
热门标签
热门文章
- 1【Pytorch学习】-- 模型参数更新-- Loss Function & Optimizer_pytorch多个损失怎么更新
- 2在Linux系统上安装Wine方法教程_linuxxiezaiwine教程
- 3《Python编程从入门到实践》外星人入侵游戏——添加 飞船 图片和外星人 图片,素材_游戏外星人入侵的飞船图片
- 4深度学习中初始学习率设置技巧
- 5第一次参赛获Java B组国二,给蓝桥杯Beginners的6700字保姆级经验分享。_蓝桥杯java组经验贴
- 6【Linux内核链表】的原理及使用方式整理_linux内核链表的使用
- 7使用GPT-4,学渣比学霸更有优势
- 8【游戏开发创新】Unity+人工智能,让小朋友的画成真,六一儿童节一起来画猫猫吧(Unity | 人工智能 | 绘图 | 爬虫 | 猫妖)_unity 粒子绘画
- 9STATUS_STACK_BUFFER_OVERRUN encountered
- 10u-boot spl 学习总结_uboot spl
当前位置: article > 正文
matplotlib 热力图_还在一味追求看似漂亮,实则无用的热力图吗?Python可视化系列...
作者:Gausst松鼠会 | 2024-02-29 16:44:48
赞
踩
matplotlib库热力图介绍
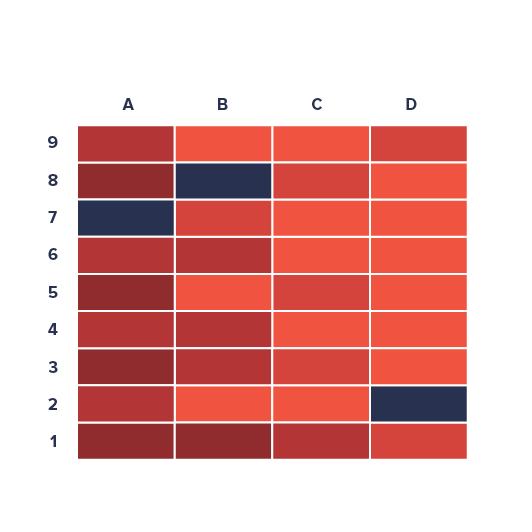
最初看到热力图时,你是不是会从内心发出惊呼,看着特别有感觉?
那老海就问第二个问题了,然后你还能看出什么来?
颜色有深有浅?还有什么?能看出哪个区域大吗?到底又大多少?
哈哈,这种感觉就是热力图的特点:如同蒙面美人的图表类型!
OK,什么是热力图?
热力图 (Heat Map),“热力图” 一词最初是由软件设计师提出并创造的,专门用来描述实时金融市场信息的图表类型。注意是软件设计师提出的,不是视觉设计师,更不是数据分析师!
正因如此,就如同南丁格尔玫瑰图一样,都是特殊出身,因此用途局限性非常大。
最早的热力图,都是在矩形色块加上颜色变换。而当今我们说的大多是经过平滑模糊的热力图谱,这样的热力图更容易让人们理解和解读。
热力图的基本数据样式
不同的特征字段,在不同的数值上的统计情况,统计分布不同则颜色也变化。
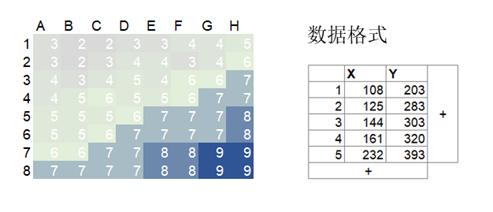
热力图的使用建议
- 热力图在绘图前尽量统一数据量纲、或者进行归一化标准化处理
- 热力图的主要应用在整体全局的数据呈现,不适合局部精准数据展示
- 热力图的颜色带来强烈的视觉冲击力,数据准确度上较弱,很难来分辨具体大小
- 热力图常用来用表达分布,所以一般情况用彩虹色系(rainbow)来传达这个分布变化
- 热力图背景常常是图片或地图,因此不需要必须有坐标轴。
下面开始具体的操作案例
准备工作
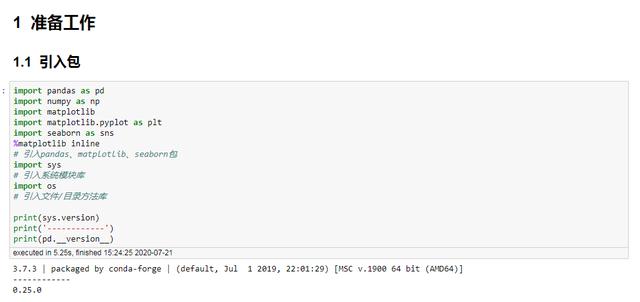
## 初始字体设置,设置好可避免很多麻烦plt.rcParams['font.sans-serif']=['Source Han Sans CN'] # 显示中文不乱码,思源黑体 plt.rcParams['font.size'] = 22 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整plt.rcParams['axes.unicode_minus'] = False # 显示负数不乱码## 初始化图表大小plt.rcParams['figure.figsize'] = (20.0, 8.0) # 设置figure_size尺寸## 初始化图表分辨率质量plt.rcParams['savefig.dpi'] = 300 # 设置图表保存时的像素分辨率plt.rcParams['figure.dpi'] = 300 # 设置图表绘制时的像素分辨率## 图表的颜色自定义colors = ['#dc2624', '#2b4750', '#45a0a2', '#e87a59', '#7dcaa9', '#649E7D', '#dc8018', '#C89F91', '#6c6d6c', '#4f6268', '#c7cccf']plt.rcParams['axes.prop_cycle'] = plt.cycler( color=colors)path = 'D:系列文章'# 自定义文件路径,可以自行设定os.chdir(path)# 设置为该路径为工作路径,一般存放数据源文件设定图表样式和文件路径
Financial_data = pd.read_excel('虚拟演示案例数据.xlsx',sheet_name='二维表')Financial_data读入数据
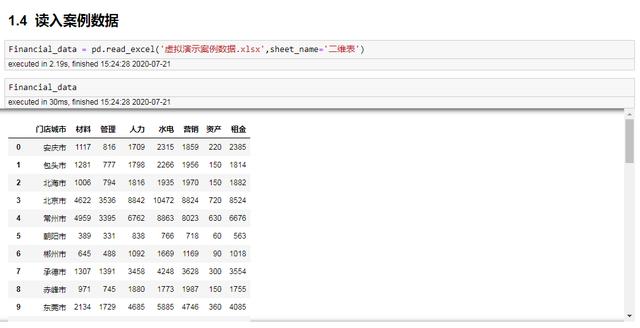
Financial_data = pd.read_excel('虚拟演示案例数据.xlsx',sheet_name='二维表')Financial_data热力图的基本数据结构
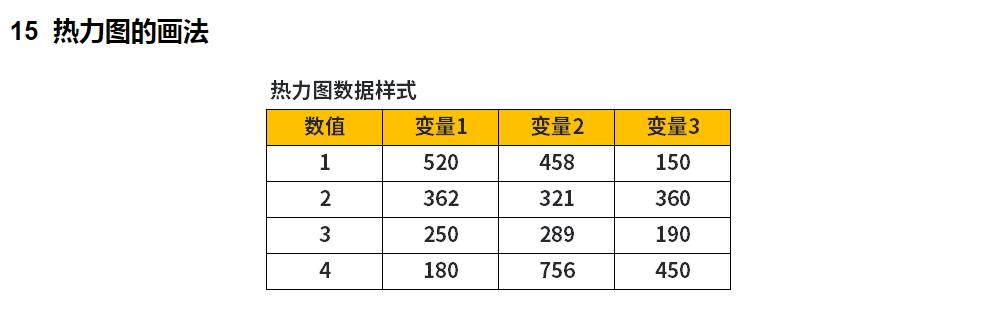
热力图的基本颜色配色

各个数值在不同特征下的热力情况
最基本的热力图原理,方便我们理解热力这个概念是什么
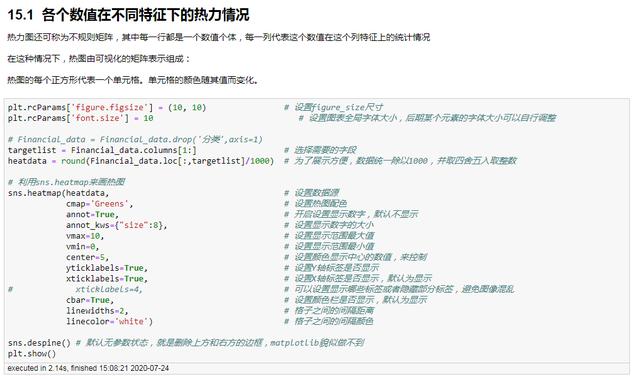
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整# Financial_data = Financial_data.drop('分类',axis=1)targetlist = Financial_data.columns[1:] # 选择需要的字段heatdata = round(Financial_data.loc[:,targetlist]/1000) # 为了展示方便,数据统一除以1000,并取四舍五入取整数# 利用sns.heatmap来画热图sns.heatmap(heatdata, # 设置数据源 cmap='Greens', # 设置热图配色 annot=True, # 开启设置显示数字,默认不显示 annot_kws={"size":8}, # 设置显示数字的大小 vmax=10, # 设置显示范围最大值 vmin=0, # 设置显示范围最小值 center=5, # 设置颜色显示中心的数值,来控制 yticklabels=True, # 设置Y轴标签是否显示 xticklabels=True, # 设置X轴标签是否显示,默认为显示# xticklabels=4, # 可以设置显示哪些标签或者隐藏部分标签,避免图像混乱 cbar=True, # 设置颜色栏是否显示,默认为显示 linewidths=2, # 格子之间的间隔距离 linecolor='white') # 格子之间的间隔颜色sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()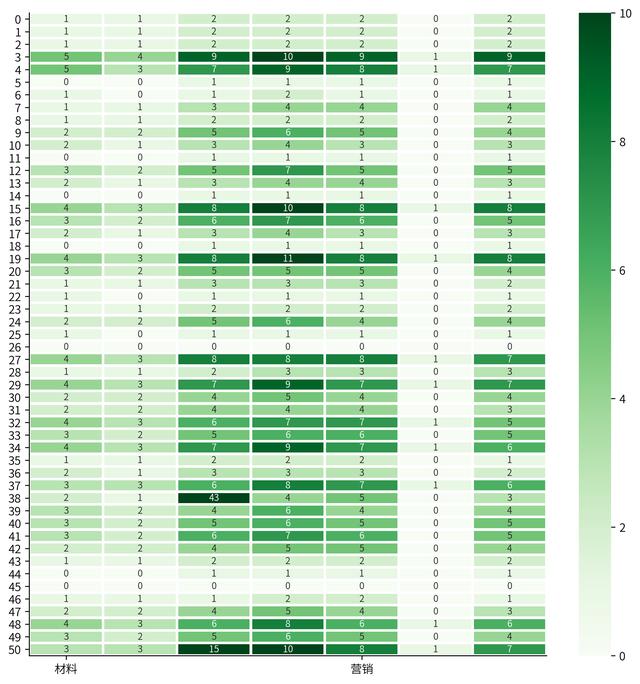
设定分组对象在不同特征下的热力情况
可自定义我们需要参考的对比对象
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整# Financial_data = Financial_data.drop('分类',axis=1)# targetlist = Financial_data.columns[:] # 选择需要的字段heatdata = Financial_data.set_index('门店城市',drop=True) # 设置参考对象列作为index索引# corr_matrix=heatdata.corr()# 利用sns.heatmap来画热图sns.heatmap(heatdata, # 设置数据源 cmap='Greens', # 设置热图配色 annot=True, # 设置显示数字 vmax=10, # 设置显示范围最大值 vmin=0, # 设置显示范围最小值 center=5, # 设置颜色显示中心的数值,来控制 linewidths=2) # 格子之间的间隔距离sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()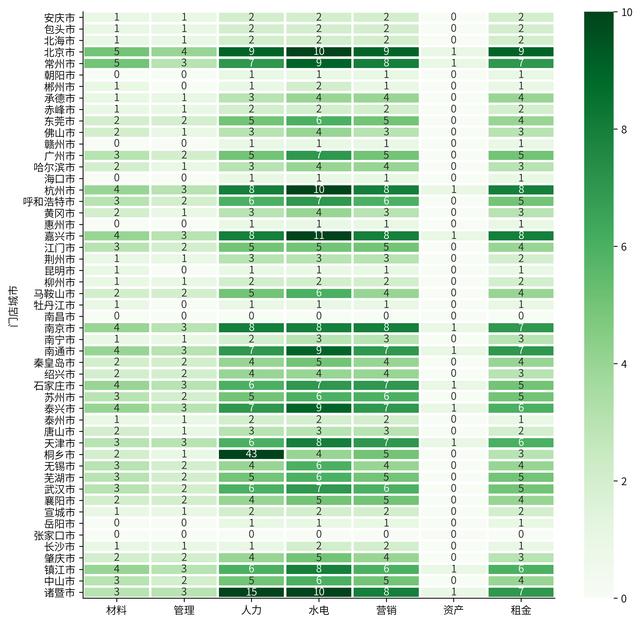
相关矩阵(平方)
除了查看统计分布,还可以查看不同变量之间的相关性,常用在特征选择上
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整# Financial_data = Financial_data.drop('分类',axis=1)targetlist = Financial_data.columns[1:] # 选择需要的字段heatdata = round(Financial_data.loc[:,targetlist]/1000) # 为了展示方便,数据统一除以1000,并取四舍五入取整数corr_matrix=heatdata.corr()# 利用sns.heatmap来画热图sns.heatmap(corr_matrix, # 设置数据源 cmap='Greens', # 设置热图配色 annot=True, # 设置显示数字 vmax=1, # 设置显示范围最大值 vmin=0, # 设置显示范围最小值 center=5, # 设置颜色显示中心的数值,来控制 linewidths=2) # 格子之间的间隔距离sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()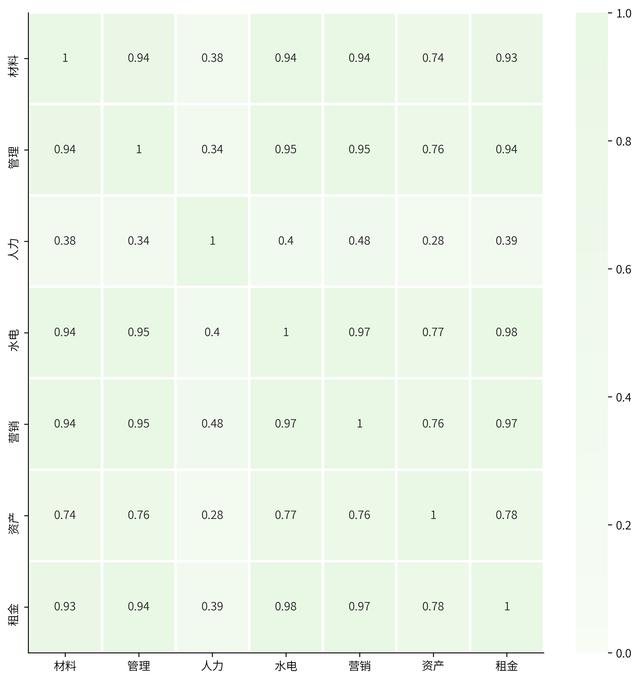
半相关热图
这是相关矩阵热力图的简化版,因为对角矩阵的一半元素都是相同的,所以可以简化
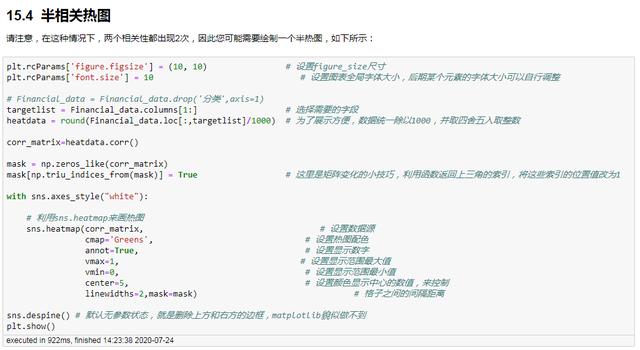
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整# Financial_data = Financial_data.drop('分类',axis=1)targetlist = Financial_data.columns[1:] # 选择需要的字段heatdata = round(Financial_data.loc[:,targetlist]/1000) # 为了展示方便,数据统一除以1000,并取四舍五入取整数# 极值化MAX-MINnormalization_matrix=(heatdata-heatdata.min())/heatdata.max()# 正则化normalization_matrix=(heatdata-heatdata.mean())/heatdata.std()# 利用sns.heatmap来画热图sns.heatmap(normalization_matrix, # 设置数据源 cmap='Greens', # 设置热图配色 annot=True, # 设置显示数字 vmax=1, # 设置显示范围最大值 vmin=0, # 设置显示范围最小值 center=5, # 设置颜色显示中心的数值,来控制 linewidths=2) # 格子之间的间隔距离sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()
无量纲化热力图
有时数据的量纲规模变化很大,此时建议统一数据量纲,效果会好些
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整# Financial_data = Financial_data.drop('分类',axis=1)targetlist = Financial_data.columns[1:] # 选择需要的字段heatdata = round(Financial_data.loc[:,targetlist]/1000) # 为了展示方便,数据统一除以1000,并取四舍五入取整数# 极值化MAX-MINnormalization_matrix=(heatdata-heatdata.min())/heatdata.max()# 正则化normalization_matrix=(heatdata-heatdata.mean())/heatdata.std()# 利用sns.heatmap来画热图sns.heatmap(normalization_matrix, # 设置数据源 cmap='Greens', # 设置热图配色 annot=True, # 设置显示数字 vmax=1, # 设置显示范围最大值 vmin=0, # 设置显示范围最小值 center=5, # 设置颜色显示中心的数值,来控制 linewidths=2) # 格子之间的间隔距离sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()树形+热力图
这是混合图表应用,用途特别有些,有时候数据图表都堆在一起,看着就乱,不推荐
plt.rcParams['figure.figsize'] = (10, 10) # 设置figure_size尺寸plt.rcParams['font.size'] = 10 # 设置图表全局字体大小,后期某个元素的字体大小可以自行调整heatdata = Financial_data.set_index('门店城市',drop=True) # 设置参考对象列作为index索引# # 利用sns.heatmap来画热图# sns.heatmap(heatdata, # 设置数据源# cmap='Greens', # 设置热图配色# annot=True, # 设置显示数字# vmax=1, # 设置显示范围最大值# vmin=0, # 设置显示范围最小值# center=5, # 设置颜色显示中心的数值,来控制# linewidths=2) # 格子之间的间隔距离# 距离相似性的设置sns.clustermap(heatdata.iloc[:20,:], metric="correlation", # 距离相似性,设置为相似性:"correlation",欧氏距离:"euclidean" method="single", # 聚类的方法,设置为最近点算法:"single",方差最小化算法:"Ward" cmap="Blues", # 设置热图配色 standard_scale=1, # 归一化设置,还可设置z_score=1的方法 robust=True, # 离群值检验,默认为不开启,这里设置开启离群值研究# row_colors=row_colors )sns.despine() # 默认无参数状态,就是删除上方和右方的边框,matplotlib貌似做不到plt.show()
写在最后
上一篇介绍气泡图,而热力图给人的视觉冲击力更强,当然也就变得更不精准
我们使用图表的目标不同,选择图表时就得非常注意,
热力图我一般是不会选择的,商业分析一般要求务必表达精准,所以它不适合
更多的时候是在做机器学习的特征选择时,会探索一下变量间的相关性如何。
OK,今天先到这里了,老海日常随笔总结,码字不易,初心不改!
如果觉得喜欢,请动动小手关注和转发,鼓励一下我们。
我是老海,来自数据炼金术师
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/166863
推荐阅读
相关标签

