
- 1新魔百和M301H_关于CW代工_JL(南传)代工_zn及sm代工区分及鸿蒙架构全网通卡刷包刷机教程_m301h刷机
- 2ajax请求报parsererror错误_ajax parsererror是什么错误
- 3云端技术驾驭DAY15——ClusterIP服务、Ingress服务、Dashboard插件、k8s角色的认证与授权
- 4kubeCon2020重磅演讲:基于k8s构建新一代私有云和容器云_captain k8s
- 5HTML+CSS:3D轮播卡片
- 6Python+医学院校二手书管理 毕业设计-附源码201704_基于python的校园二手交易平台论文开题报告
- 7python函数递归求和详解_Python函数中多类型传值和冗余参数及函数的递归调用
- 8【毕业设计】ASP.NET 网上选课系统的设计与实现(源代码+论文)_aspnet毕业设计含代码
- 9Stable Diffusion提示词总结_stable diffusion 提示词详解
- 10玩转k8s:Pod详解_k8s pod配置文件查看
机器视觉【基础】什么是机器视觉?_what is computer vision
赞
踩
前言:本文尝试由繁到简论述机器视觉的定义和发展历程:
1 什么是机器视觉

What is Computer Vision? Computer Vision has a dual goal.
From the biological science point of view, computer vision aims to come up with computational models of the human visual system.
From the engineering point of view, computer vision aims to build autonomous systems which could perform some of the tasks which the human visual system can perform (and even surpass it in many cases). Many vision tasks are related to the extraction of 3D and temporal information from time-varying 2D data such as obtained by one or more television cameras, and more generally the understanding of such dynamic scenes. Of course, the two goals are intimately related. The properties and characteristics of the human visual system often give inspiration to engineers who are designing computer vision systems. Conversely, computer vision algorithms can offer insights into how the human visual system works. In this paper we shall adopt the engineering point of view.
2 机器视觉发展历史:
2.1 1950s
To understand where we are today in the field of computer vision, it is important to know the history and the key milestones that shaped this rapidly evolving field. The field of computer vision emerged in the 1950s with research along three distinct lines. Replicating the eye, replicating the visual cortex and replicating the rest of the brain. These are cited in order according to their level of difficulty. One early breakthrough came in 1957 in the form of the Perceptron machine. The giant machine tightly tangled with wires was the invention of psychologist and computer vision pioneer, Frank Rosenblatt. Then the same year marked the birth of the pixel. In the spring of 1957, the National Bureau of Standards Scientists, Russell Kirsch, took a photo of his son Walden and scanned it into the computer. To fit the image into computer's limited memory, he divided the picture into a grid. This five centimeters square photo was the first digital image ever created.
2.2 1960s
In 1963, MIT graduate students, Larry, Roberts, submitted a PhD thesis outlining how machines can preserve solid three-dimensional objects by breaking them down into simple two-dimensional figures. Robert's block, well, provided the basis for future computer vision research. Another key moment in the field of computer vision was the founding of the Artificial Intelligence Lab at MIT. One of the co-founders was Marvin Minsky who famously instructed a graduate student in 1966 to connect a camera to a computer and have it describe what it sees, as a summer project. Fast forward, 50 years and we're still working on it. Around the time, ARPANET went live in the fall of 1969. Bell Lab scientists Willard Boyle and George Smith were busy inventing the charge-coupled device, the CCD, which converted photons into electrical impulses, quickly became the preferred technology for capturing high-quality digital images. In October 2009, they were awarded the Nobel Prize in physics for their invention.
2.2 1970s
The 70s saw the first commercial applications of computer vision technology, which is optical character recognition or OCR. Studies in the 1970s form the early foundations for many of the computer vision algorithms that exists today, including extraction of edges from images, labeling of lines, modeling and representations of objects as interconnections of smaller structures, optical flow, and motion estimation. The first commercial digital camera appeared in 1975. The next decade saw studies based on more rigorous mathematical analysis and quantitative aspects of computer vision.
2.3 1980s
2.4 1990s
projective 3D reconstructions
By the 1990s, research in projective 3D reconstructions led to better understanding of camera calibration. This evolved to methods of sparse 3D reconstructions of scenes from multiple images. Progress was being made in the field of stereo imaging and multi-view stereo techniques. At the same time, variations of graph cut algorithms were used to solve image segmentation, which enabled higher level interpretation of the coherent regions of images. This decade also marked the first time statistical learning techniques were used in practice to recognize faces. Toward the end of 1990s, a significant change came about with the increased interaction between the field of computer graphics and computer vision. This included image-based rendering, image morphing, view interpolation, panoramic image stitching and early light-field rendering. In 2001, two computer scientists, Paul Viola and Michael Jones, triggered a revolution in the field of face detection, which brought computer vision into the spotlight. Later, the face detection framework was successfully incorporated in digital cameras. In 2004, David Lowe published the famous Scale Invariant Feature Transform, which is the breakthrough solution to the correspondence problem. Neural networks got their game on in 2005, where training them was made multiple times faster, much cheaper and more accurate by using off the shelf GPUs, popularly used in gaming consoles. Progress in the field of computer vision accelerated further due to the Internet, thanks to the larger annotated datasets of images becoming available online. The datasets helped drive the field forward by proposing difficult challenges. They also contributed to the rapid growth in importance of learning methods and they helped benchmark and rank computer vision techniques. The ImageNet project started in 2009, which is a large visual database designed for use in visual object recognition software research. Since 2010, the ImageNet Large Scale which will challenge has pitted people against computers to see who does a better job of identifying images. It is not an exaggeration to say that the artificial intelligence boom we see today could be attributed to a single event, the announcement of the 2012 ImageNet challenge results. A research team from University of Toronto submitted a deep convolutional neural network architecture called AlexNet, still used in research to this day, which bet the state of the art back then by a whopping 10.8 percentage point margin. Convolutional neural networks later became the neural network of choice for many data scientists, as it requires very little pre-programming compared to other image processing algorithms. In the last few years, CNNs have been successfully applied to identify faces, objects and traffic signs as well as powering vision in robots and self-driving cars. In 2014, a team of researchers at the University of Montreal introduced the idea that machines can learn faster by having two neural networks compete against each other. One network attempts to generate fake data that looks like the real thing and the other network tries to discriminate the fake from the real. Over time, both networks improve. The generator produces data so real that the discriminator can't tell the difference. Generative adversarial networks are considered a significant breakthrough in computer vision in the past few years. In 2015, Facebook announced that the DeepFace facial recognition algorithm identifies the current person 97.35 percent of the time, putting it more or less on par with humans. While computer vision was barely mentioned in the news before 2015, the news coverage about the topic grew by more than 500 percent since then. Today, we see computer vision related news in the media quite often. Let us have a look at few media articles in the recent times.
参考:
1 机器视觉历史
2 机器视觉时间线
https://www.verdict.co.uk/computer-vision-timeline/
More than 50 years ago Marvin Minsky made the first attempt to mimic the human brain, triggering further research into computers’ ability to process information to make intelligent decisions. Over the years, the process of automating image analysis led to the programming of algorithms. However, it was only from 2010 onward, when there was acceleration in deep learning techniques. In 2012 Google Brain built a neural network of 16,000 computer processors which could recognise pictures of cats using a deep learning algorithm.
Listed below are the major milestones in the computer vision theme, as identified by GlobalData.
1959 – The first digital image scanner was invented by transforming images into grids of numbers.
1963 – Larry Roberts, the father of CV, described the process of deriving 3D info about solid objects from 2D photographs.
1966 – Marvin Minksy instructed a graduate student to connect a camera to a computer and have it described what it sees.
1980 – Kunihiko Fukushima built the ‘neocognitron’, the precursor of modern Convolutional Neural Networks.
1991-93 – Multiplex recording devices were introduced, together with cover video surveillance for ATM machines.
2001 – Two researchers at MIT introduced the first face detection framework (Viola-Jones) that works in real-time.
2009 – Google started testing robot cars on roads.
2010 – Google released Goggles, an image recognition app for searches based on pictures taken by mobile devices.
2010 – To help tag photos, Facebook began using facial recognition.
2011 – Facial recognition was used to help confirm the identity of Osama bin Laden after he is killed in a US raid.
2012 – Google Brain’s neural network recognized pictures of cats using a deep learning algorithm.
2015 – Google launched open-source Machine learning-system TensorFlow.
2016 – Google DeepMind’s AlphaGo algorithm beat the world Go champion.
2017 – Waymo sued Uber for allegedly stealing trade secrets.
2017 – Apple released the iPhone X in 2017, advertising face recognition as one of its primary new features.
2018 – Alibaba’s AI model scored better than humans in a Stanford University reading and comprehension test.
2018 – Amazon sold its real time face recognition system Rekognition to police departments.
2019 – The Indian government announced a facial recognition plan allowing police officers to search images through mobile app.
2019 – The US added four of China’s leading AI start-ups to a trade blacklist.
2019 – The UK High Court ruled that the use of automatic facial recognition technology to search for people in crowds is lawful.
2020 – Intel will launch the Intel Xe graphics card pushing into the GPU market.
2025 – By this time, regulation in FR will significantly diverge between China and US/Europe.
2030 – At least 60% of countries globally will be using AI surveillance technology (it is currently 43% according to CEIP).
This is an edited extract from the Computer Vision – Thematic Research report produced by GlobalData Thematic Research.
3 https://computer-vision-ai.com/blog/computer-vision-history/
To track the key dates in computer vision history, one should be ready to learn a lot about the boom of technologies in the 20th century in general. Computer vision was once considered a futuristic dream. Then it was labeled as a slowly emerging technology. Today, computer vision is an established interdisciplinary field.
The history of computer vision is a telling example of how one science can impact other fields over a short period of time. Computer vision made image processing, photogrammetry, and computer graphics possible. On top of that, the history of computer vision demonstrates how spheres remotely related to computers get influenced too. For instance, modern computer vision algorithms help to facilitate agriculture, retail shopping, post services etc.
In this post, we have decided to shed light on how computer vision evolved as a science. The main question we have raised is “Who and how contributed to the growth of computer vision technology?” To answer this question, we have prepared a short overview of milestones in computer vision history in the chronological order. Get ready to discover why the first attempt to teach computers to “see” were doomed. Also, we will examine the most influential works in computer vision published in the 20th century. Feel free to join us if you are a professional computer vision developer or just as an enthusiastic admirer of computers!
First Success (the 1950s – 1960s)
Constructing computer vision systems seemed to be an unrealistic task for scientists at the beginning of the 20th century. Neither engineers nor data analysts were fully equipped to extract information from images, let alone videos. As a result, the very idea of information being transformed into editable and systemized data seemed unrealistic. In practice, it meant that all image recognition services, including space imagery and X-rays analysis, demanded a manual tagging

(Source – Brain Wars: Minsky vs. Rosenblatt)
A group of scholars led by Allen Newell was also interested in the investigation the connection between an electronic device and data analysis. The group included Herbert Simon, John McCarthy, Marvin Minsky, and Arthur Samuel. Together, these scientists managed to come up with the first AI programs, for instance, the Logic Theorist and the General Problem Solver. These programs were used to teach computers to play checkers, speak English, and solve simple mathematical tasks. Inspired by the achieved results, the scholars got over-enthusiastic about the potential of computers. The famous Summer Vision Project is a telling example of how unrealistic most expectations about computer vision were back in the 1960s.

(Source – Vision memo)
Another important name in the history of computer vision is Larry Roberts. In his thesis ”Machine perception of three-dimensional solids” (issued in 1963), Roberts outlined basic ideas about how one could extract 3D information from 2D imagery. Known for his “block-centered” approach, Roberts laid down the foundations for further research on computer vision technology.

(Source – Machine Perception Of Three-Dimensional Solids)
The potential of computers and artificial intelligence (aka AI) mesmerized the scientific community in the middle of the 20th century. As a result, more computer labs got funded. That was mostly done by the Department of Defense of the USA). However, the goals that scientists set during the 1960s were too ambitious. They included the full discovery of an advanced computer vision technology, professional and mistake-free machine translation. There is no wonder why quite soon (already in the mid-1970s), the boom caused by AI research in general and computer vision studies, in particular, started to fade. The growing criticism of the AI and computer vision technology resulted in the first ”AI winter”.
Computer Vision History: AI Winter (1970s)
AI winter is a term used to describe a time when AI research was criticized and underfunded. There were several reasons why computer-related studies underwent a skeptical analysis in the 1970s, namely:
- Too high and often unrealistic expectations about the potential of AI and computer vision. Some of the goals set at the time are still to be reached. Needless to say, the research in AI and computer vision slowed down. That is because of the military, commercial, and philosophical pressure.
- The lack of scientific support on an international level. Although the computer vision laboratories started to appear already in the 1960s, mostly computer vision scholars worked as individuals and isolated groups.
- Imperfect computing capacity. As any data analysis implies processing huge amounts of images, characters, and videos, this analysis can be performed only on advanced devices with relatively high computing capacity.
All the above-mentioned factors combined led to a decrease in the quantity and quality of computer vision studies.
Despite the sharp cutback in the research, the 1970s are also marked as years when computer vision got its first recognition as a commercial field. In 1974, Kurzweil Computer Products offered their first optical character recognition (aka OCR) program. This program was aimed at overcoming the handicap of blindness. That was done by giving free access to media printed in any font. Sure thing, the intelligent character recognition quickly won the attention of the public sector. Moreover, it was used by the industries, and individual researchers.

(Source – People of the Assoc. for Computing Machinery: Ray Kurzweil)
Computer Vision History: Vision by Marr (1980s)
One of the main advocates of computer vision was David Marr. Thanks to his “Vision. A Computational Investigation into the Human Representation and Processing of Visual Information”, published in 1982 posthumously, computer vision was brought to a whole new level.
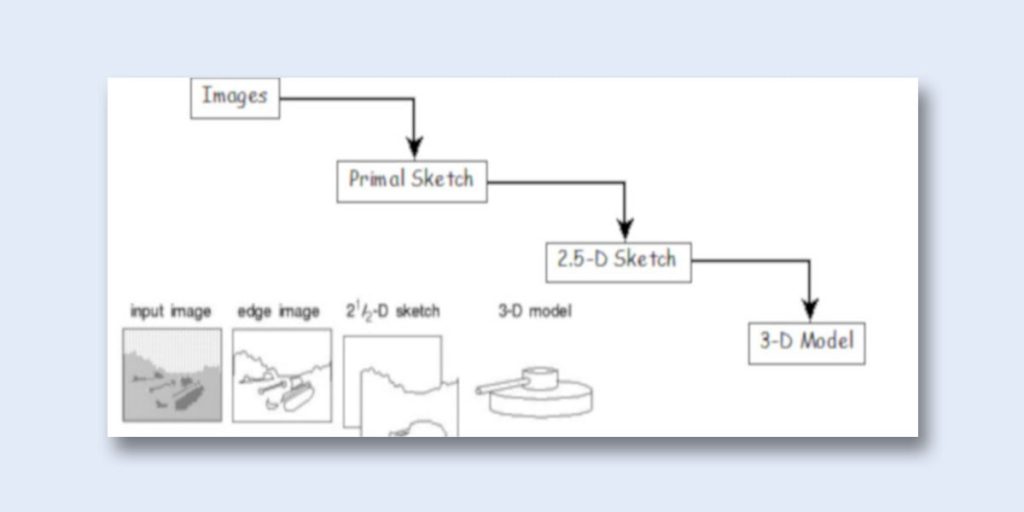
(Source – Vision: Marr Lecture Index)
What Marr offered was a simple and elegant way to create 3D sketches from 2D (and 2.5D) sketches of an image. During the first stage of computer vision analysis, Marr was applying edge detection and image segmentation techniques to an initial image in order to create 2D models or so-called “primal sketches”. After that, these primal sketches were further processed with a help of binocular stereo to get 2.5D sketches. The final stage of Marr’s analysis was about developing 3D models out of the 2.5D images.
In spite of the fact that modern computer vision scientists consider Marr’s approach to be too complicated and not goal driven, his work remains one of the biggest breakthroughs in the history of computer vision.
Mathematical Tools (the 1990s – until today)

With computers getting cheaper and quicker and the amount of data constantly increasing, computer vision history took a turn towards mathematical algorithms. Most modern studies on computer vision apply linear algebra, projective and differential geometry, as well as statistics to solve numerous tasks connected with image and video recognition and 3D modeling.
A telling example how computer vision is influenced by mathematics these days is the eigenface approach. Using the covariance matrix (a mathematics term) and findings of L. Sirovich and M. Kirby (1987), Matthew Turk and Alex Pentland created the eigenface automated face recognition system. Based on the probability theory and statistics, this system can be applied not only to identify the existing faces but also to generate new ones.
Lucas-Kanade method is one more example of how computer vision history is connected with mathematics. Developed by Bruce D. Lucas and Takeo Kanade, this method argues that pixels in the neighborhood are constant and dependant on each other. This is why it makes sense to identify the contents of an image by using the optical flow equation.
John F. Canny is another scholar who managed to make a solid contribution to the history of computer vision. He developed the Canny edge detector, the instrument that helps to identify a vast majority of image edges easily.

(Source – Canny edge detector demos)
As computer vision technology is getting comparatively inexpensive, more enterprises have implemented this technology in the manufacturing cycles. Computers are trained to scan products to check their quality, sort mail, and tag images and videos. Almost any phase of manufacturing can be tracked with a help of industrial machine vision technology.
However, as computer vision history demonstrates, human interference is still needed to train computers when it comes to image tagging and video tracking. To tag, sort, and identify both stable images and moving objects, any computer vision system has to be given enough examples, already marked and categorized. In other words, the future when computers take over the world is a bit more distant than it may seem for an average computer enthusiast.
https://www.phase1vision.com/resources/timeline


