
- 1计算机管理中没有vhd,防患于未然,安全体验Win11很简单
- 2MyBatis常见面试题汇总
- 3Jmeter之HTTP请求详解_jmeter http请求
- 4python爬取微博数据_Python selenium爬取微博数据代码实例
- 5ChatGPT目前的AI一哥
- 6机器学习(四)——多变量回归_多变量调整模型
- 7天天干些鸟事.自己都拿自己没办法.无奈。_色天天
- 8java switch用法_javaswitch用法
- 9安装labelme时遇到的问题及解决方案_building wheel for pyqt5-sip (pyproject.toml) did
- 10模拟a标签实现下载,文件下载通过Blob对象实现_模拟a链接下载
软件架构-zookeeper场景讲解(分布式锁)和zkclient使用_zookeeper与zkclient 有什么区别
赞
踩
继续开车,其实zookeeper能用到的场景很多,在这里在介绍几个场景,在说下分布式锁,很多了解都想知道分布式锁, 其实分布式锁并不是zk的一个特性,用zk能做的事情太多了。
源码:https://github.com/limingios/netFuture/源码/『互联网架构』软件架构-zookeeper场景讲解(分布式锁)和zkclient使用(35)

场景分析
- 以前的job场景
很多的项目中,都要有job,跑一些定时的任务,每天需要统计下订单量,需要定时发送消息,很多的job。原来的job是部署在服务器上的,因为代码都是都是一致的,导致job根据服务器多少,执行多少次,为了防止这一点,就要设置开关,单独在要在执行的那个机器上设置一个文本,程序读各自的文本,只有1个机器标识的是开,其他都是关闭。也就是线上可能部署了5台机器,但是只有1台机器在跑。

肯定有人问我,为啥只启动一台机器,都启动多好啊,如果要执行一个短信的任务,每个机器都接收到了,都启动的话那用户会根据服务的数量接收到响应的短信数量。这肯定是有问题的。不要重复干事情,一个人干就好了。
如果定时服务job的服务挂了,整个任务系统也就挂了。也是有问题的。
用zk来接管的话,在这三个里面选出一个老大出来
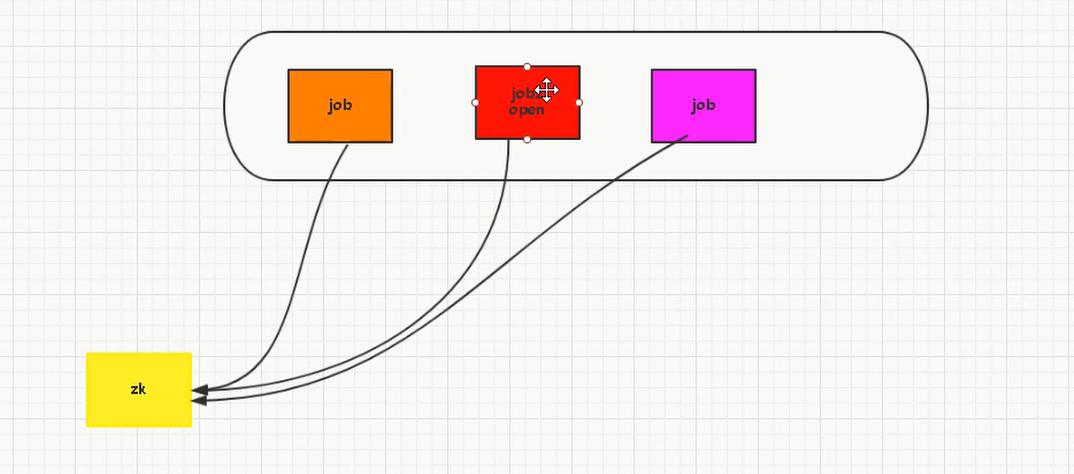
如果老大挂了,下面的2个小弟根据规则选出来老大
- 分布式配置中心
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者获取数据,实现配置信息的集中式管理和动态更新。
总结:感应变化 pull模式(C>S)/push模式(S>C)
适用:
全局的配置信息 服务式服务框架的服务地址列表
注意点:
数据量很小,但是数据更新可能会比较快的场景
代表:
百度的disconf github:https://github.com/knightliao/disconf
(二)分布式锁
- 由来
执行一段代码,例如i++,部署在3台机器,每台机器上都有个jvm,如果要统一的控制i++这段代码,jvm都是相对独立的,这里用jvm的锁,是完全不行的。这里就产生了分布式锁。也可以用数据库来完成。通过数据库的排它锁的特性上,大部分业务场景都不需要借助分布式锁。但也有业务需要用到分布式锁。但是对于大型互联网架构,数据库就是瓶颈,尽量多读少写,如果使用数据库这个排它锁的特性有可能给数据库更大的压力。数据库有可能产生死锁,数据库的竞争太激烈了,锁没有及时的释放掉,数据库也会产生问题,直接锁表。这时候就必须使用分布式锁。
- 介绍
分布式锁,这个主要是易于zookeeper为我们保证数据的枪一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
1.所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁,通常的做法是把zk上的一个znode看作一把锁,通过create znode的方式来实现。所有客户端都去创建/distribute_lock节点,最终成功创建的那个客户端就拥有了这把锁
2.控制时序,就是吧所有试图来获取这个锁的客户端,最终是会被安排执行,只是有了全局时序了。做法和上边基本类似,只是这里/distribute_lock 已绊,预先存在,客户端在他下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建时序性,从而也形成了每个客户端的全局时序。
- 排它锁
排它锁(Exclusive Lovks,简称X锁),又称为写锁
如果事务T1对数据对象01加上了排它锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能在对这个数据对象进行任何类型的操作(不能再对该对象加锁),直到T1释放了排它锁。
谁创建谁获的锁

但是上边这个,如果10000个线程等待一个锁,那么当锁被释放后,10000个线程同时去竞争,就会产生羊群效应。所谓羊群效应就是每个节点挂掉,所有节点都去监听,然后做出反映,这样会给服务器带来巨大压力。zookeeper分布式锁的原理其实很简单,首先zookeeper创建个PERSISTENT持久节点,然后每个要获得锁的线程都会在这个节点下创建个临时顺序节点,然后规定节点最小的那个获得锁,所以每个线程首先都会判断自己是不是节点序号最小的那个,如果是则获取锁,如果不是则watcher监听比自己小的上一个节点,如果上一个节点不存在了,然后会再一次判断自己是不是序号最小的那个节点,是则获得锁。当一个节点挂掉只有监听这个节点的才会做出反映。
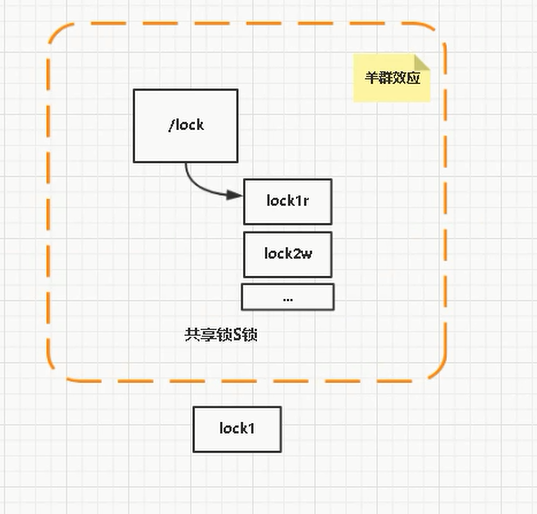
- 共享锁
共享锁(Shared Locks,简称S锁),又称为为读锁。
如果事务T1对数据对象O1加上一个共享锁,那么T1只能对O1进行读操作,其他事务也能同时怼O1加共享锁(不能是排它锁),知道O1上的所有共享锁都释放后O1才能被加排它锁。
zookeeper客户端
很少人直接用原生的,就像我们解析json,其实用字符串根据规则也可以解析,后来有了新的jar,阿里fastjson后,谁也不在用字符串解析了吧。站在巨人的肩膀上才能看的更高更远。
- ZkClient
ZkClient是由Datameer的工程师开发的开源客户端,对Zookeeper的原生API进行了包装,实现了超时重连、Watcher反复注册等功能。
- Curator
Curator是Netflix公司开源的一个Zookeeper客户端,与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量。
zkClient
在使用ZooKeeper的Java客户端时,经常需要处理几个问题:重复注册watcher、session失效重连、异常处理。目前已经运用到了很多项目中,知名的有Dubbo、Kafka、Helix。
Maven依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
或者
<dependency>
<groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
Github:https://github.com/sgroschupf/zkclient

- ZKClient的设计

- ZkClient的组件说明
从上述结构上看,IZKConnection是一个ZkClient与ZooKeeper之间的一个适配器。在代码里直接使用的是ZKClient,其实质还是委托了zookeeper来处理了。使用ZooKeeper客户端来注册watcher有几种方法:
1、创建ZooKeeper对象时指定默认的Watcher,
2、getData(),
3、exists(),
4、getchildren。
其中getdata,exists注册的是某个节点的事件处理器(watcher),getchildren注册的是子节点的事件处理器(watcher)。而在ZKClient中,根据事件类型,分为了节点事件(数据事件)、子节点事件。对应的事件处理器则是IZKDataListener和IZKChildListener。另外加入了Session相关的事件和事件处理器。
ZkEventThread是专门用来处理事件的线程。
- 启动ZKClient
在创建ZKClient对象时,就完成了到ZooKeeper服务器连接的建立。具体过程是这样的:

1、 启动时,指定好connection string,连接超时时间,序列化工具等。
2、 创建并启动eventThread,用于接收事件,并调度事件监听器Listener的执行。
3、 连接到zookeeper服务器,同时将ZKClient自身作为默认的Watcher。
- 为节点注册Watcher
ZooKeeper的三个方法:getData、getChildren、exists,ZKClient都提供了相应的代理方法。就拿exists来看:

可以看到,是否注册watcher,由hasListeners(path)来决定的。

hasListeners就是看有没有与该数据节点绑定的listener。
所以呢,默认情况下,都会自动的为指定的path注册watcher,并且是默认的watcher(ZKClient)。怎么才能让hasListeners判定值为true呢,也就是怎么才能为path绑定Listener呢?
- ZKClient提供了订阅功能:

一个新建的会话,只需要在取得响应的数据节点后,调用subscribteXxx就可以订阅上相应的事件了。
- ZooKeeper的变更操作
Zookeeper中提供的变更操作有:节点的创建、删除,节点数据的修改。
创建操作,数据节点分为四种,ZKClient分别为他们提供了相应的代理:

删除节点的操作:
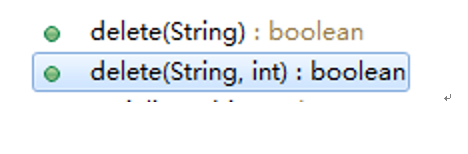
修改节点数据的操作:
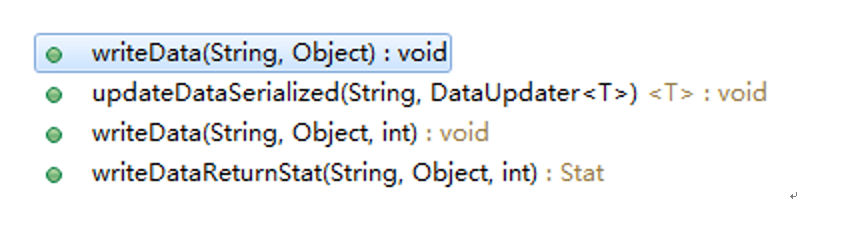
writeDataReturnStat():写数据并返回数据的状态。
updateDataSerialized():修改已序列化的数据。执行过程是:先读取数据,然后使用DataUpdater对数据修改,最后调用writeData将修改后的数据发送给服务端。
- 客户端处理变更
前面已经知道,ZKClient是默认的Watcher,并且在为各个数据节点注册的Watcher都是这个默认的Watcher。那么该是如何将各种事件通知给相应的Listener呢?
处理过程大致可以概括为下面的步骤:
1、判断变更类型:变更类型分为State变更、ChildNode变更(创建子节点、删除子节点、修改子节点数据)、NodeData变更(创建指定node,删除节点,节点数据变更)。
2、取出与path关联的Listeners,并为每一个Listener创建一个ZKEvent,将ZkEvent交给ZkEventThread处理。
3、ZkEventThread线程,拿到ZkEvent后,只需要调用ZkEvent的run方法进行处理。
从这里也可以知道,具体的怎么如何调用Listener,还要依赖于ZkEvent的run()实现了。
- 序列化处理
ZooKeeper中,会涉及到序列化、反序列化的操作有两种:getData、setData。在ZKClient中,分别用readData、writeData来替代了。
对于readData:先调用zookeeper的getData,然后进行使用ZKSerializer进行反序列化工作。
对于writeData:先使用ZKSerializer将对象序列化后,再调用zookeeper的setData。
- 注册监听
在ZkClient中客户端可以通过注册相关的事件监听来实现对Zookeeper服务端时间的订阅。其中ZkClient提供的监听事件接口有以下几种:
| 接口类 | 注册监听方法 | 解除监听方法 |
|---|---|---|
| IZkChildListener | ZkClient的subscribeChildChanges方法 | ZkClient的unsubscribeChildChanges方法 |
| IZkDataListener | ZkClient的subscribeDataChanges方法 | ZkClient的subscribeChildChanges方法 |
| IZkStateListener | ZkClient的subscribeStateChanges方法 | ZkClient的unsubscribeStateChanges方法 |
其中ZkClient还提供了一个unsubscribeAll方法,来解除所有监听。
- ZkClient如何解决使用ZooKeeper客户端遇到的问题的呢?
Watcher自动重注册:这个要是依赖于hasListeners()的判断,来决定是否再次注册。
如果对此有不清晰的,可以看上面的流程处理的说明Session失效重连:如果发现会话过期,就先关闭已有连接,再重新建立连接。
异常处理:对比ZooKeeper和ZKClient,就可以发现ZooKeeper的所有操作都是抛异常的,而ZKClient的所有操作,都不会抛异常的。在发生异常时,它或做日志,或返回空,或做相应的Listener调用。
相比于ZooKeeper官方客户端,使用ZKClient时,只需要关注实际的Listener实现即可。所以这个客户端,还是推荐大家使用的。
PS:zkClient应该就是对zk的操作的一个工具类,方便使用zk,了解api,其实不难。但是zk的原理必须了解。临时,永久,排它锁,共享锁。

