
热门标签
热门文章
- 1有奖征集|与OneDiff加速前行,GenAI探索触手可及
- 2C# Using StreamReader
- 3Microsoft TTS(Text To Speech)语音包的简单应用_微软tts语音包不同人的名称
- 4ChatGLM部署问题——ValueError: Unrecognized configuration class <class ‘transformers_modules.chatglm-6b.co_valueerror: unrecognized configuration class
- 5洛雪音乐助手用不了了?使用六音自定义音源即可解决_六音音源js文件
- 6WFST--学习笔记
- 7微服务集成Windows版kafka_kafka windows运行
- 8Unity3D 引擎学习2022资料整理(一)_rapier voxels
- 9Linux的三种配置 IP方法_linux配置ip地址
- 10YOLOv5和v8实验对比,训练效果,哪个更好呢?_yolov8和yolov5哪个更好用
当前位置: article > 正文
2023.05.09-使用AI克隆孙燕姿的声音来进行唱歌_reference_loss
作者:Gausst松鼠会 | 2024-03-26 05:57:16
赞
踩
reference_loss
1. 简介
- 如果我们想要克隆孙燕姿的声音,整体的思路很简单,首先找一些孙燕姿唱歌时没有伴奏的人声,然后把这个声音放到模型中进行训练拟合,让AI学习说话的这种声线风格,最后使用这个训练出来的模型进行推理和风格迁移,这样一首孙燕姿唱其他人歌曲的音频就制作出来了。
2. 资源合集
- 原始项目:GitHub - voicepaw/so-vits-svc-fork: so-vits-svc fork with realtime support, improved interface and more features.
- 懒人包:pan.baidu.com/s/12u LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4
- 炼丹百科全书
3. 准备数据集
- 用于训练的音频数据集应该切分为10秒的音频,太长的话会爆显存
- 数据集是越多越好,但一般情况下,如果想要得到一个比较好的训练效果的话,有200段10秒的片段应该就差不多了
3.1. 人声分离
- 一般使用spleeter来完成这个工作
GitHub boy1dr/SpleeterGui: Windows desktop front end for Spleeter AI source separation
3.2. 音频进行切片化处理
- 使用[Audio Slicer](…/…/…/…/…/…/…/…/…/音频/音频切片/Audio Slicer.md)来完成这个工作
github.com/openvpi/audio slicer
3.2.1.
3.3. 数据集存放格式要求


4. 训练
4.1. 启动web UI.bat
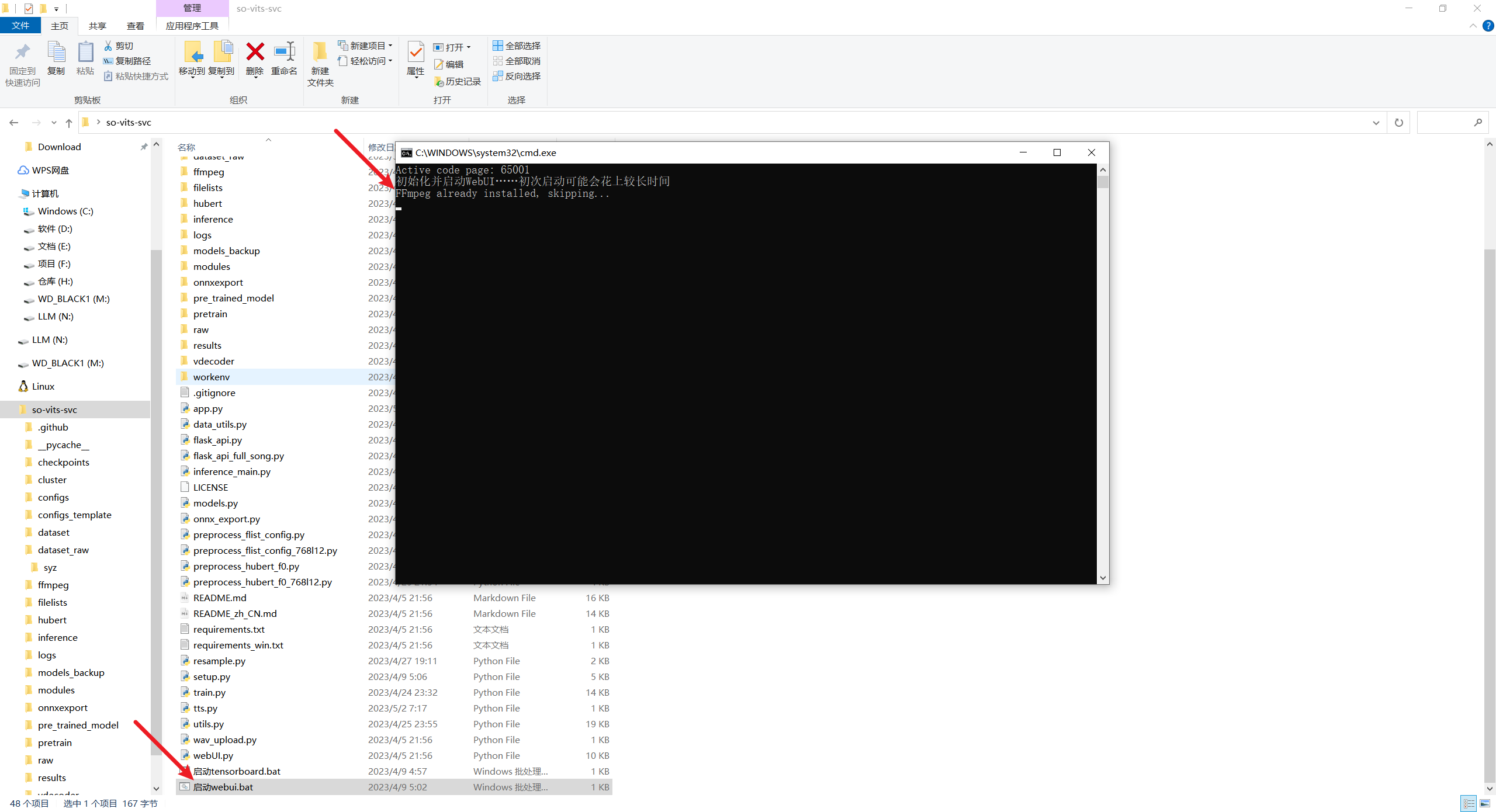
- 之后会自动弹出一个训练网页
- 127.0.0.1:7860/
- 训练的时候需要有一张支持cuda的N卡,显存要求6gb以上
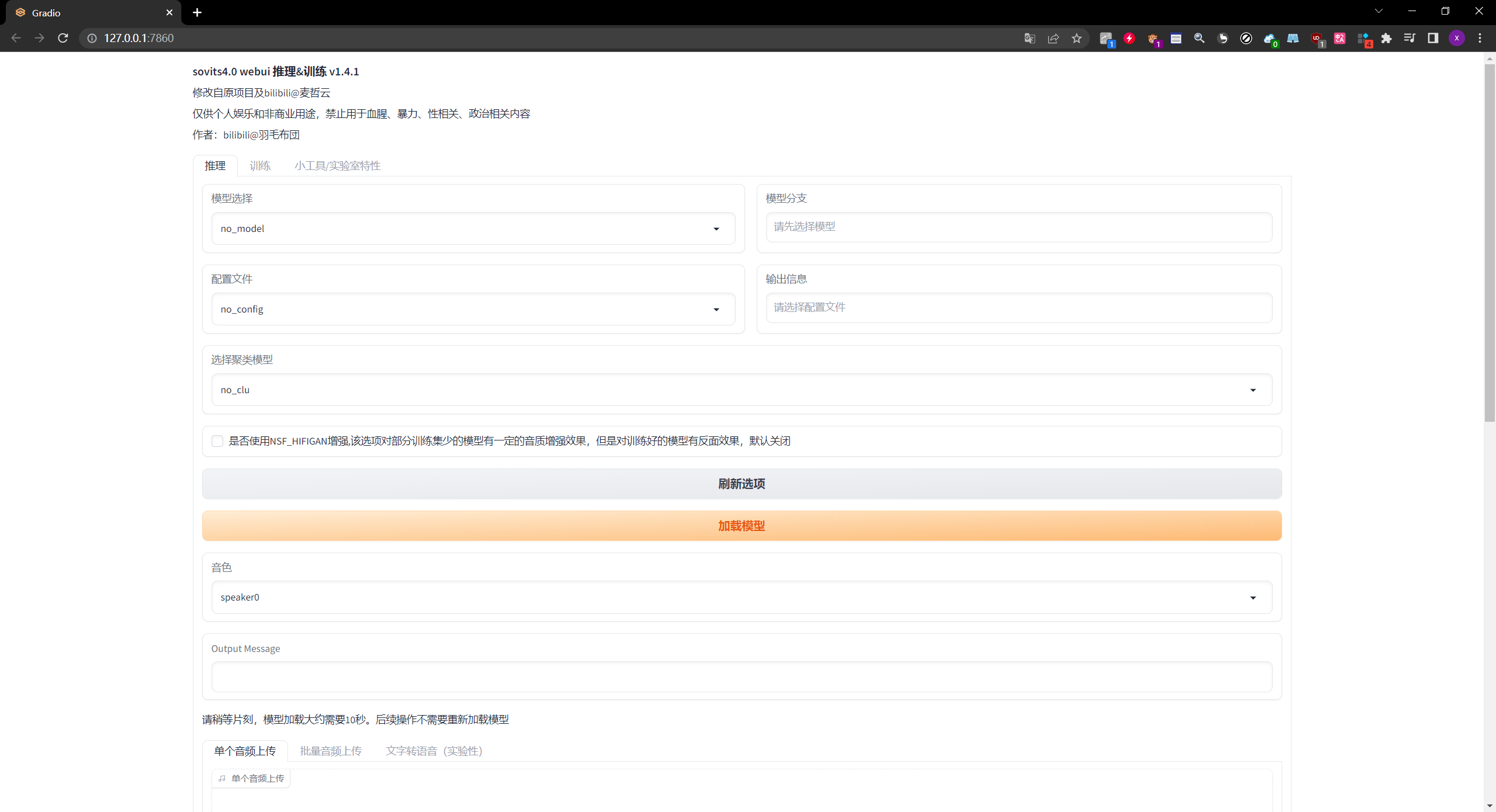
4.2. 识别数据集
- 点击训练选项卡中的识别数据集,

- 就会自动识别到我们刚才放到dataset_raw文件夹下面的音频文件

4.3. 数据预处理
- 这个数据预处理很简单,只需要点击这个按钮选项即可开始进行处理
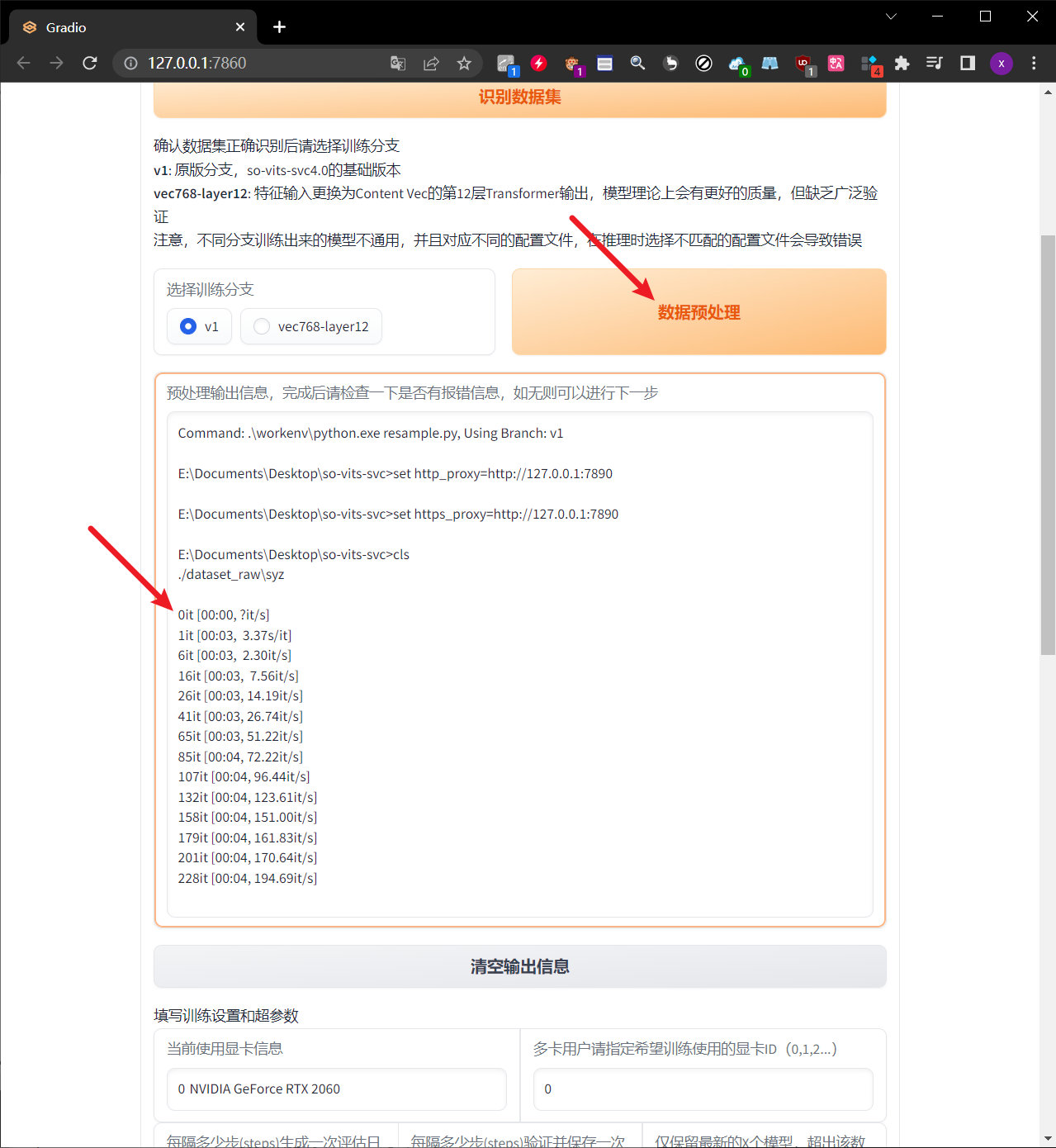
预处理完结束之后,检查一下是否有对应的报错信息。 - 正常情况下,预处理结束之后,会生成非常长的一段过程信息,简单检查一下即可,如果没有报错的话,就证明这个预处理是成功的
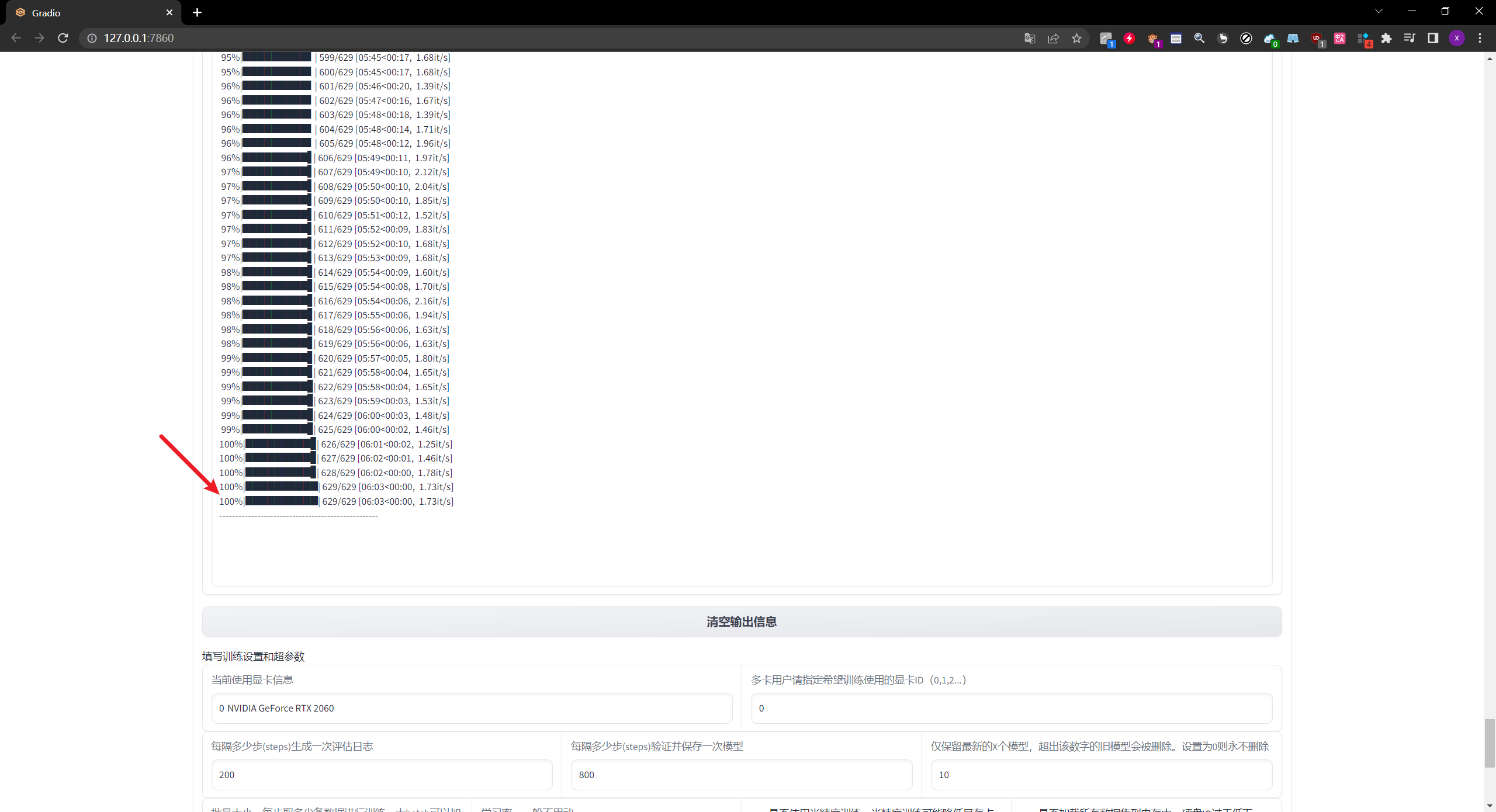
- 那么我们就可以把这个输出信息给清空,会方便接下来的操作显示
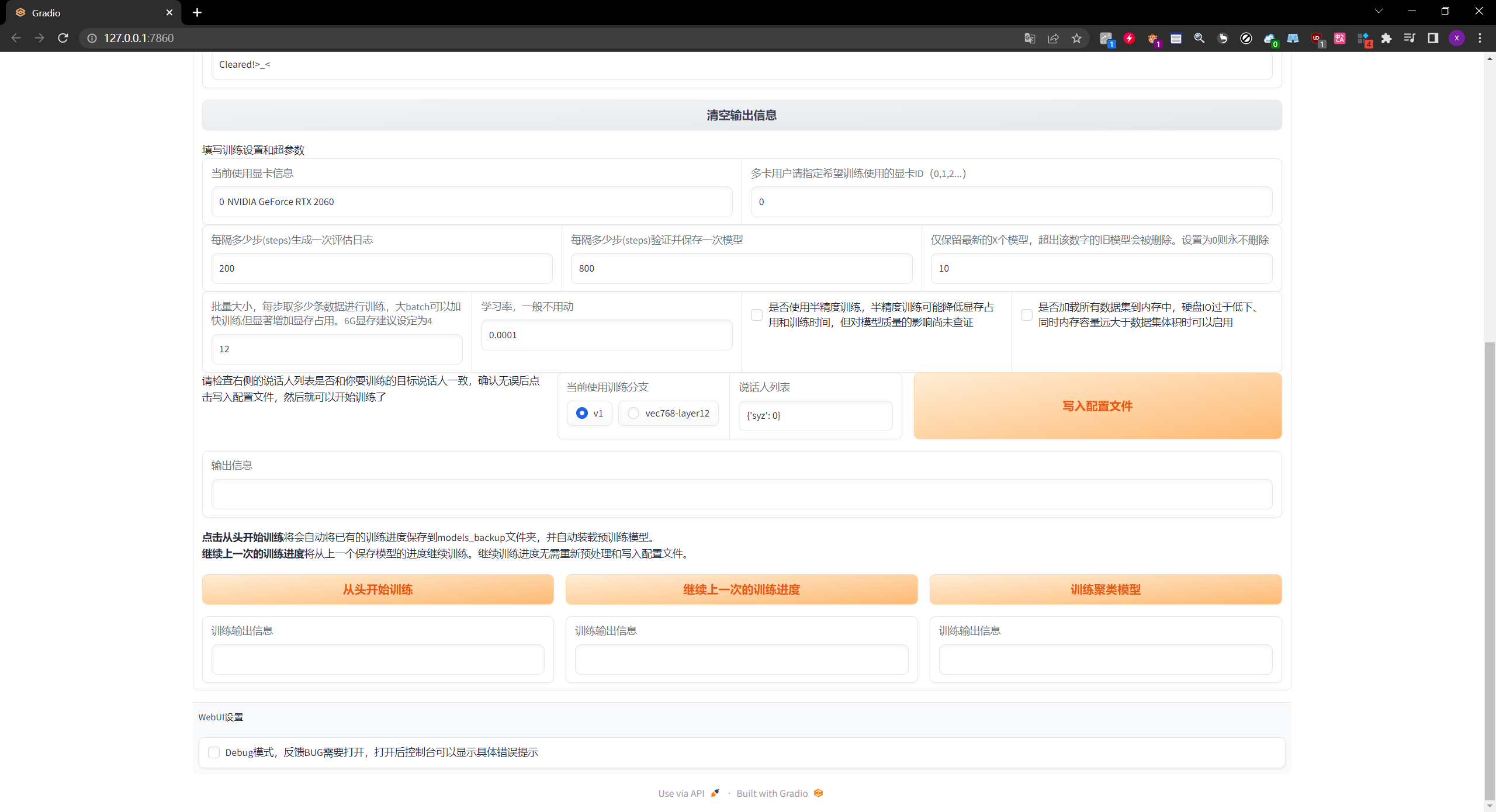
4.4. 设置训练超参数
- 这里的超参数可以自行设置,也可以直接使用默认的参数
4.4.1. 选择模型分支
一共有两个分支,一个是v1,另一个是vec768-layer12,目前说来,应该是第二个分支效果更好,但是没有经过广泛验证。总体来说比较玄学,选择哪一个都可以
-

-
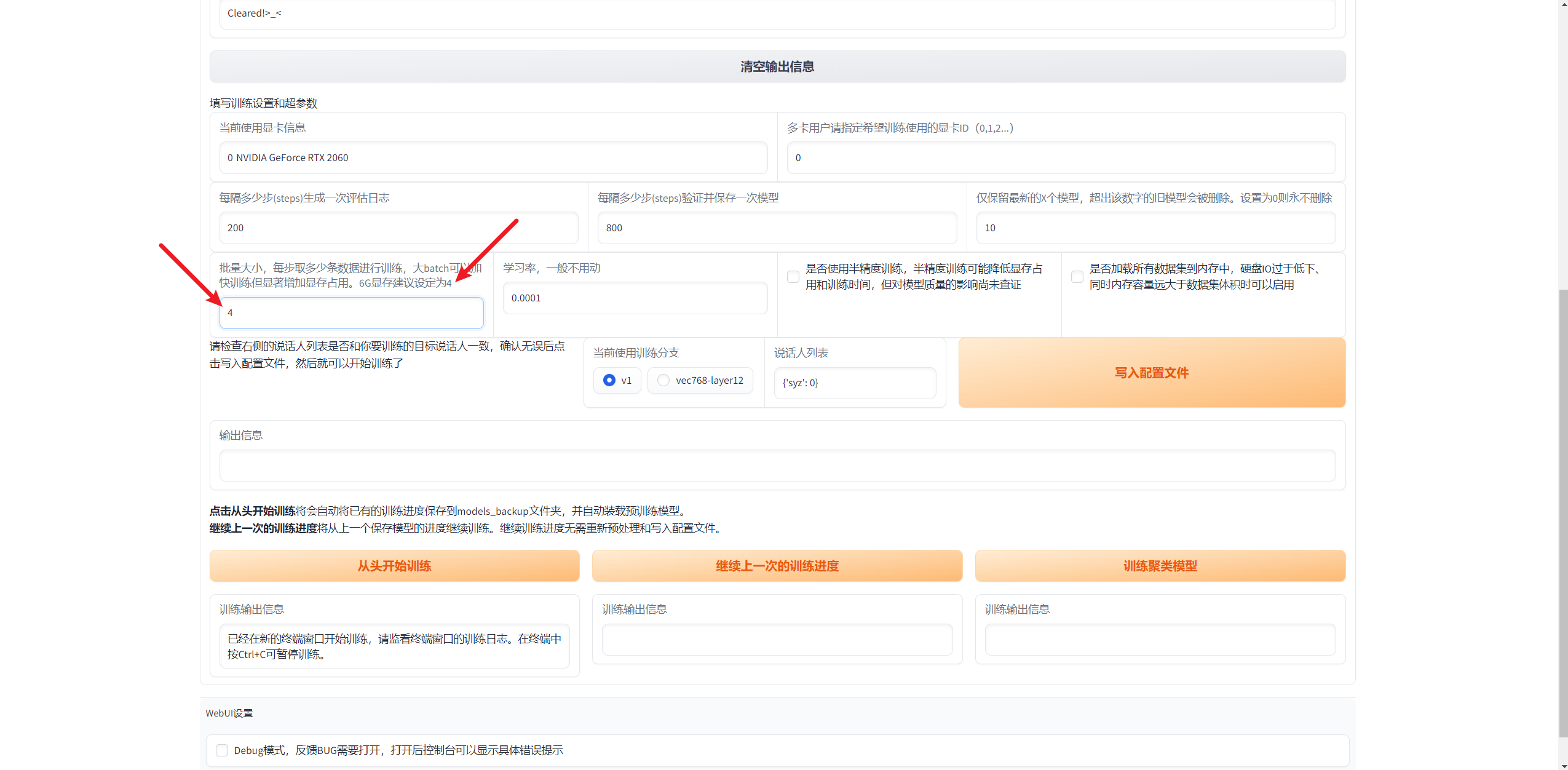
如果GPU显存不是特别大的话,把这个Batch Size设的小一点,6G显存就设置为4即可
-
同时,为了减少显存占用,可以使用半精度进行训练

-
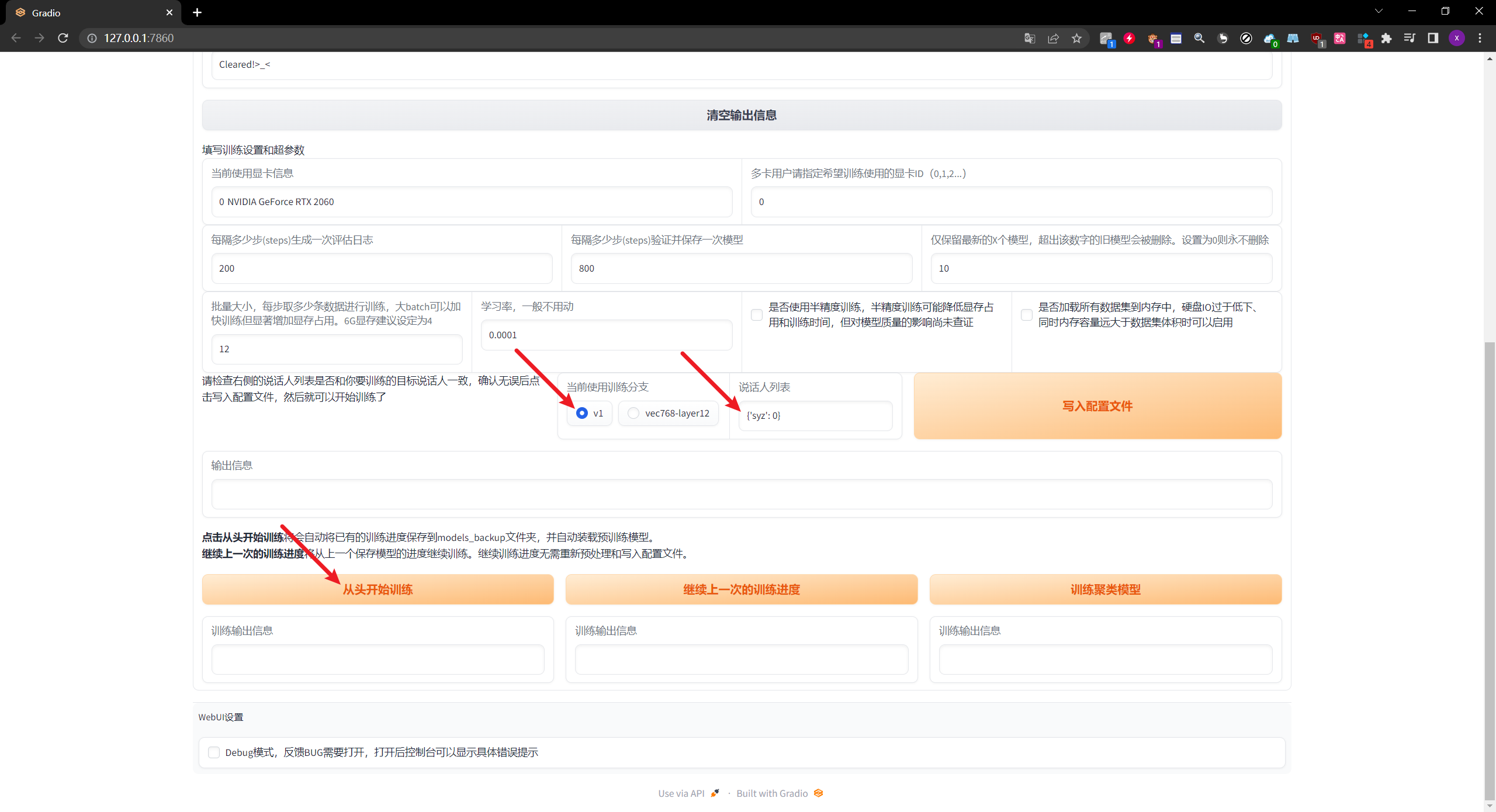
检查训练分支以及说话人列表
-
如果所有的参数都设置正确的话,点击这个写入配置文件,才可以让上面选项生效

4.5. 进行训练
-
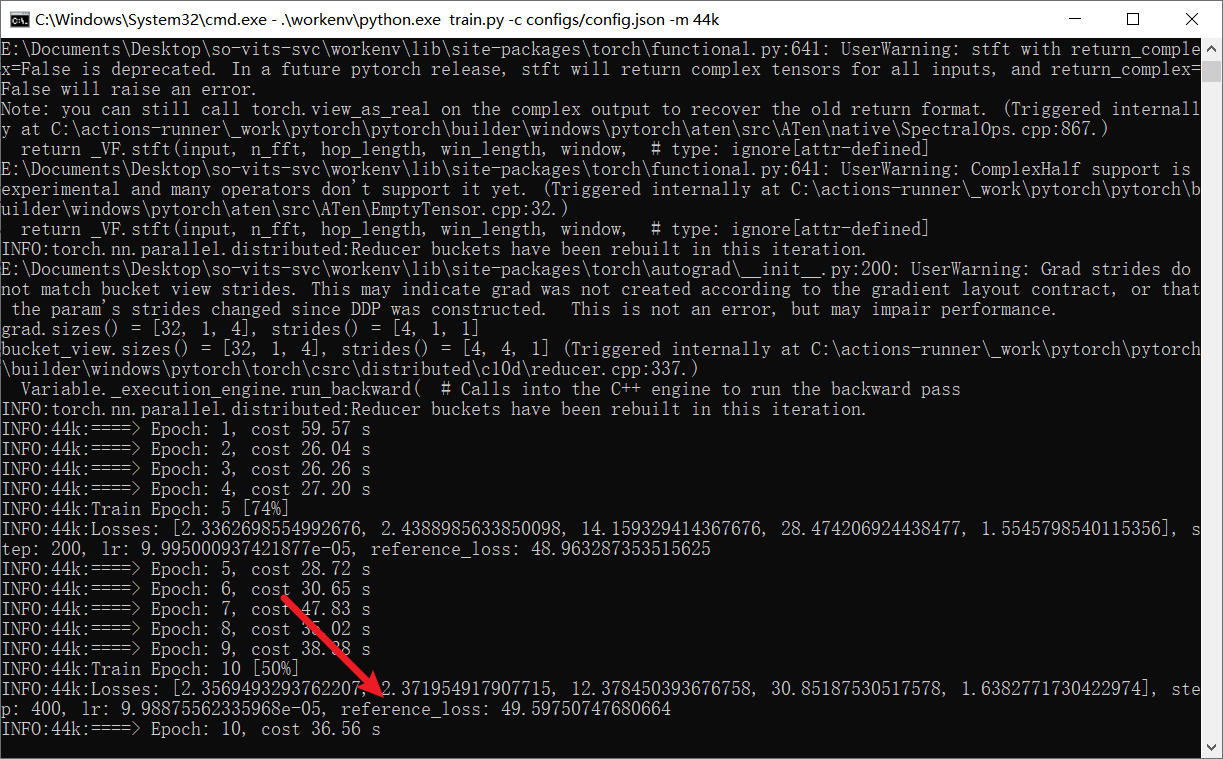
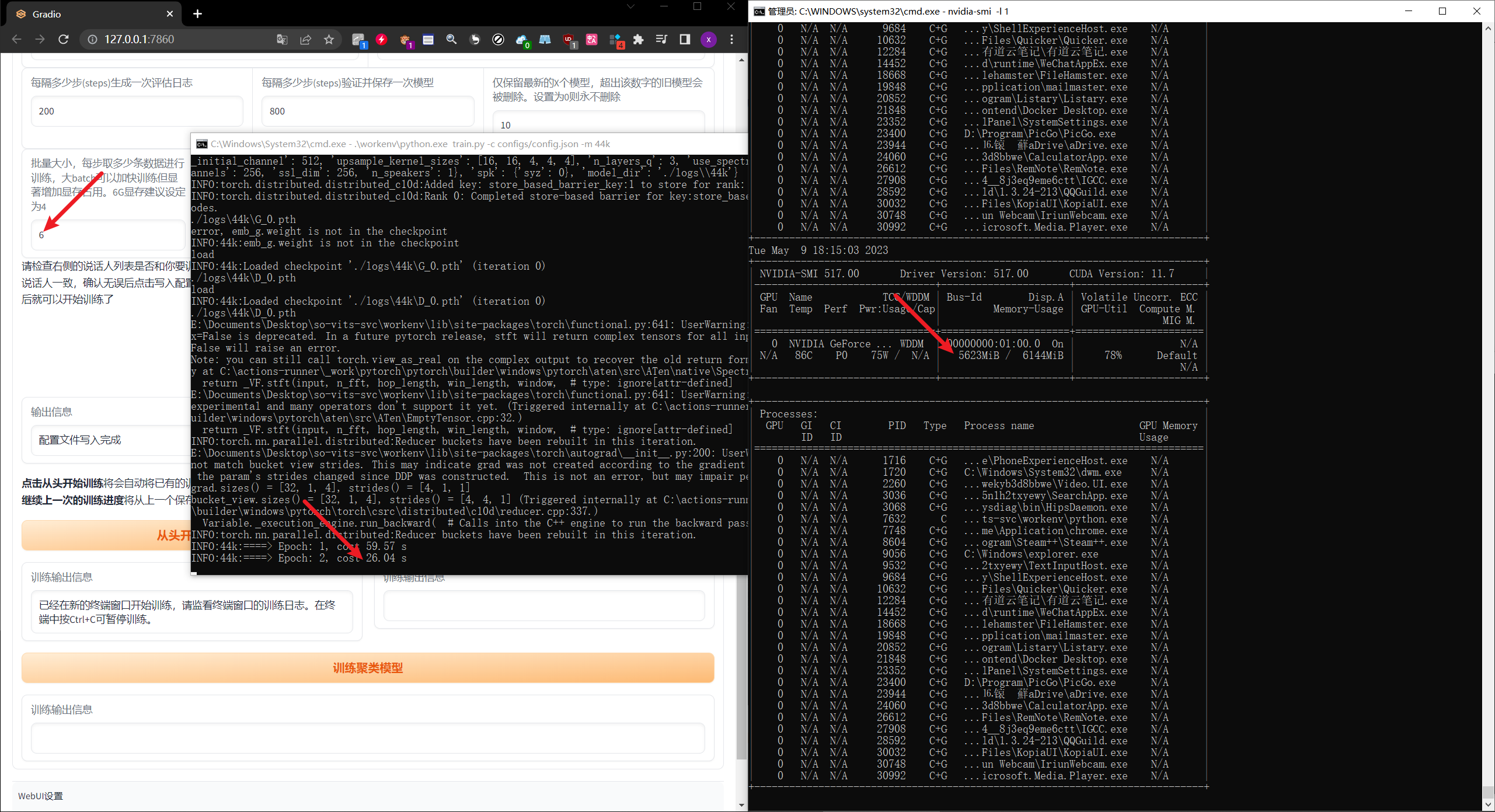
点这个训练按钮就可以开始训练了,训练过程中会弹出来一个黑色的命令行窗口,

-
上面会有很多信息,其中我们主要关注这个reference_loss这个值是越低越好的,如果它的值可以在20以下的话,那么表示他的模型是相当不错的
-
需要说明的是,这个训练是不会自动充值的,需要你自己根据损失值来判断是否已经训练合乎要求了
4.5.1. 关于显存的说明
这样的过程中,如果爆显存了,那么就把这个数据集的切片设的更短一点,每段都设成5秒应该就够了
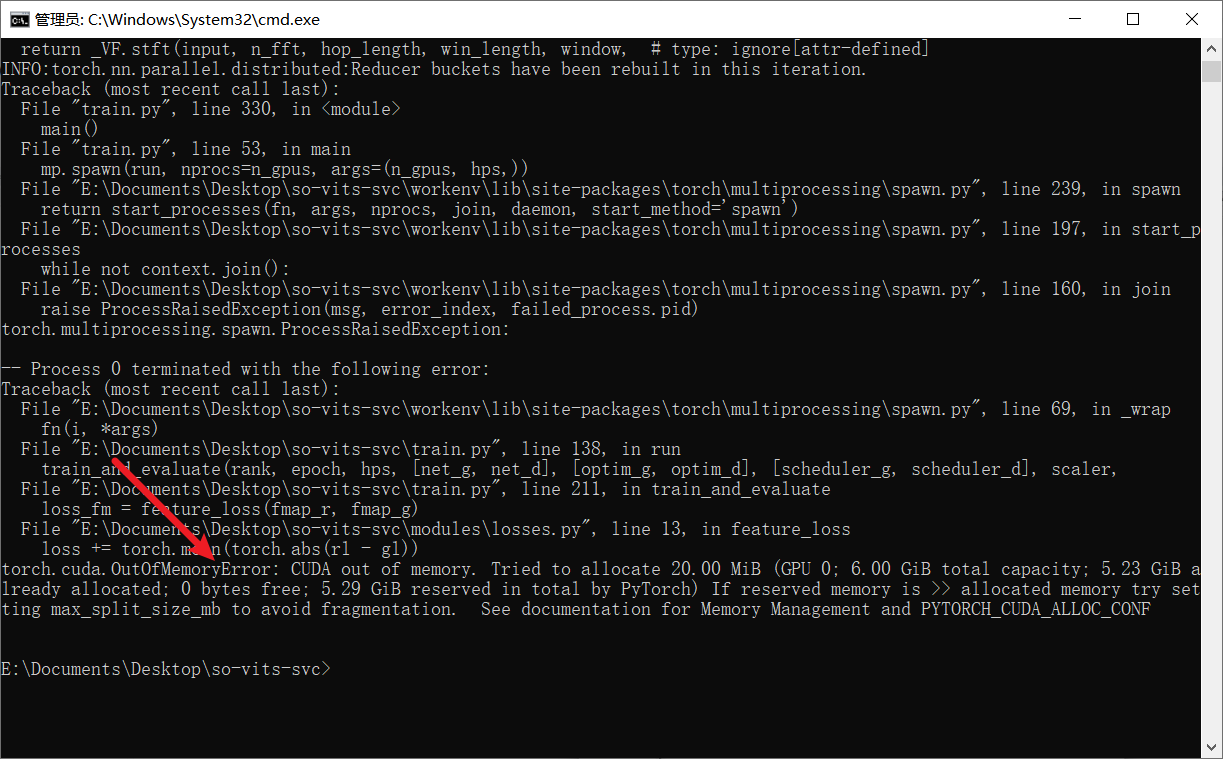
- 如果这样显存依然不够用的话,那么可以去云端租借一张GPU卡片
我这边使用的是6G显存Batch Size为1的时候占用了3个G的显存 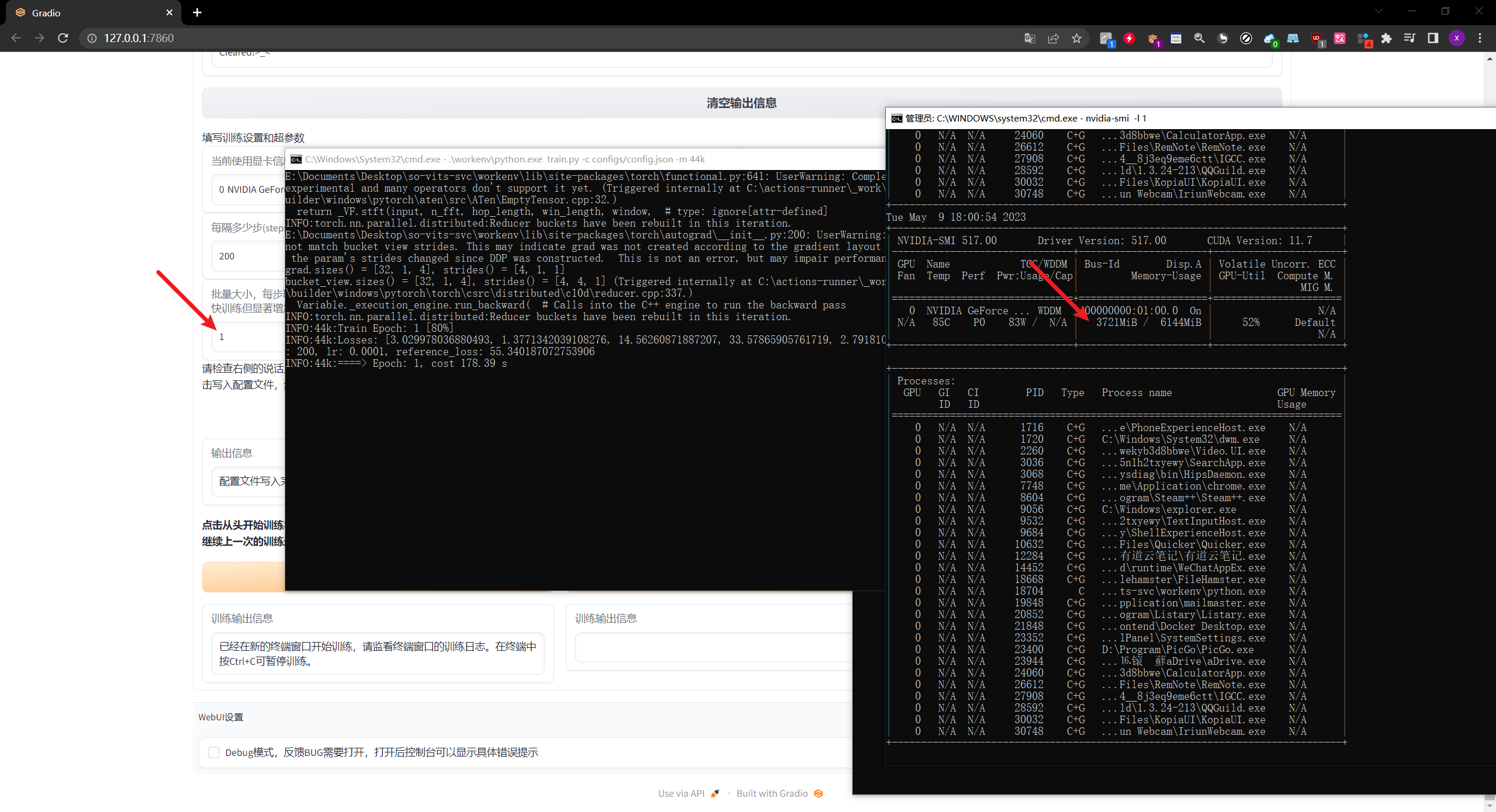
- Batch Size为2,占用显存为4590,

- Batch Size为6,占用显存为5623
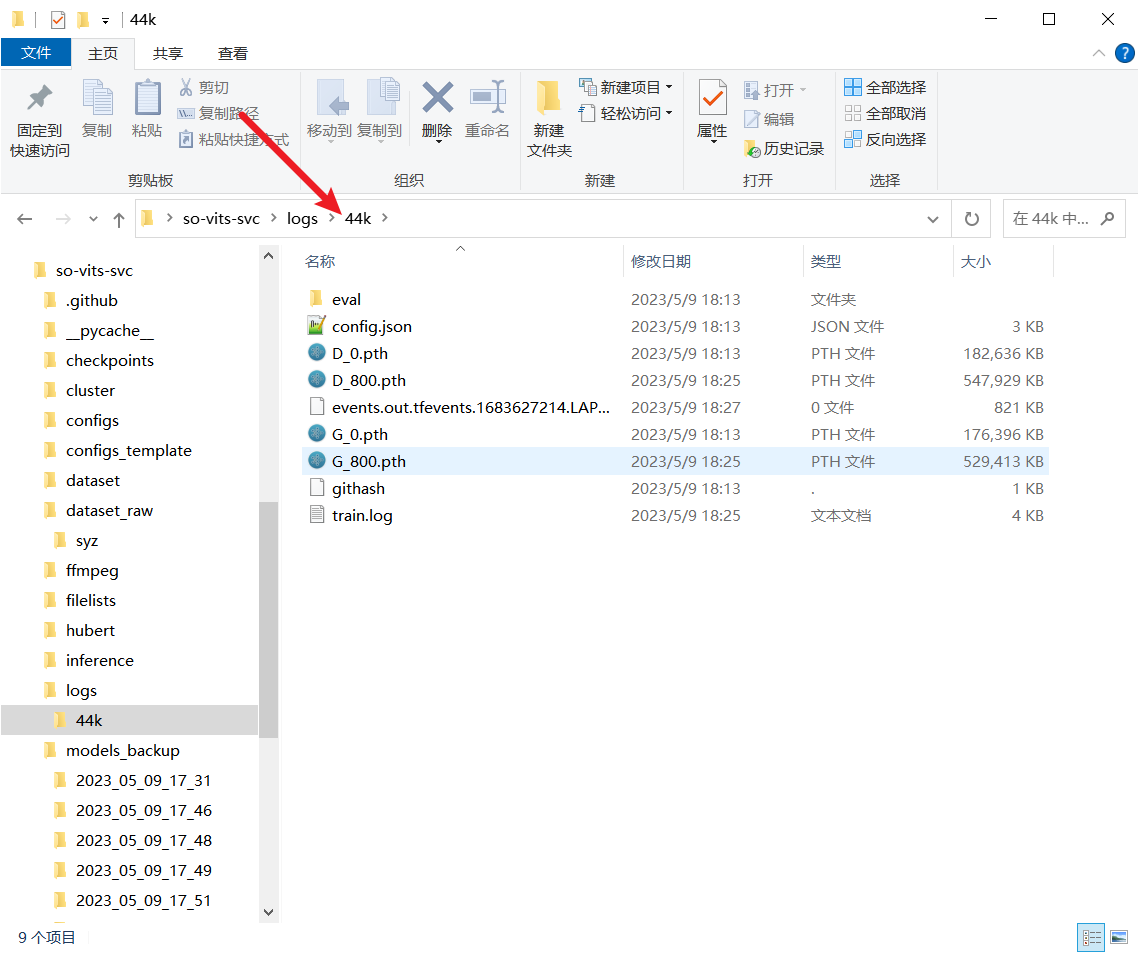
- 训练完成后,模型会保存在logs文件夹下面
5. 推理
5.1. 加载模型
- 训练完成后,回到推理的选项卡上面
5.1.1. 加载模型配置
如果是刚训练完,那么模型和配置文件的路径都是正确的。如果是从外部转移过来的的话,那么需要放到对应的位置才行
- 这个配置文件的路径是为 G模型和Kmeans聚类模型:logs\44k;配置文件:configs,
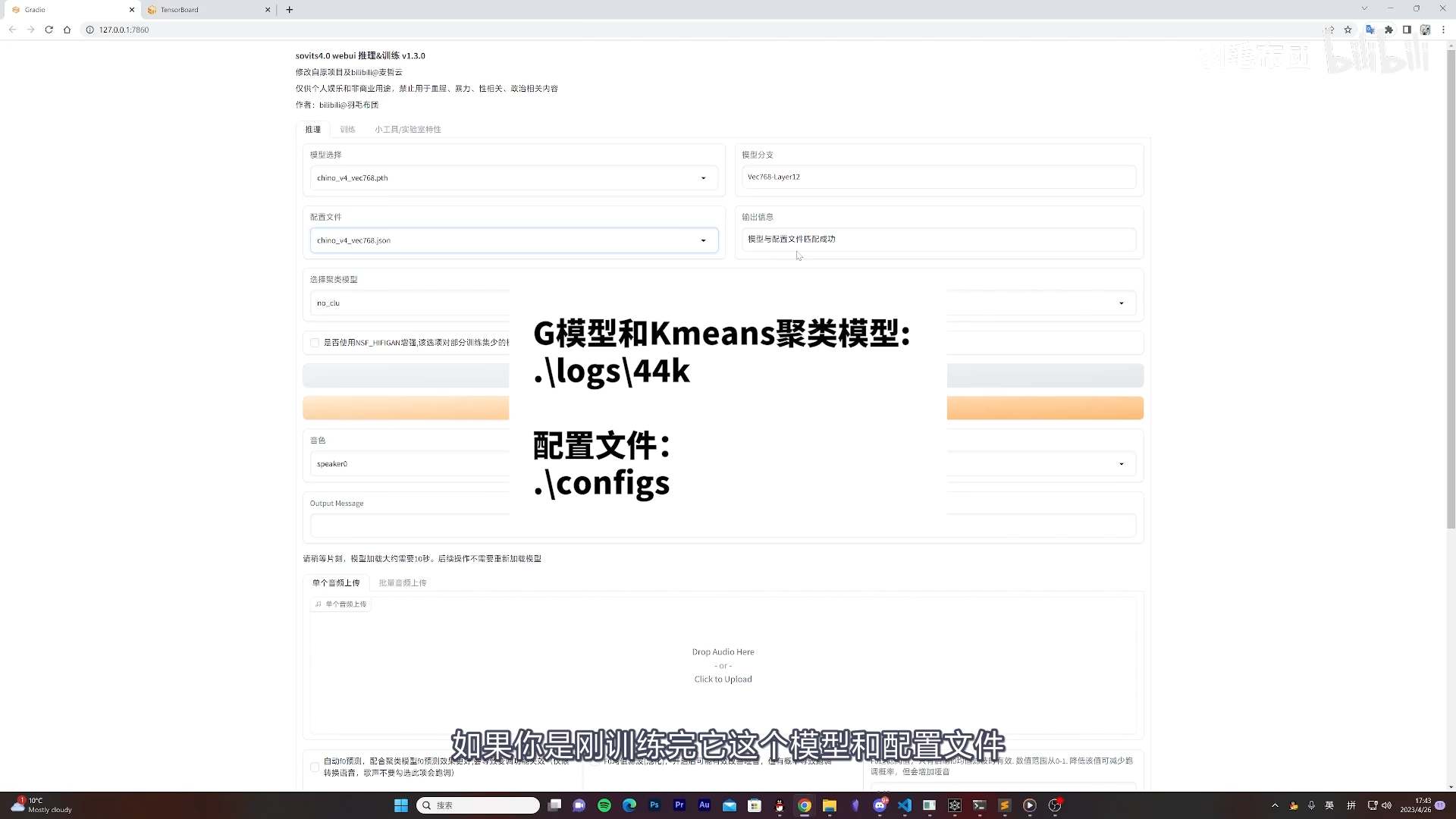
- 如果路径不是这个的话,是读取不到的
模型参数选择 - 这模型选择的是G打头的文件,后面的这个数字就是他的训练步数
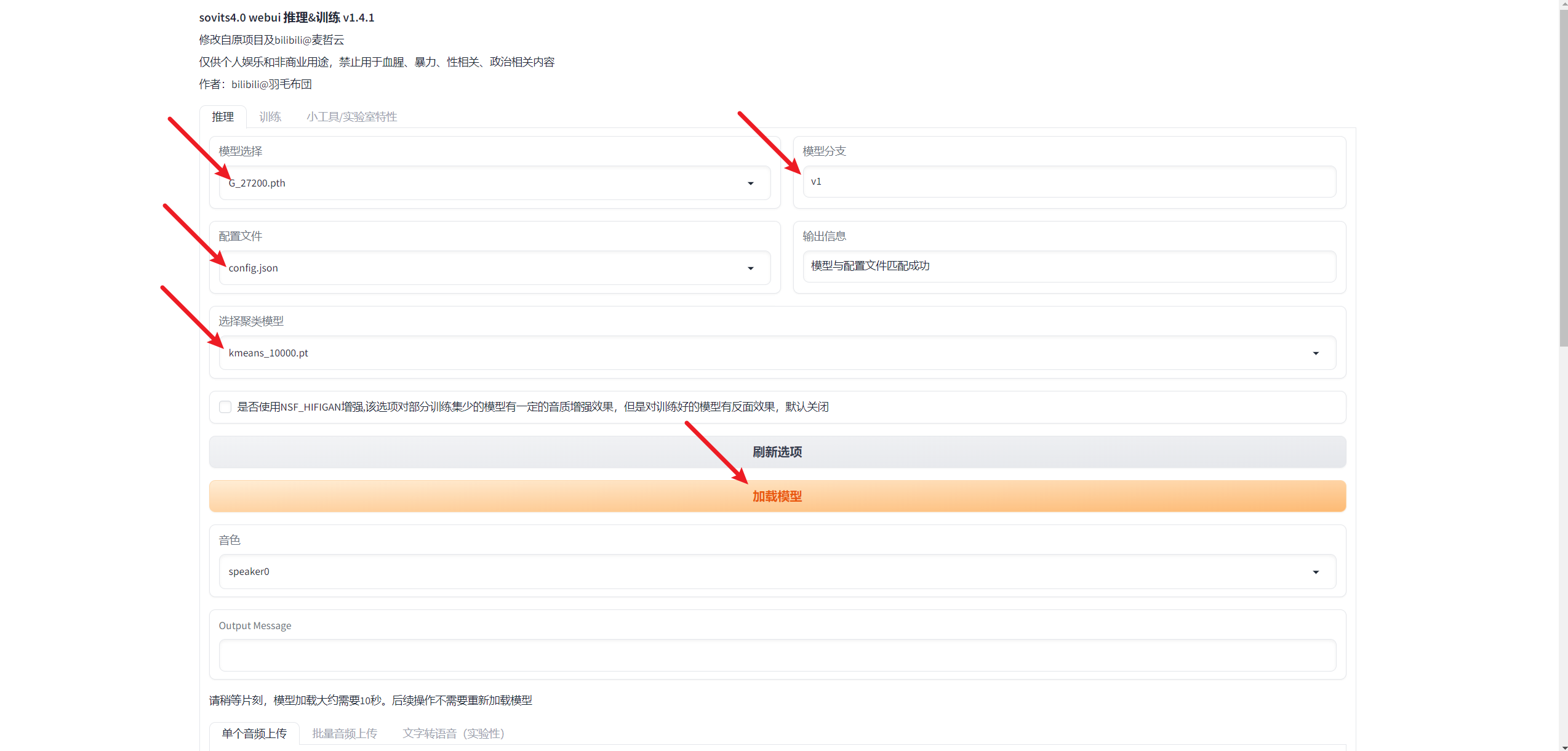
- 点完之后点击加载模型,稍等一会儿,这个模型就可以加载到自己的显卡上面了

5.2. 上传音频进行推理
-
加载完模型之后,上传一段去除了背景声的音频,之后点击这个音频转换
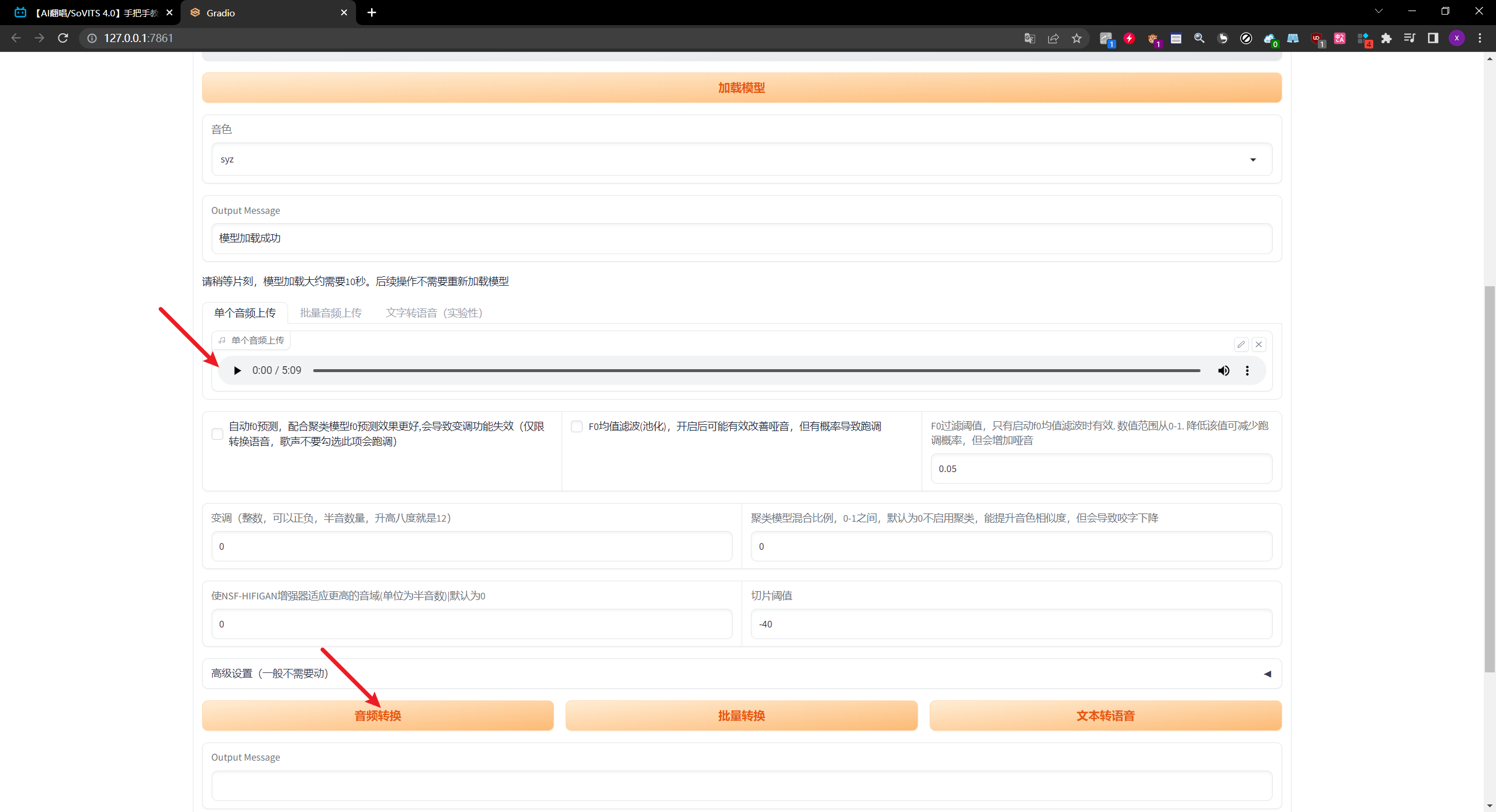
-
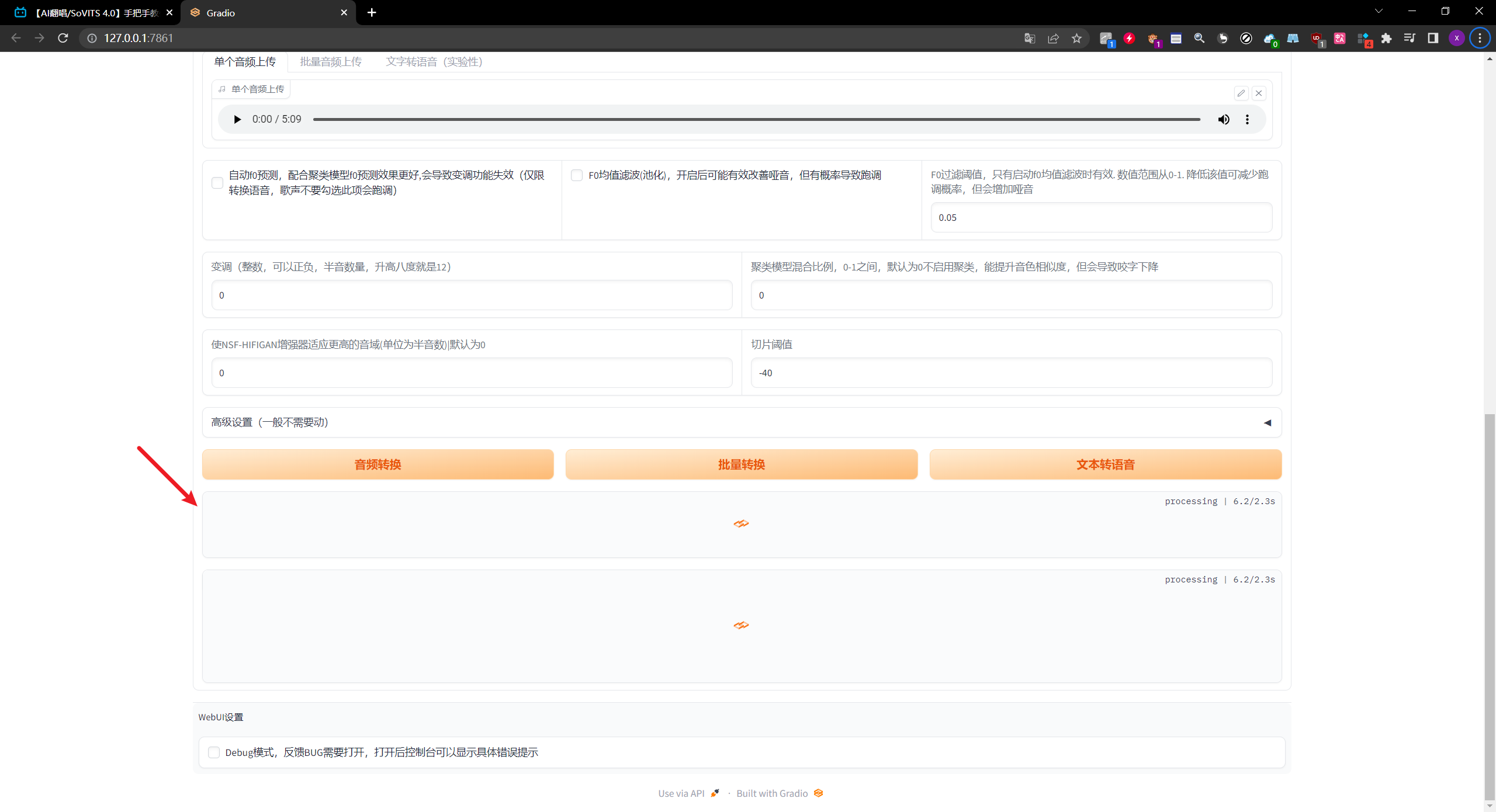
推理完成后,点击这里进行试听
-

-
如果确定是自己想要的效果的话,点击音频右边的三个点进行下载
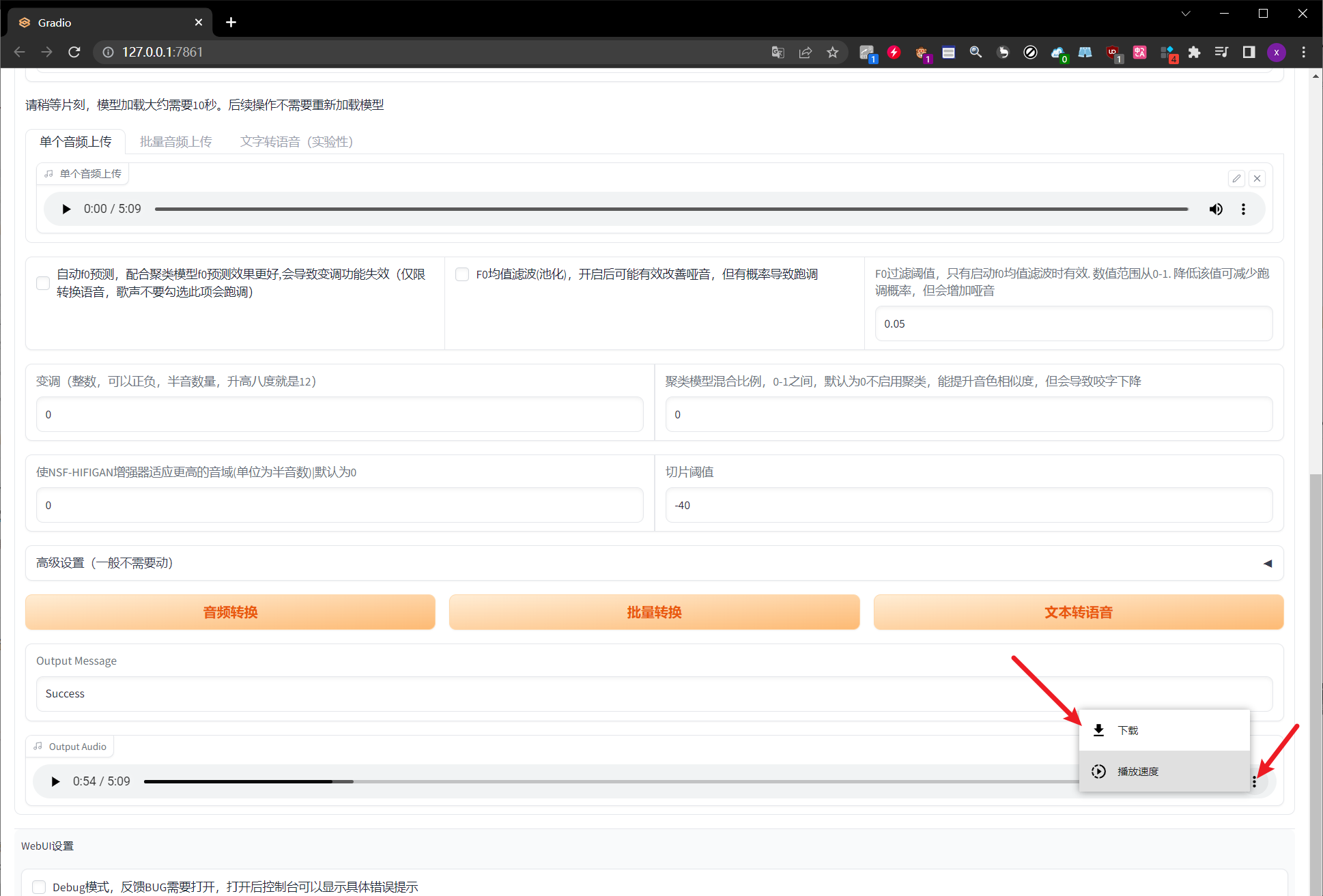
-
需要注意的是,这里是纯人声,并没有伴奏,之后可以把它导入到PR或者一些类似的处理软件中进行声音的合成

-
之后就可以导出来或者发布到其他平台上了
(img-L8NnbjCy-1683636718490)]
- 需要注意的是,这里是纯人声,并没有伴奏,之后可以把它导入到PR或者一些类似的处理软件中进行声音的合成
[外链图片转存中…(img-4E0VZD7i-1683636718490)] - 之后就可以导出来或者发布到其他平台上了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/315064
推荐阅读
相关标签

