
热门标签
热门文章
- 1黑马程序员---GUI(图形化界面)_黑马 gui
- 2芒种和环境日开展互动h5小游戏的作用是什么_h5案例芒种
- 3【知识整理】vue-cli脚手架开发项目如何进行js高级加密_vue 开发时 混淆加密文件
- 4Git环境配置及基本使用_please adapt and uncomment the following lines:
- 5Laravel与Element-plus开发(一、Laravel安装)_laravel element plus
- 6Spring Boot 整合 spring-boot-starter-mail 实现邮件发送和账户激活
- 7CLUSTERDOWN The cluster is down 的解决办法
- 8springboot整合neo4j-使用原生cypher Java API_springboot neo4j
- 9虚拟机配置IP地址_虚拟机routeros配置ip地址
- 10Pytest系列(13)- 重复执行用例插件之pytest-repeat的详细使用_@pytest.mark.repeat打印第几次
当前位置: article > 正文
SparkSQL优化器与执行流程_spark的执行过程 解释器 优化器
作者:Cpp五条 | 2024-06-06 05:38:42
赞
踩
spark的执行过程 解释器 优化器
Spark RDD执行流程
- 如图所示:
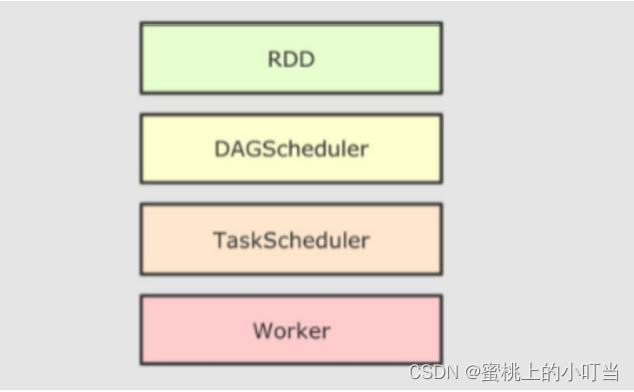
- 上图为RDD执行流程,主要的执行过程就是RDD代码→DAG调度器逻辑任务→Task调度器任务分配和管理监控→Worker工作。
SparkSQL的自动优化
- RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响;而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
- 为什么相比RDD,SparkSQL可以自动优化呢?
- 答:RDD内含的数据类型不限格式和结构;而DataFrame是二维表结构,可以被优化,而SparkSQL的优化依赖于Catalyst优化器。
Catalyst优化器
-
为了解决过多依赖Hive的问题,SparkSQL使用了一个新的SQL优化器代替Hive优化器。SparkSQL的架构如下图:

- API层就是Spark会通过一些API接受SQL语句。
- 收到SQL之后,将其交给Catalyst,Catalyst负责解析SQL,生成执行计划。
- Catalyst的输出应该是RDD执行计划。
- 最终交给群集Cluster来运行。
-
具体流程如下图:

-
解析SQL,并生成AST(抽象语法树)
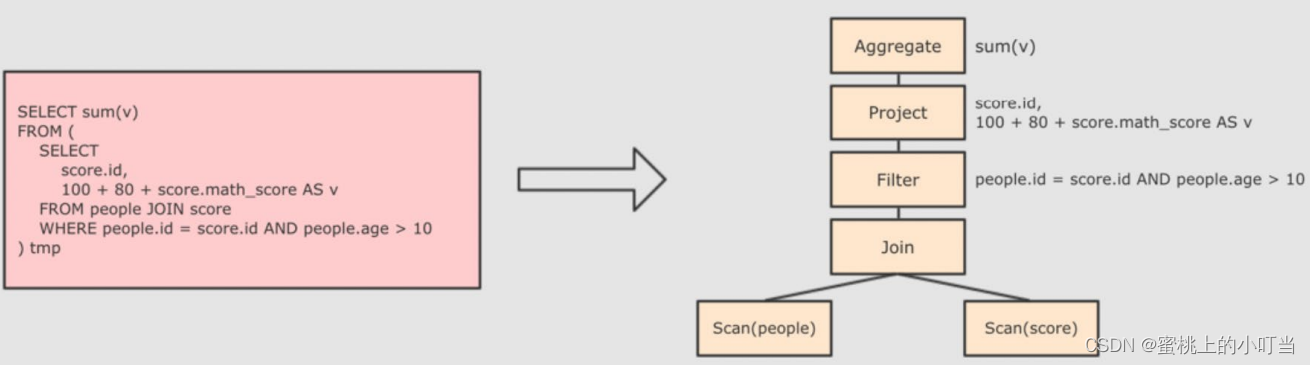
-
在AST中加入元数据信息,这一步也是为了后续优化
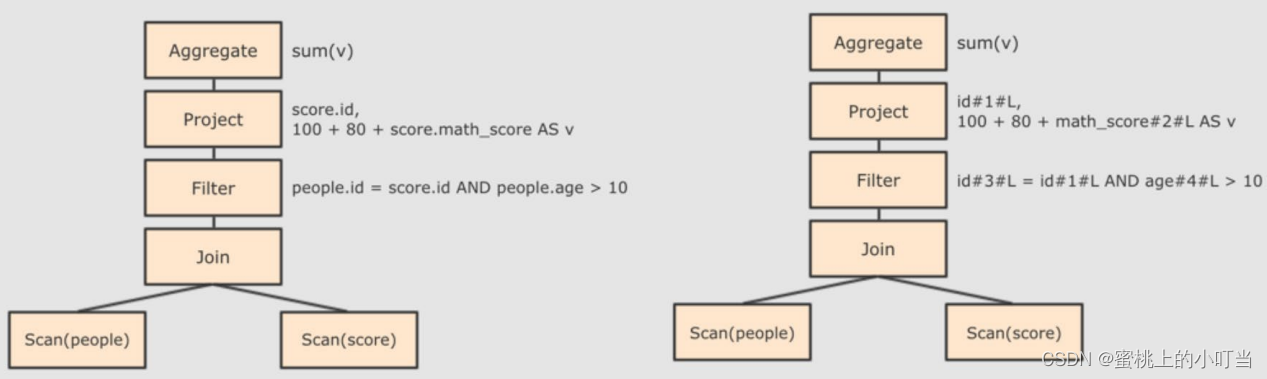

-
对已加入元数据的AST,输入优化器,进行优化,常见的优化方式有两种如下图所示:
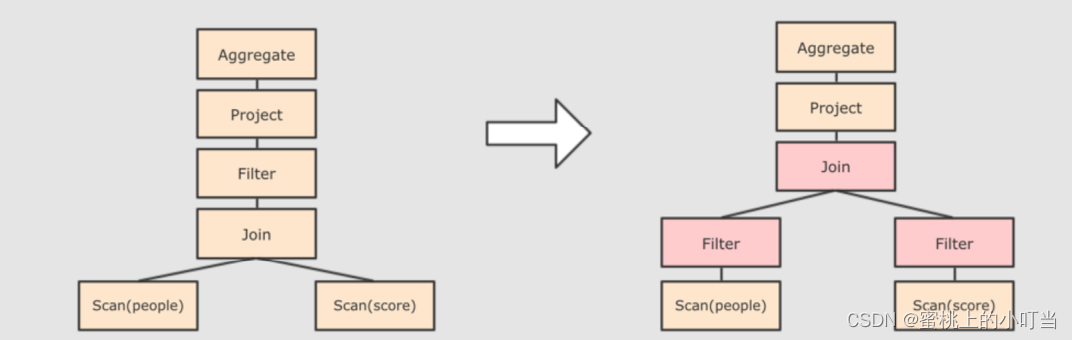
断言下推,将Filter这种可以减少数据集的操作下推,放在Scan位置,为了减少操作时候的数据量。上述代码是先join再where,而下推之后先过滤age,再join,这样可以减小join数据量提升性能。
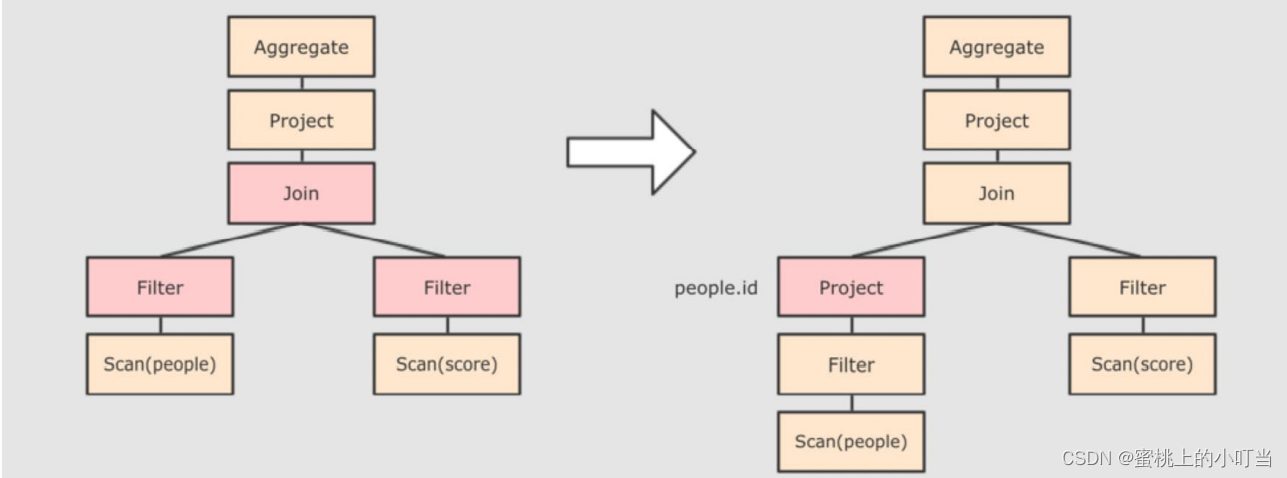
列值裁剪,在断言下推之后进行裁剪,由于people表中只用到了id这一列,所以可以把其他列裁剪掉,从而做到减少数据量,优化处理速度。 -
AST逻辑计划结束之后需要生成物理计划,从而生成RDD来进行后续的运行。我们可以通过queryExecution来查看逻辑执行计划;explain来查看物理执行计划。
-
-
总体上看Catalyst两大方面优化:
- 断言下推:将逻辑判断提到前面,以减少shuffle阶段的数据量;简单点说就是行过滤,提前执行where。
- 列值裁剪:将加载的列进行裁剪,尽量减少被处理数据的宽度;简单点说就是列过滤,提前规划select字段的数量。(列值裁剪存储parquet)
SparkSQL的执行流程

- 提交SparkSQL代码。
- Catalyst优化。
- Driver执行环境入口构建SparkSession。
- DAG调度器规划逻辑任务。
- TASK调度分区分配逻辑任务到具体的Executor上工作并监控管理任务。
- Worker执行工作。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/679741
推荐阅读
相关标签

