
- 1【学习笔记】图神经网络库 DGL 入门教程(backend pytorch)_dglbackend
- 2SPI协议(三):SPI_Flash(M25P16)读写操作_spi flash 读写
- 3教你如何将Web项目部署到Linux中_前端项目发布到linux
- 4vue 跨域代理,对象存储(阿里云、aws)预签名上传文件
- 5vue3组件封装系列-表格及分页_vue3封装table、分页组件
- 6iReport 笔记(五) 中文设置_ireport4.5.0汉化
- 7测试用例编写方法_编写测试用例。软件需求描述: 2、用户名和密码分别有大小写字母、数字、特殊字符构成。作业要求: 1、
- 8mysql中的DQL查询_mysql查询命令dql
- 9Docker部署安装及常规操作
- 10数据库管理系统学习笔记_数据库管理系统笔记
基于Informer的股价预测(量化交易综述)_基于informer算法的气象数据预测研究
赞
踩
摘要
股票市场是金融市场中不可或缺的组成部分。准确预测股票趋势对于投资者和市场参与者具有重要意义,因为它们可以指导投资决策、优化投资组合以及降低金融风险。而且可以提升国家国际地位以及金融风险控制能力,还可以促进股票市场发展以及资源优化利用。与此同时,股票趋势预测算法作为时间序列预测领域的重要分支,在其它时序预测分支上也具备通用性。
而量化交易就是利用数学模型和计算机技术来进行投资交易决策的一类方法,旨在增加投资回报率。随着信息技术和数据处理能力的不断提升,量化交易在金融市场中的真实应用越来越广泛。本论文介绍了量化交易的背景,发展历史及国内外的发展现状,并引入了量化交易核心的前置理论与技术。其中,股票价格预测作为量化交易中的主要任务,对投资决策具有重要影响。故本论文重点介绍了当今主流的Informer模型,提出了实际方案探讨其在股票价格预测中的应用。并通过实验检验当前Informer方案的可行性,同时观察方案预测效果。
然而,本论文提出的原Informer方案在不同方面均存在一定局限,故从数据与模型两大部分讨论了原方案的不足,并提出了优化架构的思考。也针对其中的一些思考基于原方案的代码进行了改进,并通过消融实验对比验证了优化效果,还进行了实验结果的展示与可视化的尝试,为读者提供了更直观的理解和评估。也为进一步提高股价预测效果和量化交易应用提供了一定的参考和指导。
关键词:Informer;股价预测;深度学习;
目录
第1章 简介
本论文主要将从架构、流程、效果等方面介绍基于Informer的股票价格预测方案。故在本章首先简介量化交易的核心前置知识,包括其概念、起源、意义、面临的问题等背景,由此过渡到其数据的来源与类别,转而再解析其技术发展历程与发展现状,并在最后明晰本论文的后续章节安排。
1.1 背景与研究意义
股票市场作为金融市场的一个重要组成部分,在经济发展中发挥着至关重要的作用。在过去的几十年里,人们对股票市场的兴趣呈指数级增长。因此,每天都有价值数十亿美元的资产在证券交易所交易也就不足为奇了。投资者们在资本市场上十分活跃,希望在其投资期限内实现盈利。而量化交易就是兴起于上世纪七十年代的股票市场的一种投资方式,它广义上是指利用统计分析方法和计算机技术来建立量化模型发掘历史金融时间序列数据中存在的规律,以此计算出对应的未来趋势。在此基础上,进行投资决策,并获得收益的一种投资方式[1]。其背景可以追溯到金融市场和科技的发展,即离不开现代金融理论的发展、计算机技术的普及和发展,以及交易成本的下降三个主要原因。与量化交易相对的是基于基本面分析的主观判断交易,后者更注重交易者结合自身经验与市场基本面(经济形势、公司数据、行业动态和市场预期等因素)分析做出交易投资决策,两类交易方法的对比如表1.1所示:
表1.1 量化交易 vs 基于基本面分析的主观判断交易
| 量化交易 | 基于基本面分析的主观判断交易 | |
| 核心原理 | 利用数学模型和计算机技术来进行投资交易决策 | 依赖于交易者对基本面数据的解读结合个人或团队主观判断 |
| 依赖 | 历史金融数据和模型的计算结果 | 基本面因素与交易者经验 |
| 特点&应用场景 | 系统性,客观性,自动化,高效可并行,消除情绪和主观判断的影响,更适应大规模、高频率的交易 | 人工操作,速度有局限,但能捕捉市场中的非线性特征和变化,对特定事件和市场趋势作出灵活的反应。 |
在不同维度上量化交易带来较准确的股票预测都有重大意义。对于个人或机构投资者,他们可以通过量化交易对金融时间序列未来趋势的判断和预测,来进行相关决策,来达到规避情绪干扰风险、获取超额收益的目的,同时提高时间与资源的利用率。同时,量化交易对社会与交易市场也都有着积极作用。一方面,预测股票走势增加投资者回报也增强他们的消费能力和信心,拉动内需增长。其次,预测股票走势也促进股票市场的发展和完善,提高市场效率和透明度,降低市场的系统性风险和金融危机的潜在影响。另外,预测股票走势还可以增加社会财富和福利,改善民生水平,推动经济结构调整和转型升级,增加就业机会和税收收入。而在国家意义层面上,通过量化交易的技术手段和数据分析,国家可以更好地理解和应对股票市场的变化和波动,优化经济结构并提高资源配置效率。核心作用可以概括为以下几点:第一,有助于政府制定合理的经济政策,促进经济增长和稳定。第二,增强国家在国际金融市场上的竞争力和影响力。第三,提高国家对风险和危机的应对能力,维护国家安全和利益。总体而言,量化交易的意义在于提供了一种科学、系统化和高效的交易方法,可以提高交易的一致性、效率和风险控制能力。为个人提供了公平、高效和智能化的投资方式,提高了交易决策的准确性和投资回报率。同时也推动了金融市场的发展、优化资本配置和加强监管,对社会和国家的金融体系稳定和可持续发展起到积极的推动作用。
然而,尽管量化交易在金融领域取得了显著的进展,但它仍然面临一些问题和挑战[2],最核心的问题是股价预测的准确度难以保证,且抗波动能力(市场适应性)与泛化性能比较差。由于影响股票市场的因素非常多,各种金融时间序列数据也随着交易过程不断地波动变化,因此这是一个非常复杂的市场。具体来说,量化交易主要依赖于模型的计算结果,由历史金融数据“学习”而产生决策。但影响股票价格等金融时间序列数据变化的因素不但包括微观方面的,例如公司的经营以及财务状况、投资者的情绪等。也有宏观方面的,例如通货膨胀、国家宏观经济政策、国际形势、自然灾害、战争等。故其中包含了大量的非稳态和不可控因素。而这些非平稳的混沌信号数据如果不能得到很好的处理,将会对人们使用的方法或者模型产生巨大的干扰,甚至使得该系统得到完全错误的结论和判断。同时,除了外部微观宏观方面对于数据的冲击,还有不同方案设计与选择对于模型效果的影响。目前量化交易使用的一般为深度学习模型,效果与数据本身的可靠性与丰富性、特征与参数选择的合理性、网络结构设计的正确性等均有影响,如设计不当,很容易出现过拟合、机械化风险等问题,大大影响真实交易中股价预测的准确性。另外,量化交易本身便存在一定的风险,其涉及到金融市场的各种法规和监管要求,违反相关规定可能导致法律风险和处罚。综上所述,针对基于量化交易进行股票价格预测的应用仍面临着巨大的挑战,如何针对这类非稳态金融时间序列数据进行合理地处理,如何有效设计并选择量化交易方案,提取出市场中真正有用的、对未来趋势产生影响的信息,以协助深度学习预测模型来进行预测,并积极依照相关法律法规规避相关风险,最终提高量化交易模型在股票预测中的准确率,已经成为了当前工作的重心所在。
1.2 数据简介
随着量化交易不断发展,多种多样的数据都逐渐纳入了其统计分析或模型训练的考量范围。具体使用哪些训练数据取决于选取的量化交易策略的特点和目标。不同的策略可能会侧重不同类型的数据,以满足其模型的需求和目标。总的来说,量化交易的数据可以按数据类型分为三种。第一,纯文字数据,如一些政策改革、议情信息或论坛讨论等。第二,纯数字数据,如股票的成交量、成交额、不同时期价格等。第三,混合信息,一般是一些股价数据与分析说明,或一些股价变化与讨论等。具体来说,量化交易数据常见的来源与类别汇总于表1.2:
表1.2 量化交易数据常见来源与类别
| 1、来源:
|
| 2、类别:
|
1.3 发展历程与研究现状
1.1背景描述中提到,广义上量化交易起源于20世纪下半叶,总的来说早期的量化交易主要基于一些统计学方法或机器学习模型,而随着计算机技术与硬件资源的高速发展,基于分类与时间系列的深度学习模型出现并在股价预测应用中表现出优秀效果。而在注意力机制与Transformer算法出现与流行后,基于Transformer及其变体模型成为了当前量化交易的主流方案。
1970年,尤金·法玛(Eugene Fama)提出了有效市场假说(EMH)[3],证明了股票价格包含的信息量以及重要性,也从侧面论证了根据股票公开的历史信息可以推断股票价格。至此,大量使用传统统计学和机器学习方法来分析过去的股票趋势和预测未来的股票价格的工作开始出现。在量化交易中基于传统统计方法进行时间序列预测的工作有很多,一些经典方案包括差分整合移动自回归平均模型(ARIMA)[4]用于非平稳数据序列预测,简单指数平滑法(SES)[5]用于预测时间序列,以及霍尔特阻尼指数平滑法[6]。而在基于机器学习方法的量化交易工作上,支持向量机(SVM)、随机森林(RF)、人工神经网络(ANN)等方法在一些复杂和非线性的时间序列数据上表现出了优势。具体应用中,Huang等人[7]用SVM 预测了股票指数的每周运动方向。Hassan等人[8]通过结合隐马尔可夫模型(HMM)、ANN 和遗传算法(GA)预测了金融市场行为。Shen等人[9]引入了人工鱼群算法(AFSA)来优化径向基函数神经网络(RBFNN)以预测股票指数。上述论文的实验结果无一例外地证明了一个结论:在预测股票走势应用方面,机器学习模型优于ARIMA等统计学模型。
自21世纪以来,得益于计算机技术与硬件的进步,深度学习进入了快速发展期。一些深度学习方法开始在量化交易的时间序列预测任务中取得了显著的成果,如基于分类的深度学习(卷积神经网络(CNN)、时间卷积网络(TCN)等)。而在基于时间系列的深度学习研究中也出现了如循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)等方法,在长期依赖高维度的时间序列数据上展现出了更优秀的效果和效率。具体工作中,Li X等人[10]与Liu X等人[11]使用递归神经网络(RNNs)用于预测股票价格,Selvin S等人[12]和Chen K等人[13]使用LSTM进行股价预测。在对比评估方面,Nabipour 等人[14]比较了九种机器学习模型(决策树、随机森林、支持向量机、逻辑回归和人工神经网络等)和两种深度学习方法(RNN和LSTM)在预测股票趋势方面的效果,验证了单一深度模型相较机器学习模型在股价预测应用上的优势。同时,大量组合模型方案在量化交易实际应用中被提出,比如Li X等人[15]将autoencoders和LSTM结合在一起,预测全球各个不同市场的指数,并在各种发展中市场和发达市场中显示了其预测能力。而在分类深度模型结合中,Lin 等人[16]提出了一个股票价格趋势预测模型 Resnet-M,该模型结合了一个残差网络和一个卷积神经网络。另外,为降低股票数据的高噪音和高波动性对模型的影响,有很多降噪算法也与深度模型组合应用于金融预测领域,比如,应用经验模态分解(EMD)和自适应噪声完全集合经验模式分解(CEEMDAN)算法分解金融时间序列特征[17],以及LSTM结合EMD分析和预测债券指数[18]等。
2014年,Bahdanau等人[19]提出了注意力机制。2017 年,基于注意力机制的Transformer[20]问世,并在图像识别和自然语言处理等任务上都取得了进一步的成果,性能得到了显著提升。与此同时,也有大量基于Transformer算法与它的改进算法(如Informer[21])进行股票预测的研究工作出现,例如,Liu等人[22]和Chen等人[23]都基于注意力机制提出了不同的股票趋势预测算法;Jiali等人[24]提出了一个基于双重注意机制的生成网络,以捕捉股票的长期依赖性;Tae-Won等人[25]使用Transformer 对不同股票数据进行分类;Chao等人[26]使用Transformer对多国指数数据集进行回溯测试;Zong-Yu等人[27]结合LSTM和Transformer预测中国 A 股市场。而对于基于Transformer方案的效果评估,许多研究成果[28][29]都表明基于Transformer及其变体的方案于股价预测的应用上在信息提取能力、推理速度、预测准确率等多方面相较基于LSTM等过往基于时间系列的深度模型量化交易方案均有更好的效果,故基于Transformer及其变体模型成为了如今量化交易的主要技术方案。
1.4 后续章节安排
本论文后续结构分布如下,在第二章会解析本文研究Informer涉及到的核心前置理论技术和算法,主要是股价预测模型的抽象架构介绍,以及LSTM与Transformer算法的解析。第三章将会详细介绍Informer在股票价格预测中的具体应用方案,包括但不限于其原理介绍、架构解读与流程分析。而在第四章中,会从不同维度基于Informer模型的局限进行讨论,并尝试提出了一些优化的思路。第五章中主要进行Informer方案的实践与优化,验证第三章方案的可行性,并通过消融实验结果的展示与对比分析检验第四章部分优化思路的正确性与合理性。并在最后标明了本论文的参考文献。
第2章 前置相关理论与技术
上一章从背景、数据、发展历程及现状简介了量化交易策略,为便于后续章节中基于Informer的股票价格预测的解析、实践与优化,本章将会引入核心的前置相关理论与技术。包括股票预测模型架构的介绍,LSTM、Transformer的原理介绍与模型解析等。
2.1 股票预测模型架构
近年来,随着深度学习算法的发展,深度学习模型也被广泛应用于量化交易中的股票趋势预测任务。基于深度学习股票预测的抽象架构如图 2.1 所示,深度学习模块(模块)是核心。
使用不同类型数据预测股票趋势,往往需要进行不同的预处理。对论坛评论、机构研究报告等文本数据,需要进行清洗、数字化等预处理。而对于使用价格、交易量等市场数据进行预测趋势的情况而言,最常见且最需要的预处理是降噪、改变维度等。另外,使用不同的参数组合,不同的深度学习模型组成量化交易架构,都会使预测效果大相径庭。

图2.1 股票预测抽象模型架构
2.2 LSTM
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种,解决了传统RNN梯度消失[30]的问题与长期以来隐变量模型存在着长期信息保存和短期输入缺失的问题,即其具有更好的学习长期依赖的能力。LSTM架构如图2.2所示,如图2.2可见,在架构设计上,LSTM在隐藏层的各个神经单元中增加记忆单元,用于记录通过隐藏层的信息。引入了称为“门”的机制,通过门控制信息的流动和记忆的更新,其中门的类别与简介汇总于表2.1。LSTM 的网络结构由多个 LSTM 单元组成,每个单元接受输入、产生输出,并将细胞状态传递给下一个时间步。
表2.1 LSTM中门的类别与简介
| 类别 | 简介 |
| 遗忘门(Forget Gate) | 决定细胞状态中哪些信息应该被遗忘 |
| 输入门(Input Gate) | 决定新的输入信息对细胞状态的影响程度 |
| 输出门(Output Gate) | 决定当前时刻细胞状态对于下一时刻隐层输出的影响 |
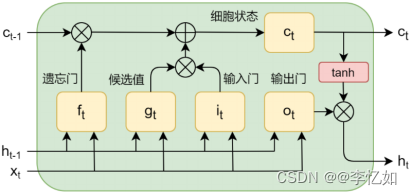
图2.2 LSTM架构[31]
而LSTM的包括模型原理与门设计简介的流程解析(http://colah.github.io/posts/2015-08-Understanding-LSTMs/)总结于表2.2:
表2.2 LSTM总体流程解析
| 输入:将数据集导入模型 |
| 1、Sigmiod层: 输出0到1之间的数值,描述每个部分有多少量可以通过。0代表“不许任何量通过”,1就指“允许任意量通过”。通过三个门来保护和控制细胞状态。 |
| 2、遗忘门(LSTM-1): 决定我们从“细胞”中丢弃什么信息。该层读取当前输入x和前神经元信息h,由ft来决定丢弃的信息。输出结果1表示“完全保留”,0表示“完全舍弃”。
图2.3 LSTM遗忘门设计与原理 |
| 3、输入门(LSTM-2): 确定细胞状态所存放的新信息,这一步由两层组成。sigmoid层作为“输入门层”,决定我们将要更新的值i;tanh层来创建一个新的候选值向量加入到状态中。在语言模型的例子中,我们希望增加新的主语到细胞状态中,来替代旧的需要忘记的主语。
图2.4 LSTM输入门设计与原理 |
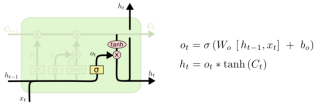
| 4、输出门(LSTM-3): 更新旧细胞的状态,丢弃掉我们确定需要丢弃的信息。接着获取新的候选值,根据我们决定更新每个状态的程度进行变化。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的信息并添加新的信息的地方。
图2.5 LSTM输出门设计与原理 |
| 5、输出确定/候选记忆元: 最后一步要确定输出,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在-1到1之间的值)并将它和sigmoid门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。在语言模型的例子中,因为语境中有一个代词,可能需要输出与之相关的信息。例如,输出判断是一个动词,那么我们需要根据代词是单数还是负数,进行动词的词形变化。
图2.6 LSTM输出确定原理 |
| 输出:处理后的数据/预测数据 |


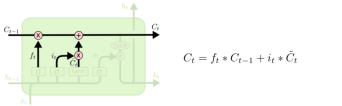
综上所述,通过在时间维度上不断迭代上述过程,LSTM 可以得到与输入时间序列维度相同的隐藏层序列数据{h0,h1,……,ht}。这么多年来,LSTM已经在很多领域进行了探索和研究,例如自然语言处理、机器翻译、天气预测等,并且在这些领域得到了广泛的应用,取得了优秀的成果。
2.3 注意力机制
注意力机制是用于神经网络模型中一种模拟人类视觉或认知过程的技术,用于在给定输入数据的情况下,选择性地聚焦于相关的部分,以便在处理和解决问题时更加有效地利用信息。注意力机制在各种机器学习任务中被广泛应用,包括自然语言处理、计算机视觉和强化学习等领域。具体来说,注意力机制会在模型处理序列信息时,通过分配不同的权重给序列中的不同位置,使得模型能够更加注意到序列中的重要信息。即使用新的注意力机制权重作为关键程度度量,来学习和训练特征数据中的各个部分。它使用特定的算法将特征数据中每个部分的关键程度表示出来,并加以学习训练。这种机制可以通过计算每个特征的重要性来帮助模型更好地分析数据,注意力机制的应用架构样例(以增强字的应用场景为例)如图2.7所示。
注意力机制主要涉及到三个概念:查询(Query)、键(Key)和值(Value)。查询是用来表示我们希望关注的内容或特征,而键值对是表示输入信息中的内容或特征。注意力机制通过计算查询和键之间的相似度,以确定在给定查询下,应该关注哪些键值对。
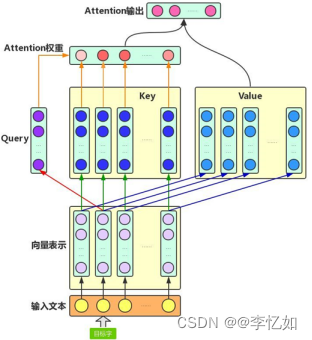
图2.7 注意力机制应用架构样例
注意力机制的实现方式有很多种。一种常用的注意力机制是自注意力模型(Self-attention Mechanism),架构如图2.8所示,Transformer模型也是也是基于自注意力机制。
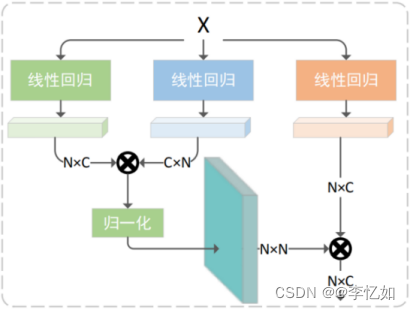
图2.8 自注意力机制架构[20]

图2.9 多头注意力机制架构[20]
2.4 编码器-解码器结构
编码器-解码器结构(Encoder-Decoder)是深度学习模型的抽象概念,常用于处理序列到序列等各种自然语言处理任务,如机器翻译、文本摘要、对话生成等。一般认为很多模型均起源/共同表征于这个架构,包括但不限于CNN、RNN、Transformer,抽象架构如图2.10。顾名思义,它包含两个部分:编码器(Encoder)和解码器(Decoder)。编码器接收一个输入,并在编码过程中计算出中间特征。解码器接收中间特征和另一个输入,并在解码过程中计算出输出。
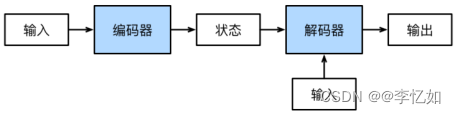
图2.10 编码器-解码器抽象架构
2.5 Transformer模型
Transformer是一种基于自注意力机制的深度学习模型,采用了一种并行化的方式来处理输入序列。架构如图2.11所示。主要应用于自然语言处理任务,如机器翻译、问答系统和实体识别,同时也可以在应用在量化交易等其他真实场景。它由输入层、编码器、解码器和输出层组成。输入层对输入文本进行预处理,包括词的字嵌入表示和添加位置编码。输出层将解码器的输出序列线性变换到指定维度进行输出。
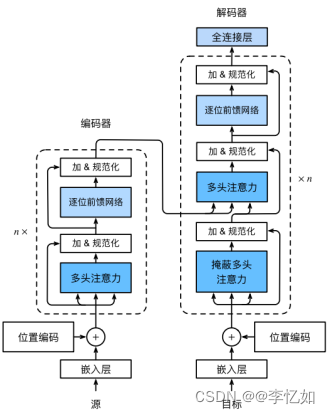
图2.11 编码器-解码器抽象架构[20]
编码器是Transformer的关键部分,用于对输入文本进行编码,生成文本序列的表示向量。解码器利用编码器的输出和自身的输入文本作为输入,逐步生成输出序列。编码器和解码器由多个层堆叠而成,每一层都包含多个注意力块,通过自注意力机制来捕捉输入序列中单词之间的关系,并将这些信息融合生成新的表示。通过多层和多头注意力机制的变换,编码器和解码器能够学习到语言中的长期依赖关系,自动捕捉文本序列的语法结构和语义信息,其中逐位前馈网络的核心如公式2.6。
(2.6)
由于注意力机制对时序的感知能力较弱,Transformer引入了位置编码(Position Encoding)来增强输入数据的位置特征。位置编码是一种在序列中编码位置信息的方法,用于帮助模型理解语句的语义。Transformer使用正弦和余弦函数对位置进行编码,一般形式如公式2.7所示。将编码作为额外的特征输入到模型中,以提供额外的位置信息。
(2.7)
在训练Transformer模型时,通常需要提供一对输入和输出序列作为训练数据。例如,在股价预测任务中,输入序列是过去一段时间的股价,输出序列是未来一段时间的股价预测。编码器的输入为过往股价,解码器的输入为预测股价,并且解码器的输出也是预测股价。因此,训练数据集是一对对应的数据,而不是单一类别的数据。
但是,在常见的长序列数据场景中,例如未来一天银行每个小时的交易量、未来一周电力系统每天的用电量、未来一个月云服务器每天的访问量等,随着预测序列长度的增加,Transformer预测难度会越来越高,准确率也会大幅下降。尤其是预测波动性较高的金融序列表现依旧不够理想。
第3章 Informer方案
第一章简介了量化交易及其相关技术发展,上一章引入了必要的前置理论知识与技术。而在本章将会深入基于Informer的股票价格预测方案,从架构出发,基于方案的流程对每一个步骤的原理与技术进行详解,包括但不限于数据获取与处理、模型构建解析、交易策略分析等。
3.1 架构
本论文使用的是基于Informer的股票价格预测方案,根据实际情况从图2.1的股票预测抽象模型架构转化为了Informer方案架构,如图3.1所示。总的来说,本Informer方案核心流程分为三步:1)数据获取与处理,本方案数据来源于Tushare社区,并提供了汇总后的数据csv文件供直接使用。而在数据处理中本方案主要是做了数据重整与归一化的分块操作,便于后续模型调用。2)模型构建:本方案使用模型为Informer模型,原理在后文详述,同时本方案提供了两种LSTM模型与一种Transformer模型供模型构建与对比实验中使用。3)训练与推理:将分块处理后的数据输入构建好的模型,进行训练与推理,得到对股价预测的结果并输出。
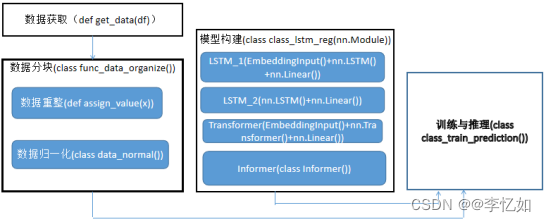
图3.1 本论文Informer方案架构
3.2 数据获取
在1.2节中我们对量化交易中的股价预测任务的数据来源与类别做了综述,而在本论文的Informer方案中我们主要使用纯数字数据,来源为Tushare大数据开放社区(www.tushare.pro),数据获取的核心流程为登录社区,注册token,并使用相关接口API(https://tushare.pro/document/2)调用所需股票数据即可。另外,除了直接在金融社区与平台调用接口,还可以使用相关脚本获取所需股票数据,例如Python的beautifulsoup4。常见股票数据格式如表3.1所示。
本论文以中国A股市场深交所股票代码为“300059”的“东方财富”公司为例作为训练数据,同时提供了数据获取后的文件300059.SZ.csv,包含“东方财富”公司数据自2010年3月19日至2023年4月17日共计3114条相关信息作为原始数据。
表3.1 股票数据常见格式
| 名称 | 类型 | 描述 |
| ts_code | str | 股票代码 |
| trade_date | str | 交易日期 |
| open | float | 开盘价 |
| high | float | 最高价 |
| low | float | 最低价 |
| close | float | 收盘价 |
| pre_close | float | 昨收价(前复权) |
| change | float | 涨跌额 |
| pct_chg | float | 涨跌幅(未复权) |
| vol | float | 成交量(手) |
| amount | float | 成交额(千元) |
3.3 数据分块
在2.1节中解析股票预测模型架构中介绍了几种常见的预处理操作,我们知道了使用不同类型数据预测股票趋势,往往需要进行不同的预处理。在本论文的Informer方案中主要对获取到的数据进行了数据重整与归一化,便于后续模型的训练与推理。
3.3.1 数据重整
数据重整是指将原始数据按照一定规则进行调整和重新组织,以满足特定的分析需求和数据处理目的。对于一般基于深度模型的股价预测任务,一般需要在表3.1的无序不等间隔数据上增加有序等间隔信息(序号、年、月、日等),操作如图3.2所示,由此实现不同信息的维度统一。
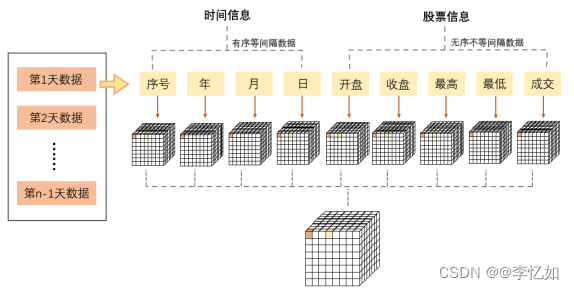
图3.2 基于深度模型的股价预测数据重整一般操作
而在本论文的Informer方案中,实际上提供的300059.SZ.csv文件是同时包含时间信息与股票信息的,故我们进行数据重整只需要修订序号与时间数据即可。具体操作是将第一个“year”对应上序号,将所有的年份信息减去2000,因为我们的训练数据均是2000年之后的。
3.3.2 数据归一化
数据归一化(Normalization)是一种常见的数据预处理技术,用于将不同特征的数值范围映射到统一的范围内。它的目的是消除不同特征之间的尺度差异,使得数据在相同的尺度上进行比较和分析。常见的两种归一化分别是1)最小-最大缩放(Min-Max Scaling):将数据线性地缩放到指定的范围,通常是[0, 1]或[-1, 1]。具体做法是对每个特征进行如公式3.1的变换,其中,X是原始数据,Xmin和Xmax分别是该特征的最小值和最大值。其适用于大部分数据,可以保留原始数据的分布形态,并确保数据都在统一的范围内。2)标准化(Standardization):将数据转换为均值为0、标准差为1的标准正态分布。具体做法是对每个特征进行如公式3.2的变换,其中,X是原始数据,Xmean是该特征的平均值,Xstd是该特征的标准差。其适用于数据分布符合正态分布假设的情况,可以使得数据的平均值为0,方差为1。标准化保留了原始数据的相对关系,但不会将数据限定在特定范围内。
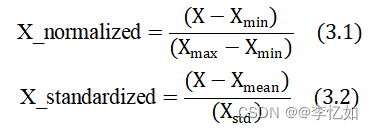
在本论文的Informer方案中,对于重整后的数据也需要进行归一化的操作,选用的是最小-最大缩放,较好地保留了股票数据的分布形态并使并数据均分布在[0, 1]范围内。另外,在后续实验中对模型预测输出进行了如公式3.3的反归一化。
(3.3)
3.4 模型构建
本论文的股票价格预测是基于Informer模型的,在第一章中我们简介了股价预测的技术发展历程,在第二章中也解析了一些核心的前置理论与模型,在Informer前,效果最优的方案主要是基于Transformer模型,而在2.5节中也提到,Transformer是一种基于自注意力机制的深度学习模型,是编码器-解码器的一个应用实例,但预测效果仍有局限,故本节将解析更优的Informer模型技术方案。
Tips:关于Informer模型构建细节的解析,包括但不限于输入端Positional Encoding、输入端Token Embedding均在3.4.1节综述,未分别单开小节叙述。而注意力机制在2.3节已详述,本部分不赘述。
3.4.1 Informer模型
Informer是一种基于Transformer模型改进的长时间序列预测(Long Sequence Time-Series Forecasting,LSTF)模型,专门用于处理具有长期依赖关系和不规则间隔的时间序列数据,即具有提取长距离依赖耦合的能力。架构如图3.3所示。与Transformer一样,Informer也是典型的编码器解码器模型结构,通过使用自注意力机制和卷积层来捕捉时间序列数据中的时序特征和上下文信息。
2.4节中提到,在以往的编码器解码器模型中,编码器的作用是将原始输入信号转换成中间格式,而解码器则将中间格式转换成目标信号,而Informer的提出则是为了优化这种形式。在Informer中,编码器的输入为长时间序列,通过概率自注意力机制(ProbSparse Self-attention)和蒸馏操作生成编码特征,特征自注意力机制如公式3.4所示,其中Q为概率查询特征。解码器接收另一部分长时间序列输入,使用概率自注意力机制提取解码特征,而后使用自注意力机制根据编码特征和解码特征来生成目标序列。

图3.3 Informer架构[21]
(3.4)
Informer模型是改进于Transformer的,更适用于长时间序列预测,根据2.5节对Transformer的解析与论文中对Informer的解析,Informer的主要优化策略总结于表3.2。
表3.2 Informer基于Transformer的主要优化策略
| 1、多尺度时间注意力: Informer引入了多尺度时间注意力机制,使模型能够在不同时间尺度上对时间序列进行建模。传统的Transformer模型只使用固定尺度的自注意力机制,而Informer通过使用不同的时间尺度,可以捕捉到不同尺度的时间依赖关系,提高对时间序列中不同尺度模式的建模能力。 |
| 2、卷积层: 为了增强模型对局部特征的感知能力,Informer模型引入了卷积层。卷积层能够有效地捕捉时间序列数据中的局部模式和趋势,使模型能够更好地理解和建模时间序列中的局部特征。 |
| 3、Masking机制: 由于时间序列数据具有不规则的时间间隔,Informer模型使用了掩码机制,如三角形因果掩码和概率掩码,以便在训练和推理过程中对未来信息进行屏蔽。这样可以避免模型在预测未来时间步时使用未知的未来信息,从而提高预测准确性。 |
| 4、数据嵌入和位置编码: Informer模型在输入端使用了数据嵌入(Token Embedding)和位置编码(Positional Encoding)。数据嵌入将时间序列数据转换为嵌入向量表示,而位置编码则提供了每个时间步的位置信息。这样可以使时间序列数据适应Transformer模型的输入格式,并捕捉时间序列数据的时序特征。 |
| 5、预测输出: Informer模型使用线性投影层将解码器的输出映射到预测输出空间。这样可以将模型的输出转换为时间序列的预测结果,便于与实际值进行比较和评估。 |
综上,由于Informer在传统Transformer模型上了引入多尺度时间注意力&概率自注意力机制、掩码机制、数据嵌入和位置编码等优化策略,使Informer能够更好地捕捉时间序列数据中的时序特征和上下文信息,在股价预测及其各种应用场景中都有着更优秀的表现,比如Gong M等人[32]基于Informer进行了区域供热系统的负荷预测,Yang Z等人[33]使用Informer完成了基于信息员的电机轴承振动的时间序列预测。而回归到本论文研究的股价预测领域,同样有许多基于Informer的研究实践工作被提出。如Lu Y等人[34]将Informer与常用的LSTM、Transformer和BERT网络在1分钟和5分钟的频率上对四个不同的股票/市场指数进行比较。预测结果由三个评价标准来衡量:MAE、RMSE和MAPE。在每个数据集上,Informer在所有网络中都获得了最好的性能。而Liu H等人[35]则是在股价预测任务中基于Informer提出了一种名为PSO-Informer的股票价格长期序列预测方法,经过基于上证50股指和沪深300股指的5分钟K线数据的实验研究,验证了PSO-Informer的性能优越性。
3.4.2 交易策略
在量化交易中,交易策略是指根据预测的股价走势和其他相关因素制定的用于买入和卖出股票的规则与时机等策略。常见的交易策略如表3.3所示。
表3.3 常见量化交易策略
| 交易策略 | 简介 |
| 高频交易策略 | 利用短期价格波动进行高频买卖,通过捕捉股价微小变动来获取买卖价差收益。 |
| 长期投资策略 | 基于基本面分析,选择那些具有长期发展潜力的公司,通过持有股票并等待其股价稳定增长后出售来获取收益。 |
| 组合投资策略 | 权衡不同股票特征、风险等因素,在整个股票市场内构建投资组合,通过分散投资风险来获得超额收益。 |
| 事件驱动策略 | 基于公司公告、财务数据发布、行业新闻等事件来进行相应的买入或卖出操作。 |
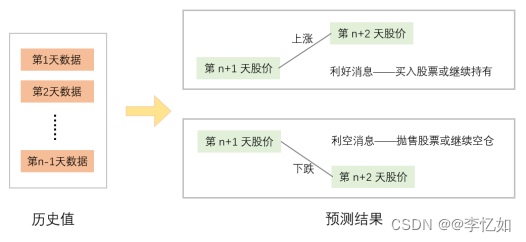
图3.4 Informer方案交易策略
在本论文的Informer方案中,量化交易策略如上图3.4所示,可详细表述为:通过过去time_step(本方案以60为例)天内的股价数据,对股票连续两日的价格做出预测,并根据股票的涨跌趋势选择购入/继续持有或者卖出/继续等待。即当第n天时(收盘前),对第n+1天和第n+2天的股票收盘价做出预测,若发现第n+2天的价格高于第n+1天,则说明下一交易日(第n+1天)股价会涨;进一步判断目前的股票持有情况,若目前未持有股票,则可使用第n天收盘价购入股票,若目前已持有股票,则继续持有即可。同理,若发现第n+2天的价格低于第n+1天,则说明下一交易日(第n+1天)股价会跌;进一步判断目前的持有情况,若目前未持有股票,则继续保持空仓不购入股票,若目前已持有股票,则使用第n天收盘价卖出股票。由此,可以实现股票涨价时手中持有股票持续增值,股价下跌时立即反应及时止损,从而实现高收入。
为保证操作一致性,避免由于买卖股票数量差距导致的总盈亏差异,每次买卖都执行至当前可执行的最大操作以充分展现策略效果。此外,必须在当日股票收盘前完成对未来两日股票收盘价的预测,否则将无法完全覆盖第n+1天的股票价格变动数值。因为股票市场上采取的是逐笔连续撮合交易的方式,即只有等到了出现与交易者买卖数量相同、价格相同、意愿相反的对手方时,交易者才能按照心中预期进行股票买卖,这样的结果是较长时间的等待或者不得不选择折溢价买卖。为保证可以按照确定价格买卖一次性买卖全部股票,利用收盘前最后的集合竞价时期是最好的选择。
3.5 训练与推理
根据图3.1可见,本论文的Informer方案在完成数据获取并分块与模型构建的流程后需要进行训练与推理,返回预测结果并利用3.4.2节介绍的交易策略进行买卖操作的指导。本方案的训练与推理架构如图3.5所示。
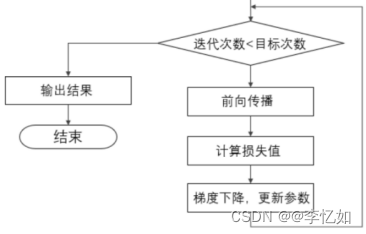
图3.5 Informer方案训练与推理架构
3.5.1 训练
对于深度模型,训练(train)一般是指通过使用训练数据来调整模型的参数,使其能够学习输入和输出之间关系的过程。在训练过程中,模型会反复进行前向传播和反向传播来计算预测值与实际值之间的误差,并根据误差来更新模型的参数。训练的目标是使模型能够在训练数据上达到较低的误差(损失函数值),并具有较好的泛化能力,即在未见过的数据上表现良好。
而在训练过程中,不同(超)参数组合、不同模型、不同损失函数、不同优化器的选择都会使训练效果存在差异。对于本论文的Informer方案,核心超参数如表3.4所示。选用的损失函数为均方误差(MSE)损失,如公式3.5所示。而优化器选择为Adam优化器,其对梯度的一阶矩估计(梯度的均值)和二阶矩估计(梯度的未中心化的方差)进行综合考虑,计算出更新步长。
表3.4 Informer方案核心超参数选择
| 超参数 | 简介 | 取值 |
| hidden_size | 隐藏层神经元数量 | 50 |
| num_layers | 模型层数 | 2 |
| epoch | 单次训练迭代次数 | 50 |
| lr | 学习率 | 0.0002 |
| batch_size | 批处理大小 | 20 |
| time_step | 时间步长 | 60 |
(3.5)
结合图3.5的架构,本论文的Informer方案训练核心流程即分为三步。1)为有效利用计算资源,将数据Batch化并输入构建好的模型,2)判断是否停止训练(迭代次数 < 50?),3)若迭代次数 < 50,进行前向传播得到预测值并计算MSE,再利用Adam优化器进行梯度下降与参数更新。反之,停止训练并保存模型(参数)。
3.5.2 推理
在深度学习中,推理(inference)指的是使用已经训练好的模型对新的输入数据进行预测或分类的过程。在推理过程中一般是输入数据经过前向传播,从输入层经过模型的各个层级,最终得到模型的输出结果。通常不涉及梯度计算和参数更新,因此相对训练,推理的计算量较小,速度较快。
在本论文的Informer方案的推理也是同理,即对Batch=1的股价数据进行推理。核心流程即对预测输入进行预处理,将其作为解码器输入与预测输入的历史信息拼接,然后将其传递给训练好的Informer模型,最终得到股价的预测结果,并基于3.4.2节中的交易策略给出输出结果。
第4章 讨论
开篇两章简介了量化交易的背景与技术部分核心前置知识,上一章从数据、Informer模型、训练与推理三部分解析了本论文主要研究的基于Informer的股票价格预测方案。而实际上,基础的方案在预测正确率、训练与推理速度、模型泛化性与应用场景等方面存在局限,故本章将从不同角度讨论第三章Informer方案,并提出一些优化思路供后续研究与实践参考。
4.1 数据部分优化讨论
数据对于深度模型起着至关重要的作用。高质量、多样化和充分表示目标任务的数据可以帮助深度模型更好地学习和推断,从而提高模型的预测能力和泛化能力。因此,在深度学习项目中,数据的准备、选择和处理是至关重要的步骤。
根据图3.1的Informer方案架构图与3.2节和3.3节对于方案内数据部分的叙述,本论文原方案在数据部分主要进行了数据获取与数据分块,是对有局限的数据进行了相对比较简单的处理方式,在数据丰富度与处理方式上都可以进行其他尝试。
4.1.1 数据获取优化
本论文的原Informer方案的数据获取部分使用纯数字数据,即以“东方财富”公司数据自2010年3月19日至2023年4月17日共计3114条相关信息作为原始数据。对于数据部分常见优化为数据增强,即通过对原始数据进行变换或扩充,获取新的训练样本。根据1.2节的数据简介我们知道股价预测任务的数据除了纯数字数据还有文字类信息,故在数据获取部分有如下三个主要优化思路:1)获取“东方财富”公司更大时间范围的数据,更多数据的不同特征,增加数据量。2)尝试引入文字类数据,如议情信息与金融时政等,丰富数据类型,同时引入基本面分析。3)使用随机剪切、平移、旋转或添加噪声等数据增强方式,以增加数据多样性和复杂性。
4.1.2 数据分块优化
本论文的原Informer方案的数据分块部分直接对获取的数据进行修订序号与时间数据+最小-最大缩放,有比较多值得讨论的点。主要可以分为两部分:1)特征工程与其他归一化尝试,2)数据清洗&优秀降噪算法的引入,简介如下。
原方案的数据分块第一步是数据重整,将第一个“year”对应上序号,并将所有的年份信息减去2000。实际上还可以使用特征工程技术添加或选择其他与股价预测更相关的核心特征,包括技术指标(如移动平均线、相对强弱指数等)或基本面数据(如财务指标、市场指标等)。通过增加更多的特征,模型可以获得更丰富的输入信息,提高预测性能。而在重整后的归一化部分,可以尝试比较更多归一化方法,如Z-score标准化或均值归一化等,并通过消融实验选择更优的归一化方法。
另外,原方案中数据分块只包含了直接对数据进行的操作,属于预处理的基本操作。而实际上还可以引入数据清洗&降噪等处理,进一步提高数据质量。因为在真实应用场景中,获取到的数据未必是直接可用的,尤其是股票数据这种由于高频交易、新闻舆论、政策变动等因素呈现高度波动且带有噪音的非线性数据,不进行降噪将对预测效果产生很大影响。而在量化交易领域,实际上已经有很多经过实践检验的降噪算法了,比如滑动平均算法(MA)、指数滑动平均算法(EMA)、经验模态分解(EMD)和改进的复杂经验模态分解(ICEEMD)等。以EMA为例,其主要思想是对历史数据进行加权平均,其中前期的数据权重越小,近期的数据权重越大。如公式4.1所示,其中,α是权重系数,系数越大,表示最近的数据对平均值的影响越大,而历史数据对平均值的影响越小,α∈(0,1),且一般令α = 0.3。
(4.1)
综上所述,经过4.1.1与4.1.2的讨论,数据部分优化后的架构如图4.1所示。
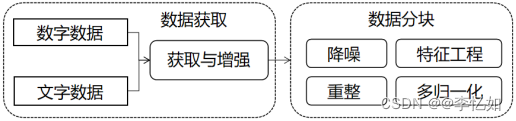
图4.1 Informer方案数据部分优化后架构
4.2 模型部分优化讨论
量化交易是利用数学统计方法和计算机技术来进行投资交易决策的一类方法,深度模型是其中的核心,模型效果与股价预测的准确率与交易效果直接相关,即直接影响投资回报率。故模型的构建、训练、推理是基于深度模型的股价预测任务中非常重要的一环,即如何构建出一个高效且高速的模型是非常值得商榷的。
根据图3.1的Informer方案架构图与3.4节和3.5节对于方案内模型部分的叙述,本论文原方案在模型部分主要进行了模型构建、训练和推理,Informer架构、本方案相关参数与组件选择在前文有详述。但实际上原方案在模型部分仍有许多可以优化的部分,在参数组合与模型组件搭配、网络结构设计、交易策略选择等维度上都可以进行其他尝试。
4.2.1 参数与模型组件优化
对于深度模型,(超)参数是深度模型中可学习的变量,用于表示模型的权重和偏置,而模型组件则是构成模型的各个部分或层,负责处理数据和进行计算。参数与模型组件共同作用,通过不断调整参数来优化模型的性能,以实现对输入数据的准确预测或分类。
而实际上,不同参数组合与不同模型组件的搭配都会使同一个方案最终呈现出截然不同的效果,故选择合适且优秀的搭配方案是至关重要的。根据3.5.1的叙述,原Informer方案核心的参数组合如表3.5,一些其他参数(属性)设置如表4.1所示。而原方案中模型组件主要是Informer模型+MSE损失函数+Adam优化器。
表4.1 原Informer方案其他参数选择
| 超参数 | 简介 | 取值 |
| input_size | 输入数据的特征维度 | 9 |
| output_size | 输出数据的特征维度 | 3 |
| total_days_offset | 数据集中的时间偏移量 | 20 |
| pred_days | 预测天数 | 2 |
| rotation_num | 数据旋转的次数 | 0 |
为了探究更优的参数组合并选择合适的模型组件,一般需要大量的消融实验。对于参数组合而言,可单独改变某个参数的取值探究其对模型的贡献度并根据预测效果优化取值。同时,可直接进行参数组合改变的效果对比实验,因为参数优化对于模型效果的优化一般是非线性的,即并非所有单参数最优值组合就是最优参数组合。另外,除了上述基于经验与消融实验的调参,经过深度学习在各种任务上的多年发展,有一些自动化参数优化方法与工具也成为了主流,如Optuna、Hyperopt等,它们结合了各种方法的优点,并提供了更高级的搜索和优化算法,能更快找到最优的参数组合。
同理,对于模型组件的搭配也可以对同一组件的不同选择进行消融实验。以损失函数与优化器的选择为例,本实验使用的MSE损失函数是比较经典的损失函数,可实际上在股价预测任务中数据通常是非线性和非平稳的,MSE并不能很好地捕捉价格趋势,同时MSE本身对数据异常值非常敏感且对预测误差的敏感性不平衡,故MSE未必是本任务中最优选择。常见的一些损失函数样例总结于表4.2所示。而对于优化器的选择,Adam虽在深度学习任务中被广泛应用,但也存在对学习率敏感、参数更新速度不一致、内存占用大等问题。对此,可以尝试直接对Adam优化器的问题进行优化,如Reddi S J等人[36]等人的改进策略聚焦于两个方面:1)解耦权重衰减,2)修正指数移动均值,并以此提出了AMSGrad。另外,也可直接选择其他的优化器进行消融实验,确定更优搭配。如传统的SGD、RMSprop等,或更新的Ranger、Lookahead等。

而在最优参数组合与模型组件搭配验证实验中,并非只使用模型效果这个单一指标来度量,可以引入多维评估指标体系,样例及简介如表4.3所示。
表4.3 最优参数组合与模型组件搭配验证实验多维评价体系样例及简介
| 1、模型的复杂度和容量考量: 参数与模型组件的选择应该适合模型的复杂度和容量。过于简单的模型可能无法捕捉到数据中的复杂关系,而过于复杂的模型可能导致过拟合。 |
| 2、交叉验证的使用: 评估参数与模型组件选择时,使用交叉验证方法来减小评估结果方差,并更好地估计模型性能。 |
| 3、目标指标选择: 根据具体任务和问题的要求,选择适当的目标指标来评估方案的性能。常见的目标指标包括准确率、精确度、召回率、F1值等。 |
| 4、模型的稳定性评估: 选择最优参数与模型组件时,不仅要考虑性能的好坏,还要考虑模型的稳定性。即使某个组合在某个评估指标上表现较好,但如果在其他数据集或评估指标上表现不稳定,也不是最优的选择。 |
4.2.2 训练策略优化
深度模型的训练策略指的是在训练过程中采用的一系列策略和技巧,以提高模型的性能和泛化能力。4.2.1节中讨论了不同参数组合与模型组件搭配对于模型效果的影响,而实际上最优组合并非一成不变的,在原方案中,训练策略的核心即使用同样的设置不断迭代训练(单次训练epoch=50),而实际上不同训练轮次最优组合方案可以有差异,故可以引入不同的训练策略去优化模型效果。
原方案中每次训练结束都会进行模型的保存,实际上根据这个特点我们可以引入“预训练-微调”策略,属于迁移学习的一种,即针对已有模型进行参数或模型组件的调整,方法类似4.2.1的叙述,以此在每一次训练中获得最优模型。通过迁移学习,可以利用已有模型的知识来加速目标任务的训练,并提高模型的泛化能力。同时,还有一些其他的训练策略可以尝试,比如集束搜索、半监督学习等。另外,在实际应用场景中,可以根据具体任务和模型的特点进行选择和组合,以获得更好的训练效果和模型性能。
而在股价预测任务中,训练策略还包括很重要的一环,即交易策略,也存在许多值得讨论的部分。根据3.4.2的叙述,本论文原Informer方案中的交易策略为通过过去60天内的股价数据,对股票连续两日的价格做出预测,并根据股票的涨跌趋势选择购入/继续持有或者卖出/继续等待。有如下几个可尝试优化的点:1)数据选择:股价预测中,时间窗口(time_step)大小的选择,需要权衡过去数据的多少与模型的复杂性。较长的时间窗口可以提供更多信息,但可能会引入更多噪音和延迟效应。可以尝试不同的时间窗口大小,并评估其对交易策略的影响。2)交易信号与执行:市场中存在噪音和波动,单凭两天的价格变动可能无法准确预测趋势。您可以考虑引入更多特征和指标,如技术指标、市场情绪指标等,来增强交易信号的可靠性。3)其他交易策略的引入:除了简单的对单股票进行跟踪与价格趋势预测,还可以引入更多高阶交易策略或引入组合策略,在表3.3有叙述。
4.2.3 模型结构优化
除了前两节提到的各种参数、组件与策略的选择,实际任务中影响相关的重要一环还有模型本身,原方案使用基础Informer模型,架构如图3.3所示,经过1年多的技术发展,随着对Informer的研究深入,实际上其模型仍存在一定局限,主要包括以下几个方面:1)训练复杂度较高:需要大量的训练数据和计算资源。对于规模较大的时间序列数据,成本可能较高。2)长期依赖建模:Informer模型对于数据的质量和特征工程的要求较高。如果时间序列数据存在缺失、异常值或噪音,或者需要进行复杂的特征工程处理,这些问题可能会影响Informer模型的性能。3)参数调整和模型解释性:Informer模型有多个超参数需要调整,包括网络结构、学习率、正则化等。合理的参数选择对模型性能至关重要,但参数调整可能需要耗费大量时间和计算资源。此外,Informer模型的内部结构较复杂,可能缺乏直观的解释性,使得理解模型的工作变得困难。
在3.4.1中提到目前已有许多基于Informer的股价预测应用[34][35],并以此提出了股价预测领域的优化算法PSO-Informer。除此之外,也有许多基于Informer模型本身局限进行优化的工作被提出,如Liu F等人[37]针对考虑到负荷曲线的周期性特性对Informer模型进行了优化,而Tian Y等人[38]基于Informer的自适应损失函数,结合了改进的变模分解(IVMD)和模糊熵(FE)提出了IVMD-FE-Ad-Informer。由此可见,针对Informer模型本身的局限或应用场景的特点都可以进行特定模型结构的优化,以此提升模型的效果。
4.2.4 速度优化
前三节的优化讨论主要是针对模型的预测效果、稳定性、泛化性能等因素,而模型的速度在许多应用中也具有重要的意义,影响着模型的实用性和适应性,是方案性能评估的重要指标。尤其是在量化交易领域模型速度至关重要,高速的模型能够实时生成交易信号、快速执行交易、适应高频交易环境,并提供高效的数据处理能力,从而增强量化交易的竞争力和执行效果。然而本论文Informer方案除了一些对数据的基本处理,并没有在速度优化上做太多设计,故仍存在性能上的局限。除了前几节中叙述的结构与策略优化,常见的深度模型速度优化一般聚焦在几个方面:1)模型压缩与加速算法引入,2)大数据框架或平台引入3)计算资源的丰富。
模型的压缩与加速是一种常见面的优化技术,旨在减少深度学习模型的存储空间、计算复杂度和推理时间,以提高模型的效率和速度。对于模型压缩,核心是对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,常见压缩方法简介如表4.4所示,一般流程如图4.2所示。
表4.4 模型压缩方法简介汇总
| 模型压缩方法 | 方法细节 |
| 紧凑模型设计 | 设计了特殊的结构卷积滤波器来降低存储和计算复杂度,只能从零开始训练 |
| 剪枝 | 针对模型参数的冗余性,试图去除冗余和不重要的项,支持从零训练和预训练 |
| 量化 | 以低于浮点精度的位宽执行计算和存储张量的技术。允许更紧凑的模型表示和在许多硬件平台上使用高性能矢量化操作 |
| 低秩近似/分解 | 使用矩阵/张量分解来估计深度学习模型的信息参数,支持从零训练和预训练 |
| 知识蒸馏 | 通过学习一个蒸馏模型,训练更紧凑的神经网络来重现更大的网络输出,只能从零开始训练 |
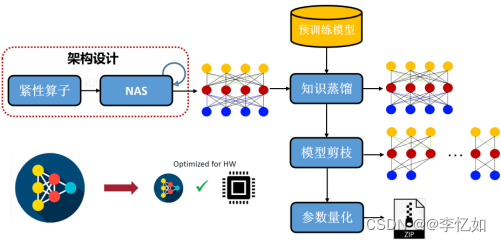
图4.2 模型压缩优化基本/主要流程
而模型加速/系统优化是指在特定系统平台上,通过Runtime层面性能优化,以提升AI模型的计算效率,与压缩方法有一定交集部分。一般来说,常用的加速方案可分为以下四类:
1、Op-level的算子优化:FFT Conv2d (7x7, 9x9), Winograd Conv2d (3x3, 5x5) 等;
2、Layer-level的快速算法:Sparse-block net等;
3、Graph-level的图优化:BN fold、Constant fold、Op fusion和计算图等价变换等;
4、优化工具与库(手工库、自动编译):TensorRT (Nvidia), MNN (Alibaba), TVM (Tensor Virtual Machine), Tensor Comprehension (Facebook) 和OpenVINO (Intel) 等;
综上,模型压缩与加速的一般流程架构如图4.3所示。
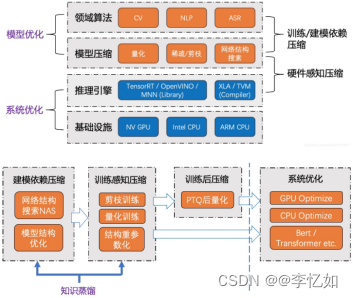
图4.3 模型压缩与加速的一般流程架构(https://blog.csdn.net/nature553863/article/details/81083955)
对于基于深度模型实际应用的速度优化第二类方法即大数据框架或平台的引入。由于在真实场景中,模型应用需要应对数据爆发式增长、数据多样性、高速数据处理、水平扩展性以及容错性和可靠性等挑战,而相关大数据框架与平台应运而生,满足了相关需求。对于大数据框架,在本论文的原Informer方案中可基于表4.5汇总的常见大数据框架进行部署与推理,有以下几个主要优点:1)数据处理规模:股票市场的交易数据通常是庞大的使用大数据框架可以有效地处理和分析这些大规模的数据集,提高处理速度和效率。2)并行计算能力:大数据框架具备强大的并行计算能力,可以将任务分解为多个子任务并并行处理,加快计算速度。对于Informer模型的训练和推理过程,可以利用大数据框架的分布式计算能力,加快模型训练和预测的速度。3)弹性和可扩展性:大数据框架通常具备良好的可扩展性,可以根据需求进行横向扩展,以应对不断增长的数据量和计算需求。股票市场的数据量和复杂性可能会随着时间的推移增加,使用大数据框架可以灵活地扩展计算资源,以适应不断变化的需求。4)数据存储和管理:大数据框架通常与分布式文件系统集成,例如Hadoop的HDFS,可以高效地存储和管理大规模数据。对于股票市场的历史数据和实时数据流,使用大数据框架可以方便地将数据存储在可靠的分布式存储系统中,并进行高效的数据访问和检索。
表4.5 常见大数据框架汇总简介
| 大数据框架 | 简介 |
| Hadoop | 包括分布式文件系统(HDFS)和MapReduce计算模型。HDFS将数据分散存储在多个节点上,通过冗余副本实现数据的可靠性和容错性。MapReduce模型将计算任务分解为多个子任务,并在集群中的多个节点上并行执行,然后将结果进行汇总。Hadoop适用于处理大规模数据集的存储和计算任务。 |
| Spark | 采用了内存计算的方式,在内存中对数据进行高性能处理。使用弹性分布式数据集(RDD)作为基本数据抽象,支持数据的并行处理和缓存,提供了丰富的API(如Spark SQL、Spark Streaming、MLlib和GraphX)来处理批处理、流处理、机器学习和图形处理等不同类型的数据处理任务。 |
| Flink | 基于事件时间进行流处理,并提供了窗口操作和状态管理功能,使得处理实时数据流更加灵活和精确。Flink还支持批处理任务,能够无缝地将流处理和批处理任务结合起来进行统一的数据处理。 |
而除了基于大数据框架的本地部署,还可以将我们的项目部署到云端,利用云计算资源实现模型训练与推理的速度优化。另外,可以使用一些大数据或机器学习平台实现加速优化,大数据平台如HPE Vertica、Cloudera等,机器学习平台如AWS的SageMaker、Alibaba的PAI、Baidu的PaddlePaddle等。
对于基于深度模型实际应用的速度优化第三类方法即计算资源的丰富,如使用图形处理单元(GPU)或领域特定集成电路(ASIC)等加速器,可以显著提高模型的计算速度。并通过硬件和软件的协同优化,进一步提高深度模型的速度。
4.3 方案优化综述
经过4.1节与4.2节分别从数据部分与模型部分对于本论文中原Informer方案进行了不同角度的讨论,并提出了大量可能的方案优化思路,最终优化后方案架构如图4.4所示。主要优化部分综述如下:1)在数据获取部分,丰富了数据量与数据类型。2)数据分块部分,引入了不同的分块方法,并对数据进行了降噪处理。3)在模型构建部分,将Informer模型替换成更适用于股价预测的PSO-Informer模型,并使用消融实验与自动化工具选取了最优的参数组合与模型组件搭配。另外,引入了“预训练-微调”策略,为每次再训练提供了最优参数/组件的选择。4)在训练与推理部分,使用不同的模型压缩与加速技术实现部分速度优化,并在训练&策略中进行了其他高阶方案的组合引入,提高了训练精度、预测准确度与模型的泛化性能。5)在预测与评估部分,引入了基于准确率、速度、复杂、容量等因素的多维评价体系,便于方案结果的准确评估与后续的迭代与再优化。6)在框架&平台服务部分,引入了大数据框架,并使用了许多机器学习平台的云服务与云计算资源,提高了方案内模型的构建、训练与推理速度,使其更好地在真实的数据场景下应用。
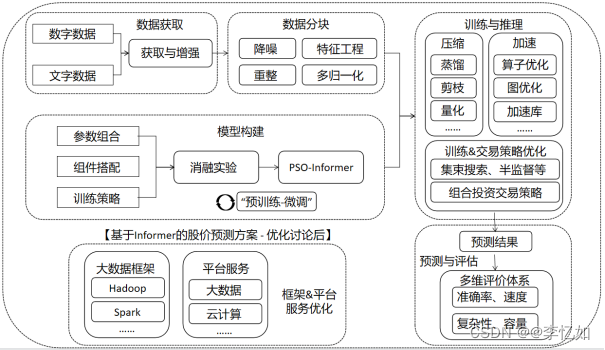
图4.4 讨论优化后基于Informer的股价预测方案架构
第5章 实验与结果
开篇两章简介了量化交易的背景与技术部分核心前置知识,第三章详解了本论文提出的Informer方案的架构与流程原理,上一章针对原方案的不足在不同维度进行了架构优化的讨论。故本章将会首先验证原Informer方案的可行性与相对LSTM&Transformer方案的优越性。并基于图4.4的优化架构与原方案代码进行部分优化,并通过消融实验与结果展示验证优化的效果。
5.1 原Informer方案实践
在论文前四章从量化交易发展现状、模型原理、方案设计等多个角度均证明了基于Informer模型的股价预测是优秀且可行的方案,故本节首先补充实验端的验证。
5.1.1 可行性验证
首先根据图3.1的论文原Informer架构设计编写代码(本论文已提供,可以直接使用),并将准备好的数据输入,等待模型的构建、训练与推理,模型训练的测试样例如图5.1所示,相关数据绘图结果如图5.2所示。
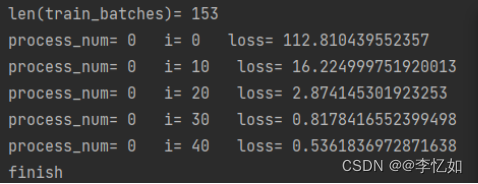
图5.1 原Informer方案可行性验证样例
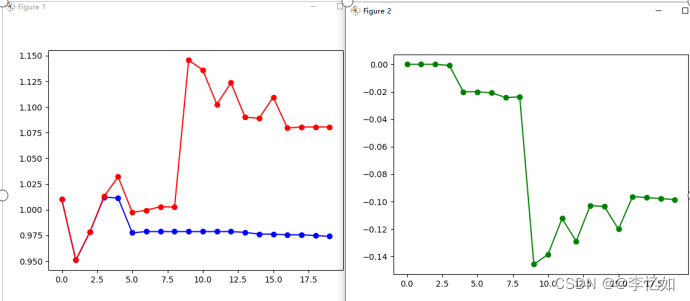
图5.2 原Informer方案绘图结果样例
根据图5.1与图5.2可见,论文中原Informer方案可以成功运行并完成股票价格预测的任务,并将相关结果简单可视化,验证了原方案的可行性与设计的合理性。
5.1.2 优越性验证
本论文的原Informer方案代码中同时提供了Transformer方案与LSTM方案(本实验选用带有全局位置时间输入信息的LSTM作为基模型)的股价预测,故本节进行模型选择的消融实验,去探究不同模型对于股价预测效果的影响。具体实验方案为,控制除模型选择外其他变量保持一致,分别使用三种方案训练100轮,且均分别进行20次,取平均的损失函数作为评价指标,数据汇总于表5.1,趋势对比如图5.3所示,为使对比明显,绘图仅选择epoch>30的情况。
表5.1 模型选择消融实验数据汇总
| eopch | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| LSTM | 119.99 | 30.14 | 5.76 | 2.14 | 0.89 | 0.69 | 0.41 | 0.28 | 0.26 | 0.25 |
| Transformer | 108.98 | 15.13 | 1.98 | 0.72 | 0.54 | 0.47 | 0.37 | 0.19 | 0.17 | 0.15 |
| 原Informer | 111.94 | 16.47 | 2.75 | 0.84 | 0.63 | 0.34 | 0.3 | 0.18 | 0.15 | 0.14 |
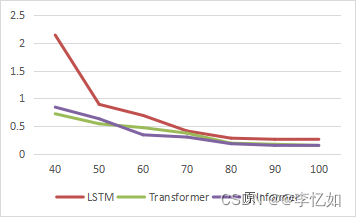
图5.3 不同基模型对损失函数趋势的影响对比
根据表5.1与图5.3可见,在同样的实验设置下,针对本论文提供的数据,三种方案在epoch=80之后均接近收敛(损失函数值相对稳定)。而在本次消融实验中,epoch<=50时,基于Transformer的股价预测效果最好,而epoch>50的情况下,原Informer方案的预测效果最好。故验证了Informer模型在股价预测任务中的优越性,但效果优势与实验情况息息相关。
5.2 Informer优化方案实践
在5.1节中验证了论文中基于Informer的股价预测的可行性与相对优越性,本节将从第四章的优化讨论中选取部分设计一个Informer优化方案,并通过对比实验与结果展示验证优化效果。
5.2.1 Informer优化方案设计
根据第4章的优化讨论得出了一个抽象的优化Informer方案架构如图4.4所示,而本节设计同样起源于抽象架构,具体待实践的优化方案架构如图5.4所示。优化部分主要可以分为以下几个方面:1)在数据获取部分,对于数据进行了数据增强,主要使用了数据的平移缩放旋转于特征变换(对数变换、差分变换等),旨在增加数据量与丰富度,从而提供更多的学习特征。2)在数据分块部分,引入了EMD降噪,减少股价数据非稳态、高波动对后续模型的影响,同时对原重整与归一化操作进行了向量化,增加数据处理效率。3)在模型构建部分,通过参数调整、网络结构优化、批量归一化等操作,优化基本Informer模型为自购建的LW-Informer模型。在参数组合部分,主要进行了batch_size的消融实验,选取了更优取值,同时引入StepLR自动调整学习率,并尝试使用Optuna框架进行其他参数的最佳组合搜索。在模型组件部分,分别将损失函数与优化器替换为了SmoothL1Loss与AMSGrad。且在训练策略上引入了“预训练-微调”策略,每次训练均使用更适宜情况的参数组合。4)在训练与推理部分,针对训练出的模型进行了剪枝与量化,减小了模型的计算复杂度和存储开销,从而提高模型的效率和可部署性。同时引入multiprocessing模块,进行并行计算,提高预测速度。5)在结果部分,同样引入了基于准确率、速度、复杂、容量等因素的多维评价体系,便于方案结果的准确评估与后续的迭代与再优化。6)将实验环境迁移到了云端(计算资源由腾学汇提供),并引入了大数据框架Spark,便于模型训练与推理的加速。

图5.4 Informer优化方案实际架构
5.2.2 消融实验
根据图5.4的架构进行代码的修改与云端的部署,环境测试(hadoop的启动)如图5.5所示,在成功后使用类似5.1.1节的方法进行优化方案的可行性验证,在此不赘述。
图5.5 云环境测试与大数据框架启动
在完成Informer优化方案的实践测试后,正式进入优化效果的验证,即优化前后的效果消融实验,本次实验选取指标为预测准确率与速度。具体实验步骤为,控制除方案选择外其他变量保持一致,分别使用优化前后方案训练100轮,且均分别进行20次,取平均的损失函数作为与归一化后的训练与推理速度作为评价指标,数据汇总于表5.2与表5.3,损失函数变化趋势对比如图5.6所示,为使对比明显,绘图仅选择epoch>=30的情况,速度对比如图5.7所示。
Tips:优化方案的损失函数进行了转换,故可以直接比较两方案的值,并间接反映预测准确度。
表5.2 优化前后方案选择消融实验数据汇总(损失函数值)
| eopch | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| LSTM | 119.99 | 30.14 | 5.76 | 2.14 | 0.89 | 0.69 | 0.41 | 0.28 | 0.26 | 0.25 |
| Transformer | 108.98 | 15.13 | 1.98 | 0.72 | 0.54 | 0.47 | 0.37 | 0.19 | 0.17 | 0.15 |
| 原Informer | 111.94 | 16.47 | 2.75 | 0.84 | 0.63 | 0.34 | 0.3 | 0.18 | 0.15 | 0.14 |
| 优化Informer | 100.22 | 13.22 | 1.65 | 0.64 | 0.31 | 0.19 | 0.14 | 0.12 | 0.1 | 0.09 |
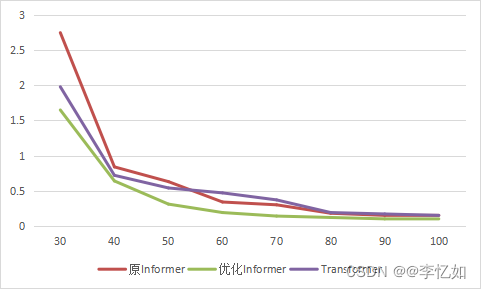
图5.6 方案优化前后对损失函数趋势的影响对比
表5.3 优化前后方案选择消融实验数据汇总(速度)
| 方案 | 训练时长 | 推理时长 |
| 原Informer | 1 | 1 |
| 优化Informer | 0.42 | 0.67 |
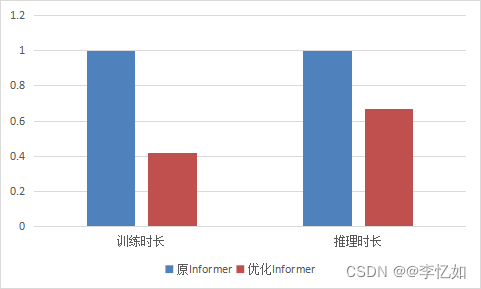
图5.7 方案优化前后对模型速度的影响对比
根据表5.2与图5.6可以看出,优化Informer方案在本实验的数据情况下任何epoch的预测效果(仅以损失函数值评判)均是四个方案中最优的,并不会出现原Informer方案在较小epoch劣于Transformer方案的情况,且较少的迭代次数就达到了较低的相对收敛值。而根据表5.3与图5.6分析,优化后的Informer方案在模型速度上更有优势,分别在训练时长与推理时长中相对原Informer方案降低了58%与33%。综上所述,根据如上的消融实验与结果展示分析,验证了优化Informer方案在股价预测应用中的设计合理性、可行性与相对原Informer方案的优越性,优化成功!
5.2.3 局限性讨论
由于本次论文撰写时间有限,且实验结果具有一定随机性,基于图5.4优化架构的方案与自购建模型LW-Informer虽在测试消融实验中验证了优化效果,但并非本方案最优效果,还在不断完善中。同时笔者仍在探索股价预测中相关参数组合与组件搭配的新范式,故本优化实验仅作为后续基于Informer模型进行股价等金融时间序列预测方案设计的参考,并提供一定的优化实践思路。
参考文献
- 陈健, 宋文达. 量化投资的特点, 策略和发展研究[J]. 时代金融, 2016 (29): 245-247.
- 彭志.量化投资和高频交易:风险、挑战及监管[J].南方金融,2016(10):84-89.
- Fama E F. Efficient capital markets: A review of theory and empirical work[J]. The journal of Finance, 1970, 25(2): 383-417.
- Hyndman R J, Khandakar Y. Automatic time series forecasting: the forecast package for R[J]. Journal of statistical software, 2008, 27: 1-22.
- Gardner Jr E S. Exponential smoothing: The state of the art[J]. Journal of forecasting, 1985, 4(1): 1-28.
- Gardner Jr E S. Exponential smoothing: The state of the art—Part II[J]. International journal of forecasting, 2006, 22(4): 637-666.
- Huang W, Nakamori Y, Wang S Y. Forecasting stock market movement direction with support vector machine[J]. Computers & operations research, 2005, 32(10): 2513-2522.
- Hassan M R, Nath B, Kirley M. A fusion model of HMM, ANN and GA for stock market forecasting[J]. Expert systems with Applications, 2007, 33(1): 171-180.
- Shen W, Guo X, Wu C, et al. Forecasting stock indices using radial basis function neural networks optimized by artificial fish swarm algorithm[J]. Knowledge-Based Systems, 2011, 24(3): 378-385.
- Li X, Li Y, Zhan Y, et al. Optimistic bull or pessimistic bear: Adaptive deep reinforcement learning for stock portfolio allocation[J]. arXiv preprint arXiv:1907.01503, 2019.
- Liu X Y, Xiong Z, Zhong S, et al. Practical deep reinforcement learning approach for stock trading[J]. arXiv preprint arXiv:1811.07522, 2018.
- Selvin S, Vinayakumar R, Gopalakrishnan E A, et al. Stock price prediction using LSTM, RNN and CNN-sliding window model[C]//2017 international conference on advances in computing, communications and informatics (icacci). IEEE, 2017: 1643-1647.
- [15]Chen K, Zhou Y, Dai F. A LSTM-based method for stock returns prediction: A case study of China stock market[C]//2015 IEEE international conference on big data (big data). IEEE, 2015: 2823-2824.
- Nabipour M, Nayyeri P, Jabani H, et al. Predicting stock market trends using machine learning and deep learning algorithms via continuous and binary data; a comparative analysis[J]. IEEE Access, 2020, 8: 150199-150212.
- Li X, Li Y, Zhan Y, et al. Optimistic bull or pessimistic bear: Adaptive deep reinforcement learning for stock portfolio allocation[J]. arXiv preprint arXiv:1907.01503, 2019.
- Lin H, Zhao J, Liang S, et al. Prediction model for stock price trend based on convolution neural network[J]. Journal of Intelligent & Fuzzy Systems, 2020, 39(4): 4999-5008.
- Cao J, Li Z, Li J. Financial time series forecasting model based on CEEMDAN and LSTM[J]. Physica A: Statistical mechanics and its applications, 2019, 519: 127-139.
- Wang J, Tang J, Guo K. Green bond index prediction based on CEEMDAN-LSTM[J]. Frontiers in Energy Research, 2022, 9: 793413.
- Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
- Zhou H, Zhang S, Peng J, et al. Informer: Beyond efficient transformer for long sequence time-series forecasting[C]//Proceedings of the AAAI conference on artificial intelligence. 2021, 35(12): 11106-11115.
- Liu G, Wang X. A numerical-based attention method for stock market prediction with dual information[J]. Ieee Access, 2018, 7: 7357-7367.
- Chen J, Du J, Xue Z, et al. Prediction of Financial Big Data Stock Trends Based on Attention Mechanism[C]//2020 IEEE International Conference on Knowledge Graph (ICKG). IEEE, 2020: 152-156.
- Jiali X. Financial Time Series Prediction Based on Adversarial Network Generated by Attention Mechanism[C]//2021 International Conference on Public Management and Intelligent Society (PMIS). IEEE, 2021: 246-249.
- Lee T W, Teisseyre P, Lee J. Effective Exploitation of Macroeconomic Indicators for Stock Direction Classification Using the Multimodal Fusion Transformer[J]. IEEE Access, 2023, 11: 10275-10287.
- Wang C, Chen Y, Zhang S, et al. Stock market index prediction using deep Transformer model[J]. Expert Systems with Applications, 2022, 208: 118128.
- Peng Z Y, Guo P C. A data organization method for LSTM and transformer when predicting Chinese banking stock prices[J]. Discrete Dynamics in Nature and Society, 2022, 2022: 1-8.
- Zhang S, Zhang H. Prediction of Stock Closing Prices Based on Attention Mechanism[C]//2020 16th Dahe Fortune China Forum and Chinese High-educational Management Annual Academic Conference (DFHMC). IEEE, 2020: 244-248.
- 章宁, 闫劭彬, 范丹. 基于深度学习的收益率预测与投资组合模型[J]. 统计与决策, 2022年, 第23期(总第611期): pp 48-51.
- Lipton Z C, Kale D C, Elkan C, et al. Learning to diagnose with LSTM recurrent neural networks[J]. arXiv preprint arXiv:1511.03677, 2015.
- Li X, Li Y, Liu X Y, et al. Risk management via anomaly circumvent: mnemonic deep learning for midterm stock prediction[J]. arXiv preprint arXiv:1908.01112, 2019.
- Gong M, Zhao Y, Sun J, et al. Load forecasting of district heating system based on Informer[J]. Energy, 2022, 253: 124179.
- Yang Z, Liu L, Li N, et al. Time series forecasting of motor bearing vibration based on informer[J]. Sensors, 2022, 22(15): 5858.
- Lu Y, Zhang H, Guo Q. Stock and market index prediction using Informer network[J]. arXiv preprint arXiv:2305.14382, 2023.
- Liu H, Chen D, Wei W, et al. Long-term stock price forecast based on PSO-informer model[C]//Fifth International Conference on Computer Information Science and Artificial Intelligence (CISAI 2022). SPIE, 2023, 12566: 288-294.
- Reddi S J, Kale S, Kumar S. On the convergence of adam and beyond[J]. arXiv preprint arXiv:1904.09237, 2019.
- Liu F, Dong T, Liu Y. An Improved Informer Model for Short-Term Load Forecasting by Considering Periodic Property of Load Profiles[J]. Frontiers in Energy Research, 2022, 10: 950912.
- Tian Y, Wang D, Zhou G, et al. An Adaptive Hybrid Model for Wind Power Prediction Based on the IVMD-FE-Ad-Informer[J]. Entropy, 2023, 25(4): 647.

