
- 1【Unity3D实战】零基础一步一步教你制作跑酷类游戏_unity3d跑酷人物
- 2pocketminemp运行php,教程 - PocketMine-MP - Linux常见问题解决【转载】 | MineBBS 我的世界中文论坛...
- 3Element table组件内容\n换行解决办法_element表单内容换行
- 4Python GUI 设计(一)———Tkinter窗口创建、组件布局_python gui界面设计
- 5Python电能质量扰动信号分类(六)基于扰动信号特征提取的超强机器学习识别模型
- 6java 通过枚举实现单例模式做缓存_java枚举缓存
- 7python小程序表白_python表白小程序
- 8MPLS技术简介_mpls工作的三个过程
- 9c#语言read函数,如何:使用 Windows ReadFile 函数(C# 编程指南)
- 10[Unity]内置渲染管线转URP_unity内置渲染管线换 urp
9 算法设计与分析_算法的设计过程是一个灵活的充满智慧的过程,设计解决问题的算法对计算机专业人员来说通常是最具挑战的任务
赞
踩
9 算法设计与分析
算法给公认为是计算机科学的基石,算法理论研究的是算法的设计技术和分析技术。
前者回答的是“ 对特定的问题,如何提出一个算法来求解? ”这样的问题,即面对一个问题,如何设计一个有效的算法;后者回答的是“ 该算法是否足够好? ”,即对已设计的算法,如何评价或判断其优劣。
二者是互相依存的,设计出的算法需要检验和评价,对算法的分析反过来又将改进算法的设计。、
9.1 算法设计与分析的基本概念
9.1.1 算法
算法(Algorithm)是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作。此外,一个算法还具有下列 5 个重要特性。
(1)有穷性。
一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间内完成。
(2)确定性。
算法中每一条指令必须有确切的含义,读者理解时不会产生二义性。并且在任何条件下,算法只有唯一的一条执行路径,即对于相同的输入只能得出相同的输出。
(3)可行性。
一个算法是可行的,即算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现。
(4)输入。
一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合。
(5)输出。
一个算法有一个或多个输出,这些输出是通输入有着特定关系的量。
9.1.2 算法设计
算法设计是一件非常困难的工作,通常设计一个“ 好 ”的算法应考虑多个目标,包括正确性、可读性、健壮性和高效性等。
由于实际问题各种各样,问题求解的方法千变万化,所以算法设计又是一个灵活的充满智慧的过程,需要设计人员根据实际情况具体问题具体分析。
存在多种算法设计技术(也称为算法设计策略),它们是设计算法的一般方法。已经证明这些技术对于设计好的算法非常有用,掌握了这些技术之后,设计新的和有用的算法会变得容易。经常采用的算法设计技术主要有分治法、动态规划法、贪心法、回溯法、分支界限发、概率算法和近似算法等。
另外,在解决计算机领域以外的问题时,这些技术也能起到很好的指导作用。
9.1.3 算法分析
通常求解一个问题可能会有多种算法可供选择,选择的主要标准首先是算法的正确性、可靠性、简单性和易理解性。
其次是算法的时间复杂度和空间复杂度要低,这正是算法分析技术的主要内容。
算法分析是指对一个算法所需要的资源进行估算,这些资源包括内存、通信带宽、计算机硬件和时间等,所需要的资源越多,该算法的复杂性就越高。
不言而喻,对于任何给定的问题,设计出复杂性尽可能低的算法是设计算法时追求的目标。
另一方面,当给定问题有很多种算法时,选择其中复杂性最低者,是选用算法时遵循的重要准则。因此,算法的复杂性分析对算法的设计和选用有重要的指导意义和实用价值。
而在计算机资源中,最重要的是时间和空间(存储器)资源,因此复杂性分析主要包括时间复杂性和空间复杂性。
9.1.4 算法的表示
常用的算法的方法有自然语言、流程图、程序设计语言和伪代码等。
(1)自然语言。
最大的优点是容易理解,缺点是容易出现二义性,并且算法通常很冗长。
(2)流程图。
优点是直观易懂,缺点是严密性不如程序设计语言,灵活性不如自然语言。
(3)程序设计语言。
优点是能用计算机直接执行,缺点是抽象性查,是算法设计者拘泥于描述算法的具体细节,忽略了“ 好 ”算法和正确逻辑的重要性。此外,还要求算法设计者掌握程序设计语言及编程技巧。
(4)伪代码。
伪代码是介于自然语言和程序设计语言之间的方法,它采用某一程序设计语言的基本语法,操作指令可以结合自然语言来设计。计算机科学家从来没有对伪代码的书写形式达成共识。在伪代码中,可以采用最具表达力的、最简明扼要的方法来表达一个给定的算法。
本章采用伪代码来表示算法。
本章伪代码的一些约定。
(1)用缩进表示程序中的分程序和程序块结构。
(2)while、for等循环结构和if、then、else等条件结构与Pascal 中的相似。其实只要熟悉Pascal、C、C++或者Java中的某一种语言,便可很容易理解伪代码表达的含义。
(3)用 ▷ 表示注释。
(4)数组的元素通过“ 数组名[ 下标 ] ”的方式访问,下标从 1 开始。
(5)参数采用按值传递。
(6)布尔运算符 and 和 or 具有短路能力。
9.2 算法分析基础
9.2.1 时间复杂性
由于时间复杂性与空间复杂性概念类似,计算方法相似,且空间复杂性分析相对简单些,因此下面将主要讨论时间复杂性。
算法的时间复杂度分析主要是分析算法的运行时间,即算法所执行的基本操作数。
不同规模的输入所需要的基本操作数是不相同的,如用同一个排序算法排序 100 个数和排序 10 000 个数所需要的操作数是不相同的,因此考虑特定输入规模的算法的具体操作数既是不现实也是不必要的。在算法分析中,可以建立输入规模 n 为自变量的函数 T(n)时间复杂度。
即使对相同的输入规模,数据分布不相同也决定了算法执行不同的路径,因此所需要的执行时间也不相同。根据不同的输入,将算法的时间复杂度分析为三种情况。
(1)最佳情况。
使算法执行时间最少的输入。
一般情况下,不进行算法在最佳情况下的时间复杂度分析。
应用最佳情况分析的一个例子是已经证明基于比较的排序算法的时间复杂度下限为 Ω(ngln),那么就不需要白费力气去想方设法将该类算法改进为线性时间复杂度。
(2)最坏情况。
使算法执行时间最多的输入。
一般会进行算法在最坏时间复杂度的分析,因为最坏情况是在任何输入下运行时间的一个上限,它给我们提供一个保障,情况不会比这更糟糕。
另外,对于某些算法来说,最坏情况还是相当频繁的。而且大致上看,平均情况通常与最坏情况的时间复杂度一样。
(3)平均情况。
算法的平均运行时间,一般来说,这种情况很难分析。
举个简单的例子,现要排序 10 个 不同的整数,输入就有 10!中不同的情况,平均情况的时间复杂度要考虑每一种输入及其该输入的概率。平均情况分析可以按如下三个步骤进行。
① 将所有的输入按其执行时间分类。
② 确定每类输入发生的概率。
③ 确定每类输入的执行时间。
下式给出了一般算法在平均情况下的复杂度分析。
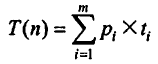
其中,P表示第 i 类输入发生的概率; ti 表示 第 i 类输入的执行时间,输入分类 m 类。
9.2.2 渐进符号
以输入规模 n 为自变量建立的时间复杂度实际上还是较复杂的,如 ![]() ,不仅与输入规模有关,还与系数 a、b和 c 有关。此时可以对该函数做进一步的抽象,仅考虑运行时间的增长率或称为增长的量级,如忽略上式中的低阶和高阶项的系数,斤考虑 n2.当输入规模达到使只有与运行时间的增长量级有关时,就是在研究算法的渐进效率。也就是说,从极限角度看,只关心算法运行时间如何随着输入规模的无限增长而增长。下面简单介绍三种常用的标准方法来简化算法的渐进分析。
,不仅与输入规模有关,还与系数 a、b和 c 有关。此时可以对该函数做进一步的抽象,仅考虑运行时间的增长率或称为增长的量级,如忽略上式中的低阶和高阶项的系数,斤考虑 n2.当输入规模达到使只有与运行时间的增长量级有关时,就是在研究算法的渐进效率。也就是说,从极限角度看,只关心算法运行时间如何随着输入规模的无限增长而增长。下面简单介绍三种常用的标准方法来简化算法的渐进分析。
(1)Ο记号。
给出一个函数渐进上界。
给定一个函数g(n),Ο(g(n))表示为一个函数集合{f(n):存在正常数 c和 n0,使得对所有的 n≥n0,有 0≤f(n) ≤ cg(n)}。
(2)Ω 记号。
给出一个函数渐进下界。
给定一个函数g(n),Ο(g(n))表示为一个函数集合 ![]()
(3)Θ 记号。
给出一个函数的渐进上界和下界,即渐进确界。
给定一个函数 g(n),Ο(g(n))表示一个函数集合![]()
![]()

9.2.3 递归式
从算法的结构上看,算法可以分为非递归形式和递归形式。非递归算法的时间复杂度分析较简单,本节主要讨论递归算法的时间复杂度分析方法。
(1)展开法
将递归式中等式右边的项根据递归式进行替换,称为展开。展开后的项被再次展开,如此下去,直到得到一个求和表达式,得到结果。
(2)代换法。
这一名称来源于当归纳假设用较小值时,用所猜测的值代替函数的解。
用代换法解递归式时,需要两个步骤:猜测解的形式;用数学归纳法找出使解真正有效的常数。
(3)递归树法。
递归树法弥补了代换法猜测困难的缺点,它适于提供“ 好 ”的猜测,然后用代换法证明。在递归树中,每一个节点都代表递归函数调用集合中每一个子问题的代价。将树中每一层的代价相加得到一个每层代价的集合,再将每层的代价相加得到递归式所有层次的总代价。当递归式表示分治算法的时间复杂度时,递归树的方法尤其有用。
(4)主方法。
也称为主定理,给出求解如下形式的递归式的快速方法。
其中,a≥ 1 和 b>1 是常数,f(n) 是一个渐进的正函数。
9.3 分治法
9.3.1 递归的概念
递归是指子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己,是一种描述问题和解决问题的常用方法。在计算机算法设计与分析中,递归技术是十分有用的。使用递归技术往往使函数的定义和算法的描述简洁易懂且易于分析,为此在介绍其他算法设计方法之前先讨论它。
递归有两个基本要素:边界条件,即确定递归到何时终止,也称为递归出口;递归模式,即大问题是如何分解为小问题的,也称为递归体。
9.3.2 分治法的基本思想
分治与递归就像一对孪生兄弟,经常同时应用于算法设计之中,并由此产生许多高效的算法。
我们知道,任何一个可以用计算机求解的问题所需要的计算时间斗鱼其规模有关。问题的规模越小,解题所需要的计算时间往往也越少,从而也较容易处理。
例如,对于 n 个元素的排序问题,当 n =1时,不需任何比较;当 n= 2时,只要做一次比较即可;... ... 而且当 n 较大时,问题就不那么容易处理了。要想直接解决一个较大的问题,有时是相当困难的。
分治法的设计思想是将一个难以直接解决的大问题分解成一些规模较小的相同问题以便各个击破,分而治之。如果规模为 n 的问题分解为 k 个子问题,1 ≤ k ≤ n,这些子问题互相独立且与原问题相同。
分治法产生的子问题往往是原问题的较小规模,这就为递归技术提供了方便。
一般来说,分值算法在每一层递归上都有三个步骤。
(1)分解。将原问题分解成一系列子问题。
(2)求解。递归地求解各子问题。若子问题足够小,则直接求解。
(3)合并。将子问题的解合并成员问题的解。
9.3.3 分治法的典型实例
以上讨论的是分治法的基本思想和一般原则,下面用一些具体例子来说明如何针对具体问题分治思想来设计有效算法。
例:
归并排序。
归并排序算法是成功应用分治法的一个完美的例子,其基本思想是将待排序元素分成大小大致相同的两个序列,分别对这两个子序列进行排序,最终将排序号的子序列合并为所要求的序列。归并排序算法完全依照上述分治算法的三个步骤进行。
(1)分解。将 n 个元素分成各含 n/2 个元素的子序列。
(2)求解。用归并排序对两个子序列递归地排序。
(3)合并。合并两个已经拍好的子序列已得到排序结果。
9.4 动态规划法
9.4.1 动态规划法的基本思想
动态规划法与分治法类似,其基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治法不同的是,适合于用动态规划法求解的问题,进分解得到的子问题往往不是独立的。
若用分治法来解这类问题,则相同的子问题会被求解多次,以至于最后解决原问题需要耗费指数级时间。
人儿,不同子问题的数目常常只有多项式量级。如果能保存已解决的子问题答案,而在需要时找出已求得的答案,这样可以避免大量的重复计算,从而得到多项式时间的算法。为了达到这个目的,可以用一个表来记录所有已解决的子问题的答案。不管该子问题以后是否被用到,只要她被计算过,就将其结果填入表中。这就是动态规划法的基本思路。
动态规划算法通常用于求解具有某种最优性质的问题。
在这类问题中,可能会有许多可行解,每个解都对应于一个值,我们希望找到具有最优值(最大值或最小值)的那个解。
,最优解可能会有多个,动态规划算法找出其中的一个最优解。
设计一个动态规划算法,通常可按照以下几个步骤进行。
(1)找出最优解的性质,并刻画其结构特征。
(2)递归地定义最优解的值。
(3)以自底向上的方式计算出最优值。
(4)根据计算最优值时得到的信息,构造一个最优解。
步骤(1)~ (3)是动态规划算法的基本步骤。在只需要求最优值的的情形,步骤(4)可以省略。
若需要求出问题的一个最优解,则必须执行步骤(4)。此时,在步骤(3)中计算最优值时,通常需记录更多的信息,以便在步骤(4)中根据记录的信息快速构造出一个最优解。
动态规划法是一个非常有效的算法设计技术,那么何时可以用用动态对话来设计算法呢?
对于一个给定的问题,若其具有以下两个性质,则可以考虑用动态规划法来求解:
(1)最优子结构。
如果一个问题的最优解中包含了其子问题的最优解,就说该问题具有最优子结构当一个问题具有最优子结构时,提示我们动态规划法可能会使用,但是此时贪心策略也可能使用的。
(2)重叠子问题。
指用来解原问题的递归算法可反复地解同样的子问题,而不是总在产生新的子问题。
即当一个递归算法不断地调用同一个问题时,就说该问题包含重叠子问题。此时若用分治法递归求解,则每次遇到子问题都会视为新问题,会极大降低算法的效率,而动态规划法总是充分利用重叠子问题,对每个子问题仅计算一次,把解保存在一个需要时就可以查看的表中,而每次查表的时间为常数。
9.4.2 动态规划法的典型实例
0-1 背包问题
0-2 矩阵连乘问题
0-3 最长公共子序列(LCS)
9.5 贪心法
9.5.1 贪心法的基本思想
作为一种算法设计技术,贪心法是一种简单的方法。
和动态规划法一样,贪心法也经常用于解决最优化问题。不过与动态规划法不同的是,贪心法在解决问题的策略上是仅根据当前已有的信息作出选择,而且一旦做了选择,不管将来有什么结果,这个选择都不会改变。换言之,贪心法并不是从整体最优考虑,它所做出的选择只是在某总意义上的局部最优。这种局部最优选择并不能保证总能获得全局最优解,但通常能得到较好的近似最优解。举一个简单的贪心法列子,平时购物找钱时,先尽量用最大面值的币种,当不足大面值币种的金额时才去考虑下一种较小面值的币种。这就是采用贪心法。这种方法在这里总是最优,是因为银行对其发行的硬币种类和硬币面值的巧妙安排。
如果只有面值分别为1,5和11单位的硬币,而希望找回总额为15单位的硬币,按贪心算法,应找 1个11单位面值的硬币和 4 个 1 单位面值的硬币,共找回 5 个硬币。但最优的解答应是 3 个 5单位面值的硬币。
我们知道,贪心算法不中能得到最优解,那么对于一个具体的问题,如何得知是否可以用贪心法来求解,以及能否得到问题的最优解?这个问题很难得到肯性的回答。但是,从许多可以用贪心法求得最优解的问题中看到,这类问题一般具有两个重要的性质。
(1)最优子结构。
当一个问题的最优解包含其子问题的最优解时,称此问题具有子结构。问题的最优子结构时该问题可以采用动态规划法或者贪心法求解的关键性质。
(2)贪心选择性质。
指问题的整体最后解可以通过一系列局部最优的选择,即贪心选择来得到。这是贪心法和动态规划法的主要区别。证明一个问题具有贪心选择性质也是贪心法的一个难点。
9.5.2 贪心法的典型实例
(1)活动选择问题
(2)多机调度问题
9.6 回溯法
回溯法有“ 通用的解题法 ”之称,用它可以系统地搜索一个问题的所有解或任一解。
回溯法是一个既带有系统性又带有跳跃性的搜索算法。它在包含问题的所有解的解空间树中,按照深度优先的策略,从根节点出发搜索解空间树。算法搜索至解空间树的任一节点时,总是先判断该节点是否肯定不包含问题的解。如果肯定不包含,则跳过对以该节点为根的字数的系统搜索,逐层向其祖先节点回溯;否则,进入该子树,继续按深度优先的策略进行搜索。回溯法在用来求问题的所有解时,要回溯到根,且根节点的所有子树都已被搜索编才结束;而用来求为题的任一解时,只要搜索到问题的一个解就可结束。这种以深度优先的方式系统地搜索问题的解的方法称为回溯法,它适用于解一些组合数较大的问题。
9.6.1 回溯法的算法框架
1. 问题的解空间
应用回溯法解问题时,首先应明确定义问题的解空间。问题的解空间应至少包含问题的一个(最优)解。
2.回溯法的基本思想
确定了解空间的组织结构或,回溯法从开始节点(根节点)出发,以深度优先的方式搜索整个解空间。
这个开始节点就成为一个活节点,同时也称为当前的扩展节点。当前的扩展节点处,搜索向纵深方向移至一个新节点。这个新节点就称为一个新的活节点,并称为当前扩展交界点。如果在当前扩展节点处不能再向纵深方向移动,则当前的扩展节点就称为死节点。话句话说,这个节点不再是一个活节点。此时,应往回移动(回溯)至最近的一个活节点处,并使这个活节点成为当前的扩展节点。回溯法即以这种工作方式递归地在解空间中搜索,直至找到所要求的的解或解空间中无活节点时为止。
综上所述,运用回溯法解题通常包括以下三个步骤:
(1)针对所给问题,定义问题的解空间。
(2)确定易于搜索的解空间结构。
(3)以深度优先的方式搜索解空间。
3. 回溯法的算法框架
回溯法的算法框架有非递归和递归两种方式。
非递归方式:

递归方式:


4. 回溯法的界限函数
问题的解空间往往很大,为了有效的进行搜索,需要在搜索的过程中对某些交界点进行剪枝。面对哪些细节进行剪枝,需要设计界限函数来判断。因此,界限函数的设计是回溯法的一个核心问题,也是一个很难的问题。设计界限函数的通用指导原则是尽可能多和尽可能早地“ 杀掉 ”不可能产生最优解的活节点。好的界限函数可以大大减少问题的搜索空间,从而大大提高算法的效率。下面通过例子来说明。
9.6.2 回溯算法的典型实例
0-1 背包问题
n- 皇后问题
9.7 分支限界法
分支限界法类似于回溯法,也是一种在问题的解空间树 T 上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出 T 中满足的约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
由于求解目标不同,导致分支限界法与回溯法在空间树 T上的搜索方式也不相同。回溯法以深度优先的方式搜索解空间 树 T,而分支限界法的搜索策略是每一个活动节点一次机会成为扩展节点。
活节点一旦称为扩展节点,就一次性产生其所有儿子节点。在这些儿子节点中,那些导致不可行解或非最优解的儿子节点被舍弃,其余儿子节点被加入活节点表中。此后,从活节点表中去下一节点成为当前扩展节点,并重复上述节点扩展过程。这个过程一直持续到所需的解或活节点表空间位置。人们已经利用分支限界法解决了大量离散最优化的实际问题。
与回溯法相似,限界函数的设计是分支限界法的核心问题,也是一个很难的问题。如何设计好限界函数来有效的减少搜索空间是应用分支限界法要考虑的问题。
与回溯法相似,限界函数的设计是分支限界法的一个核心问题,也是一个很难的问题。如何设计好限界函数来有效地减少搜索空间是应用分支限界法要考虑的问题。
从活节点表中选择下一扩展节点的不同方式导致不同的分支限界法。最常用的有以下两种。
(1)队列式(FIFO)分支限界法。
队列式分支限界法将活节点表组织一个队列,并按队列的先进先出原则选择下一个节点作为扩展节点。
(2)优先队列式分支限界法。
优先队列式分支界限法将活节点组成一个优先队列,并按优先队列中规定的节点优先选取优先级最高的下一个节点作为扩展节点。
优先队列中规定的节点优先通常用一个与该节点相关的数值 p 来表示。节点优先级的高低于 p值的大小相关。最大优先队列规定 p 值较大的节点优先级较高。 在算法实现时,通常用一个最大堆来实现最大优先队列,用最大堆的 Deletemax 运算抽取堆中下一个节点称为当前扩展节点。类似地,最小优先队列规定 p 值较小的节点优先级较高。在算法实现时,常用一个最小堆来实现最小优先队列,用最小对的 Deletemin 运算抽取堆中下一个节点称为当前扩展节点。
9.8 概率算法
前面讨论的算法对于所有合理的输入都给出正确的输出,概率算法将这一条放宽,把随机性的选择加入到算法中,在算法执行某些步骤时,可以随机地选择下一步该如何进行,同时允许结果以较小的概率出现错误,并以此为代价,获得算法运行时间的大幅度减少。
概率算法的一个基本特征是对所求解问题的统一实例用同一概率算法求解两次,可能得到完全不同的效果。这两次求解所需的时间甚至所得到的的结果可能会有相当大的差别。如果一个问题没有有效的确定性算法可以在一个合理的时间内给出解,但是该问题能接受小概率错误,那么采用概率算法就可以快速找到这个问题的解。
一般情况下,概率算法具有以下基本特征。
(1)概率算法的输入包括两部分,一部分是原问题的而输入,另一部分是一个供算法进行随机选择的随机数序列。
(2)概率算法在运行过程中,包括一处或多处随机选择,根据随机值来决定算法的运行。
(3)概率算法的结果不能保证一定是正确的,但能限制其出错概率。
(4)概率算法在不同的运行过程中,对于相同的输入实例可以有不同的结果,因此,对于相同的输入实例,概率算法的执行时间可能不同。
概率算法大致分为 4 类:数值概率算法、蒙特卡罗(Monte Carlo)算法、拉斯维加斯(LasVegas)算法和舍伍德(Sherwood)算法。
(1)数值概率算法。
数值概率算法常用语数值问题的求解。这类算法所得到的往往是近似解,且近似解的精度随计算时间的增加不断提高。
在多数情况下,要计算出问题的精确解时不可能的货没有必要的,因此用树枝概率算法可得到相当满意的解。
(2)蒙特卡罗算法。
蒙特卡罗算法用于求问题的精确解。用于蒙特卡罗算法能求得问题的一个解,但这个解未必是正确的。求得正确界的概率依赖于算法所用的时间,所发所用的时间越多,得到正确解的概率越高。蒙特卡罗算法的主要缺点也在于此,一般情况下,无法有效地潘丁丁所得到的的解是否肯定正确。
(3)拉斯维加斯算法。
拉斯维加斯算法不会得到不正确的解。一旦用拉斯维加斯算法找到一个解,这个解就一定是正确解。拉斯维加斯算法找到正确解的概率试着它所用的时间增加而提高。对于所求解问题的任一实例,用同一拉斯维加斯算法反复对该实例求解足够多次,可是求解失效概率任意小。
(4)舍伍德算法。
舍伍德算法总能求得问题的一个解,且所求得的解总是正确的。当一个确定性算法在最坏情况下的计算复杂度与其在平均情况下的计算复杂度有较大差别时,可在这个确定性算法中引入随机性将它改造成一个舍伍德算法,消除或减少问题的好坏实例件的这种差别。舍伍德算法的精髓不是避免算法的最坏情况行为,而是设法消除这种最坏情形行为与特定实例之间的关联性。
9.9 近似算法
迄今为止,所有的难解问题都没有多项式时间算法,采用回溯法和分支限界法等算法设计技术可以相对有效地解决这类问题。然而,这些算法的时间性能常常是无法保证的。近似算法是解决难解问题的一种有效策略,其基本思想是放弃求最优解,而近似最优解代替最优解,以换取算法设计上的简化和时间复杂度的降低。
近似算法是这样一个过程:虽然它可能找不到一个最优解,但它总会与带求解的问题提供一个解。为了具有实用性,近似算法必须能够给出算法所产生的最优解之间的差别或者比例的一个界限,它保证任意一个实例的近似最优解与最优解之间相差的程度。显然,这个差别越小,近似算法越具有实用性。
衡量近似算法性能最重要的标准有两个。
(1)算法的瞬间复杂度。
近似算法的时间复杂度必须是多项式阶的,这是近似算法的基本目标。
(2)解的近似程度。
近似最优解的近似程度也是设计近似算法的重要目标。近似程度与近似算法本身、问题规模,乃至不同的输入实例有关。
几个实例说明近似算法的应用:
1、顶点覆盖问题
2、TSP问题
3、子集和数问题
9.10 NP完整性理论
NP完全问题(NP-C问题),是世界七大数学难题之一。 NP的英文全称是Non-deterministic Polynomial的问题,即多项式复杂程度的非确定性问题。简单的写法是 NP=P?,问题就在这个问号上,到底是NP等于P,还是NP不等于P。
迄今为止,我们接触过大部分算法都是多项式时间算法,它们在最坏情况下的运行时间为![]() ,其中 n 为输入规模,k 为某个常数。我们自然会提出一个问题:是否所有问题都能做多项式时间内解决呢?答案是否定的。
,其中 n 为输入规模,k 为某个常数。我们自然会提出一个问题:是否所有问题都能做多项式时间内解决呢?答案是否定的。
例如存在一些问题,如著名的停机问题,是计算机不论花多少时间都不能解决的。
还有一些问题尽管可以求解,但它们都不能再多项式![]() 的时间内得到解决。
的时间内得到解决。
一般来说,把在多项式时间内的问题看作是容易的问题,而把超过多项式时间才能解决的问题看作是难的问题。
本部分主要介绍 NP 完全性理论,它是研究计算问题难易以及一类特殊的难解问题的理论。
关于 NP 完全性的理论研究是基于某种计算模型针对语言识别问题而进行的,从本节算法的角度给出一种非形式化的简单解释。
1. P 类问题和 NP 类问题
在计算复杂性研究中,经常考虑的是判定问题,因为判定问题可以很容易地表达为语言的识别问题,从而方便地在某种计算模型上进行求解。
1、判定问题。
2、确定性算法。
3、P类问题。
P 类问题是由具有多项式时间的确定性算法来求解的判定问题组成。对于判定问题定义 P 类问题,主要是为了能够给出较为严格的 NP 类问题的定义。事实上,所有易解问题都属于 P类问题。
4、设 A 是求解问题 Ⅱ 的一个算法,如果算法 A 以如下猜测并验证的方式工作,就称算法 A 是非确定性算法。
(1)猜测阶段。
在这个阶段,对问题的输入实例产生一个任意字符串 y,在算法的每一次运行时,串 y 的值可能不同,因此,猜测以一种非确定的形式工作。
(2)验证阶段。
在这个阶段,用一个确定算法验证两件事:
首先,检查在猜测阶段产生的串 y 是否是合适的形式,如果不是,则算法停下来并得到 no:另一方面,如果串 y 是合适的形式,那么算法验证它是否是问题的解,如果是问题的解,则算法停下来并得到 yes,否则算法停下来并得到 no;
5、NP 类问题。
如果对于某个判定问题 Ⅱ,存在一个非负整数 k,对于输入规模为 n的实例,能够以 ![]() 的时间运行一个非确定性算法,得到 yes 或 no 的答案,则该判定问题 Ⅱ 是一个 NP 类问题。
的时间运行一个非确定性算法,得到 yes 或 no 的答案,则该判定问题 Ⅱ 是一个 NP 类问题。
对于 NP 类判定问题,重要的是它必须存在一个确定性算法,能够以多项式时间来检查和验证在猜测阶段所产生的答案。NP类问题是难解问题的一个子类,并不是任何一个在常规计算机上需要指数时间的问题(即难解问题)都是 NP 类问题。
尽管 NP 类问题是对于判定问题定义的,事实上,可以在多项式时间应用非确定性算法解决的所有问题都属于 NP 类问题。综上所述, P 类问题和 NP 类问题的主要差别如下。
(1)P类问题可以用多项式时间的确定性算法来进行判定和求解。
(2) NP 类问题可以用多项式时间的非确定性算法来进行判定或求解。
如果问题 Ⅱ 属于 P类,则存在一个多项式时间的确定性算法来对它进行判定或求解。
显然,对这样的问题 Ⅱ,也可以构造一个多项式的非确定性算法来验证其解的正确性。因此,问题 Ⅱ 也属于 NP类问题,即 P ⊆ NP。反之,如果问题 Ⅱ 属于 NP类,则存在一个多项式时间的非确定性算法来猜测并验证它的解,但是,不一定能够构造一个多项式时间的确定性算法来对它进行求解或判定。因此,人们猜测 P ≠ NP。但是,这个不等式是成立还是不成立,至今没有得到证明。
2、 NP 完全问题
NP 完全问题是 NP 类问题的一个子类,对于这个子类中的任何一个问题,如果能够证明用多项式时间的确定性算法来进行求解或判定,那么,NP 完全问题中的所有问题都可以通过多项式时间的确定性算法来进行求解或判定。
1、问题变换。
有三个定理,不太好理解。
2、NP 完全问题。
NP 完全问题是 NP 类问题中最难的一类问题,其中任何一个问题至今都没有找到多项式时间算法。而且 NP 完全问题有一个中药性质:如果一个 NP 完全问题能在多项式时间内得到解决,那么 NP 完全问题中的每一个问题都可以在多项式时间内求解。尽管已经进行了多年的研究,目前还没有一个 NP 完全问题有多项式时间算法。这些问题也许存在多项式时间算法,因为计算机科学是相对新生的科学,肯定还会有性的算法设计技术有待发现;这些问题也许不存在多项式时间算法,但目前缺乏足够的技术来证明这一点。
已定义了 P 类问题、 NP类问题和 NP完全问题等概念,广义上说, P 类问题是可以用确定性算法在多项式时间内求解的一类问题,NP类问题是可以用非确定性算法在多项式时间猜测并验证的一类问题,而且 P ⊆ NP。
是否存在一些问题属于 NP 类问题而不属于 P 类问题呢?
至今,还没有人能证明是否 P ≠ NP。若 P ≠ NP ,则说明 NP 类中的所有问题,包括 NP 完全问题都不存在多项式时间算法;若 P = NP,则说明 NP 类中的所有问题,包括 NP 完全问题都 具有多项式时间算法。无论哪一种答案,都将为算法设计提供重要的指导和依据。
NP 类问题中还有一些问题,人们还不知道它是属于 P 类问题还是属于 NP 完全问题,这些问题还在等待人么证明它们的归属。这类问题包括图的同构问题和线性规划问题。
3、典型的 NP 完全问题
1971年,Cook 通过 Cook 定理证明了可满足问题(SAT问题)是 NP 完全的。1972 年,Karp 证明了十几个问题都是 NP 完全的。
这些 NP 完全问题的证明思想和技巧,以及利用它们证明的几千个 NP 完全问题,极大地丰富了 NP 完全理论。下面列出的是一些基本的 NP 完全问题。
(1)SAT 问题。
SAT 问题也称为合取范式的可满足问题,来源于许多实际的逻辑推理的应用。
(2)最大团问题。
图G = (V,E)的团是图G的一个完全子图,即子图中任意两个互异的顶点都有一条边相连。团问题是对于给定的无向图 G(G,E)和正整数 k,是否存在具有 k 个顶点的团。
(3)图着色问题。
给定无向连通图 G=(V,E)和正整数 k,是否可以用 k 种颜色对G中的顶点着色,使得任意两个相邻顶点着色不同。
(4)哈密尔顿问题。
在图 G(V,E)中,从某个顶点出发,求经过所有顶点一次且仅一次,再回到出发点的回路。
(5)TSP 问题。
给定带权图 G = (V,E)和正整数 k,是否存在一条哈密尔顿回路,其路径长度小于 k。
(6)顶点覆盖问题。
设图 G(V,E),V‘ 是顶点 V 的子集,若图 G 的任一条边至少有一个顶点 属于 V’,则称为 图 G的顶点覆盖。
顶点覆盖问题是对于图G(V,E)和正整数 k,是否存在顶点 V的一个子集 V’,使得图 G的任一条边至少有一个顶点 属于 V’,且|V’|≤ k。
(7)最长路径问题。
给定一个带权图 G=(G,E)和一个正整数 k,对于图 G中的任意两个顶点 vi,vj∈ V(1≤ n,i≠j),是否存在从顶点 vi到顶点vj的长度大于k的简单路径。
(8)子集和问题。
给定一个整数集合 S 和一个正整数 k,判断是否存在 S的一个子集 S’,使得 S’中整数的和 为 k。

