
- 1C++list_c++ list find
- 2Coherence Score验证LDA主题分类水平_coherence 评价 主题数目
- 3逐行对比LLaMA2和LLaMA模型源代码_llama2 论文
- 4openssl+ SM2 + linux 签名校验开发实例(C++)_openssl c++ sm2 linux
- 5程序员PS技能(四):程序员创建PSD文件、展示简单PSD设计流程,上传PSD至蓝湖,并下载Demo切图
- 6面试官问你什么B树和B+树,把这篇文章丢给他
- 7React Native v0.70 踩坑:@tsconfig/react-native/tsconfig.json Not Found_file '@tsconfig/react-native/tsconfig.json' not fo
- 8初识大数据,一定要知道的知识!_并行计算与分布式系统两大核心技术时间
- 9英伟达对华“特供”的H20、RTX409D将受限?
- 10c++ stl容器set成员函数介绍及set集合插入,遍历等用法举例_c++ set集合按值查找
CVPR2021 基于GAN的模糊图像复原
赞
踩
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!

文章 新智元 CVPR2021 编辑:LRS
【新智元导读】马赛克的图像还能被修复?只要给深度学习模型足够的想象能力就能做到!CVPR2021上一篇论文能够相当逼真地修复低清晰度的人像照片,但网友却表示,这也许不叫修复,叫重新想象更靠谱吧!
深度学习无所不能,一张打满了马赛克的脸也能通过模型的「想象」来消除。
但这不禁让人思考,通过深度学习训练出来人脸,还叫「图像修复」吗?也许叫「生成」更靠谱一些!
香港理工大学在CVPR2021上发表了一篇论文,GAN Prior Embedded Network for Blind Face Restoration in the Wild,可以将模糊的图片变清晰。

例如这张经典的1927年召开的索尔维会议,当把图像放大到200%的时候,就会变得模糊,根据修复技术,则可以重见清晰。
有网友表示,还原(restore)这个词可能是,不能保证那个人看起来就是那个样子,或许「重新想象」更为恰当。

相比之前的工作,生成的图片更加真实。


严重损坏的人脸图像复原(Blind face restoration)是一个非常具有挑战性的问题。
由于问题的严重性和复杂的未知退化,直接训练深层神经网络往往不能得到满意的结果。
现有的基于生成对抗性网络(GAN)的方法可以产生更好的结果,但往往会产生过于平滑的修复。
这篇论文提出了一种新的人脸图像生成方法,首先学习一个用于高质量人脸图像生成的 GAN,并将其嵌入到 U-shaped DNN 中作为先验解码器,然后用一组合成的低质量人脸图像对先验嵌入的 GAN DNN 进行微调。
设计 GAN 模块是为了保证从 DNN 的深度和浅度特征分别生成 GAN 的潜码和噪声输入,控制重建图像的全局人脸结构、局部人脸细节和背景。
论文提出的 GAN 预嵌入式网络(GPEN)具有易于实现、可视化生成逼真结果的特点。
实验表明,所提出的 GPEN 取得了显着优于sota的 BFR 方法在定量和定性,尤其是在野外严重退化的人脸图像恢复的结果。
论文中提出的GPEN网络的架构:
(a) 是一个GAN先验网络
(b)是一个GAN块的细节部分
(c)是GPEN的完整的架构
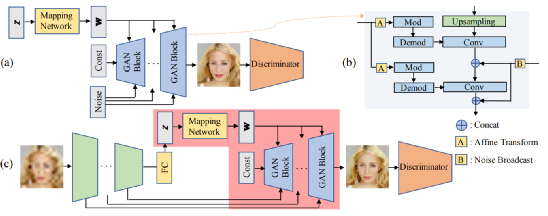
GAN先验网络U-Net在许多图像恢复任务中得到了成功和广泛的应用,并证明了它能够保存图像细节。
因此,GPEN总体上遵循U-shaped编码器-解码器架构。
GAN先验网络应设计成满足两个要求:
1)能够生成高质量的人脸图像;
2)它可以很容易地嵌入到U-shaped GPEN中作为解码器。
受最先进的GAN架构的启发,例如StyleGAN,使用映射网络将潜码z投射到纠缠度较小的空间w∈ W中。然后将中间码w扩散到每个GAN块。
由于GAN-prior网络将嵌入Ushaped DNN中进行微调,因此我们需要为跳过由U-shaped DNN的编码器提取的特征映射。
除此之外,训练数据还提供额外的噪声输入到每个块中。

对于GAN块的构造,有几种选择。在这项工作中采用了StyleGAN v2的架构,因为其生成HQ图像的能力很强(其他可供选择的GAN架构,如StyleGAN v1、PGGAN和BigGAN也可以很容易被GPEN采用)
GAN的块数等于U形DNN中提取的跳过特征映射的个数(和噪声输入的个数),与输入人脸图像的分辨率有关。
StyleGAN在每个GAN块中需要两个不同的噪声输入。
不同于StyleGAN,为了使GAN先验网络能够容易地嵌入到U形GPEN中,噪声输入以相同的空间分辨率重复应用到所有的GAN块中。
此外,在StyleGAN中,噪声输入被串联而不是添加到卷积中。
研究人员经验性地发现,这可以带来更多的细节来还原的人脸图像。

完整的网络架构:一旦使用一些数据集(例如FFHQ)训练了GAN先验网络后,将其嵌入U形DNN中作为解码器。
潜在的代码z和噪声输入到GAN网络被替换为输出全连接层(即较深的特征)和较浅的各层的编码器的DNN,这将控制重建全局人脸结构,局部人脸细节,以及人脸图像的背景。
因为该模型是不完全卷积的低质量人脸图像,输入到GPEN之前首先调整到所需的分辨率(例如1024*1024)使用简单的双线性插值。
在嵌入之后,整个GPEN将进行微调,以便将编码器部分和解码器部分可以学习适应彼此。

参考资料:
https://www.reddit.com/r/artificial/comments/o221ni/gpen_restores_extremely_degraded_faces_that_is/
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!


