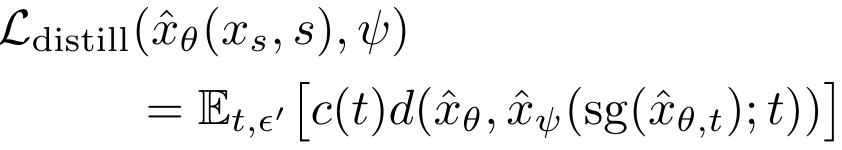
s g sg sg 表示停止梯度操作。分数蒸馏损失使用的是距离指标(d),它计算的 是ADD-学生生成的样本 x θ x_\theta xθ与 DM-教师输出之间的差异。 为了找到一个合适的 d ,我们在实验中测试了许多函数,其中平均平方误差(MSE)是最有效的。
3. 试验
3.1 生成模型与 SOTA 的定量比较
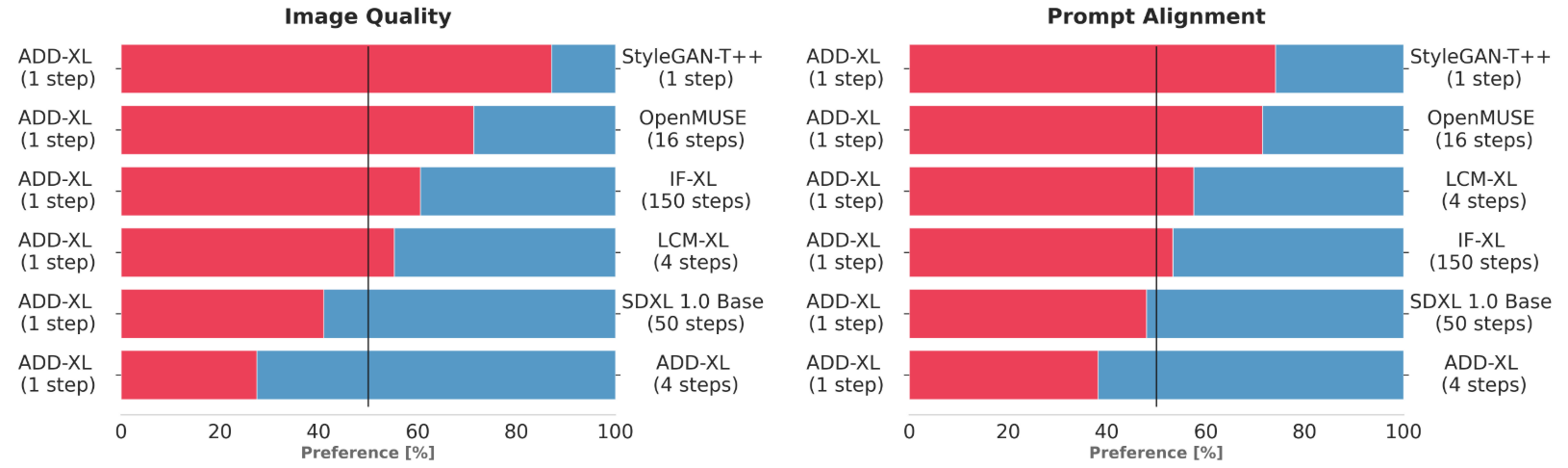
图 1:用户偏好调查(单步);ADD-XL(单步)与基线的比较结果
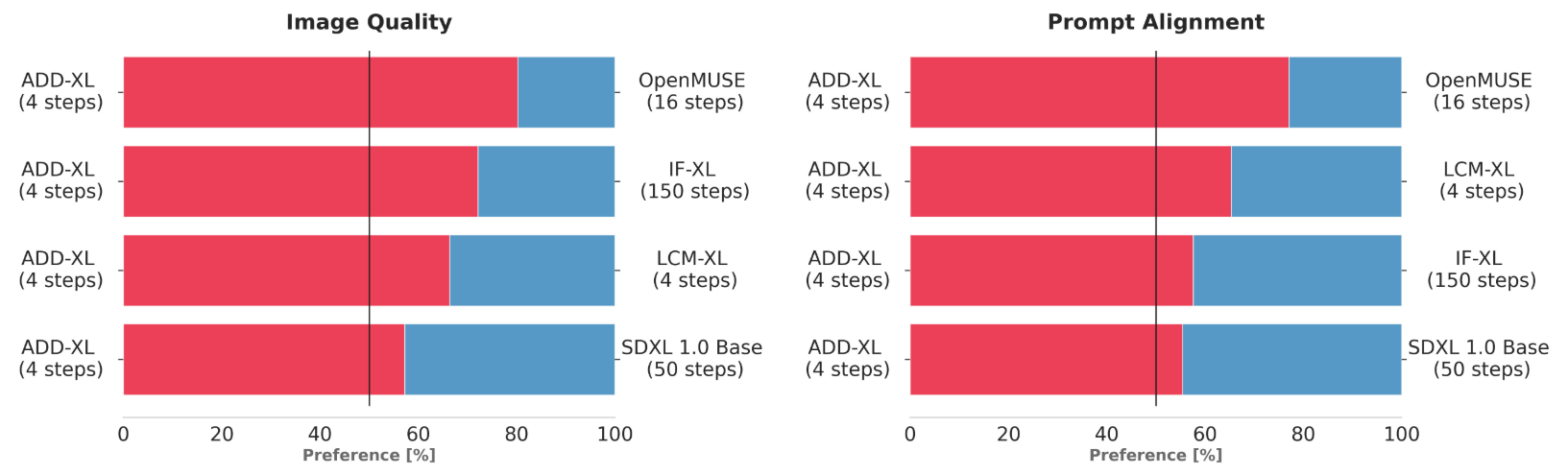
图 2.用户偏好调查(多步骤);ADD-XL(4 个步骤)与基线的比较结果
在本实验中,通过用户偏好调查,而不是常用的自动计算评价指标,更客观地检验了建议方法的有效性。用户选择了两个评价指标中较好的一个:提示符合性(输入提示是否正确反映在输出图像中)和图像质量。图 2 和图 3 对结果进行了总结。只需几个采样步骤(1-4),提议的方法就能超越生成模型的代表模型,并实现 SOTA 结果,尤其是在第 4 步。
3.2 定性结果和比较

图 3:SDXL 和拟议方法生成的结果示例。
图 3 显示了 SDXL 和建议方法之间的定性比较。可以看出,拟议方法只需四个步骤就能生成与 SDXL 相同或更好的图像质量。此外,还可以确认输入的质子也能正确反映在生成的结果中。特别是,如图 4左下方图像所示,可以确认所提出的方法比 SDXL 产生的噪声和伪影更少。包括定量实验结果在内,可以看出所提出的方法在质量和及时一致性方面都优于扩散模型的 SOTASDXL,而且采样步骤更少。
4.项目测试
4.1 图像到图像
import torch from diffusers import AutoencoderTiny, StableDiffusionPipeline from diffusers.utils import load_image from streamdiffusion import StreamDiffusion from streamdiffusion.image_utils import postprocess_image # You can load any models using diffuser's StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained("KBlueLeaf/kohaku-v2.1").to( device=torch.device("cuda"), dtype=torch.float16, ) # Wrap the pipeline in StreamDiffusion stream = StreamDiffusion( pipe, t_index_list=[32, 45], torch_dtype=torch.float16, ) # If the loaded model is not LCM, merge LCM stream.load_lcm_lora() stream.fuse_lora() # Use Tiny VAE for further acceleration stream.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd").to(device=pipe.device, dtype=pipe.dtype) # Enable acceleration pipe.enable_xformers_memory_efficient_attention() prompt = "1girl with dog hair, thick frame glasses" # Prepare the stream stream.prepare(prompt) # Prepare image init_image = load_image("assets/img2img_example.png").resize((512, 512)) # Warmup >= len(t_index_list) x frame_buffer_size for _ in range(2): stream(init_image) # Run the stream infinitely while True: x_output = stream(init_image) postprocess_image(x_output, output_type="pil")[0].show() input_response = input("Press Enter to continue or type 'stop' to exit: ") if input_response == "stop": break

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
4.2 文字到图像
import torch from diffusers import AutoencoderTiny, StableDiffusionPipeline from streamdiffusion import StreamDiffusion from streamdiffusion.image_utils import postprocess_image # You can load any models using diffuser's StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained("KBlueLeaf/kohaku-v2.1").to( device=torch.device("cuda"), dtype=torch.float16, ) # Wrap the pipeline in StreamDiffusion # Requires more long steps (len(t_index_list)) in text2image # You recommend to use cfg_type="none" when text2image stream = StreamDiffusion( pipe, t_index_list=[0, 16, 32, 45], torch_dtype=torch.float16, cfg_type="none", ) # If the loaded model is not LCM, merge LCM stream.load_lcm_lora() stream.fuse_lora() # Use Tiny VAE for further acceleration stream.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd").to(device=pipe.device, dtype=pipe.dtype) # Enable acceleration pipe.enable_xformers_memory_efficient_attention() prompt = "1girl with dog hair, thick frame glasses" # Prepare the stream stream.prepare(prompt) # Warmup >= len(t_index_list) x frame_buffer_size for _ in range(4): stream() # Run the stream infinitely while True: x_output = stream.txt2img() postprocess_image(x_output, output_type="pil")[0].show() input_response = input("Press Enter to continue or type 'stop' to exit: ") if input_response == "stop": break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
5. 总结
对抗性扩散蒸馏(ADD)是用于将预先训练好的扩散模型蒸馏为快速、低步骤的图像生成模型。所提出的方法结合了对抗性蒸馏和分数蒸馏损失,利用来自判别器的真实数据和来自扩散教师的结构理解,对稳定扩散和 SDXL 等训练有素的模型进行蒸馏。所提出的方法在进行一到两步的超快速采样时表现尤为出色,实验结果表明,它在很多情况下都优于之前的研究。另一方面,进一步增加步数会产生更好的结果,优于常用的多步扩散模型,如 SDXL、IF 和 OpenMUSE。不过,在图像质量和与 pronto 的一致性方面,单步采样生成模型仍有改进的余地。如果能做出更多改进,所提出的方法可能会成为第一个可实时使用的扩散模型。

