
热门标签
热门文章
- 1基于Next.js搭建基本可用于项目开发的过程_nextjs 权限控制
- 2【已解决】springCould整合feign提示required a bean of type xxx that could not be found_required a bean of type 引入的包
- 3Win10快捷键大全~提高工作效率必备技能,你值得拥有_win10快捷键图片
- 4关于jquery.lazyload.min.js+ajax实现分页图片预加载,如何只刷新新添加的内容
- 5使用深度学习进行时间序列预测
- 6HTML5七夕情人节表白网页(烂漫的空中散落的花瓣3D相册) HTML+CSS+JS 求婚 html生日快乐祝福代码网页 520情人节告白代码 程序员表白源码 3D旋转相册 js烟花代码_htnl5浪漫相册源码下载
- 7(附源码)springboot高校学生健康打卡系统的设计与实现 毕业设计021009_个人健康打卡系统
- 8oracle切换实例启动,SQLPLUS登录以及切换Oracle数据库实例和用户
- 9vue框架二级路由echarts不显示问题解决_vue子组件echarts图不加载
- 10工作记录 -- el-table 取消鼠标悬浮时行高亮效果_el-table划过取消高亮
当前位置: article > 正文
机器学习算法基础:所有实例代码_机器学习行业 代码实例
作者:Gausst松鼠会 | 2024-02-22 12:32:45
赞
踩
机器学习行业 代码实例
1. 字典特征抽取
代码
from sklearn.feature_extraction import DictVectorizer def dictvec(): #字典数据抽取 #实例化 dict=DictVectorizer(sparse=False) #调用fit_transform,字典储存在列表中 data=dict.fit_transform([{'city': '北京','temperature': 100} , {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}]) print(dict.get_feature_names()) print(dict.inverse_transform(data)) print(data) if __name__=="__main__": dictvec()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果

2、文本特征抽取
代码
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
#对文本进行特征值化
CV=CountVectorizer()
data=CV.fit_transform(["life is short,i like python","life is too long,i dislike python"])
print(CV.get_feature_names()) #统计所有文章当中所有的词,重复的只看做一次 词的列表
print(data.toarray()) #对每篇文章,在词的列表里面进行统计每个词出现的次数
if __name__=="__main__":
countvec()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果

3、中文文本特征抽取
代码
from sklearn.feature_extraction import DictVectorizer from sklearn.feature_extraction.text import CountVectorizer import jieba def cutword(): con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。") con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。") con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。") #转换成列表 content1=list(con1) content2=list(con2) content3=list(con3) #把列表换换成字符串 c1=" ".join(content1) c2 = " ".join(content2) c3 = " ".join(content3) return c1, c2, c3 def hanzi(): #中文特征值化 c1,c2,c3=cutword() print(c1,c2,c3) CV = CountVectorizer() data = CV.fit_transform([c1,c2,c3]) # 需要对中文进行分词处理 print(CV.get_feature_names()) # 统计所有文章当中所有的词,重复的只看做一次 词的列表 print(data.toarray()) # 对每篇文章,在词的列表里面进行统计每个词出现的次数 if __name__=="__main__": hanzi()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
结果

显示为矩阵结果:data.toarray()
4、tfidf实例
代码
from sklearn.feature_extraction import DictVectorizer from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer import jieba def tfidfvec(): #中文特征值化 c1,c2,c3=cutword() print(c1,c2,c3) tf = TfidfVectorizer() data = tf.fit_transform([c1,c2,c3]) # 需要对中文进行分词处理 print(tf.get_feature_names()) # 统计所有文章当中所有的词,重复的只看做一次 词的列表 print(data.toarray()) # 对每篇文章,在词的列表里面进行统计每个词出现的次数 if __name__=="__main__": tfidfvec()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果

5、二维数组的归一化
代码
from sklearn.preprocessing import MinMaxScaler
def mm():
#归一化处理
mm=MinMaxScaler(feature_range=(2,3))
data=mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
if __name__=="__main__":
mm()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果

6、标准化实例
代码
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def stand():
#标准化缩放
std=StandardScaler()
data=std.fit_transform([[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]])
print(data)
if __name__=="__main__":
stand()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果
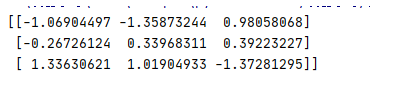
7、缺失值填补实例
代码
from sklearn.impute import SimpleImputer
import numpy as np
def im():
#缺失值
im=SimpleImputer(missing_values=np.nan, strategy=“mean”)
data=im.fit_transform([[1,2],[np.nan,3],[7,6]])
print(data)
if name==“main”:
im()
结果

8、过滤式特征选择
代码
from sklearn.feature_selection import VarianceThreshold
def var():
#特征选择
var=VarianceThreshold(threshold=1.0) #取值根据实际的需求
data=var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
print(data)
if __name__=="__main__":
var()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/130125
推荐阅读
相关标签

