
- 1python关键词大全_Python 批量获取Baidu关键词的排名并入库
- 220230508 DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Network
- 3计算机内存管理之虚拟内存_不同进程可以通过虚拟内存来共享物理内存
- 4在uView UI中扩展和使用自定义图标_uview 扩展图标
- 5【鸿蒙】鸿蒙App应用-《记账软件》开发步骤_鸿蒙记账软件开发
- 6Cesium:CesiumLab制作影像切片与切片加载_cesiumlab影像切片
- 7四川对口高职计算机一类可以填报哪些学校,四川对口高职可以考哪些大学?
- 8新增数据并发处理,避免重复数据插入
- 9零基础HTML教程(10)--写一个画龙点睛的标题_html网页制作小标题
- 10GFLOPS、GFLOPs 和 GMACs的区别与关系
【目标检测算法】YOLOv1学习笔记_yolov1中大目标与小目标
赞
踩
YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。(看最下的ppt有助于理解哦?)
需要明确的是论文中exist,appear都是指:object的中心点落入cell内。
one stage和two stage的区别(自己瞎总结):
two stage(faster rcnn)是产生了一定数量的不同大小但是尺寸固定的proposals,训练阶段这些proposals送给回归和定位网络和原始的ground-truth一起训练lose function。
one stage(yolo)是网络在训练过程中预测的bbox每次都不一样,计算bbox和gt的IoU大小。
cell的坐标慢慢的调整变为bbox。(这句是错的!!)重点即为bbox的坐标是如何预测出来的。
基础概念——bbox中的x,y,w,h,c(和faster rcnn不一样)
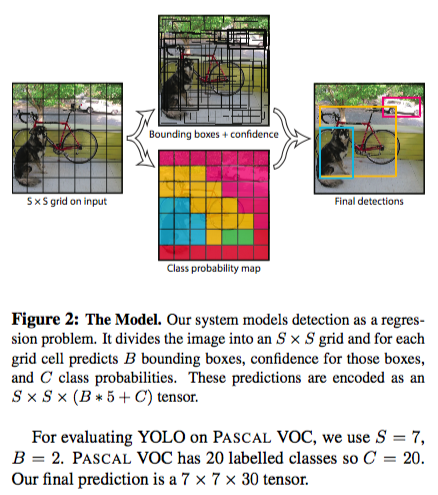
算法首先把输入图像划分成S*S的格子,然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)
基础概念——Class probability map
这个彩色的cell代表着:每个cell只负责预测一个类别,比如蓝色的cell就是负责预测dog这个目标,其余的目标不管。
训练阶段
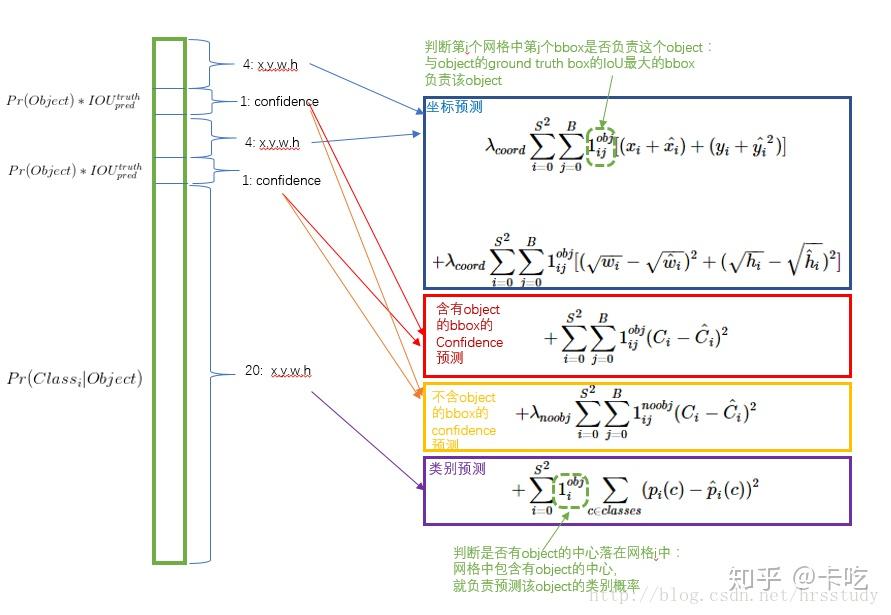
输入N个图像,每个图像包含M个object,每个object包含4个坐标(x,y,w,h)和1个label。然后通过网络得到7*7*30大小的三维矩阵。每个1*30的向量前5个元素表示第一个bbox的4个坐标和1个confidence,第6到10元素表示第二个bounding box的4个坐标和1个confidence。最后20个表示这个grid cell所属类别。注意这30个都是预测的结果。然后就可以计算损失函数的第一、二 、五行。至于第三、四行,confidence可以根据ground truth和预测的bbox计算出的IoU和是否有object的0,1值相乘得到。真实的confidence是0或1值,即有object则为1,没有object则为0。这样就能计算出loss function的值了。
(有个问题,一开始每个object包含的4个坐标xywh是cell的尺寸吗?不是)
448*448*3的图片经过CNN提取特征之后变为7*7*30。由于是将图片划分为7*7,所以49个cell里有2个predictor(总共有98个bbox),头上方的长条为从7*7中抽出一块,是1*1*30的尺寸。
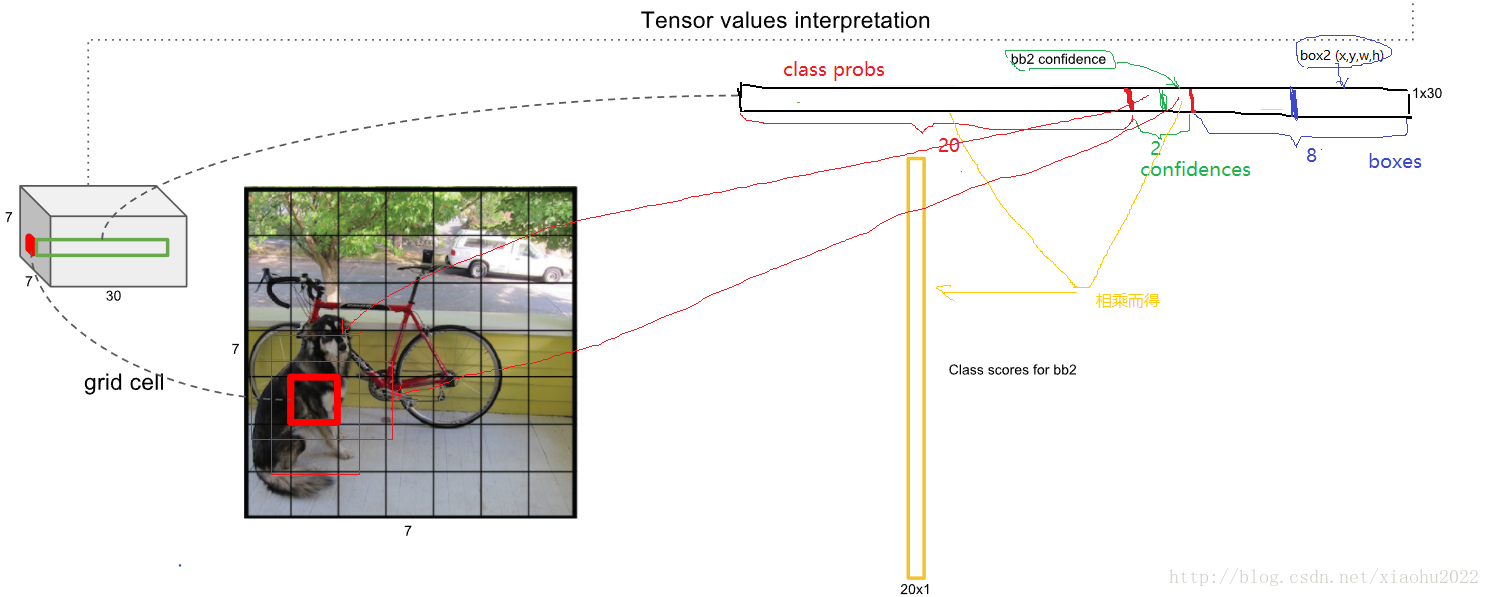
(上图,相乘而得:每个bbox的confidence和每个类别的score相乘,得到每个bbox属于哪一类的confidence score。
那么——每个bbox都对应一个confidence score,如果grid cell里面没有object,confidence就是0,如果有,则confidence score等于预测的box和ground truth的IOU值。)
在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个bbox来负责预测该目标,而其它bbox则认为不存在目标。
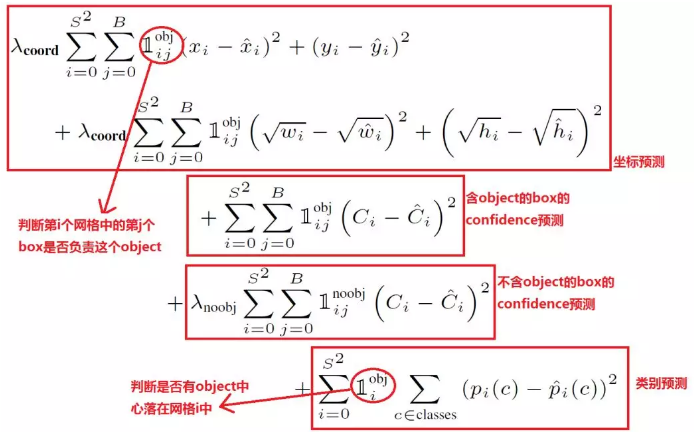
损失函数
yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。
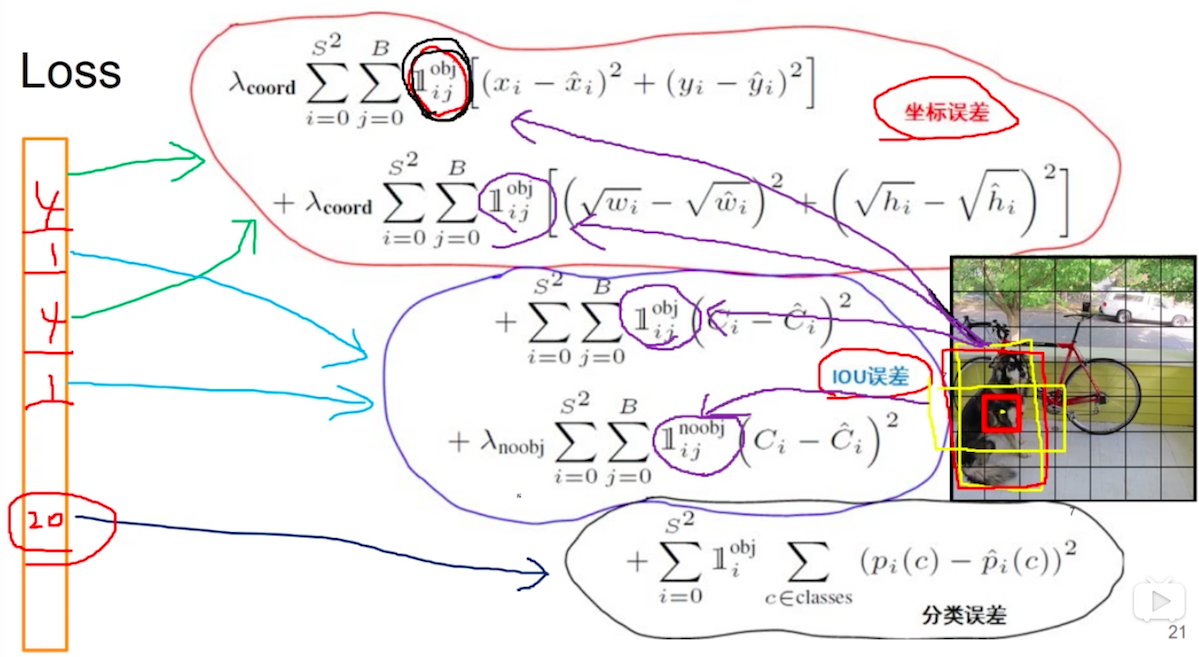
在小狗.jpg的图片里,只有dog,bike,car这三个object所属的bbox计算obj,其余的95(98-3=95)个bbox都计算noobj的那一项,正因如此负样本过多,才加入lamda_noobj用来权衡。
测试阶段
输入一张图像,到网络的末端得到7*7*30的三维矩阵,这里虽然没有计算IOU,但是由训练好的权重已经直接计算出了bounding box的confidence。然后再跟预测的类别概率相乘就得到每个bounding box属于哪一类的概率。
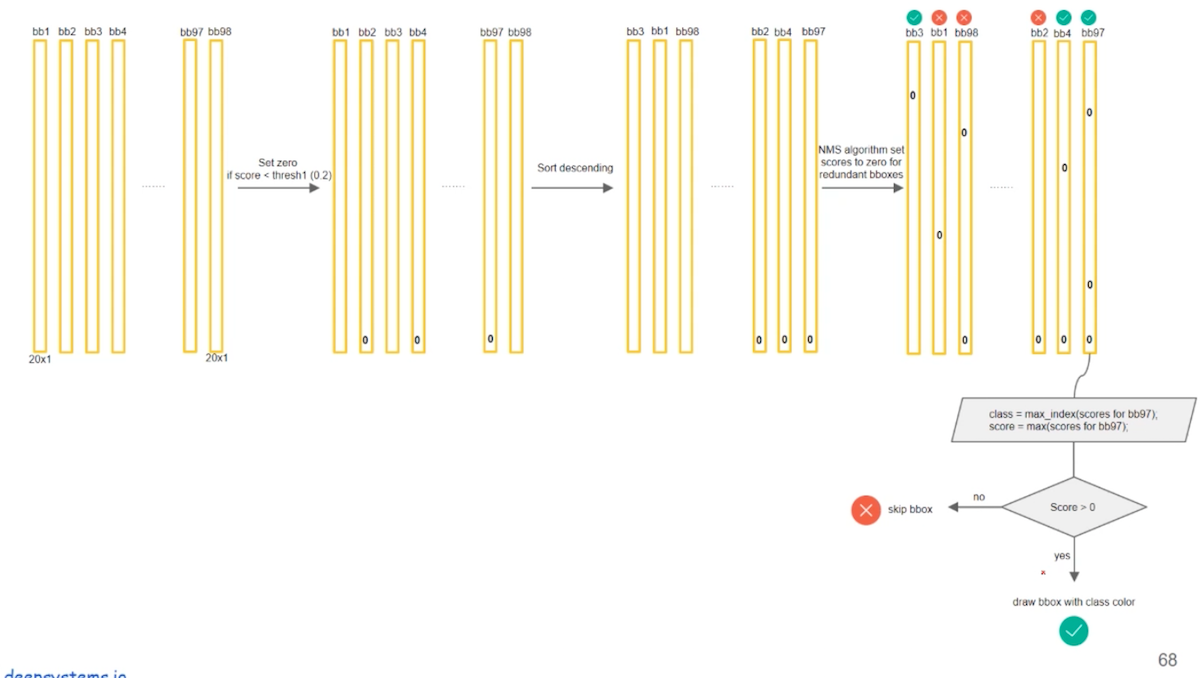
Q: 产生了98个bbox,如何找到最后包含目标的3个bbox呢?(横向是20个类别,纵向是98个bbox)。
1. 先一行一行的遍历(遍历20次),删除(此处是设置为0)98个bbox里confidence少于指定阈值的框;
2. 降序排序,通过NMS,删除多余的框(分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0);
3. 一列一列的遍历(遍历98次),选出confidence最高的所代表的那个类,然后画框。
Darknet的相关网站
一些问题

Q: 如何判断一个grid cell中是否包含object呢?
A:如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
Q: object通常是不规则的物体,那么object的中心怎么计算呢?
A:我们有每个object的标注信息,也就是知道每个object的中心点坐标在输入图像的哪个位置,那么不就相当于知道了每个object的中心点坐标属于哪个grid cell了吗,而只要object的中心点坐标落在哪个grid cell中,这个object就由哪个grid cell负责预测,也就是该grid cell包含这个object。
Q: 损失函数中为什么要开根号?
A: 用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大。举个例子,原来w=10,h=20,预测出来w=8,h=22,跟原来w=3,h=5,预测出来w1,h=7相比,其实前者的误差要比后者小,但是如果不加开根号,那么损失都是一样:4+4=8,但是加上根号后,变成0.15和0.7。
Q: bbox的位置是如何预测出来的?
A: bounding box的预测包括xywh四个值。xy表示bounding box的中心相对于cell左上角坐标偏移,宽高则是相对于整张图片的宽高进行归一化的。偏移的计算方法如下图所示。
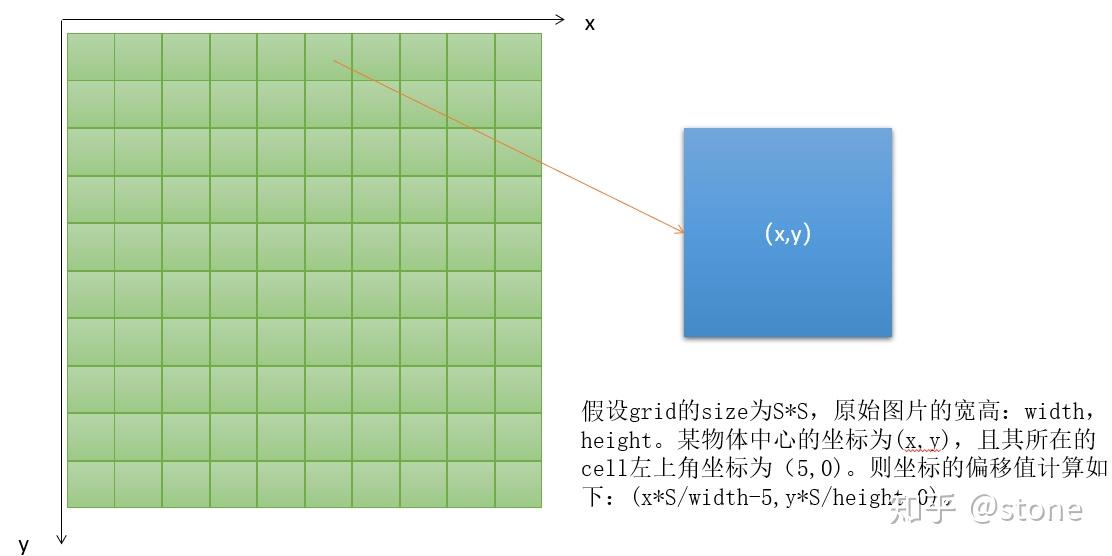
xywh为什么要这么表示呢?实际上经过这么表示之后,xywh都归一化了,它们的值都是在0-1之间。我们通常做回归问题的时候都会将输出进行归一化,否则可能导致各个输出维度的取值范围差别很大,进而导致训练的时候,网络更关注数值大的维度。因为数值大的维度,算loss相应会比较大,为了让这个loss减小,那么网络就会尽量学习让这个维度loss变小,最终导致区别对待。
A: 小目标检测效果不好的原因是:
1. 目标小,yolov1网络到后面感受野较大,小目标的特征无法再后面7*7的grid中体现,针对这一点,yolov2已作了一定的修改,加入前层(感受野较小)的特征;
2. 目标小,可能会出现在一个grid里有两种物体,但是yolov1的模型决定了一个grid只能预测出一个物体,所以就会丢失目标,针对这一点,yolov2引入了anchor的概念,一个grid有多少个anchor理论上就可以预测多少个目标。

参考
你真的读懂yolo了吗?(其实我觉得弄清train和test的打标注问题即训练问题就清楚了,这篇很好)
yolov1笔记YOLO(You Only Look Once)算法详解 (主要在讲测试阶段)

