
- 1C#结合JavaScript实现多文件上传_c#js上传文件
- 2烂泥:【解决】修改LVM卷组名重启系统后,无法进入进入系统
- 3JAVA在线购物茶叶商城网站系统设计与实现(Springboot框架)
- 4Vue2 props组件通信-父子组件传值
- 5Python 与 PySpark数据分析实战指南:解锁数据洞见_python和pyspark数据分析 乔纳森·里乌 pdf
- 6100天精通Python(可视化篇)——第105天:Pyecharts绘制多种炫酷极坐标系参数说明+代码实战
- 7网络游戏防沉迷实名认证系统常见错误说明_sys req partner error
- 8【前端异常】JavaScript错误处理:分析 Uncaught(in promise) error
- 9http和https区别
- 10JavaScript学习 ——(基础知识点大全)_定义和取出浏览器对象 javascript
上采样和下采样_一文带你读懂 DeconvNet 上采样层(语义分割)
赞
踩
本文为 AI 研习社编译的技术博客,原标题 :
Review: DeconvNet — Unpooling Layer (Semantic Segmentation)
作者 | SH Tsang
翻译 | 斯蒂芬·二狗子
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/review-deconvnet-unpooling-layer-semantic-segmentation-55cf8a6e380e
在本文中,我们简要回顾了DeconvNet,反卷积网络(DeconvNet)由反卷积deconvolution 和上池化unpooling层组成。
对于传统的全卷积网络FCN,输出是通过高比率(32×,16×和8×倍)的上采样获得的,这可能引起粗分割输出结果(标签图)。在DeconvNet中,最终的输出标签是通过逐渐进行的反卷积和上池化获得的。这篇论文发表于2015年ICCV上,当我写这篇博文时,已经有一千多的引用量(SH Tsang @ Medium)。
本文涉及的内容
上池化和反卷积
实例分割
两阶段训练
模型结果
1.上采样和反卷积
以下是DeconvNet的整体架构:
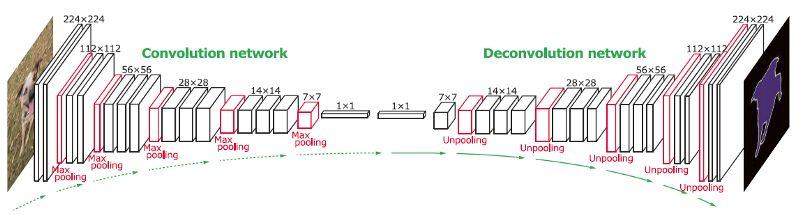
DeconvNet 的架构
正如我们看到的,该网络使用VGG作为其backbone框架。第一部分是卷积网络,像FCN一样,具有卷积和池化层。第二部分是反卷积网络,这是本文中的一个新颖部分。
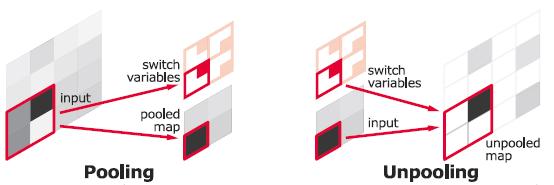
Pooling过程(左),模型记住位置信息,在Unpooling期间使用位置信息(右)
要执行上池化,我们需要记住执行最大池时每个最大激活值的位置,如上所示。然后,记住的位置信息用于上池化操作,如上所示。
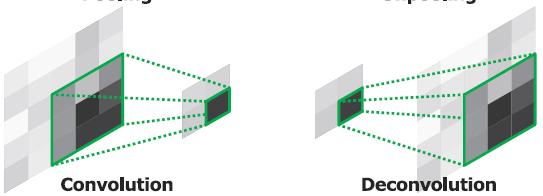
卷积是将输入转换为更小的尺寸(左),反卷积是将输入转换回更大的尺寸(右)
反卷积只是为了将输入转换回更大的尺寸。 (如有兴趣,请阅读我的有关FCN评论一文,详细了解。)
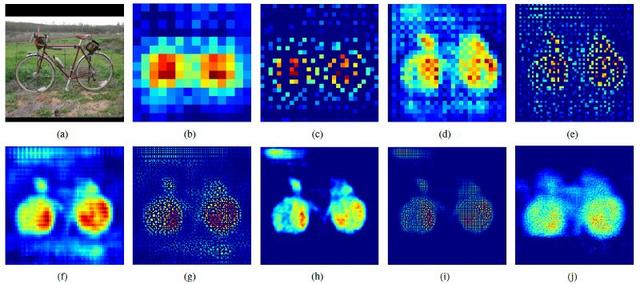
一个反卷积Deconvolution 和上池化Unpooling的例子
上图是一个例子。 (b)是14×14 反卷积层的输出。 (c)是上池化后的输出,依此顺序类推。我们可以在(j)中看到自行车的标签图可以在最后的224×224 反卷积层重建,这表明学习特征的这些卷积核可以捕获类特定的形状信息。
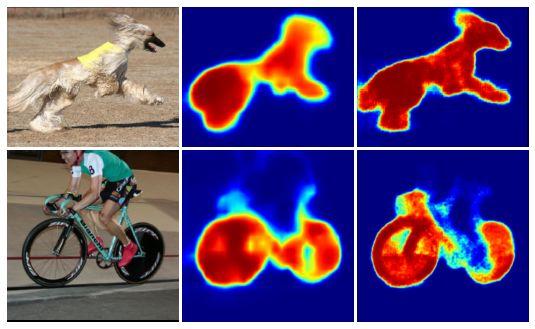
输入图像(左),FCN-8s(中),DeconvNet(右)
上面展示的其他示例表明DeconvNet比FCN-8可以给出更精确的形状。
2.实例分割

不使用区域提议Region Proposals的语义分割任务的不好的例子
如上所示,基本上大于或小于感受野的物体可能被模型给碎片化分割或贴上错误的标签。像素较小的目标经常被忽略并归类为背景。
语义分割可以看为是实例分割问题。首先,通过对象检测方法EdgeBox检测2000个区域建议region proposals中的前50个(边界框)。然后,DeconvNet应用于每个区域,并将所有建议区域的输出汇总回原始图像。通过使用 proposals ,可以有效地处理各种规模的图片分割问题。
3.两阶段训练
第一阶段训练
使用ground-truth标注来裁剪目标实例,使目标在裁剪的边界框中居中,然后进行训练。这有助于减少对象位置和大小的变化。
第二阶段训练
使用更具挑战性的例子。这些例子是由重叠的ground-truth 分割的区域建议生成/裁剪的。
其他细节
BN 在网络中使用
使用VGG的权重来初始化卷积层的参数
反卷积层的参数初始化为0均值的高斯分布
每batch样本数量是64
4.结果
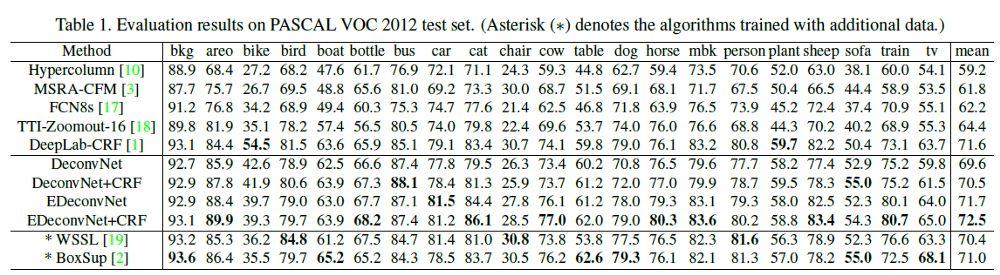
mean Iou结果
FCN-8s:只有 64.4% mean IoU.
DeconvNet: 69.6%
DeconvNet+CRF: 70.5% (其中CRF只是一个模型输出后的处理步骤)
EDeconvNet: 71.5% (EDeconvNet 是指DeconvNet和FCN-8s模型集成后的结果)
EDeconvNet+CRF: 72.5%具有最高的mean IoU结果。
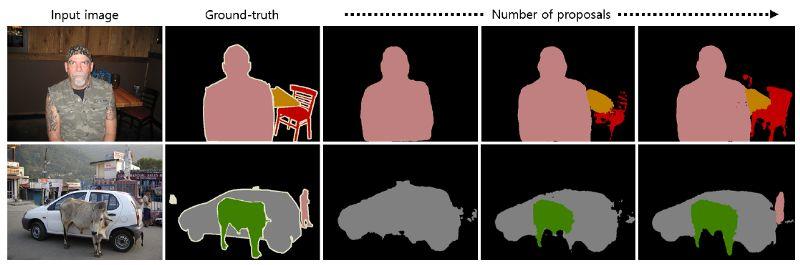
实例分割的优势
从上图中知道,实例分割有助于逐个实例地逐步分割,而不是一次对所有实例进行分段。
值得注意的是,DeconvNet的优势不仅来逐步的反卷积和上池,还可能来自实例分割和两阶段 two-stage的训练。
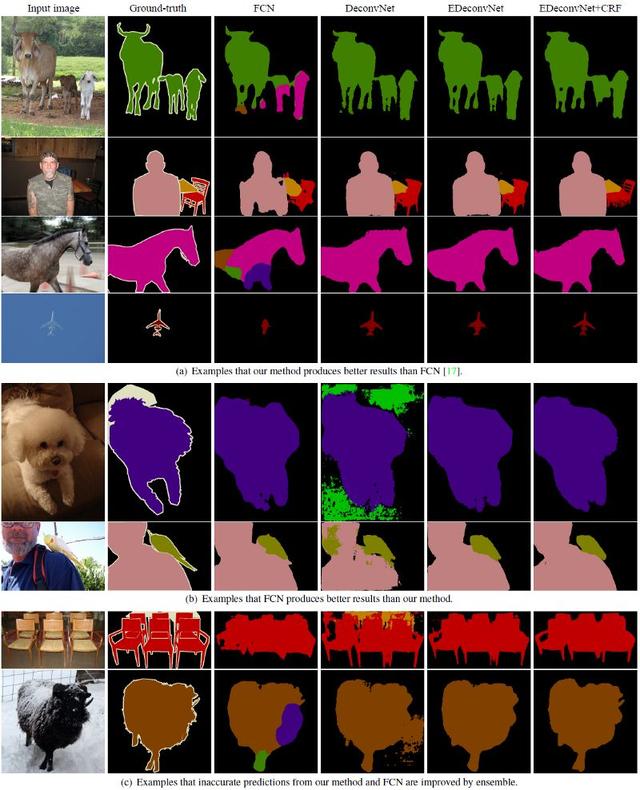
一些可视化结果
即使EConvNet + CRF输出结果比FCN差,但通常它的实际效果还是很好的。
参考文献
[2015 ICCV] [DeconvNet]Learning Deconvolution Network for Semantic Segmentation
我的其他文章
[FCN] [VGGNet]
想要继续查看该篇文章相关链接和参考文献?
点击【一文带你读懂 DeconvNet 上采样层(语义分割)】或长按下方地址:
https://ai.yanxishe.com/page/TextTranslation/1530
AI研习社今日推荐:雷锋网雷锋网雷锋网
李飞飞主讲王牌课程,计算机视觉的深化课程,神经网络在计算机视觉领域的应用,涵盖图像分类、定位、检测等视觉识别任务,以及其在搜索、图像理解、应用、地图绘制、医学、无人驾驶飞机和自动驾驶汽车领域的前沿应用。
加入小组免费观看视频:https://ai.yanxishe.com/page/groupDetail/19

