- 1如何关闭小程序复制短链按钮_微信小程序禁止复制链接
- 2python链家数据分析_练习—利用Python对链家网广州二手房进行数据分析
- 3HarmonyOS开发(DevEco Studio)_deveco studio 可输入文本组件
- 4Springboot平衡膳食系统小程序 计算机专业毕业设计源码27190_基于spring boot的健康饮食推荐系统的研究现状
- 5STM32F103--CRL,CRH寄存器_stm32f103 crh寄存器
- 6循环展开的方法--国科大体系结构 期末必考题
- 7你是否掌握了这30个Python基础代码?
- 8鸿蒙OS应用开发之——Java UI框架-常用组件ScrollView_鸿蒙开发scrollto
- 9一、LLC 谐振变换器工作原理分析_llc谐振变换器工作原理
- 10GhatGPT Chat Generative Pre-trained Transformer_ghat gpt
Chain of Verification-CoVe减少LLM中的幻觉现象
赞
踩
Chain-Of-Verification Reduces Hallucination In Large Language Models
在大型语言模型中,产生看似合理但实际上错误的事实信息,即幻觉,是一个未解决的问题。我们研究了语言模型在给出回答时进行深思以纠正错误的能力。我们开发了Chain-of-Verification(COVE)方法,该方法首先(i)起草一个初始回答;然后(ii)计划验证问题以对草稿进行事实核查;(iii)独立回答这些问题,以便答案不受其他回答的影响;最后(iv)生成其最终经过验证的回答。在实验中,我们展示了COVE在各种任务中减少了幻觉,包括来自Wikidata的基于列表的问题、封闭书籍的多跨度QA和长篇文本生成。

我们的方法假设能够访问一个基础的大型语言模型(LLM),尽管这个模型可能容易产生幻觉,但它能够以少量样本或零样本的方式接受一般性指令的提示。我们方法的一个关键假设是,当得到适当的提示时,这个语言模型能够生成并执行一个计划,以验证自己的工作,并检查是否存在错误,最后将这种分析整合到改进后的回答中。
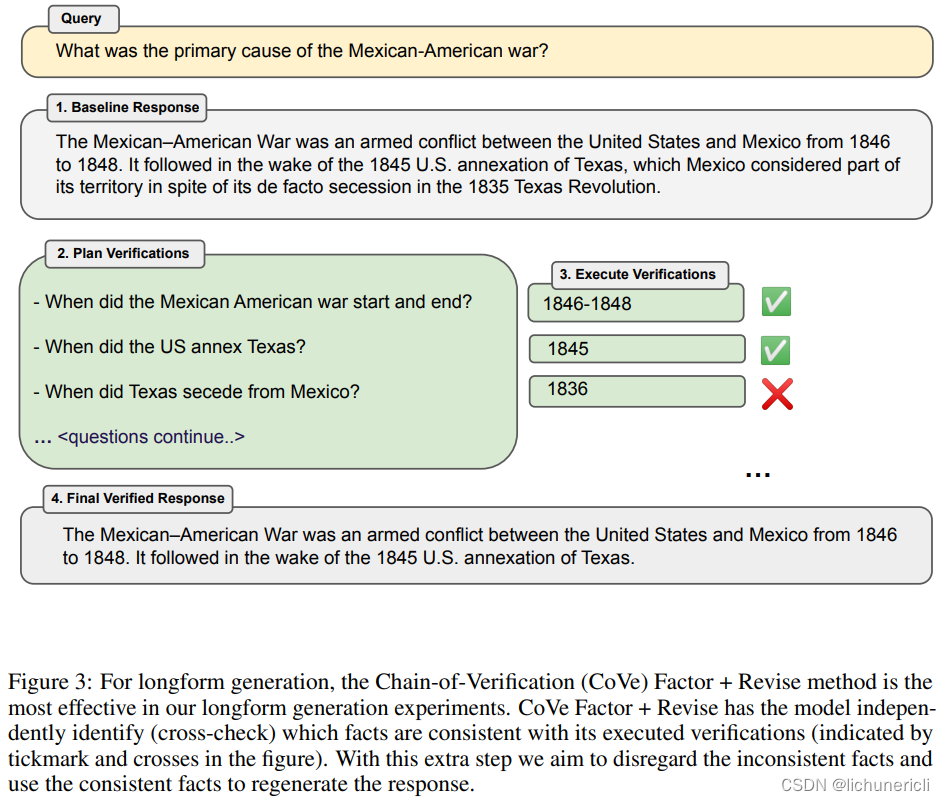
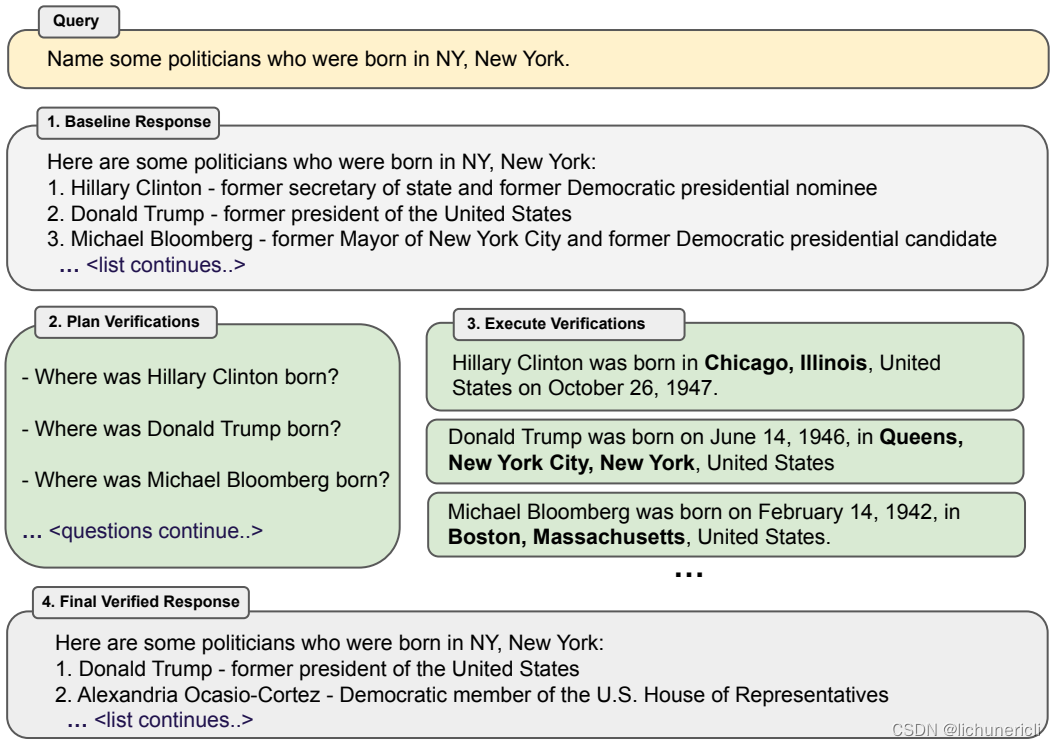
我们的整体过程,我们称之为验证链(CoVe),因此执行四个核心步骤:
1. 生成基线响应:给定一个查询,使用LLM生成响应。

2. 规划验证:给定查询和基线响应,生成一系列验证问题,这些问题有助于自我分析原始响应中是否存在任何错误。

3. 执行验证:依次回答每个验证问题,从而检查答案与原始响应之间是否存在不一致或错误。

4. 生成最终验证响应:给定发现的不一致性(如果有的话),生成一个经过修订的响应,其中包含验证结果。

这些步骤通过以不同的方式提示同一个LLM来获得所需的响应。虽然步骤(1)、(2)和(4)都可以通过单个提示来调用,但我们对步骤(3)的变体进行了研究,包括联合、两步和分解版本。这些变体要么涉及单个提示,要么涉及两个提示,要么每个问题独立提示,其中更复杂的分解可能会导致改进的结果。
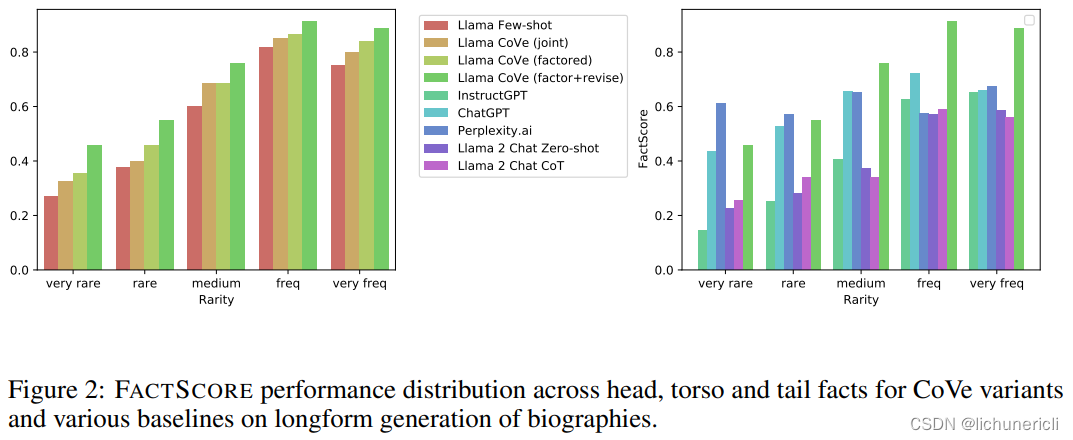
我们介绍了验证链(CoVe)方法,这是一种通过对其自己的响应进行深思熟虑并进行自我纠正来减少大型语言模型中幻觉的方法。特别是,我们展示了模型在将验证分解为一系列更简单的问题时,回答验证问题的准确性高于回答原始查询。其次,在回答验证问题集时,我们展示了控制模型的注意力,使其无法关注其之前的答案(分解CoVe)有助于减轻复制相同的幻觉。总的来说,我们的方法通过让同一个模型对(验证)其答案进行深思熟虑,大大提高了原始语言模型响应的性能。我们工作的一个明显扩展是将CoVe与工具使用相结合,例如在验证执行步骤中使用检索增强,这可能会带来进一步的收益。
尽管我们的验证链(CoVe)方法旨在减少幻觉,但它并没有完全从生成中移除幻觉。这意味着,即使CoVe改进了基线,它仍然可以为给定查询生成不正确或误导性的信息。我们还注意到,在我们的实验中,我们只解决了以直接陈述的事实不准确形式出现的幻觉。然而,幻觉可能以其他形式出现,例如在推理步骤中出错,作为观点的一部分等。我们还注意到,CoVe生成的内容附带验证,如果用户查看,会增加其决策的可解释性,但代价是输出中生成更多令牌,从而增加计算成本,与其他推理方法(如思维链)类似。
我们的方法旨在通过花费更多时间来识别自己的错误,使大型语言模型产生改进的响应。虽然我们已经证明了这确实有所改进,但改进的上限显然受到模型整体能力的影响,例如在识别和知道它知道什么方面。在这方面,正如第2节讨论的,一个与我们的工作平行的研究方向是语言模型使用外部工具,以获取超出其权重存储范围的信息。虽然我们在这项工作中没有探索这一领域,但这些技术很可能与这里的发现相结合。