
- 1c语言实现通讯录管理系统_c语言通讯录管理系统
- 2Python数据处理笔记-1_python 生成qa
- 3ubuntu需要多大的固态硬盘_Ubuntu如何安装和优化SSD硬盘
- 4Window 10未连接到互联网_校园网 检查代理服务器和防火墙
- 5驱动程序开发:基于ICM20608六轴传感器 --- 使用Regmap API 的 SPI 读取数据 之 IIO驱动_icm20608数据手册
- 6【黑马苍穹外卖】个人小程序模拟实现微信支付_微信小程序模拟支付
- 7pycharm创建vue项目idealTree:npm: sill idealTree buildDeps,换taobao源后还不好使?那就再换一个
- 8【先验知识归纳】没有银弹——伴随软件工程的长期问题
- 9update left join mysql_mysql update left join on 多表关联更新和where语句
- 10MySQL表结构转换为ES索引Mapping_将mysql的表转换成es的索引
搜索引擎只能抓取html文件,通过robots屏蔽搜索引擎抓取网站内容
赞
踩
robots协议屏蔽搜索引擎抓取
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
有时候有些页面访问消耗性能比较高不想让搜索引擎抓取,可以在根目录下放robots.txt文件屏蔽搜索引擎或者设置搜索引擎可以抓取文件范围以及规则。
文件写法:
User-agent: 这里的代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /phpinc/ 这里定义是禁止爬寻phpinc目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录)
Disallow: /? 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件
Allow: /framework/ 这里定义是允许爬寻framework目录下面的目录
Allow: /temp 这里定义是允许爬寻temp的整个目录
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
例1. 禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: /
例2. 允许所有的robots访问 (或者也可以建一个空文件 “/robots.txt” file):
User-agent: *
Allow: /
例3. 禁止某个搜索引擎的访问:
User-agent: BadBot
Disallow: /
例4. 允许某个搜索引擎的访问:
User-agent: Baiduspider
allow:/
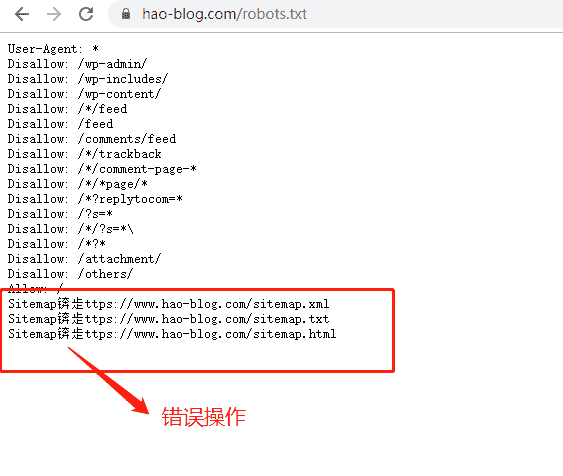
Sitemap网站地图注意事项:
Sitemap:与https://www.hao-blog.com/sitemap.xml 之间的连接是英文冒号如下:
Sitemap:https://www.hao-blog.com/sitemap.xml
Sitemap:https://www.hao-blog.com/sitemap.txt
Sitemap:https://www.hao-blog.com/sitemap.html
以下是错误的书写形式:
Sitemap:https://www.hao-blog.com/sitemap.xml
Sitemap:https://www.hao-blog.com/sitemap.txt
Sitemap:https://www.hao-blog.com/sitemap.html
挡在浏览器中看到时错误的就会显示乱码状态
- 代码html><html lang="en"> [详细] -->
赞
踩

