
- 1使用IDEA连接本地数据库_idea如何导入.txt文件
- 2Java NIO开发需要注意的陷阱(转)
- 3apdplat_org.apdplat
- 4XML注入漏洞_xml攻击
- 5【粉丝福利 | 第1期】教你如何一站式解决OpenCV工程化开发痛点
- 6基于STM32的智能宠物养护系统(边做边更新)_基于stm32的智能宠物喂食系统用到什么技术
- 7Oracle字符集的查看查询和Oracle字符集的设置修改_oracle数据库字符集查询
- 8【python】绘制地图:使用Html2Image生成png图片
- 9MaterialGAN:从ProGAN,StyleGAN,StyleGAN2到MaterialGAN_material gan
- 10git整合分支的两种方法——合并(Merge)、变基(Rebase)_分支合并
(AIGC)FIRST:百万数据集用于文本驱动的服饰合成和设计
赞
踩
整理:AI算法与图像处理
欢迎关注公众号 AI算法与图像处理,获取更多干货:

推荐
微信交流群现已有2000+从业人员交流群,欢迎进群交流学习,微信:nvshenj125

B站最新成果demo分享地址:https://space.bilibili.com/288489574
顶会工作整理Github repo:https://github.com/DWCTOD/CVPR2023-Papers-with-Code-Demo
论文速读
FIRST:百万数据集用于文本驱动的服饰合成和设计
标题: FIRST: A Million-Entry Dataset for Text-Driven Fashion Synthesis and Design
论文:https://arxiv.org/pdf/2311.07414.pdf
摘要:
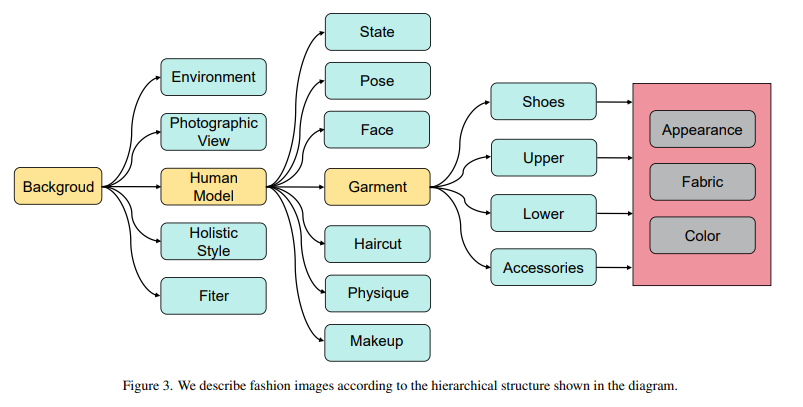
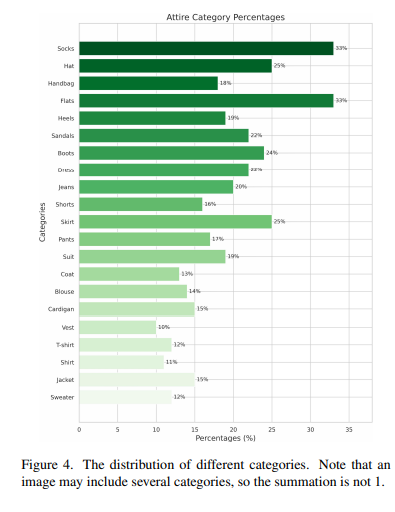
文本驱动的时尚合成和设计是人工智能生成内容(AIGC)中极其有价值的一部分,它有潜力推动传统时尚行业的巨大革命。为了推进文本驱动的时尚合成和设计的研究,我们引入了一个新的数据集,其中包含一百万张高分辨率时尚图像以及丰富的结构化文本(FIRST)描述。在 FIRST 中,有各种各样的服装类别,每个图像配对的文本描述都按多个层次结构进行组织。对通过 FISRT 训练的流行生成模型进行的实验表明了 FIRST 的必要性。我们邀请社区进一步开发更智能的时装合成和设计系统,使时装设计基于我们的数据集更具创意和想象力。数据集即将发布
主要贡献:

图像中出现的三大类失败案例由 SDXL 制作。(a) 显示了不自然的结构的面孔。(b) 包含生成的衣服的不正确结构。(c) 显示了弱可控性SDXL。
• 我们推出了第一个拥有一百万个实例的大规模时尚生成数据集,称为FIRST。该数据集包括分层和结构化文本注释,适合训练文本控制的时尚生成模型。此外,我们对此数据集提出了两个挑战。
• 初步的定量和定性实验表明,FIRST可以有效提高服饰stable diffusion的生成质量,提高文本对生成图像的控制。
数据 :
效果展示:

更多细节参考论文原文和GitHub项目,如果有帮助欢迎转发,感谢
工作整理
CVPR 2023
Updated on : 14 Nov 2023
total number : 2
Towards Automatic Honey Bee Flower-Patch Assays with Paint Marking Re-Identification
论文/Paper: http://arxiv.org/pdf/2311.07407
代码/Code: None
DialMAT: Dialogue-Enabled Transformer with Moment-Based Adversarial Training
论文/Paper: http://arxiv.org/pdf/2311.06855
代码/Code: https://github.com/keio-smilab23/dialmat
WACV 2024
Updated on : 14 Nov 2023
total number : 4
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
论文/Paper: http://arxiv.org/pdf/2311.07357
代码/Code: None
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
论文/Paper: http://arxiv.org/pdf/2311.06654
代码/Code: None
CrashCar101: Procedural Generation for Damage Assessment
论文/Paper: http://arxiv.org/pdf/2311.06536
代码/Code: None
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
论文/Paper: http://arxiv.org/pdf/2311.06443
代码/Code: None
NeurIPS 2023
Updated on : 14 Nov 2023
total number : 4
Robust semi-supervised segmentation with timestep ensembling diffusion models
论文/Paper: http://arxiv.org/pdf/2311.07421
代码/Code: None
Adaptive recurrent vision performs zero-shot computation scaling to unseen difficulty levels
论文/Paper: http://arxiv.org/pdf/2311.06964
代码/Code: None
LayoutPrompter: Awaken the Design Ability of Large Language Models
论文/Paper: http://arxiv.org/pdf/2311.06495
代码/Code: https://github.com/microsoft/layoutgeneration
Sounding Bodies: Modeling 3D Spatial Sound of Humans Using Body Pose and Audio
论文/Paper: http://arxiv.org/pdf/2311.06285
代码/Code: None

