
- 1codemirror6 制作markdown编辑器(源码模式)_codemirror markdown
- 2Python彩色图像卷积特征提取——边缘提取_python图像边缘提取
- 3Gap Statistic算法详解
- 4数据可视化分析大屏全屏系统地图应用之福建福州地图_福建可视化大屏
- 5grpc java helloworld 简单demo实现_grpc 没有hellojava类
- 6postgresql 日志参数相关配置解析_log_destination
- 7本地部署github上的stable diffuion,轻松玩转ai绘画(新手小白也能懂)_github ai绘画
- 8SQLServer无法打开用户默认数据库 登录失败错误4064的解决方法_sqlserver 4064
- 9TimeGPT:时间序列预测模型实例
- 10保存mongodb数据时出现_class字段,应该如何去掉
在亚马逊云科技Amazon SageMaker上使用vLLM框架进行Rolling Batch推理优化的部署实践_vllm 模型推理部署 并行
赞
踩
业务场景&背景介绍
对于LLM推理的GenAI实际生产应用,其推理的时延和吞吐量是非常重要的性能指标。一方面推理输出的响应时间(时延)越短,客户端的体验越好;一方面同样的时间GenAI应用能推理生成的tokens数量越多,则意味着同样资源开销下吞吐量更大,其性价比更高。
然而这两点在实施落地上却是痛点和难点,因为对于动则几十上百亿参数的LLM模型,其推理生成时GPU显存和计算的成本非常高,而且很多场景,如文案生成、报告解读等,输入的token长度和输出的token长度都超过1K甚至达到10K。tokens的长度直接关系到LLM推理计算时资源的开销(光加载一个token大概需要1M显存,1K token即消耗1G显存),这还没有考虑用户请求量激增,并发量增长的时候,如何在资源有限的情况下,尽可能地增加处理吞吐量,同时控制响应时延。这是摆在GenAI生产落地层面的现实问题。
本文介绍了近期业界新的Rolling Batch(continually batch)的批处理推理优化技术原理,并给出了在亚马逊云科技Amazon SageMaker上使用vLLM框架进行Rolling Batch推理优化的实践和测试对比,可以帮助客户在实际生产场景中通过简单配置,立竿见影地提升线上部署的LLM的推理吞吐量,降低响应时延,节省资源。
Rolling Batch原理
对于LLM推理优化,通常想到的通过量化、自定义CUDA内核等方式进行优化的“黑盒”。然而,情况并非完全如此。
LLM推理是内存IO约束,而不是计算约束。换句话说,目前将1MB数据加载到GPU的计算核心上所花费的时间比这些计算核心对1MB数据进行LLM计算所花费的时间要多。这意味着LLM推理吞吐量在很大程度上取决于您可以在高带宽GPU内存中适应多大的批处理量。所以当我们使用批处理优化的时候,在实际工作负载中可产生10倍或更多的令人惊讶的性能差异。
批处理优化简单来说,是指您不必每次有输入序列时都加载新的模型参数,而是一次加载模型参数,然后使用它们来处理多个输入序列。这更有效地利用了芯片的内存带宽,从而提高了计算利用率、提高了吞吐量、降低了LLM推理的成本。
刚才提到的一次性批量处理,就是我们常说的batch方式,传统的批处理方法为静态批处理,因为批大小在推理完成之前保持不变,静态batch示意图如下所示:
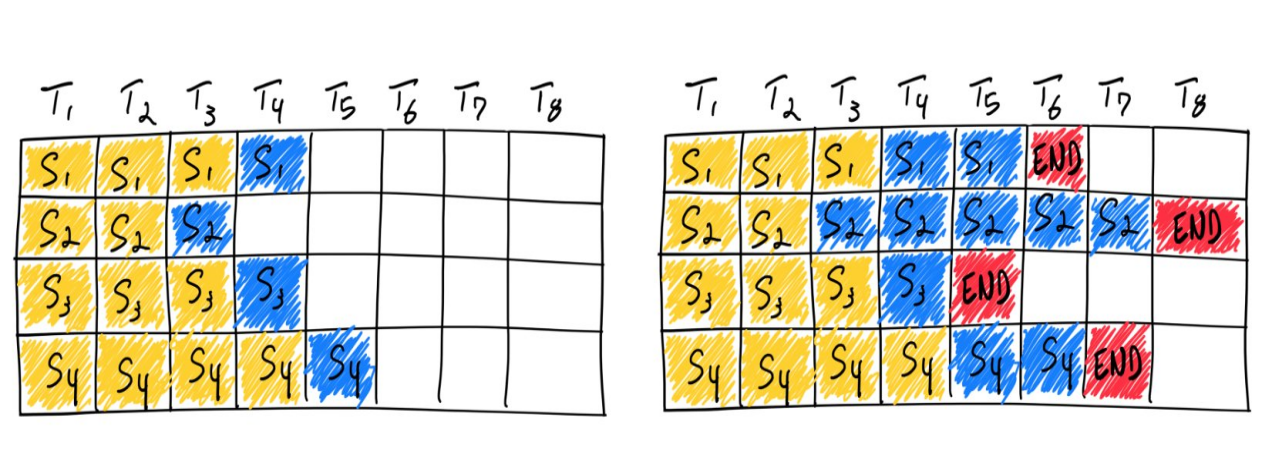
可以看到LLM推理服务器端将多个推理请求打包,并作为一个批次一次性交给模型的pipeline或者tokenization统一批处理,当所有推理请求完成后,统一输出给客户调用端,这样的批量处理技术利用了GPU批量加载token的优势,很大程度上提升了吞吐性能,但存在明显的缺陷:
-
批处理的窗口大小在推理完成之前是保持不变的(比如batch size为16,一次性处理16个prompt推理请求),但单个请求可能提前“完成”(比如S3),这时候整个资源是不能释放的,因为需要等待最长prompt推理的output输出(比如S2)。这意味着其吞吐是GPU在批次跟多条prompt中的最大生成长度正相关。
-
另外输出到客户端的是一个batch数组,客户端程序需要处理多个prompt的输出,并且需要指定最大的等待时间,比如2s,这样即便某个prompt请求1s即可完成,客户端仍然会等待到2s的批次打包窗口时间,才能交由server端打包该批次的推理处理。
近期业界逐渐转向动态batch,它对于提高并发,降低响应时延,有更高性价比的场景,相对于静态batch数倍的性能提升,也就是本文中重点介绍的Rolling Batch技术,Rolling Batch技术原理图如下所示:

如上图所示,动态batch(Rolling Batch,也叫Continually Batch)不是等待批次中的每个序列完成生成,而是实现迭代级调度,其中批量大小由每次迭代决定。结果是,一旦批处理中的序列完成生成,就可以在其位置插入新序列,从而产生比静态批处理更高的GPU利用率。
当多个prompt请求到达时,LLM推理服务器端执行Iteration级别batch,每当一个output token生成,则会检测整个处理队列,当发现有prompt请求已经有结束生成(EOS token id),则自动调度,拉取新的prompt请求的input token填充,不会等待其他prompt未完成的生成过程,整个过程不断循环,也没有静态batch中的打包等待时间。
Rolling Batch框架
实现Rolling Batch的框架有如下关键的功能:
-
服务端需要实现网络监听,持续接收客户端请求并不断加入到请求队列;并且检测推理的每个step,当发现某个prompt请求结束的EOS token id时,调度并填充新的prompt请求填充;另外在计算层面,Rolling Batch在一个sequence里面要同时计算不同prompt请求的prefilling tokens(输入token)和completion tokens(输出token),这二者计算方式是不一样的。
-
除此之外,continually batch还能够解锁新的paged attention的功能,因为连续的batch,在每次iteration的时候可以分配非连续的显存给下一个填充的input sequence token,意味着不需要像常规batch时固定分配连续显存,提高显存利用率。
-
最后,continually batch还能和stream流式输出结合,因为每个step都是iteration级别的,即每次处理都可以输出一个prompt请求的token,则在服务端可以把每次生成的token都放到输出队列并向客户端推送,即使其没有生成完成,只需要标记uncompletion的request id对应关系。
目前支持Rolling Batch的服务端推理框架主要有HF的text generation inference和vLLM,本文重点介绍业界知名度较高的vLLM框架的Rolling Batch实现。
vLLM是UC伯克利团队开发的一个开源的LLM推理和服务引擎,它实现了上文提到的Rolling Batch批处理以及PagedAttention的全新的注意力算法,相对于静态batch,vLLM提供了高达数十倍的吞吐量,而无需进行任何模型架构更改,详细内容可以参考vLLM官方站点。
本文简单讲解vLLM框架的核心代码,帮助理解其Rolling Batch的具体实现。
vLLM提供了两类推理的实现,一类是offline inference,类似于HF pipeline的batch推理接口,用于离线批量的推理生成;一类是和openai api类似的实时在线推理,用于服务端接收并发推理请求的应用部署,其本身也可以通过命令行拉起一个web服务端进行部署。
vLLM框架offline inference
vLLM的offline inference首先使用LLM的接口初始化离线推理的LLMEngine引擎类型,使用model路径参数加载模型,使用SamplingParams传递推理参数,再通过generate推理接口,对传入的多条prompt请求进行批量推理。
vLLM框架online inference
vLLM的在线推理接口与刚才的离线推理接口不同,是面向web应用服务器端的api推理接口,用户通常使用vLLM提供的api server命令行工具拉起应用服务器,该服务器会循环监听在线实时请求的到达,对到达的请求不断进行Rolling Batch的推理迭代,每次iteration迭代后,检测sequences队列是否有完成的sequence(eos),如有则输出,并继续填充新的prompt inputs。
这部分web服务端的实现是典型的异步调用方式,NIO非阻塞多路复用,vLLM是使用python coroutine协程技术来处理的。
Rolling batch on SageMaker的使用
SageMaker推理容器同时支持HuggingFace的TGI和vLLM两种动态batch框架,本文着重介绍vLLM框架在SageMaker上的使用。
SageMaker使用Large Model Inference(LMI)容器inference时,直接调用了vLLM engine的step api,每次iteration迭代逐个输出token到输出队列,并调用vLLM状态api判断单条request请求是否结束,如果结束则标记并清理。
用户可以通过配置化方式,轻松实现推理服务器上的Rolling Batch推理调用,不需要安装及部署vLLM库及开发封装vLLM engine的服务器端应用,且自动enable vLLM的paging attention关注度优化等功能。
SageMaker LMI容器镜像配置及使用
LMI vLLM的容器镜像配置在SageMaker上很简洁方便,SageMaker上通过image_uris SDK指定LMI对应的镜像版本。
客户端调用
如上文所述,Rolling Batch下的客户端推理调用不用等待静态batch打包,及处理输出的数组,正常单次调用,单次返回结果即可。
我们用了3个客户端并发线程,对三个prompt并行请求vLLM的SageMaker Endpoint服务端,结果显示3并发几乎同时返回,平均响应时间在7,8s左右,验证了Rolling Batch不需要客户端等待静态batch打包输出及处理数组返回。
我们再用8个prompt并发请求,同样的vLLM SageMaker Endpoint服务端进行测试:
可以看到请求结果,延迟增长了一点(14.7s),但是吞吐量增加明显(8*300 new tokens vs 4*300 new tokens),发挥出了Rolling Batch的优势。
同时,SageMaker的LMI推理镜像封装了流式输出的功能,如果配置为流式输出,则LMI容器会向客户端推送单个的token,客户端调用SageMaker的invoke stream api即可获得vLLM rolling batch的单个token结果,客户端可以像openai stream api方式迭代接收服务端输出的chunk片段序列,并逐个展示,进一步增强客户体验。
只需要调用invoke_endpoint_with_response_stream接口,SageMaker vLLM LMI会自动封装Rolling Batch的每次迭代输出token,并推送到response响应输出,该响应输出是一个python迭代器,客户端遍历该event_stream,即可获取每次流式生产的tokens。
可以看到,流式调用Rolling Batch时,第一个token生成只用了2s即可以在客户端输出,和openai stream接口一样的客户体验,并且整个3个prompt并发推理在10s左右,和刚才的压测延迟基本一致,延续了Rolling Batch的高吞吐性能,一举两得。
性能压测对比
我们使用Python Parallel并发库,模拟生产线上多用户prompt请求的并发场景,使用g5.12xlarge(A10,4卡,24G显存)机器,vLLM SageMaker LMI推理镜像,部署llama2 13b模型进行推理请求。
我们同样使用Python Parallel库,并发多线程请求部署vLLM的SageMaker endpoint终端节点,通过多个线程并行处理多个prompt输入,模拟多用户客户端的实时请求。
没有并发时,响应时延为7.9s,输出37tokens/s左右
当并发增加到4,延迟只增加了2s左右,但吞吐量增加到106 tokens/s
当并发再增加到8,延迟为14.9s,吞吐量为171 tokens/s
并发增加到16,延迟为22.4s,吞吐218 tokens/s
可以明显看到Rolling Batch的吞吐量性能,当并发增长,服务端batch越大,优势越明显。
以下为详细的机型,input token length,max new token length,在不同并发请求场景下,benchmark的响应时延和吞吐量(tokens/s)的情况:

总结
本文介绍了近期业界新的Rolling Batch(Continually Batch)的批处理推理优化技术原理,讲解了vLLM框架Rolling Batch的具体实现的核心代码,以及在Amazon SageMaker上使用vLLM框架进行Rolling Batch推理优化的部署实践,并给出了不同并发下的benchmark测试对比。客户在实际生产场景中可以参考本文中的配置及压测性能,使用SageMaker vLLM部署方案显著提升线上部署的LLM的推理吞吐量,降低响应时延,降低TCO。

