
- 1鸿蒙版「玩Android」已经来了,你还不来学习一下?_玩安卓 鸿蒙开发
- 2常见的机器学习算法与人工神经网络_机器学习和神经网络算法
- 3数据架构选型必读:4月数据库产品技术解析
- 4真机调试鸿蒙HarmonyOS应用步骤(超详细!!!)_鸿蒙 project signing configs
- 5对抗攻击(HopSkipJumpAttack)
- 6微调预训练的 NLP 模型_nlp模型微调数据集
- 7深度学习代码输出评价指标:通过代码详细指出COCO数据集和VOC数据集如何计算AP值_voc标签格式数据计算ap ac
- 8PyTorch学习之:深入理解神经网络
- 9python 面向对象,类和对象。函数装饰器 和 类的特殊属性和方法_2.综合性总结软件测试高级语法知识:类和对象、函数装饰器和类装饰器、python魔法
- 10android如何自定义dialog,安卓dialog的使用+如何自定义dialog
浅析Auto-GPT_autogpt深度解析
赞
踩
小弟斗胆,尝试浅析一下最近大热的项目Auto-GPT。最近网上也有不少文章介绍如何部署Auto-GPT到本机,docker,以及使用效果等,但是具体实现方式和介绍项目本质的文章并不多,所以想写下一些文字做个简单记录…
什么是Auto-GPT
一句话概括,之前使用ChatGPT,需要自己思考并创建prompt来输入模型让其输出尽可能令人满意的答案。而Auto-GPT,则是只需给定一个目标, Auto-GPT便会自动构造prompt作为输入给到ChatGPT,根据回复再执行各种给定的工具来帮助达到目的,这个过程会不断循环,模型会不断思考,直到其认为任务结束为止。要注意的是,这个开源项目目前还处于试验性质,距离真正实用还有一段距离。但相信随着项目的不断优化和新功能的添加,这一天应该不会太远。
ChatGPT
要实现Auto-GPT,那么ChatGPT,或者是其他的语言模型是必不可少的组件,他相当于整个项目的大脑,所有工具的调度都要经它来决定。关于ChatGPT的模型架构,训练,API等内容,网上有不少介绍文章,这里只做简单概括…
模型架构:和之前的GPT预训练模型差别不大,都是Transformer的decoder only架构,详细的内容可以查阅其他大神的文章,我就不在这里班门弄斧了,包括如何tokenize,embedding,position encoding, self-attention等等概念…
ChatGPT的训练:OpenAI根据在GPT1,GPT2和GPT3预训练模型的基础上,训练出了GPT3.5,具体参数量和训练数据未知。具体GPT预训练过程的详细内容,又是一个大的话题,在这里就先略过了。在GPT3.5的预训练结束后,通过三步对GPT3.5进行微调,令其能讲人话的同时,还能够按照正常人的思路回答问题。第一步是所谓的SFT,OpenAI雇佣一群来自肯尼亚的labeler,想出了一些优质的问答对然后输入原始的预训练模型GPT3.5做supervised fine-tune。第二步重复地从数据库中随机找到一个问题,并把问题输入SFT,输出n次答案,labeler对输出的答案满意度排序,最后把排序的结果作为训练集来训练一个奖励模型reward model,模型会输出一个分数判断答案的满意度。第三步是Reinforcement Learning,把刚才训练出来的Reward model看成是environment,把第一步Fine-tune出来的GPT3.5看成Agent,然后通过PPO算法进行强化学习训练,尽量让Agent(GPT3.5)输出的答案得分(Reward)最高,最后训练出来的Agent,就是ChatGPT了。当然这些只是非常笼统的概括,当中还有大量的细节没有提及。
ChatGPT API:从OpenAI官网获取,https://platform.openai.com/account/api-keys,注意调用API是需要按token数收取费用的,新注册账号只有5美元免费额度。
Auto-GPT
先看一个简略版的图,该图是根据Auto-GPT项目源码,抽丝剥茧把一些不太重要的功能简化(魔改)后得出的大体框架。如果需要添加额外功能,理论上能从上面添加。根据个人理解画出,如与实际有出入欢迎指正~
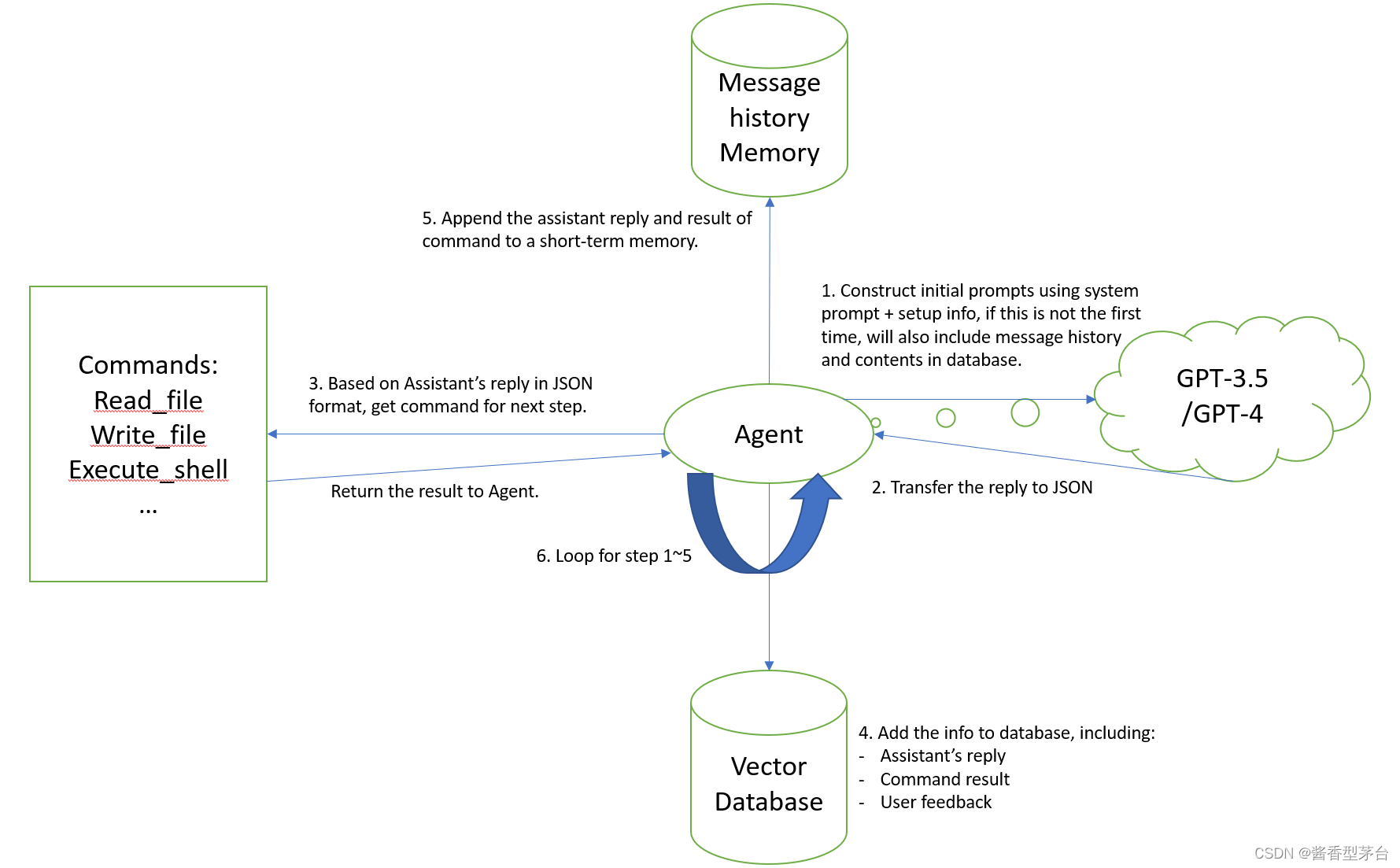
第一步:运行主程序之后,首先检测OpenAI的API Key的信息是否已提供,然后把初始化的信息,包括:短期记忆,数据库中相关联内容(如果是第一次运行,这两应该都是没有的),组合过的prompt等传入Agent。Agent再根据prompt,memory等信息传入chat_with_ai函数。Chat_with_ai函数会根据used token数量为条件,把组合的信息整合并发送到GPT3.5/GPT4模型并获取返回的回复内容。
第二步:根据第一步返回的内容,Agent会调用名为fix_json_using_mutiple_techniques的函数,把模型返回的结果进一步转成JSON格式。
第三步:根据JSON格式的模型回复,Agent会读取其中的thoughts, reason, plan, criticism。然后调用get_command函数,获取其中包含的command name和对应的argument然后再传入execute_command函数,该函数再根据传入的command name调用对应的预先准备好的工具函数例如google search, read file, write file, execute code甚至是start agent, message agent等等,以此来达到给定任务的目标。具体各工具的实现,可以参阅Auto-GPT开源代码。
第四步:把模型回复的内容通过预训练模型做embedding,然后保存到数据库中,在Auto-GPT的源码里,这个数据库可以是成熟的向量数据库如milvus,pinecone等,但也需要API Key来调用,如果没有第三方数据库,则创建一个local的JSON文档来记录。在数据库中调用相关联的内容时,会把当前短期记忆里的内容做embedding,然后再与数据库中每次保存的内容点积作比较,然后排序把最相关的top 10拿出来作为输入。
第五步:把第三步执行某个command的结果append到一个短期记忆的list里,下一次循环会把它加入到输入中让模型思考下一步。
第六步:重复执行前五步直至模型认为任务完成为止。
最后附上魔改后的代码https://github.com/DeeJ4yNg/Mini-Auto-GPT,这是在4月初项目代码量还不太大的基础上修改的。去掉了原Auto-GPT项目里的参数配置,config,log,plugin等相关模块,可以更清晰的理解其工作原理,另外Memory也取消了第三方的向量数据库,直接搬运local cache,command方面也只保留了文件操作和执行脚本等相关工具,取消了联网搜索功能。附上Auto-GPT开源项目地址:GitHub - Significant-Gravitas/Auto-GPT: An experimental open-source attempt to make GPT-4 fully autonomous.
当然,如果今天想简单地实现Auto-GPT,可以用Langchain,不到30行代码即可拥有:https://python.langchain.com/en/latest/use_cases/autonomous_agents/autogpt.html
个人感想:
从ChatGPT横空出世到Auto-GPT star数飙升,也不过半年时间,不得不感概这半年来深度学习领域技术传播的迅速,让广泛大众开始接触生成式模型带来的便利。也感概如今的大语言模型效果超乎想象。虽然目前Auto-GPT还是一个实验性质的东西,效果大多数时候不太理想还烧美金,但随着各大厂的竞争和大语言模型的持续发展和优化,以及类似Auto-GPT等应用工具在各大社区的不断完善之下,相信类似的工程模式在未来会百花齐放。

