- 1pyqt5背景色设置使用css或者是调色板
- 2五一 Llama 3 超级课堂 | 第一节 本地Web Demo部署 实践笔记
- 3HBase优化之Apache Phoenix二级索引_skip-scan-join table 0
- 4【idea插件神器】教你如何使用IDEA一键set实体类中所有属性_idea设置set所有bean属性
- 5群晖HomeAssistant安装HACS插件商店结合内网穿透实现公网访问本地智能家居_群晖hacs安装包
- 6学习通刷课_学习通自动刷视频插件
- 7RP2040-HAT-MODBUS-C_arduino rp2040 modbus
- 8腾讯计算机编程本科年薪,腾讯程序员年薪80万,却感慨:天花板太低,想放弃工作去读研!...
- 9【云原生】kubernetes中pod的生命周期、探测钩子的实战应用案例解析
- 107 Series FPGAs Integrated Block for PCI Express IP核 Advanced模式配置详解(三)_advanced设置
mysql的锁有几种,圆我大厂梦!
赞
踩
kafka面试基础[17]
1.Kafka的用途有哪些?使用场景如何?
2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
3.Kafka中的HW、LEO、LSO、LW等分别代表什么?
4.Kafka中是怎么体现消息顺序性的?
5.Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
6.Kafka生产者客户端的整体结构是什么样子的?
7.Kafka生产者客户端中使用了几个线程来处理?分别是什么?
8.Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
9.“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
10.有哪些情形会造成重复消费?
11.哪些情景下会造成消息漏消费?
12.KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
13.简述消费者与消费组之间的关系
14.当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
15.topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
16.topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
17.创建topic时如何选择合适的分区数?
kafka面试进阶[15]
1.Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么?
2.优先副本是什么?它有什么特殊的作用?
3.Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
4.简述Kafka的日志目录结构
5.Kafka中有哪些索引文件?
6.如果我指定了一个offset,Kafka怎么查找到对应的消息?
7.如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
8.聊一聊你对Kafka的Log Retention的理解
9.聊一聊你对Kafka的Log Compaction的理解
10.聊一聊你对Kafka底层存储的理解
11.聊一聊Kafka的延时操作的原理
12聊一聊Kafka控制器的作用
13.Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
14.消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
15.Kafka中的幂等是怎么实现的?
kafka面试高阶[12]
1.Kafka中的事务是怎么实现的?
2.失效副本是指什么?有哪些应对措施?
3.多副本下,各个副本中的HW和LEO的演变过程
4.Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
5.为什么Kafka不支持读写分离?
6.Kafka中的延迟队列怎么实现
7.Kafka中怎么实现死信队列和重试队列?
8.Kafka中怎么做消息审计?
9.Kafka中怎么做消息轨迹?
10.怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
11.Kafka有哪些指标需要着重关注?
12.Kafka的哪些设计让它有如此高的性能?
答案在这里啦!!整理起来好多呀,有30页…

看完了笔记,刷了面试真题,最后对整个kafka知识做个梳理总结:控制器(Controller)、生产者、配置参数、消费者、Broker端、主题与分区、文件目录、时间轮(TimingWheel)等
面试题总结
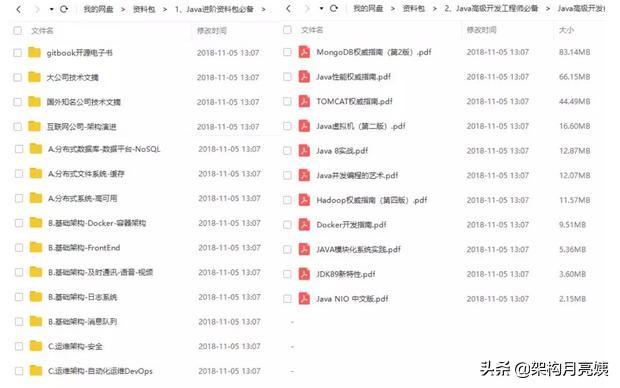
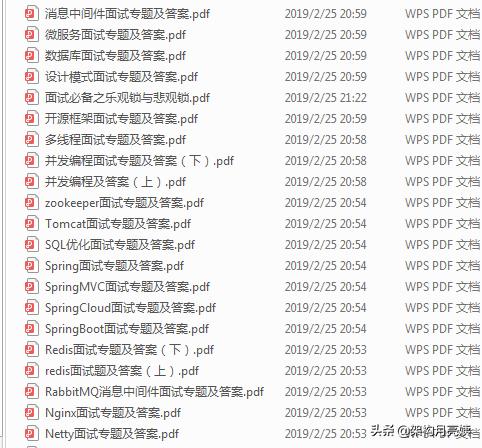
其它面试题(springboot、mybatis、并发、java中高级面试总结等)

batis、并发、java中高级面试总结等)**
[外链图片转存中…(img-wK4FlVP6-1626880274669)]
[外链图片转存中…(img-o4NYdexm-1626880274672)]