
- 1IS2010修改XML File
- 2变量取整的方式_vue 取整
- 3MySQL数据库基本命令操作_mysql数据库基础命令
- 4开源进展 | WeIdentity v3.1.0 发布,新增数据库部署和使用模式_weidentity如何使用
- 5P6【力扣144,94,145】【数据结构】【二叉树遍历】C++版
- 6Android 保活措施_android 保活设置适配
- 7SpringBootWeb 篇-深入了解请求响应(服务端接收不同类型的请求参数的方式)_springboot 设定请求和响应参数类型
- 8PAT (Advanced Level) Practice 甲级 顶级题目_pta题库甲级
- 9如何用python进行接口测试(详细教程)_python接口测试
- 10Selenium自动化测试工具的介绍与使用_selenium工具
基于 Milvus + LlamaIndex 实现高级 RAG_llamaindex milvus
赞
踩
随着大语言模型(LLM)技术的发展,RAG(Retrieval Augmented Generation)技术得到了广泛探讨和研究,越来越多的高级 RAG 检索方法也随之被人发现,相对于普通的 RAG 检索,高级 RAG 通过更深化的技术细节、更复杂的搜索策略,提供出了更准确、更相关、更丰富的信息检索结果。本文首先讨论这些技术,并基于 Milvus 给出一个实现案例。
01.初级 RAG
初级 RAG 的定义
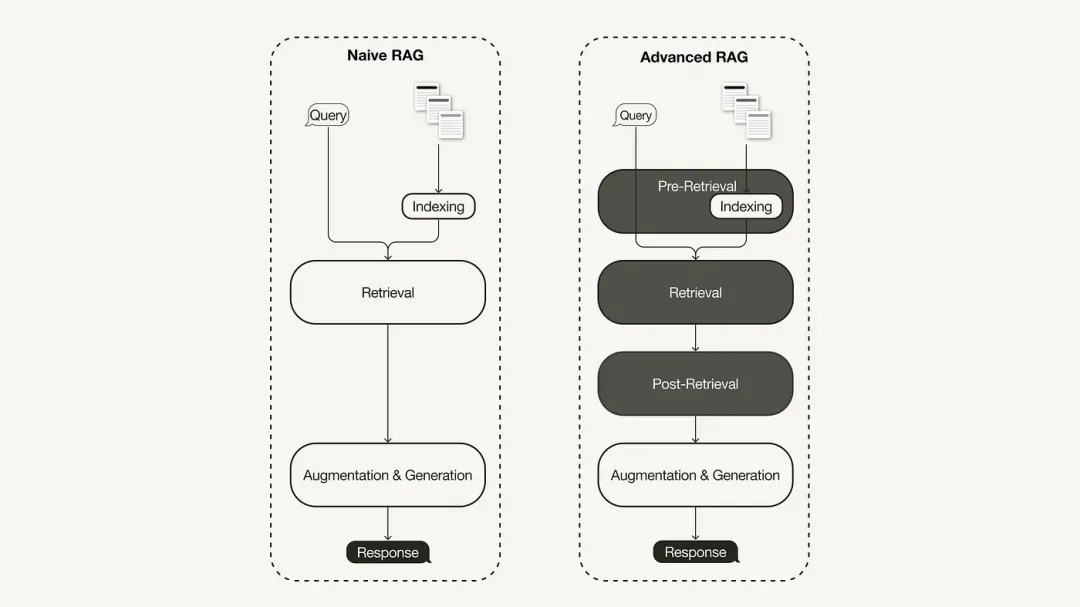
初级 RAG 研究范式代表了最早的方法论,在 ChatGPT 广泛采用后不久就取得了重要地位。初级 RAG 遵循传统的流程,包括索引创建(Indexing)、检索(Retrieval)和生成(Generation),常常被描绘成一个“检索—读取”框架,其工作流包括三个关键步骤:
-
语料库被划分为离散的块,然后使用编码器模型构建向量索引。
-
RAG 根据查询与索引块(Indexed Chunk)的向量相似度识别并对块进行检索。
-
模型根据检索块(Retrieved Chunk)中获取的上下文信息生成答案。
初级 RAG 的局限性
初级 RAG 在三个关键领域面临着显著挑战:"检索"、"生成"和"增强"。
初级 RAG 的检索质量存在许多问题,例如低精度和低召回率等。低精度会导致检索到的块无法对齐,以及幻觉等潜在问题。低召回率会导致无法检索到所有的相关块,从而导致LLM的回复不够全面。此外,使用老旧的信息进一步加剧了问题,可能导致不准确的检索结果。
生成回复质量面临着幻觉挑战,即 LLM 生成的答案并没有基于所提供的上下文,和上下文不相关,或者生成的回复存在着包含有害或歧视内容的潜在风险。
在增强过程中,初级 RAG 在如何有效地将检索到的段落的上下文与当前生成任务进行整合方面也面临着不小的挑战。低效的整合可能导致输出不连贯或破碎化。冗余和重复也是一个棘手的问题,特别是当多个检索到的段落包含相似信息时,生成的回复中可能会出现重复的内容。
02.高级 RAG
为了解决初级 RAG 的不足,高级 RAG 诞生了,并有针对性地进行了功能增强。首先讨论这些技术,这些技术可被归类为检索前优化、检索中优化和检索后优化。
检索前优化
检索前的优化关注数据索引优化以及查询优化,数据索引优化技术旨在以提高检索效率的方式存储数据:
-
滑动窗口:在数据块之间使用重叠,这是最简单的技术之一。
-
增强数据粒度:应用数据清理技术,例如移除不相关信息、确认事实准确性、更新过时信息等。
-
添加元数据:如用于过滤的日期、目的或章节信息等。
-
优化索引结构涉及不同的数据索引策略:如调整块大小或使用多索引策略。本文我们将实现的一种技术是句子窗口检索,它在检索时嵌入单个句子,并在推断时用更大的文本窗口替换它们。
检索中优化
检索阶段主要是识别最相关的上下文。通常,检索是基于向量搜索,它计算查询和索引数据之间的语义相似性。因此,大多数检索优化技术都围绕着 embedding 模型:
-
微调 embedding 模型:定制化 embedding 模型到特定领域上下文,特别是针对具有发展性或罕见术语的领域。例如,
BAAI/bge-small-en是一个高性能 embedding 模型,可以进行微调。 -
动态 embedding:适应词语使用中的上下文,不同于使用每个词一个向量的静态embedding。例如,OpenAI 的
embeddings-ada-02是一个复杂的动态embedding模型,捕捉到上下文理解。除了向量搜索之外,还有其他检索技术,如混合搜索(hybrid search),通常指的是将向量搜索与基于关键词的搜索相结合的概念。如果检索需要精确的关键词匹配,这种检索技术很有益处。
检索后优化
对检索到的上下文内容,我们会遇到如上下文超出窗口限制或上下文引入的噪音,它们会分散对于关键信息的注意力:
-
Prompt 压缩:通过移除无关并突出重要上下文来减少整体Prompt长度。
-
重排(Re-ranking):使用机器学习模型重新计算检索到的上下文的相关性得分。
检索后优化技术包括:
03.基于 Milvus + LlamaIndex 实现高级 RAG
我们实现的高级 RAG,使用了 OpenAI 的语言模型,托管于 Hugging Face的 BAAI重排模型,以及 Milvus 向量数据库。
创建 Milvus 索引
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)

- 1
索引优化示例:句子窗口检索
我们使用 LlamaIndex里的 SentenceWindowNodeParser 实现句子窗口检索技术。
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
- 1
SentenceWindowNodeParser 执行两项操作:
它将文档分隔成单独的句子,这些句子进行embedding。
对每个句子,它创建一个上下文窗口。如果指定 window_size = 3,那么生成的窗口将包含三个句子,从嵌入句子的前一个句子开始,跨越到之后的一个句子。该窗口将作为元数据存储。在检索期间,将返回与查询最匹配的句子。检索后,你需要通过定义一个 MetadataReplacementPostProcessor 并在 node_postprocessors 列表中使用它,来将句子替换为来自元数据的整个窗口。
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
- 1
检索优化示例:混合搜索
在 LlamaIndex 中实现混合搜索仅需对查询引擎进行两个参数的更改,前提是底层向量数据库支持混合搜索查询。Milvus2.4 版本之前不支持混合搜索(hybrid search),不过在最近发布的2.4版本,这个功能已经支持。
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
- 1
检索后优化示例:重排(Re-ranking)
高级 RAG 中添加一个重排器(Re-ranking)仅需三个简单步骤:
首先,定义一个重排(Re-ranking)模型,使用 Hugging Face 上的 BAAI/bge-reranker-base。
在查询引擎中,将重排模型添加到 node_postprocessors 列表中。
增加查询引擎中的 similarity_top_k 以检索更多的上下文片段,经过重排后可以减少到 top_n。
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
- 1
详细实现代码参见百度网盘链接: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 提取码: r2i1
-
好消息,Milvus 社区正全网寻找「 北辰使者」!!! • -
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 • -
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布

