
热门标签
热门文章
- 1Windows10 DockerDesktop 深度学习环境镜像构建_unknown flag --gpus
- 2Spring Boot Jpa 的使用(转载)_springboot jpa使用getconnection
- 3ipa文件反编译_iOS 逆向工程-反编译ipa包
- 4【Redis-Series】六、Redis击穿、穿透、雪崩讲解以及解决方案
- 5使用OpenCV工具包成功实现人脸检测与人脸识别,包括传统视觉和深度学习方法(附完整代码,模型下载......)_opencv人脸识别
- 6在Linux系统中执行.sh文件的几种方法
- 7用python写的新年快乐的代码,python节日祝福源代码_python新年快乐代码
- 8LeetCode分类刷题(五):哈希表(Hash Table)_hasht[a[i][j]]++表示什么意思
- 9引入外部jar包内的Class文件,通过反射去拿外部jar包内里面的一个类的内部类报错 ClassNotFoundException_jar打包后 classloader.loadclass classnotfoundexceptio
- 10手把手教你软件著作权申请(全流程)(不花一分冤枉钱)_软著申请流程
当前位置: article > 正文
机器学习的整个流程
作者:Cpp五条 | 2024-02-09 13:36:40
赞
踩
机器学习的整个流程
机器学习的整个流程定义了数据科学团队执行以创建和交付机器学习模型的工作流。此外,机器学习流程还定义了团队如何协作合作,以创建最有用的预测模型。
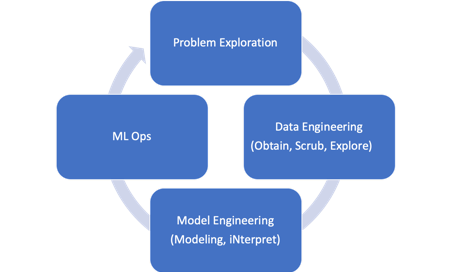
机器学习high level的流程
机器学习流程的关键步骤包括问题探索(Problem Exploration)、数据工程(Data Engineering)、模型工程(Model Engineering)和模型运营 (ML Ops)。
更详细的机器学习流程
这个更详细的流程保留了相同的高层阶段(Problem Exploration、Data Engineering、Model Engineering和ML Ops),但定义了ML流程每个阶段的关键步骤。以下是对每个步骤的讨论。
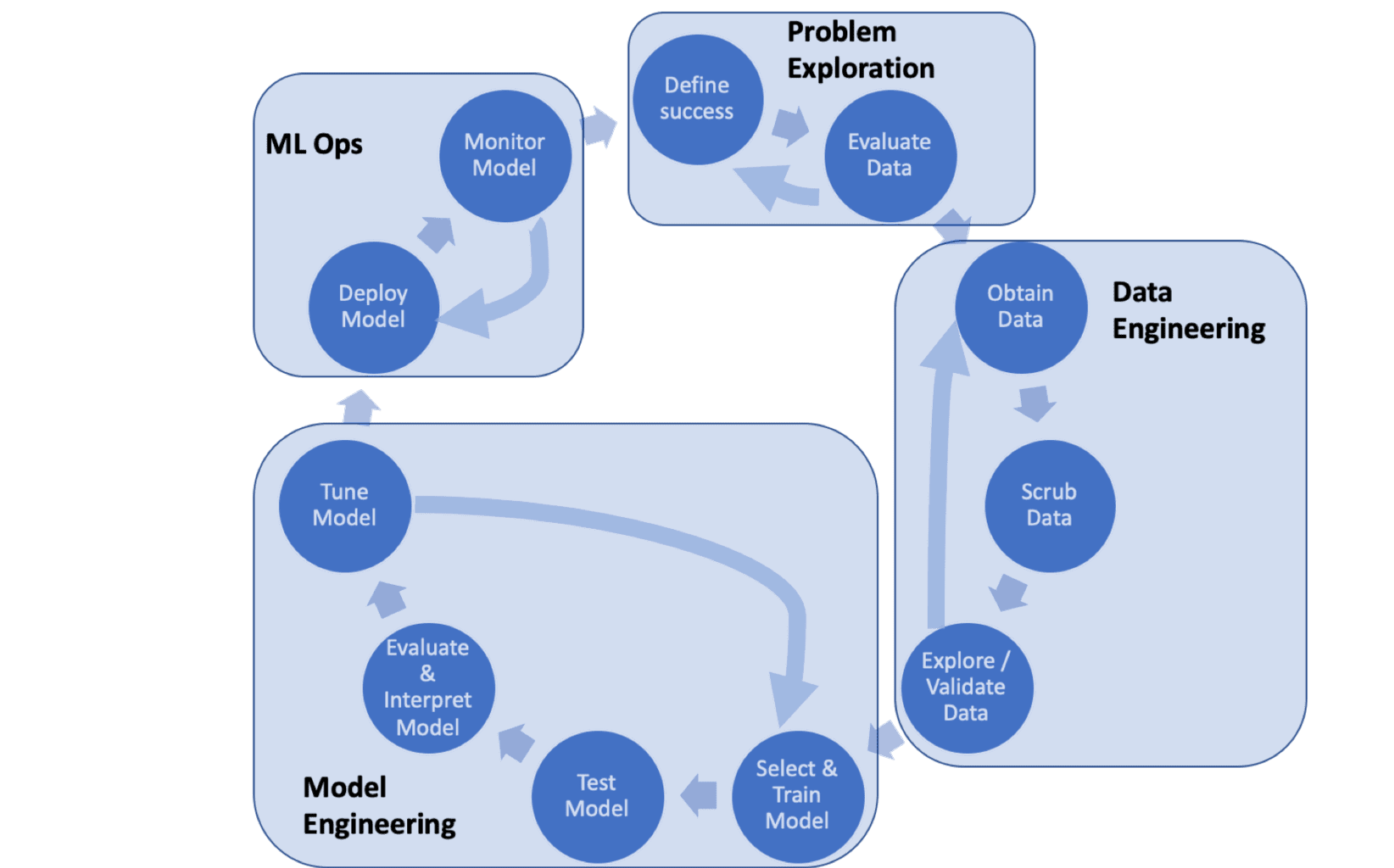
问题探索(Problem Exploration)
首先关注模型将如何使用。在这个过程中,评估期望的模型准确性并探索其他细节,比如误报和漏报哪个更糟。这个阶段还包括了解可能可用的数据。
- 定义成功(Define Success):定义要解决的问题。例如,应该预测什么。这有助于定义将需要的数据。此外,确保清楚如何度量成功。
- 评估数据(Evalute Data):确定相关的数据源。换句话说,评估团队将需要哪些数据,数据是如何收集的,以及数据存储在哪里。
数据工程(Data Engineering)
设计和构建数据管道。这些管道获取、清理和转换数据,使其更容易用于构建预测模型。需要注意的是,这些数据可能来自多个数据源,因此合并数据也是数据工程的关键方面。这通常是在机器学习项目中花费最多时间的地方。
- 获取数据(Obtain Data):组装数据。这包括连接到远程存储的数据和数据库,这些数据可能以不同的格式存在。例如,一些数据可能以CSV格式存在,而其他数据可能通过Web服务以JSON格式提供。
- 清理数据(Scrub Data):重新格式化特定属性并纠正数据中的错误,如缺失值填充。数据集通常缺少值,或者它们可能包含错误类型或范围的值。清理可以包括去重、纠正错误、处理缺失值、归一化以及处理数据类型转换。
- 探索/验证数据(Explore/Validate Data):对数据有一个基本的了解。这种探索性分析包括数据概要分析,以获取关于数据内容和结构的信息。目标是了解数据属性以及数据质量。
模型工程(Data Engineering)
这是大多数人与构建机器学习模型相关联的阶段。在这个阶段,使用数据来训练和评估模型。这通常是一个迭代的任务,其中尝试不同的模型,并调整模型。
- 选择和训练模型(Select&Train Model):确定合适的模型,并构建/训练模型(在训练数据上)。培训的目标是尽可能正确地回答问题或进行预测。
- 测试模型(Test Model):在模型尚未看到的数据上运行模型(例如测试数据)。换句话说,通过使用从培训中保留的数据进行模型测试(即回测)。
- 评估和解释模型(Evaluate&Interpret Model):客观地测量模型的性能。请注意,基本评估探讨精度和精确度等指标,以确定模型是否可用,并确定哪个模型最适合解决特定的问题。这个评估还包括了解模型何时犯错误。更普遍地说,在将训练好的模型投入生产之前,验证训练好的模型有助于确保模型符合最初的组织目标。
- 调整模型(Tune Model):这一步涉及到参数调整,这依赖于所使用的模型,可能更像是一门艺术而不是科学。简而言之,模型通常具有参数(即调整模型的旋钮),允许通过参数细化模型来获得改进的性能。简单的模型参数可能包括培训步骤的数量和某些值的初始化。
模型运营 (ML Ops)
广义上定义的模型运营(ML Ops)涵盖了数据科学家、数据工程师、云工程师、IT运营和业务利益相关者用于部署、扩展和维护机器学习解决方案的一系列实践、系统和责任。
- 部署模型(Deploy Model):打包并投入使用模型(即投入生产)。尽管这因小组而异,但团队需要了解预期的模型性能、模型将如何进行监控以及通常的模型关键绩效指标(KPI)。
- 监控模型(Moniter Model):在生产中维护模型。这包括监控关键绩效指标并主动努力确保预测稳定而且可靠。
其它
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/72138
推荐阅读
相关标签

