
SpringCloud 整合 Canal+RabbitMQ+Redis 实现数据监听
赞
踩
戳上方蓝字“Java知音”关注我
1Canal介绍
Canal 指的是阿里巴巴开源的数据同步工具,用于数据库的实时增量数据订阅和消费。它可以针对 MySQL、MariaDB、Percona、阿里云RDS、Gtid模式下的异构数据同步等情况进行实时增量数据同步。
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
Canal是如何同步数据库数据的呢?
Canal通过伪装成mysql从服务向主服务拉取数据,所以先来了解一下MySQL的主从复制吧
2MySQL主从复制原理
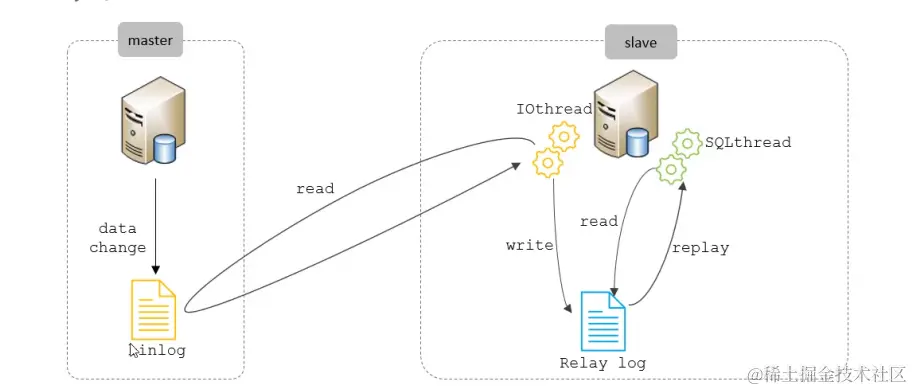
1、从库(slave)会生成两个线程,I/O线程(IOthread),SQL线程(SQLthread)。
2、当slave的I/O线程连接到master后,会去请求master的二进制日志(binlog), 此时master会通过logdump(将主库的二进制日志文件内容传输给从库的过程) 给从库传输binlog。
3、 然后slave将拿到的binlog日志依次写入Relaylog(中继日志)的最末端,同时将读取到的Master 的bin-log的文件名和位置记录到master- info文件中,作用为了让slave知道它需要从哪个位置和哪 个日志文件开始同步数据,以保证数据的一致性,并且能够及时获取到master的新的更新操作, 开始数据同步过程。slave不仅在启动时读取 master-info 文件,而且会定期更新该文件中的记 录,以确保记录都是最新的。
4、最后SQL线程会读取Relaylog,并解析为具体操作(比如DDL这种),来实现主从库的操作一致, 最终实现数据一致;
大致了解完了MySQL的主从复制,接着我们看Canal就简单啦。
3Canal工作原理
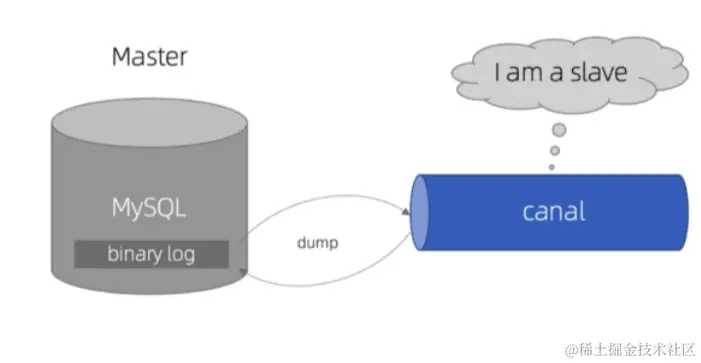
1、Canal Server与MySQL建立连接后,会通过模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议获取数据库的 binlog(二进制日志)文件。
2、Canal Server解析binlog文件,通过网络将解析后的事件传输给消息中间件(Kafka,RabbitMQ等),实现数据的实时同步。
了解完canal的原理后,我们就正式开始RabbitMQ+Canal+Redis实现缓存和数据库数据一致的功能。
4RabbitMQ+Canal+redis工作原理
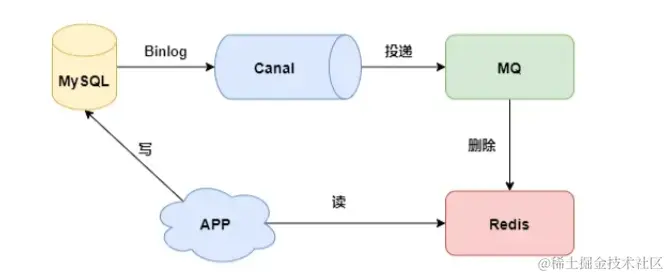
通过上图很好理解:
APP向数据库进行写操作(比如我们更新商品信息啥的)
Canal监听到数据库发生变化,便会向rabbitMQ传递数据库发生变化的消息。
消费者就可以从rabbitMQ获取这些消息,然后进行删除缓存操作。
下面通过实战让我们更好地理解是如何实现缓存和数据库数据一致性的。
5实战配置
Canal 配置
修改 conf/canal.properties 配置
修改实例配置文件 conf/example/instance.properties
- #配置 slaveId,自定义,不等于 mysql 的 server Id 即可
- canal.instance.mysql.slaveId=10
-
- # 数据库地址:配置自己的ip和端口
- canal.instance.master.address=你的IP:端口号
-
- # 数据库用户名和密码
- canal.instance.dbUsername=用户名
- canal.instance.dbPassword=密码
-
- # 指定库和表
- canal.instance.filter.regex=.*\..* # 这里的 .* 表示 canal.instance.master.address 下面的所有数据库
-
- # mq config
- # rabbitmq 的 routing key
- canal.mq.topic=canal.routing.key(这是本例子用的key)

然后重启 canal 服务。
RabbitMQ 配置
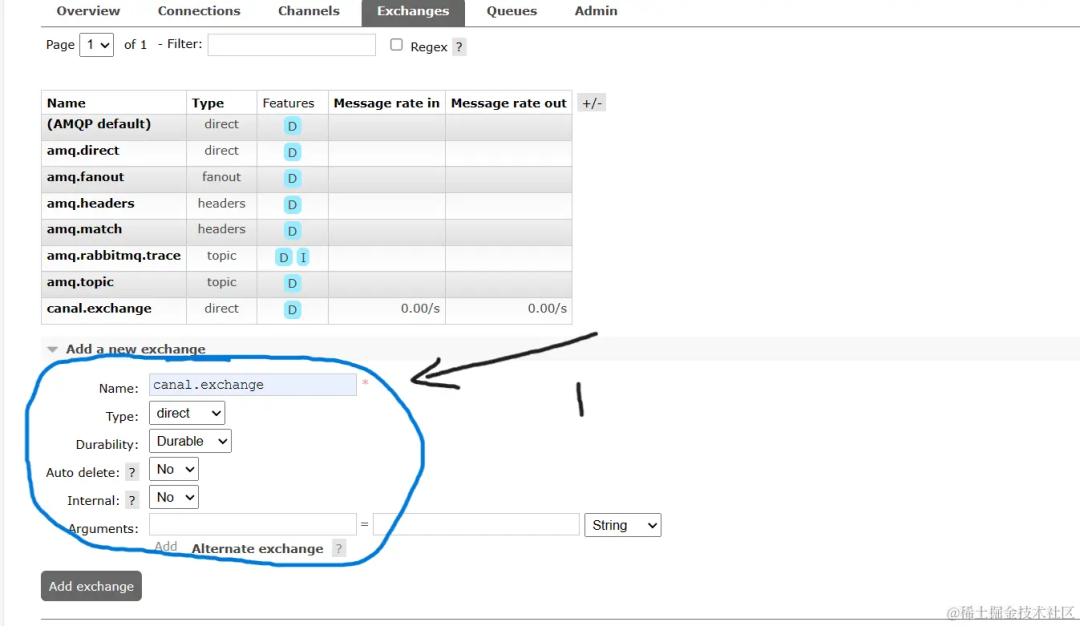
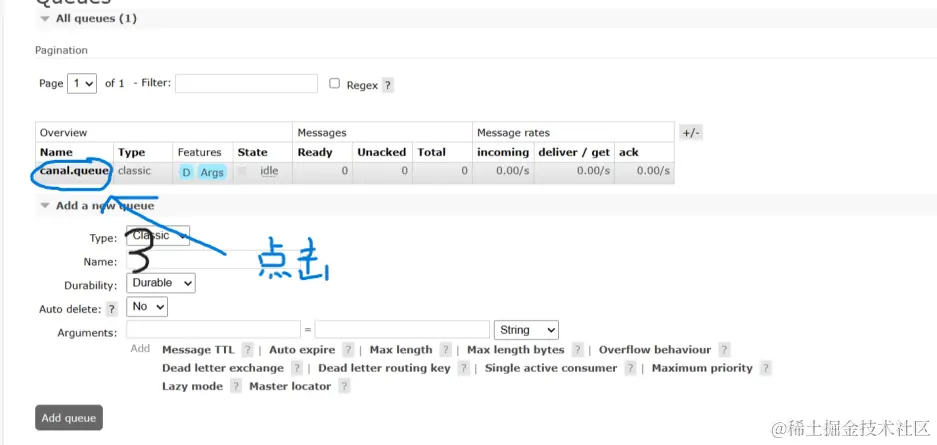
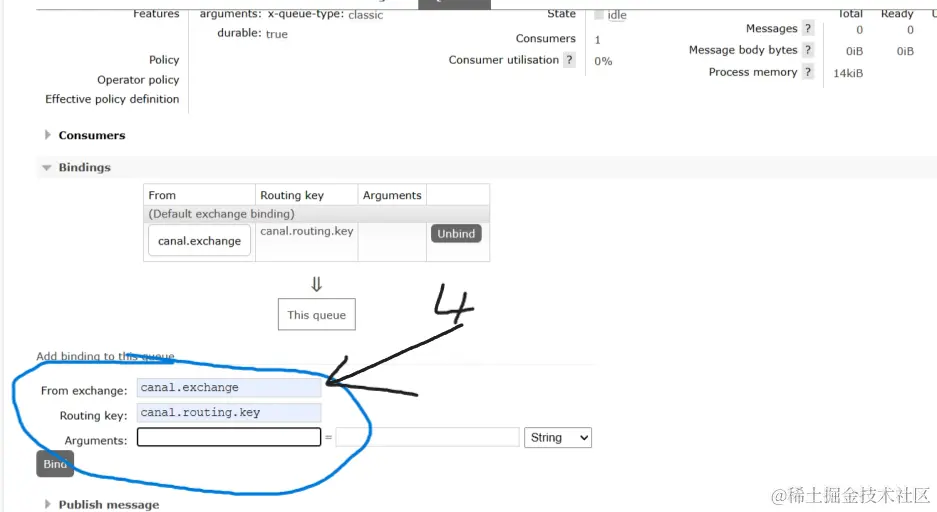
这样rabbitMQ就配置完啦,下面就是实战代码啦。
6实战代码
CanalMessage: Canal传来的消息
- @NoArgsConstructor
- @Data
- public class CanalMessage<T> {
- private String type;
- private String table;
- private List<T> data;
- private String database;
- private Long es;
- private Integer id;
- private Boolean isDdl;
- private List<T> old;
- private List<String> pkNames;
- private String sql;
- private Long ts;
- }
RabbitMQ配置类
- @Configuration
- @Slf4j
- public class RabbitConfig {
-
- /**
- * 消息序列化配置
- */
- @Bean
- public RabbitListenerContainerFactory<?> rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
- // SimpleRabbitListenerContainerFactory 是 RabbitMQ 提供的一个实现了 RabbitListenerContainerFactory 接口的简单消息监听器容器工厂。
- // 它的作用是创建和配置 RabbitMQ 消息监听器容器,用于监听和处理消息。
- SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
- //ConnectionFactory 是 RabbitMQ 提供的一个接口,用于创建 RabbitMQ 的连接
- factory.setConnectionFactory(connectionFactory);
- //使用了 Jackson2JsonMessageConverter 将消息转换为 JSON 格式进行序列化和反序列化
- factory.setMessageConverter( new Jackson2JsonMessageConverter());
- return factory;
- }
- }
将消息转换为JSON格式,才能映射到CanalMessage上。
RabbitMQ+Canal监听处理类
- @Component
- @Slf4j
- @RequiredArgsConstructor
- public class CanalListener {
-
- private final SysMenuService menuService;
-
- //@RabbitListener(queues = "canal.queue")
- public void handleDataChange(@Payload CanalMessage message) {
- String tableName = message.getTable();
-
- log.info("Canal 监听 {} 发生变化;明细:{}", tableName, message);
- if (Arrays.asList("sys_menu", "sys_role", "sys_role_menu").contains(tableName)) {
- log.info("======== 清理菜单路由缓存 ========");
- menuService.cleanCache();
- }
- }
- }
menuService的cleanCache()是把登录时的路由列表缓存清除掉,
具体可去源码查看,在最底下。
这样我们实现缓存和数据库数据一致性的功能就完成啦,接下来测试一下。
7测试
我们直接通过手动修改数据库来完成测试。
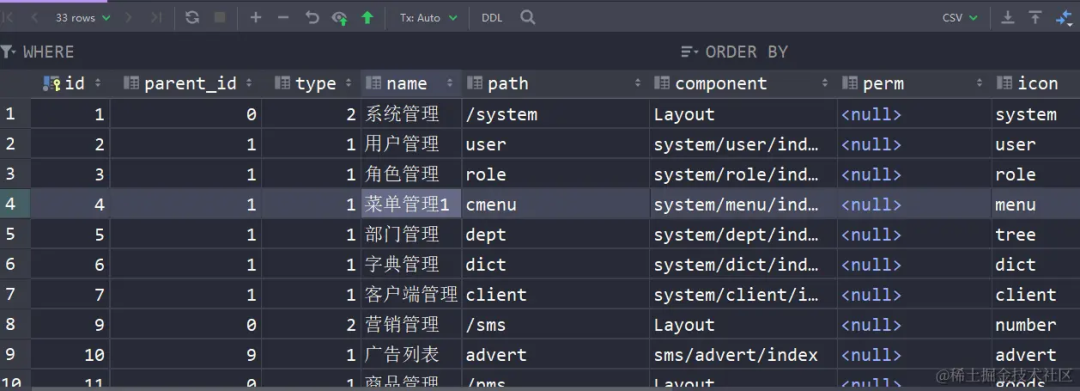
我们在菜单表修改菜单管理的内容改成菜单管理1,点击保存
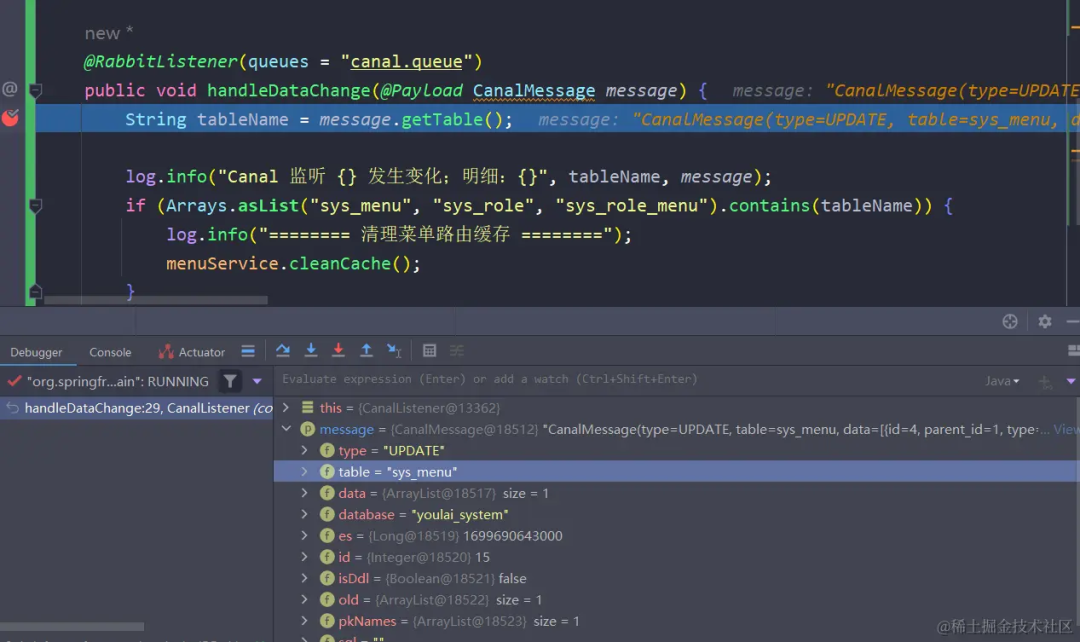
可以看到更新操作已经被监听到啦。接着就完成清理缓存操作咯,然后就可以防止缓存和数据库数据不一致的问题啦。
代码摘自
https://gitee.com/youlaitech/youlai-mall
感谢阅读,希望对你有所帮助 :) 来源:
juejin.cn/post/7299733832412643363
- 后端专属技术群
-
- 构建高质量的技术交流社群,欢迎从事编程开发、技术招聘HR进群,也欢迎大家分享自己公司的内推信息,相互帮助,一起进步!
- 文明发言,以交流技术、职位内推、行业探讨为主
- 广告人士勿入,切勿轻信私聊,防止被骗
-
- 加我好友,拉你进群

