
- 1Java Map接口 - HashMap类
- 2小程序获取图片大小
- 3Mongodb入门--头歌实验MongoDB 实验——数据库优化
- 4深度学习常见的三种模型_深度学习几个模型介绍
- 5ssh-keygen(linux 命令) 创建 private key(私钥) , public key (公钥),实现ssh,scp,sftp命令无密码连接
- 6GpuMall智算云:AUTOMATIC1111/stable-diffusion-webui/stable-diffusion-webui-v1.8.0_xformers 0.0.23.post1
- 7Python知识点14---被规定的资源_在python类的内部,使用def关键字可以定义属于类的方法,这种方法需要使用{ }
- 8数据结构与算法要点总结(4):数组、矩阵、字符串、广义表
- 9Ubuntu22.04安装WordPress教程(利用nginx环境和MariaDB数据库,安装使用WordPress)_ubuntu 22.04安装wordpress
- 10PyTorch使用tensorboard的SummaryWriter报错
Hadoop与Spark关系_阐述spark和hadoop的相互关系
赞
踩
说明:近期在做一个图关系项目时,使用到了saprk分析引擎和Hadoop的HDFS文件系统,在了解的过程中产生了关于Hadoop与Spark的关系是什么样的疑问,在此简单的整理一下
一:介绍
1:Spark
Apache Spark™ is a unified analytics engine for large-scale data processing.
这是官网上的一句话,意思就是“Spark是大规模数据处理的统一分析引擎”,是专为大规模数据处理而设计的快速通用的计算引擎。由UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用并行框架。
Apache Spark使用最先进的DAG调度程序,查询优化器和物理执行引擎,实现批处理和流数据的高性能。
可以兼容多种语言:Java,Scala,Python,R和SQL 等,来自官网的一个图:

spark的架构图:

2:Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Apache Hadoop软件库是一个允许使用简单的编程模型跨计算机集群分布式处理大型数据集的框架。它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储。库本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,从而在计算机集群之上提供高可用性服务。
简单的来说:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
在学习过程中,发现一个特别好的图,在此和大家分享一下,如评论所说’一图解千愁‘,Hadoop集群完整架构设计图(来自:https://blog.csdn.net/quwenzhe/article/details/53905572):

二:不同层面的关系
1:功能
首先,Hadoop和Spark两者都是大数据框架,但是各自存在的目的不尽相同。就如上述所说,Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着不需要购买和维护昂贵的服务器硬件,直接使用廉价的机器就可组成一个高可用的集群。Hadoop不仅提供分布式存储,还可以使用其MapReduce模型对大数据量进行分析计算。
而Spark主要是一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
2:依赖关系
Hadoop主要是提供HDFS分布式数据存储功能,在这之外还提供了叫做MapReduce的数据处理功能。所以我们完全可以抛开Spark,使用Hadoop自身的MapReduce来完成数据的处理。
Spark也不是非要依附于Hadoop才能生存。但是Spark没有提供文件管理存储系统,所以,它必须和其他的分布式文件系统进行集成才能运作。我们可以选择Hadoop的HDFS,也可以选择其他的基于云的数据系统平台。大部分情况下Spark还是使用的Hadoop的HDFS文件系统。
3:数据量影响
Hadoop的MapReduce模型特别适合大数据量的离线处理。
Spark适合对数据量不太大的数据处理,可以是离线也可以是实时处理。
对于相同的数据量,spark的处理速度快于Hadoop,为什么?
- Spark和Hadoop都是基于内存计算的。Spark和Hadoop的根本差异是多个任务之间的数据通信问题:Spark多个任务之间数据通信是基于内存,而Hadoop是基于磁盘。
- MapReduce是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果写到集群磁盘中,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群磁盘中。。。“要不断的进行磁盘的读取和存储。
- 对于Spark,它会在内存中以接近“实时”的时间完成所有的数据分析:“从集群中读取数据,完成所有必须的分析处理,将结果写回集群,完成,” 只需要加载一次即可,任务之间的通讯几乎全在内存中。Spark的所有运算并不是全部都在内存中,当shuffle发生的时候,数据同样是需要写入磁盘的
- Spark的批处理速度比MapReduce快近10倍,内存中的数据分析速度则快近100倍,下面为Spark官网中的关于spark和hadoop做逻辑回归处理的一个比较:
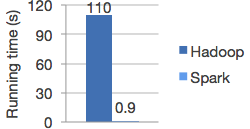
4:容错
MapReduce使用TaskTracker节点,它为 JobTracker节点提供了心跳(heartbeat)。如果没有心跳,那么JobTracker节点重新调度所有将执行的操作和正在进行的操作,交 给另一个TaskTracker节点。这种方法在提供容错性方面很有效,可是会大大延长某些操作(即便只有一个故障)的完成时间。
Spark使用弹性分布式数据集(RDD),它们是容错集合,里面的数据元素可执行并行操作。RDD可以引用外部存储系统中的数据集,比如共享式文件系统、HDFS、HBase,或者提供Hadoop InputFormat的任何数据源。Spark可以用Hadoop支持的任何存储源创建RDD,包括本地文件系统,或前面所列的其中一种文件系统。Spark的缓存具有容错性,原因在于如果RDD的任何分区丢失,就会使用原始转换,自动重新计算。
大数据领域知识博大精深,想要深入学习还需要继续努力呀。
参考:
https://blog.csdn.net/onlyoncelove/article/details/81945381
https://blog.csdn.net/forward__/article/details/78770466
https://blog.csdn.net/zcy6675/article/details/78256164?locationNum=2&fps=1

