
- 1词嵌入技术解析(一)
- 2unity工程包怎么上传git_Unity编辑器中使用GitHub管理项目
- 3快准稳的文档解析工具,帮助构建性能优越的金融领域知识库问答产品
- 4KNN算法_k nearest neighbor算法又叫knn算法,这个算法是机器学习里面一个比较经典的算法,
- 5自动驾驶的核心技术是什么----一篇文章带你揭开自动驾驶的神秘面纱_将自动驾驶看作是一个时间序列
- 6学习《Python数据分析与挖掘实战》之Python数据分析简介_python实战数据与挖掘
- 7c++文件夹的遍历_c++遍历文件夹
- 8【数据结构】 -- 堆 (堆排序)(TOP-K问题)
- 9基于web校园二手书籍置换系统设计与实现
- 10ThingsBoard 接入摄像头方案_tb平台如何接入摄像头
【YOLOv7/v5系列算法改进NO.46】融合DLinkNet模型中协同双注意力机制CDAM2_协同双注意力模块
赞
踩
前言
作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
一、解决问题
本文尝试引入一种结合道路上下文信息与全阶段特征融合的RCFSNet算法中的协同双注意力模块,能够在遮挡场景中表现出色,尝试解决目标检测中的遮挡问题。
二、基本原理
原文链接

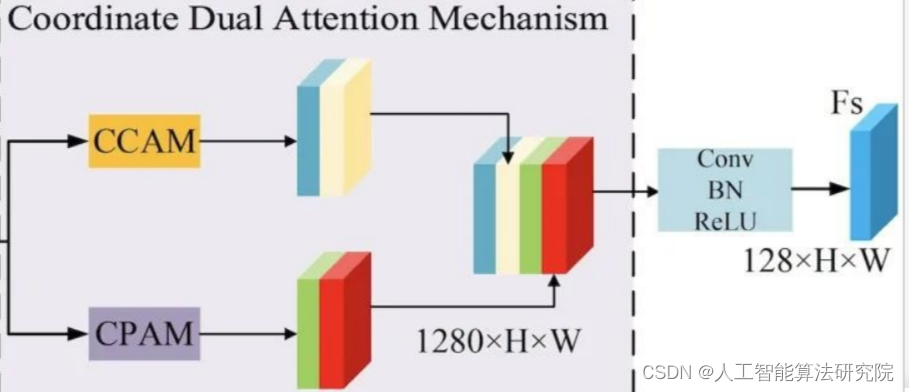
协同双注意力机制由协同通道注意力机制和协同空间注意力机制组成。在协同通道注意力中,融合特征图首先经过池化核大小为(1,W)与(H,1)的池化操作处理,随后采用reshape操作将特征图变形为H×320与W×320的特征图,特征图被输出通道数为1的1D卷积核学习相邻通道的依赖关系,随后采用变形操作将特征图变形为320×1×1的特征图。分别采用sigmoid函数获取特征图结合宽度、高度信息的通道权重,输入特征图结合权重生成两个通道特征加权的特征图。
在协同空间注意力机制中,首先采用通道平均池化和最大池化操作压缩通道特征信息,随后采用拼接与卷积操作融合特征图。分别采用卷积核大小为(1,W)与(H,1)的卷积操作压缩特征图的空间信息,随后采用expand操作恢复特征图尺寸到1×H×W。采用sigmoid函数获取特征图在宽度和高度维度的空间权重,输入特征图结合权重生成两个空间特征加权的特征图。
将协同双注意力机制生成的融合特征图采用拼接操作进行融合,随后采用输出通道数为128的1×1卷据核生成补充的道路特征图,其中128对应编码器特征图E3的通道数。
三、改进办法
部分代码如下:
class CDAM2(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, k_size=9):
super(CDAM2, self).__init__()
self.h = 256
self.w = 256
self.relu1 = nn.ReLU()
self.avg_pool_x = nn.AdaptiveAvgPool2d((self.h, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, self.w))
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = nn.Conv1d(256, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv2 = nn.Conv1d(256, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv11 = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.conv22 = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
self.convout = nn.Conv2d(64 * 5 * 4, 64*5, kernel_size=3, padding=1, bias=False)
self.conv111 = nn.Conv2d(in_channels=64*5*2, out_channels=64*5*2, kernel_size=1, padding=0, stride=1)
self.conv222 = nn.Conv2d(in_channels=64*5*2, out_channels=64*5*2, kernel_size=1, padding=0, stride=1)
# 横卷
self.conv1h = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=(self.h, 1), padding=(0, 0), stride=1)
# 竖卷
self.conv1s = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=(1, self.w), padding=(0, 0), stride=1)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Conv1d):
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
# x: input features with shape [b, c, h, w]
n, c, h, w = x.size()
y1 = self.avg_pool_x(x)
y1 = y1.reshape(n, c, h)
y1 = self.sigmoid(self.conv11(self.relu1(self.conv1(y1.transpose(-1, -2)))).transpose(-1, -2).reshape(n, c, 1, 1))
y2 = self.avg_pool_y(x)
y2 = y2.reshape(n, c, w)
# Two different branches of ECA module
y2 = self.sigmoid(self.conv22(self.relu1(self.conv2(y2.transpose(-1, -2)))).transpose(-1, -2).reshape(n, c, 1, 1))
yac = self.conv111(torch.cat([x * y1.expand_as(x), x * y2.expand_as(x)],dim=1))
avg_mean = torch.mean(x, dim=1, keepdim=True)
avg_max,_ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.cat([avg_max, avg_mean], dim=1)
y3 = self.sigmoid(self.conv1h(avg_out))
y4 = self.sigmoid(self.conv1s(avg_out))
yap = self.conv222(torch.cat([x * y3.expand_as(x), x * y4.expand_as(x)],dim=1))
out = self.convout(torch.cat([yac, yap], dim=1))
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

