
- 1终端复用工具-tmux
- 2EVO工具安装与使用小结_evo_traj python numpy
- 3【多机调度问题——贪心算法应用(4)】_多个作业的单机调度例题分析
- 4字符串的定义_stm32定义字符串
- 5人脸识别5.1- insightface人脸检测模型scrfd-训练实战笔记,目标检测的理论理解
- 6「数据分析」之零基础入门数据挖掘
- 7java代码中修改shape的颜色_shapeobject怎么调字体颜色为最淡
- 8ubuntu 的 arm 版本及其仿真_ubuntu desktop-arm64.iso
- 9resnet结构_完整学习 ResNet 家族 ResNext, SEResNet代码实现- part1
- 10激光SLAM——第一节(激光SLAM的发展与应用)
切片 里面包含interface_Golang数据结构详解之切片
赞
踩

上一章中对于编译原理的说明如下:
- 1 概述
- 2 词法和语法分析
- 3 类型检查
- 4 中间代码生成
- 5 机器码生成
接下来我们来对golang的数据结构进行说明,主要内容有:
- 1 数组
- 2 切片
- 3 哈希表
- 4 字符串
我们在上一节介绍的数组在 Go 语言中没那么常用,更常用的数据结构其实是切片,切片就是动态数组,它的长度并不固定,我们可以随意向切片中追加元素,而切片会在容量不足时自动扩容。
在 Go 语言中,切片类型的声明方式与数组有一些相似,由于切片的长度是动态的,所以声明时只需要指定切片中的元素类型:
- []int
- []interface{}
从切片的定义我们能推测出,切片在编译期间的生成的类型只会包含切片中的元素类型,即 int 或者 interface{} 等。cmd/compile/internal/types.NewSlice 就是编译期间用于创建 Slice 类型的函数:
- func NewSlice(elem *Type) *Type {
- if t := elem.Cache.slice; t != nil {
- if t.Elem() != elem {
- Fatalf("elem mismatch")
- }
- return t
- }
-
- t := New(TSLICE)
- t.Extra = Slice{Elem: elem}
- elem.Cache.slice = t
- return t
- }
上述方法返回的结构体 TSLICE 中的 Extra 字段是一个只包含切片内元素类型的 Slice{Elem: elem} 结构,也就是说切片内元素的类型是在编译期间确定的,编译器确定了类型之后,会将类型存储在 Extra 字段中帮助程序在运行时动态获取。
1. 数据结构
编译期间的切片是 Slice 类型的,但是在运行时切片由如下的 SliceHeader 结构体表示,其中 Data 字段是指向数组的指针,Len 表示当前切片的长度,而 Cap 表示当前切片的容量,也就是 Data 数组的大小:
- type SliceHeader struct {
- Data uintptr
- Len int
- Cap int
- }
Data 作为一个指针指向的数组是一片连续的内存空间,这片内存空间可以用于存储切片中保存的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。
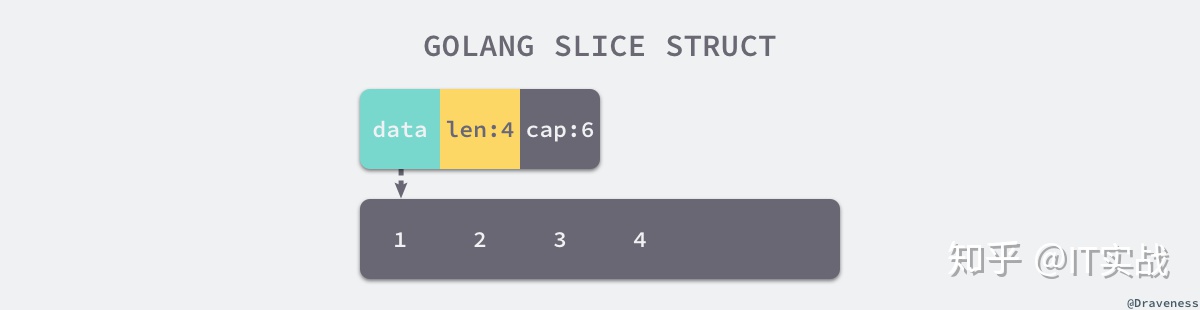
从上图我们会发现切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分片段的引用,作为数组的引用,我们可以在运行区间可以修改它的长度,如果底层的数组长度不足就会触发扩容机制,切片中的数组就会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心底层的数组变化。
我们在上一节介绍过,获取数组大小、对数组中的元素的读写在编译期间就已经进行了简化,由于数组的内存固定且连续,很多操作都会变成对内存的直接读写。但是切片是运行时才会确定内容的结构,所有的操作还需要依赖 Go 语言的运行时来完成,我们接下来就会介绍切片一些常见操作的实现原理。
2. 初始化
Go 语言中的切片有三种初始化的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字
make创建切片:
- arr[0:3] or slice[0:3]
- slice := []int{1, 2, 3}
- slice := make([]int, 10)
使用下标
使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,arr[0:3] 或者 slice[0:3] 这些操作会由编译器转换成 OpSliceMake 操作,我们可以通过下面的代码来验证一下:
- // ch03/op_slice_make.go
- package opslicemake
-
- func newSlice() []int {
- arr := [3]int{1, 2, 3}
- slice := arr[0:1]
- return slice
- }
通过 GOSSAFUNC 变量编译上述代码可以得到如下所示的 SSA 中间代码,在中间代码生成的 decompose builtin 阶段,slice := arr[0:1] 对应的部分:
- v27 (+5) = SliceMake <[]int> v11 v14 v17
-
- name &arr[*[3]int]: v11
- name slice.ptr[*int]: v11
- name slice.len[int]: v14
- name slice.cap[int]: v17
SliceMake 这个操作会接受三个参数创建新的切片,元素类型、数组指针、切片大小和容量,这也就是我们在数据结构一节中提到的切片的几个字段。
字面量
当我们使用字面量 []int{1, 2, 3} 创建新的切片时,cmd/compile/internal/gc.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
- var vstat [3]int
- vstat[0] = 1
- vstat[1] = 2
- vstat[2] = 3
- var vauto *[3]int = new([3]int)
- *vauto = vstat
- slice := vauto[:]
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 将这些字面量元素存储到初始化的数组中;
- 创建一个同样指向
[3]int类型的数组指针; - 将静态存储区的数组
vstat赋值给vauto指针所在的地址; - 通过
[:]操作获取一个底层使用vauto的切片;
第 5 步中的 [:] 就是使用下标创建切片的方法,从这一点我们也能看出 [:] 操作是创建切片最底层的一种方法。
关键字
如果使用字面量的方式创建切片,大部分的工作就都会在编译期间完成,但是当我们使用 make 关键字创建切片时,很多工作都需要运行时的参与;调用方必须在 make 函数中传入一个切片的大小以及可选的容量,cmd/compile/internal/gc.typecheck1 会对参数进行校验:
- func typecheck1(n *Node, top int) (res *Node) {
- switch n.Op {
- ...
- case OMAKE:
- args := n.List.Slice()
-
- i := 1
- switch t.Etype {
- case TSLICE:
- if i >= len(args) {
- yyerror("missing len argument to make(%v)", t)
- return n
- }
-
- l = args[i]
- i++
- var r *Node
- if i < len(args) {
- r = args[i]
- }
- ...
- if Isconst(l, CTINT) && r != nil && Isconst(r, CTINT) && l.Val().U.(*Mpint).Cmp(r.Val().U.(*Mpint)) > 0 {
- yyerror("len larger than cap in make(%v)", t)
- return n
- }
-
- n.Left = l
- n.Right = r
- n.Op = OMAKESLICE
- }
- ...
- }
- }

上述函数不仅会检查 len 是否传入,还会保证传入的容量 cap 一定大于或者等于 len,除了校验参数之外,当前函数会将 OMAKE 节点转换成 OMAKESLICE,随后的中间代码生成阶段在 cmd/compile/internal/gc.walkexpr 函数中的 OMAKESLICE 分支依据两个重要条件对这里的 OMAKESLICE 进行转换:
- 切片的大小和容量是否足够小;
- 切片是否发生了逃逸,最终在堆上初始化
当切片发生逃逸或者非常大时,我们需要 runtime.makeslice 函数在堆上初始化,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
- var arr [4]int
- n := arr[:3]
上述代码会初始化数组并且直接通过下标 [:3] 来得到数组的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组,[:3] 会被转换成上一节提到的 OpSliceMake 操作。
分析了主要由编译器处理的分支之后,我们回到用于创建切片的运行时函数 runtime.makeslice,这个函数的实现非常简单:
- func makeslice(et *_type, len, cap int) unsafe.Pointer {
- mem, overflow := math.MulUintptr(et.size, uintptr(cap))
- if overflow || mem > maxAlloc || len < 0 || len > cap {
- mem, overflow := math.MulUintptr(et.size, uintptr(len))
- if overflow || mem > maxAlloc || len < 0 {
- panicmakeslicelen()
- }
- panicmakeslicecap()
- }
-
- return mallocgc(mem, et, true)
- }
它的主要工作就是计算当前切片占用的内存空间并在堆上申请一片连续的内存,它使用如下的方式计算占用的内存:
内存空间 = 切片中元素大小 x 切片容量虽然大多的错误都可以在编译期间被检查出来,但是在创建切片的过程中如果发生了以下错误就会直接导致程序触发运行时错误并崩溃:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的内存;
- 传入的长度小于 0 或者长度大于容量;
mallocgc 就是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的一些对象会在堆上初始化,我们会在后面的章节中详细介绍 Go 语言的内存分配器,在这里就不展开分析了。
目前的 runtime.makeslice 会返回指向底层数组的指针,之前版本的 Go 语言中,数组指针、长度和容量会被合成一个 slice 结构并返回,但是从 cmd/compile: move slice construction to callers of makeslice 这次提交之后,构建结构体 SliceHeader 的工作就都交给 runtime.makeslice 的调用方处理了,这些调用方会在编译期间构建切片结构体:
- func typecheck1(n *Node, top int) (res *Node) {
- switch n.Op {
- ...
- case OSLICEHEADER:
- switch
- t := n.Type
- n.Left = typecheck(n.Left, ctxExpr)
- l := typecheck(n.List.First(), ctxExpr)
- c := typecheck(n.List.Second(), ctxExpr)
- l = defaultlit(l, types.Types[TINT])
- c = defaultlit(c, types.Types[TINT])
-
- n.List.SetFirst(l)
- n.List.SetSecond(c)
- ...
- }
- }
OSLICEHEADER 操作会创建我们在上面介绍过的结构体 SliceHeader,其中包含数组指针、切片长度和容量,它也是切片在运行时的表示:
- type SliceHeader struct {
- Data uintptr
- Len int
- Cap int
- }
正是因为大多数对切片类型的操作并不需要直接操作原 slice 结构体,所以 SliceHeader 的引入能够减少切片初始化时的少量开销,这个改动能够减少 ~0.2% 的 Go 语言包大小并且能够减少 92 个 panicindex 的调用,占整个 Go 语言二进制的 ~3.5%1。
3. 访问元素
对切片常见的操作就是获取它的长度或者容量,这两个不同的函数 len 和 cap 被 Go 语言的编译器看成是两种特殊的操作,即 OLEN 和 OCAP,它们会在 SSA 生成阶段被 cmd/compile/internal/gc.epxr 函数转换成 OpSliceLen 和 OpSliceCap 操作:
- func (s *state) expr(n *Node) *ssa.Value {
- switch n.Op {
- case OLEN, OCAP:
- switch {
- case n.Left.Type.IsSlice():
- op := ssa.OpSliceLen
- if n.Op == OCAP {
- op = ssa.OpSliceCap
- }
- return s.newValue1(op, types.Types[TINT], s.expr(n.Left))
- ...
- }
- ...
- }
- }
访问切片中的字段可能会触发 decompose builtin 阶段的优化,len(slice) 或者 cap(slice) 在一些情况下会被直接替换成切片的长度或者容量,不需要运行时从切片结构中获取:
- (SlicePtr (SliceMake ptr _ _ )) -> ptr
- (SliceLen (SliceMake _ len _)) -> len
- (SliceCap (SliceMake _ _ cap)) -> cap
除了获取切片的长度和容量之外,访问切片中元素使用的 OINDEX 操作也会在中间代码生成期间转换成对地址的直接访问:
- func (s *state) expr(n *Node) *ssa.Value {
- switch n.Op {
- case OINDEX:
- switch {
- case n.Left.Type.IsSlice():
- p := s.addr(n, false)
- return s.load(n.Left.Type.Elem(), p)
- ...
- }
- ...
- }
- }
切片的操作基本都是在编译期间完成的,除了访问切片的长度、容量或者其中的元素之外,使用 range 遍历切片时也会在编译期间转换成形式更简单的代码,我们会在后面的 range 关键字一节中介绍使用 range 遍历切片的过程。
4. 追加和扩容
向切片中追加元素应该是最常见的切片操作,在 Go 语言中我们会使用 append 关键字向切片追加元素,中间代码生成阶段的 cmd/compile/internal/gc.state.append 方法会拆分 append 关键字,该方法追加元素会根据返回值是否会覆盖原变量,分别进入两种流程,如果 append 返回的『新切片』不需要赋值回原有的变量,就会进入如下的处理流程:
- // append(slice, 1, 2, 3)
- ptr, len, cap := slice
- newlen := len + 3
- if newlen > cap {
- ptr, len, cap = growslice(slice, newlen)
- newlen = len + 3
- }
- *(ptr+len) = 1
- *(ptr+len+1) = 2
- *(ptr+len+2) = 3
- return makeslice(ptr, newlen, cap)
我们会先对切片结构体进行解构获取它的数组指针、大小和容量,如果在追加元素后切片的大小大于容量,那么就会调用 runtime.growslice 对切片进行扩容并将新的元素依次加入切片;如果 append 后的切片会覆盖原切片,即 slice = append(slice, 1, 2, 3), cmd/compile/internal/gc.state.append 就会使用另一种方式改写关键字:
- // slice = append(slice, 1, 2, 3)
- a := &slice
- ptr, len, cap := slice
- newlen := len + 3
- if uint(newlen) > uint(cap) {
- newptr, len, newcap = growslice(slice, newlen)
- vardef(a)
- *a.cap = newcap
- *a.ptr = newptr
- }
- newlen = len + 3
- *a.len = newlen
- *(ptr+len) = 1
- *(ptr+len+1) = 2
- *(ptr+len+2) = 3
是否覆盖原变量的逻辑其实差不多,最大的区别在于最后的结果是不是赋值回原有的变量,如果我们选择覆盖原有的变量,也不需要担心切片的拷贝,因为 Go 语言的编译器已经对这种情况作了优化。
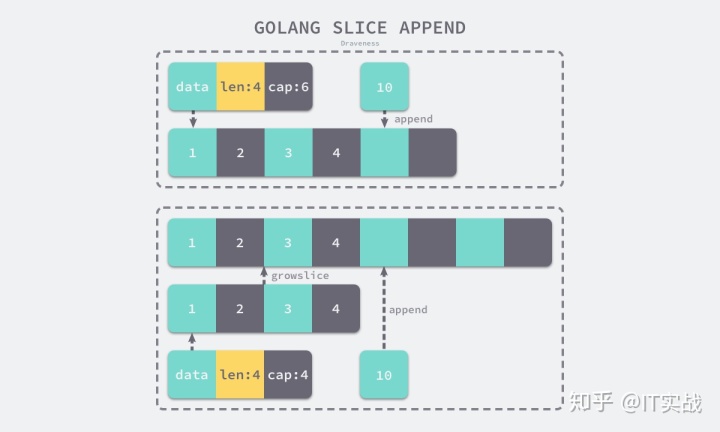
到这里我们已经通过 append 关键字被转换的控制流了解了在切片容量足够时如何向切片中追加元素,但是当切片的容量不足时就会调用 runtime.growslice 函数为切片扩容,扩容就是为切片分配一块新的内存空间并将原切片的元素全部拷贝过去,我们分几部分分析该方法:
- func growslice(et *_type, old slice, cap int) slice {
- newcap := old.cap
- doublecap := newcap + newcap
- if cap > doublecap {
- newcap = cap
- } else {
- if old.len < 1024 {
- newcap = doublecap
- } else {
- for 0 < newcap && newcap < cap {
- newcap += newcap / 4
- }
- if newcap <= 0 {
- newcap = cap
- }
- }
- }
在分配内存空间之前需要先确定新的切片容量,Go 语言根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
确定了切片的容量之后,就可以计算切片中新数组占用的内存了,计算的方法就是将目标容量和元素大小相乘,计算新容量时可能会发生溢出或者请求的内存超过上限,在这时就会直接 panic,不过相关的代码在这里就被省略了:
- var overflow bool
- var newlenmem, capmem uintptr
- switch {
- ...
- default:
- lenmem = uintptr(old.len) * et.size
- newlenmem = uintptr(cap) * et.size
- capmem, _ = math.MulUintptr(et.size, uintptr(newcap))
- capmem = roundupsize(capmem)
- newcap = int(capmem / et.size)
- }
- ...
- var p unsafe.Pointer
- if et.kind&kindNoPointers != 0 {
- p = mallocgc(capmem, nil, false)
- memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
- } else {
- p = mallocgc(capmem, et, true)
- if writeBarrier.enabled {
- bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
- }
- }
- memmove(p, old.array, lenmem)
- return slice{p, old.len, newcap}
- }
如果切片中元素不是指针类型,那么就会调用 memclrNoHeapPointers 将超出切片当前长度的位置清空并在最后使用 memmove 将原数组内存中的内容拷贝到新申请的内存中。这里的 memclrNoHeapPointers 和 memmove 都是用目标机器上的汇编指令实现的,在这里就不展开介绍了。
runtime.growslice 函数最终会返回一个新的 slice 结构,其中包含了新的数组指针、大小和容量,这个返回的三元组最终会改变原有的切片,帮助 append 完成元素追加的功能。
5. 拷贝切片
切片的拷贝虽然不是一个常见的操作类型,但是却是我们学习切片实现原理必须要谈及的一个问题,当我们使用 copy(a, b) 的形式对切片进行拷贝时,编译期间的 cmd/compile/internal/gc.copyany 函数也会分两种情况进行处理,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
- n := len(a)
- if n > len(b) {
- n = len(b)
- }
- if a.ptr != b.ptr {
- memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
- }
其中 memmove 会负责对内存进行拷贝,在其他情况下,编译器会使用 runtime.slicecopy 函数替换运行期间调用的 copy,例如:go copy(a, b):
- func slicecopy(to, fm slice, width uintptr) int {
- if fm.len == 0 || to.len == 0 {
- return 0
- }
- n := fm.len
- if to.len < n {
- n = to.len
- }
- if width == 0 {
- return n
- }
- ...
-
- size := uintptr(n) * width
- if size == 1 {
- *(*byte)(to.array) = *(*byte)(fm.array)
- } else {
- memmove(to.array, fm.array, size)
- }
- return n
- }
上述函数的实现非常直接,两种不同的拷贝方式一般都会通过 memmove 将整块内存中的内容拷贝到目标的内存区域中:

相比于依次对元素进行拷贝,这种方式能够提供更好的性能,但是需要注意的是,哪怕使用 memmove 对内存成块进行拷贝,但是这个操作还是会占用非常多的资源,在大切片上执行拷贝操作时一定要注意性能影响。
6. 小结
切片的很多功能都是在运行时实现的了,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要在使用时减少这种情况的发生避免对程序的性能造成影响。
全套教程点击下方链接直达:
IT实战:Go语言设计与实现自学教程zhuanlan.zhihu.com

