
热门标签
热门文章
- 1ESP32网络编程实例-WebSocket服务器广播信息_websocket 广播消息
- 2VS Code配置使用 Python,超详细配置指南,看这一篇就够了_vscode python环境配置
- 3MATLAB卷积运算解释(conv、conv2、convn)_matlab表示卷积公式
- 4logback在SpringBoot下出现no applicable action for [appender], current ElementPath is [[configuration][a_no applicable action for [appenders], current elem
- 5Office 中的 Copilot_office copilot
- 6NvidiaAGXXavier刷机Jetpack5.0.2报错记录(已解决,非搬运)_datetime target setup - target: depends on failed
- 7openjdk17体验
- 8深入理解@DubboReference与@DubboService【三】_@dubboservice 和 @dubboreference 在同一个服务中
- 9ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SL
- 10计算机视觉库OpenCV详解
当前位置: article > 正文
使用 Llama-2–7b 进行医学问答的检索增强生成 使用 AWS 探索 Llama-2–7b 在医学领域检索增强生成的功能_colab上 llama2-7b
作者:Gausst松鼠会 | 2024-02-18 07:20:39
赞
踩
colab上 llama2-7b
在复杂的医疗信息领域,答案的准确性和可靠性至关重要。该项目旨在通过将 Llama-2-7b 模型的先进功能与检索增强生成 (RAG) 方法相结合来满足这一需求。我们的系统利用从“pubmed”中提取的精选知识库,并采用密集和稀疏嵌入,确保提供的答案不仅是数据驱动的,而且是上下文准确且与医学相关的。该计划旨在减轻大型语言模型中经常出现的模型幻觉,同时确保提供精确且相关的响应,所有这些都使用 AWS SageMaker 和 Pinecone 等技术资源高效执行。
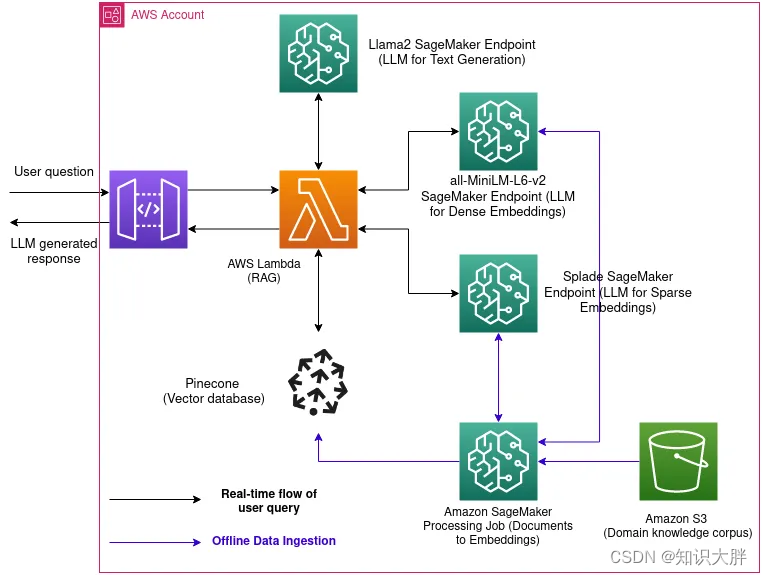
上图是在AWS SageMaker环境中实施的项目架构的直观表示。
在离线数据摄取期间,将 S3 知识库中的所有医疗文档嵌入并存储到 Pinecone 矢量数据库中。
用户向系统提交特定领域的医学知识查询。
嵌入用户的查询并从存储的向量知识库中检索语义相似的文档。
将检索到的文档作为上下文输入提供给 Llama-2–7b 模型,并将其输入提示中。
Llama-2-7b 生成响应,优先考虑从上下文文档得出的答案的效率和准确性。
将生成的精确响应返回给用户。
问答
问答 (QA) 系统在自然语言处理 (NLP) 的各个领域都至关重要,从根本上寻求从信息池中提取准确的答案来响应用户的查询。虽然大型预训练语言模型已成为在多个 NLP 任务中取得实质性成果的基石,但它们在获取和巧妙操作特定知识方面存在固有的局限性。这些限制在知识密集型任务中变得尤其明显,强调了更细致、更适合任务的解决方案的迫切必要性。
检索增强生成
检索增强生成(RAG)的出现是对独立预训练模型局限性的战略回应,引入了一
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/106055
推荐阅读
相关标签

