
- 1“access denied for user ‘root‘@‘localhost‘_phpmyadmin root
- 2精品微信小程序基于Uniapp+springboot基于微信小程序的摄影平台设计与实现|计算机毕业设计|Java毕业设计|课程设计|Python毕设|小程序|毕业设计推荐_基于微信小程序的摄影作品交流平台
- 3探讨生产环境下缓存雪崩的几种场景及解决方案_生产环境的redis、雪崩
- 4Android开发 8.0及以上调用相机/相册,并根据Uri获取图像绝对路径,并进行文件上传_android.media.action.image_capture
- 5Java加密与解密的艺术~AES-GCM-NoPadding实现_aes/gcm/nopadding
- 6【C++】【C++ Primer】9-顺序容器_yaml::const_iterator 是有序的吗?
- 7Linux/Unix解压缩unzip命令_unzip -oq
- 8Python学习笔记(十九)——Matplotlib入门_import matplotlib
- 9神经网络系列---池化
- 10Android Studio:如何修改JDK版本和获知使用的Java版本_android studio jdk
B站elasticsearch相关学习_b站elastic search推荐
赞
踩
黑马程序员大数据教程丨快速掌握上手ElasticStack技术栈_哔哩哔哩_bilibili
Elastic Search的简介
- ES是一个企业级的、近实时的全文检索引擎,性能很优秀,是目前全世界最受欢迎的全文检索引擎
- 实时性要比Solr好
- ES是基于Lucene开发的(Lucene是道格卡丁开发),ES基于Lucene之上做了很多扩展,Lucene是单机,而ES是分布式(优势的)
- ES应用场景
-
- 企业级检索
- 分析(支持不太复杂的一些业务分析,支持SQL、支持聚合计算)
-
- 日志运维(企业中的一些运维人员可以根据ES中的日志来快速排错)
- 作为传统数据库的补充(因为它非常擅长检索,可以结合Mysql来使用)
- ElasticStack(ELK):现在的组件越来越多
-
- Beats(FileBeat、MertricBeat、WinlogBeat)
- Logstash (数据采集、实时数据采集)
-
- Kibana(可视化工具)
看完这篇文章,再也不怕 Elasticsearch 索引设计_检索
当然一个索引很大的话,数据写入和查询性能都会变差。而高效检索体现在:基于日期的检索可以直接检索对应日期的索引,无形中缩减了很大的数据规模。
比如检索:“2019-02-01”号的数据,之前的检索会是在一个月甚至更大体量的索引中进行。
现在直接检索"index_2019-02-01"的索引,效率提升好几倍。
索引增量更新原理
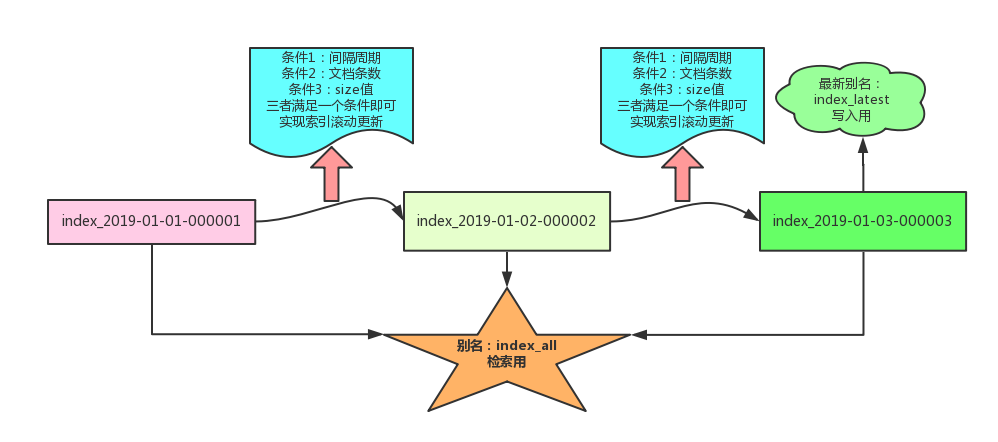
别名删除和新增操作举例:
POST /_aliases{
"actions" : [
{ "remove" :
{ "index" : "index_2019-01-01-000001", "alias" : "index_latest" }
},
{ "add" :
{ "index" : "index_2019-01-02-000002", "alias" : "index_latest" }
}
]
}
使用 curator 高效清理历史数据
目的:按照日期定期删除、归档历史数据。
一个大索引的数据删除方式只能使用 delete_by_query,由于 ES 中使用更新版本机制。删除索引后,由于没有物理删除,磁盘存储信息会不减反增。有同学就反馈 500GB+ 的索引 delete_by_query 导致负载增高的情况。
而按照日期划分索引后,不需要的历史数据可以做如下的处理。
- 删除——对应 delete 索引操作。
- 压缩 —— 对应 shrink 操作。
- 段合并 —— 对应 force_merge 操作。
而这一切,可以借助:curator 工具通过简单的配置文件结合定义任务 crontab 一键实现。
注意:7.X高版本借助iLM实现更为简单。
举例,一键删除 30 天前的历史数据:
cat action.yml actions:1: action: delete_indicesdeion: >-Delete indices older than 30days (based onindex name), forlogstash- prefixed indices. Ignore the error ifthe filter does not result inan actionable list of indices( ignore_empty_list) and exit cleanly. options:ignore_empty_list: Truedisable_action: Falsefilters:- filtertype: patternkind: prefixvalue: logs_ - filtertype: agesource: namedirection: oldertimestring: '%Y.%m.%d'unit: daysunit_count: 30
- 1、分片:分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
数据切分分片的主要目的:
(1)水平分割/缩放内容量 。
(2)跨分片(可能在多个节点上)分布和并行化操作,提高性能/吞吐量。
注意:分片一旦创建,不可以修改大小。
- 2、副本:它在分片/节点出现故障时提供高可用性。
副本的好处:因为可以在所有副本上并行执行搜索——因此扩展了搜索量/吞吐量。
注意:副本分片与主分片存储在集群中不同的节点。副本的大小可以通过:number_of_replicas动态修改。
ES 支持增加字段 //新增字段
PUT new_index{"mappings": {"_doc": {"properties": {"status_code": {"type": "keyword"}}}}}
ES 不支持直接删除字段
ES 不支持直接修改字段
ES 不支持直接修改字段类型如果非要做灵活设计,ES 有其他方案可以替换,借助reindex。但是数据量大会有性能问题,建议设计阶段综合权衡考虑。
Mapping 字段的设置流程
索引分为静态 Mapping(自定义字段)+动态 Mapping(ES 自动根据导入数据适配)。
实战业务场景建议:选用静态 Mapping,根据业务类型自己定义字段类型。
好处:
- 可控;
- 节省存储空间(默认 string 是 text+keyword,实际业务不一定需要)。
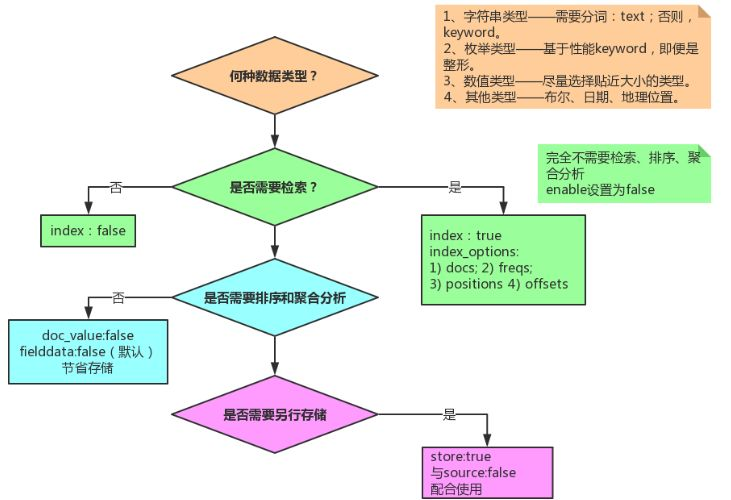
设置字段的时候,务必过一下如下图示的流程。根据实际业务需要,主要关注点:
- 数据类型选型;
- 是否需要检索;
- 是否需要排序+聚合分析;
- 是否需要另行存储。
设置字段:
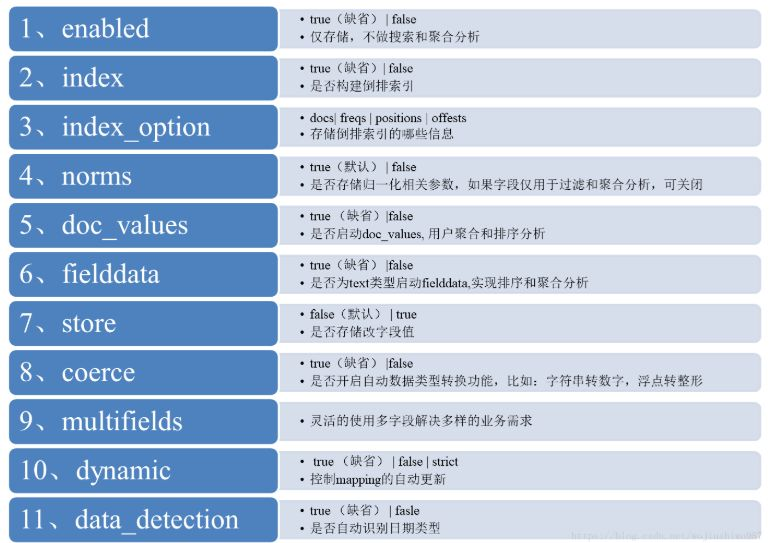
核心参数的含义:
Mapping 建议结合模板定义
索引 Templates——索引模板允许您定义在创建新索引时自动应用的模板。模板包括settings和Mappings以及控制是否应将模板应用于新索引。
注意:模板仅在索引创建时应用。更改模板不会对现有索引产生影响。
第1部分也有说明,针对大索引,使用模板是必须的。核心需要设置的setting(仅列举了实战中最常用、可以动态修改的)如下:
- index.numberofreplicas 每个主分片具有的副本数。默认为 1(7.X 版本,低于 7.X 为 5)。
- index.maxresultwindow 深度分页 rom + size 的最大值—— 默认为 10000。
- index.refresh_interval默认 1s:代表最快 1s 搜索可见;
写入时候建议设置为 -1,提高写入性能;
实战业务如果对实时性要求不高,建议设置为 30s 或者更高。
3.5 包含 Mapping 的 template 设计万能模板
以下模板已经在 7.2 验证 ok,可以直接拷贝修改后实战项目中使用。
PUT _template/test_template{
"index_patterns": ["test_index_*","test_*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"max_result_window": 100000,
"refresh_interval": "30s"},
"mappings": {
"properties": {
"id": {"type": "long"},
"title": {"type": "keyword"},
"content": {
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"keyword": {"ignore_above": 256,"type": "keyword"}
}
},
"available": {"type": "boolean"},
"review": {
"type": "nested",
"properties": {
"nickname": {"type": "text"},
"text": {"type": "text"},
"stars": {"type": "integer"}
}},
"publish_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"expected_attendees": {"type": "integer_range"},
"ip_addr": {"type": "ip"},
"suggest": {"type": "completion"}
}
}
}
分词的选型:
主要以 ik 来说明,最新版本的ik支持两种类型。ik_maxword 细粒度匹配,适用切分非常细的场景。ik_smart 粗粒度匹配,适用切分粗的场景。
分词选型:实际业务中:建议适用ik_max_word分词 + match_phrase短语检索。
原因:ik_smart有覆盖不全的情况,数据量大了以后,即便 reindex 能满足要求,但面对极大的索引的情况,reindex 的耗时我们承担不起。建议ik_max_word一步到位。
ik 要安装在集群的所有节点上
ik 匹配不到:
- 方案1:扩充 ik 开源自带的词库+动态更新词库;原生的词库分词数量级很小,基础词库尽量更大更全,网上搜索一下“搜狗词库“。
动态更新词库:可以结合 mysql+ik 自带的更新词库的方式动态更新词库。
更新词库仅对新创建的索引生效,部分老数据索引建议使用 reindex 升级处理。
- 方案2:采用字词混合索引的方式,避免“明明存在,但是检索不到的”场景。 探究 | 明明存在,怎么搜索不出来呢?
检索类型选型(5.X 版本之后,string 类型不再存在,取代的是text和keyword类型。):
- text 类型作用:分词,将大段的文字根据分词器切分成独立的词或者词组,以便全文检索。
适用于:email 内容、某产品的描述等需要分词全文检索的字段;
不适用:排序或聚合(Significant Terms 聚合例外)
- keyword 类型:无需分词、整段完整精确匹配。
适用于:email 地址、住址、状态码、分类 tags。
term 精确匹配:
- 核心功能:不受到分词器的影响,属于完整的精确匹配。
- 应用场景:精确、精准匹配。
- 适用类型:keyword。
- 举例:term 最适合匹配的类型是 keyword
prefix 前缀匹配
- 核心功能:前缀匹配。
- 应用场景:前缀自动补全的业务场景。
- 适用类型:keyword。
例:POST zz_test/_search{"query": {"prefix": {"title.keyword": "锤子加湿器"}}}
wildcard 模糊匹配
- 核心功能:匹配具有匹配通配符表达式 keyword 类型的文档。支持的通配符: *,它匹配任何字符序列(包括空字符序列);?,它匹配任何单个字符。
- 应用场景:请注意,选型务必要慎重!此查询可能很慢多组关键次的情况下可能会导致宕机,因为它需要遍历多个术语。为了防止非常慢的通配符查询,通配符不能以任何一个通配符*或?开头。
- 适用类型:keyword。
例:POST zz_test/_search{"query": {"wildcard": {"title.keyword": "*加湿器*"}}}
match 分词匹配
- 核心功能:全文检索,分词词项匹配。
- 应用场景:实际业务中较少使用,原因:匹配范围太宽泛,不够准确。
- 适用类型:text。
- 如下示例,title 包含"锤子"和“加湿器”的都会被检索到。
POST zz_test/_search{"profile": true, "query": {"match": {"title": "锤子加湿器"}}}
match_phrase 短语匹配
- 核心功能:match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索;只保留那些包含 全部 搜索词项,且 位置"position" 与搜索词项相同的文档。
- 应用场景:业务开发中 90%+ 的全文检索都会使用 match_phrase 或者 query_string 类型,而不是 match。
- 适用类型:text。
POST zz_test/_analyze{"text": "锤子加湿器","analyzer": "ik_max_word"}
multi_match 多组匹配
- 核心功能:match query 针对多字段的升级版本。
- 应用场景:多字段检索。
- 适用类型:text。
POST zz_test/_search{"query": {"multi_match": {"query": "加湿器","fields": ["title","content"]}}}
query_string 类型
- 核心功能:支持与或非表达式+其他N多配置参数。
- 应用场景:业务系统需要支持自定义表达式检索。
- 适用类型:text。
POST zz_test/_search{"query": {"query_string": {"default_field": "title","query": "(锤子 AND 加湿器) OR (官方 AND 道歉)"}}}
bool 组合匹配
- 核心功能:多条件组合综合查询。
- 应用场景:支持多条件组合查询的场景。
- 适用类型:text 或者 keyword。一个 bool 过滤器由三部分组成:
{"bool" : {"must" : [],"should" : [],"must_not" : [],"filter": []}}
- must ——所有的语句都 必须(must) 匹配,与 AND 等价。
- must_not ——所有的语句都 不能(must not) 匹配,与 NOT 等价。
- should ——至少有一个语句要匹配,与 OR 等价。
- filter——必须匹配,运行在非评分&过滤模式。
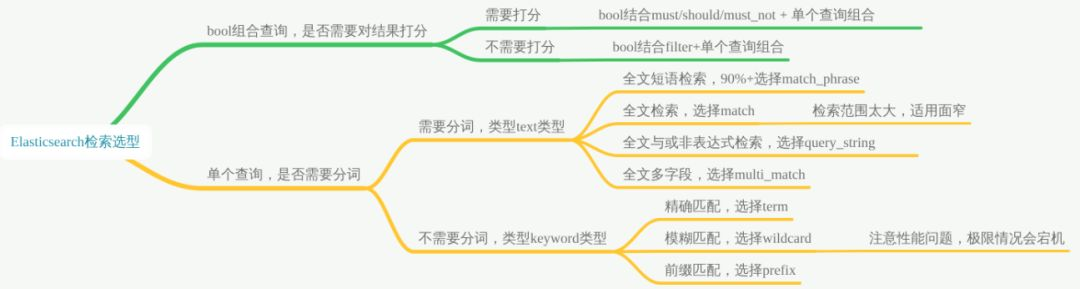
多表关联如何实现:
方案一:多表关联视图,视图同步 ES
MySQL 宽表导入 ES,使用 ES 查询+检索。适用场景:基础业务都在 MySQL,存在几十张甚至几百张表,准备同步到 ES,使用 ES 做全文检索。
将数据整合成一个宽表后写到 ES,宽表的实现可以借助关系型数据库的视图实现。
宽表处理在处理一对多、多对多关系时,会有字段冗余问题,如果借助:logstash_input_jdbc,关系型数据库如 MySQL 中的每一个字段都会自动帮你转成 ES 中对应索引下的对应 document 下的某个相同字段下的数据。
- 步骤 1:提前关联好数据,将关联的表建立好视图,一个索引对应你的一个视图,并确认视图中数据的正确性。
- 步骤 2:ES 中针对每个视图定义好索引名称及 Mapping。
- 步骤 3:以视图为单位通过 logstash_input_jdbc 同步到 ES 中。
方案二:1 对 1 同步 ES
MySQL+ES 结合,各取所长。适用场景:关系型数据库全量同步到 ES 存储,没有做冗余视图关联。
ES 擅长的是检索,而 MySQL 才擅长关系管理。
所以可以考虑二者结合,使用 ES 多索引建立相同的别名,针对别名检索到对应 ID 后再回 MySQL 通过关联 ID join 出需要的数据。
方案三:使用 Nested 做好关联
适用场景:1 对少量的场景。
举例:有一个文档描述了一个帖子和一个包含帖子上所有评论的内部对象评论。可以借助 Nested 实现。
Nested 类型选型——如果需要索引对象数组并保持数组中每个对象的独立性,则应使用嵌套 Nested 数据类型而不是对象 Oject 数据类型。
当使用嵌套文档时,使用通用的查询方式是无法访问到的,必须使用合适的查询方式(nested query、nested filter、nested facet等),很多场景下,使用嵌套文档的复杂度在于索引阶段对关联关系的组织拼装。
方案四:使用ES6.X+ 父子关系 Join 做关联
适用场景:1 对多量的场景。
举例:1 个产品和供应商之间是1对N的关联关系。
Join 类型:join 数据类型是一个特殊字段,用于在同一索引的文档中创建父/子关系。关系部分定义文档中的一组可能关系,每个关系是父名称和子名称。
当使用父子文档时,使用has_child 或者has_parent做父子关联查询。
方案三、方案四选型对比:

注意:方案三&方案四选型必须考虑性能问题。文档应该尽量通过合理的建模来提升检索效率。
Join 类型应该尽量避免使用。nested 类型检索使得检索效率慢几倍,父子Join 类型检索会使得检索效率慢几百倍。
尽量将业务转化为没有关联关系的文档形式,在 文档建模处多下功夫,以提升检索效率。

- 坑1: 数据清洗一定发生在写入 es 之前!而不是请求数据后处理,拿势必会降低请求速度和效率。
- 坑2:高亮不要重复造轮子,用原生就可以。
- 坑3:让 es 做他擅长的事,检索+不复杂的聚合,否则数据量+复杂的业务逻辑大会有性能问题。
- 坑4:设计的工作必须不要省!快了就是慢了,否则无休止的因设计缺陷引发的 bug 会增加团队的戳败感!
- 坑5:在给定时间的前提下,永远不会有完美的设计,必须相对合理的设计+重构结合,才会有相对靠谱的系统。
- 坑6:SSD 能提升性能,但如果系统业务逻辑非常负责,换了 SSD 未必达到预期。
- 坑7:由于 Elasticsearch 不支持事务 ACID 特性,数据库作为实时数据补充,对于实时数据要求严格的场景,必须同时采取双写或者同步的方式。这样,一旦实时数据出现不一致,可以通过数据库进行同步递增更新。
【编程不良人】适合后端编程人员的elasticsearch快速实战教程,已完结!_哔哩哔哩_bilibili
restFul:是一种软件架构风格
定义:一个架构的设计如果遵循Rest设计原则,称这个架构为RestFul架构
rest:表现层状态转化(Representational State Transfer)设计原则 设计约束 设计思路 设计约定...
全部:资源的表现层状态转化
资源(Resource):把网络中的一切事物统称为资源 一首歌 一张图片 静态页面 数据库记录。。。
每一个资源都存在一个唯一的资源标识符 URL
表现层(Representational):将资源具体呈现出来的形式 称之为表现层 view
状态转化(State Transfer):客户端通过操作服务器中的资源,使资源发生某种状态转变 CRUD 增删改查
原则:
-
-
-
- 使用Rest的URL 替换 传统URL
-
-
传统URL:http://localhost:8989/项目名/user/findOne?id=21
http://localhost:8989/项目名/emp/findOne?id=21
RestURL:
http://localhost:8989/项目名/user/findOne/21/
2.四种动词对应服务端端四种操作(CRUD 增删改查)
提出四种新的请求动词:GET(查询) POST(更新|添加) PUT(添加|更新) DELETE(删除)
严格来说,post是更新,put是添加,但也可以混着用
GET url
POST url update delete insert find /user/save /user/find
【编程不良人】适合后端编程人员的elasticsearch快速实战教程,已完结!_哔哩哔哩_bilibili
【优极限】倒排索引+Elasticsearch结合Elasticsearc项目千度一下实战项目详细讲解-从零开始精通分布式搜索ES从入门到精通实战教程_哔哩哔哩_bilibili
ES6.x版本及以上,每个index下只支持一个type,多个会报错:

配置多节点集群:(将es相关文件复制到其他服务器,修改单播对应ip 地址)

创建索引库:
(索引库名称必须要全部小写,不能以下划线开头,也不能包含逗号)
curl -XPUT http://地址:9200/索引名
例:curl -XPUT http://localhost:9200/ceshi
删除索引库:
curl -XDELETE http://地址:9200/索引名
例:curl -XDELETE http://localhost:9200/ceshi
创建document:
(如果没有明确指定索引数据的ID,那么es会自动生成一个随机的ID,这时需要使用POST方式,PUT方式会出错,PUT必须要指定ID;POST可以指定ID,也可以不指定ID)
#规定ID
curl -XPUT http://地址:9200/索引名/type/id -d '{
"字段名" : "字段值",
"字段名" : "字段值",
"字段名" : "字段值",
"字段名" : "字段值",
}'
#不规定ID,自动生成ID
curl -H "Content-Type: application/json" -XPOST http://地址:9200/索引名/type -d '{
"字段名" : "字段值",
"字段名" : "字段值",
"字段名" : "字段值",
}'
例:
curl -XPUT http://localhost:9200/ceshi/users/1 -d '{
"en_name" : "aiyaowei",
"zh_name" : "唉吆喂",
"age" : "18",
"address" : "shanghai",
"email" : "aiyaowei@123.com"
}'
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/ceshi/users -d '{
"en_name" : "aiyaowei",
"zh_name" : "唉吆喂",
"age" : "18",
"address" : "shanghai",
"email" : "aiyaowei@123.com"
}'
如果出现错误:
{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}%
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/ceshi/users/1 -d '{
"en_name" : "aiyaowei",
"zh_name" : "唉吆喂",
"age" : "18",
"address" : "shanghai",
"email" : "aiyaowei@123.com"
}'
修改document:
(PUT和POST都是新增/修改。PUT必须指定ID,所以PUT一般做数据更新;POST可以指定ID,也可以不指定ID,做新增比较好)
curl -XPUT http://地址:9200/索引名/type/已有id -d '{
"字段名" : "字段值",
"字段名" : "字段值",
"字段名" : "字段值",
"字段名" : "字段值",
}'
例:
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/ceshi/users/3 -d '{
"en_name" : "ai",
"zh_name" : "唉",
"age" : "18",
"address" : "shanghai",
"email" : "aiyaowei@123.com"
}'

全局更新:
(会删除原有数据)
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/ceshi/users/3 -d '{
"car" : "BMW",
"city" : "beijing"
}'
局部更新:
(可以添加新字段或者更新已有字段,必须使用POST)
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/ceshi/users/1/_update -d '{
"doc":{
"city":"beijing",
"sex":1
}
}'
普通查询索引:
curl -XGET http://地址:9200/索引/type/_search
例:curl -XGET http://localhost:9200/ceshi/users/_search?pretty

-根据ID查询(在任意的查询字符串中添加pretty参数,es可以得到易于识别的json结果):
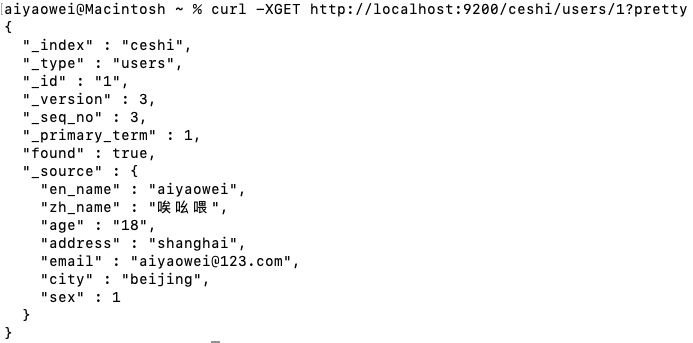
curl -XGET http://地址:9200/索引/type/id?pretty
例:curl -XGET http://localhost:9200/ceshi/users/1?pretty
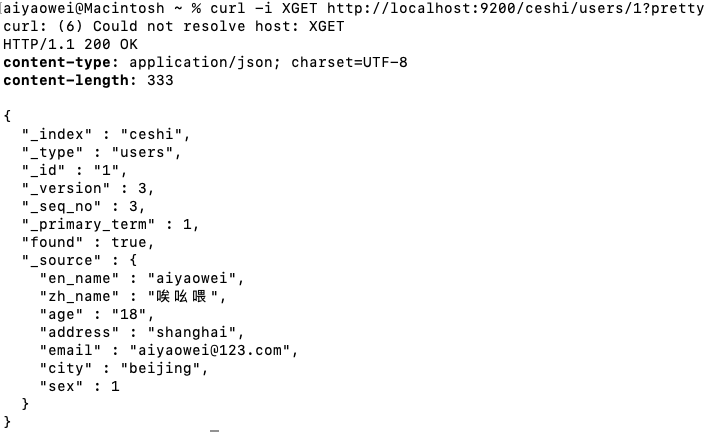
-curl后添加-i参数,这样可以得到反馈头文件
curl -i XGET http://地址:9200/索引/type/id?pretty
例:curl -i XGET http://localhost:9200/ceshi/users/1?pretty
-检索文档中的一部分,只显示指定字段
curl -XGET http://地址:9200/索引/type/id?_source=fields
例:curl -XGET http://localhost:9200/ceshi/users/1?_source=en_name,zh_name,age
如果报错:zsh: no matches found

则在~/.bash_profile中增加setopt no_nomatch,然后source ~/.bash_profile使配置生效

-如果只需要source的数据
curl -XGET http://地址:9200/索引/type/id/_source?pretty
例:curl -XGET http://localhost:9200/ceshi/users/1/_source?pretty

-查询整个es中的所有数据:
curl -XGET http://地址:9200/_search?pretty
例:curl -XGET http://localhost:9200/_search?pretty
-根据条件进行查询
curl -XGET http://地址:9200/索引/type/_search?q=字段名:值
例:curl -XGET http://localhost:9200/ceshi/users/_search?q=en_name:aiyaowei
DSL查询 Domain Specific Language

-领域特定语言
精确查询
#en_name中值为aiya
curl -H "Content-Type: application/json" -XGET http://localhost:9200/ceshi/users/_search?pretty -d '{
"query":
{"match":
{"en_name":"aiya"}
}
}'
-对多个field发起查询:multi_match 精确查询
#zh_name或en_name中值为aiya
curl -H "Content-Type: application/json" -XGET http://localhost:9200/ceshi/users/_search?pretty -d '{
"query":
{
"multi_match":
{
"query":"aiya",
"fields":["zh_name","en_name"]
}
}
}'
-复合查询 must must_not should
must: and
must_not: not
should: or
#en_name为aiyaowei,age为18的
curl -H "Content-Type: application/json" -XGET http://localhost:9200/ceshi/users/_search?pretty -d '
{
"query":
{
"bool":
{
"must":
[{
"match":
{"en_name":"aiyaowei"}
},
{
"match":
{"age":18}
}]
}
}
}'
#en_name为aiyaowei,zh_name不是aiya
curl -H "Content-Type: application/json" -XGET http://localhost:9200/ceshi/users/_search?pretty -d '
{
"query":
{
"bool":
{
"must":
{
"match":
{"en_name":"aiyaowei"}
},
"must_not":
{
"match":
{"zh_name":"aiya"}
}
}
}
}'
#查询en_name为aiya,年龄在16-30之间的
curl -H "Content-Type: application/json" -XGET http://localhost:9200/ceshi/users/_search?pretty -d '
{
"query":
{
"bool":
{
"must":[{
"term":
{"en_name":"aiya"}
},{
"range":
{
"age":{"from":16, "to":30}
}
}]
}
}
}'
删除文档:
curl -XDELETE http://localhost:9200/ceshi/users/5?pretty
- 如果文档存在,es会返回200OK的状态码,found属性为true,_version属性的值为+1
- found属性值为false,但是_version属性的值依然会+1,这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了
- 注意:删除一个文档也不会立即生效,他只是被标记成已删除。Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理


