
- 1Python画图之散点图(plt.scatter)_python plt.scatter
- 2数据仓库内容分享(十六):Doris到底有多牛,为什么大厂都在使用它?_doris 适合做业务数据库吗
- 3经验风险最小化与结构风险最小化笔记_(____6__ _)最小化原则在样本有限时是不合理的,此时一个小的经验风险值并不能
- 4「飞桨星河社区创作者激励计划」全新上线!丰富权益,等你领取~
- 5毕业设计|基于SpringBoot+Vue的校园交友平台_校园社交网络平台代码
- 6解决eureka client启动报错registration status: 204_eureka 204
- 7【转载】常见26种NLP任务的练手项目_nlp项目
- 8相似度计算(1)——余弦相似度_余弦相似度算法
- 9图像、视频生成大一统!MSRA+北大全华班「女娲」模型怒刷8项SOTA,完虐OpenAI DALL-E...
- 10scrapy+selenium实战,热搜明星数据分析,看看有哪些好玩的事情
Grad-CAM的详细介绍和Pytorch代码实现
赞
踩
Grad-CAM (Gradient-weighted Class Activation Mapping) 是一种可视化深度神经网络中哪些部分对于预测结果贡献最大的技术。它能够定位到特定的图像区域,从而使得神经网络的决策过程更加可解释和可视化。
Grad-CAM 的基本思想是,在神经网络中,最后一个卷积层的输出特征图对于分类结果的影响最大,因此我们可以通过对最后一个卷积层的梯度进行全局平均池化来计算每个通道的权重。这些权重可以用来加权特征图,生成一个 Class Activation Map (CAM),其中每个像素都代表了该像素区域对于分类结果的重要性。
相比于传统的 CAM 方法,Grad-CAM 能够处理任意种类的神经网络,因为它不需要修改网络结构或使用特定的层结构。此外,Grad-CAM 还可以用于对特征的可视化,以及对网络中的一些特定层或单元进行分析。
在Pytorch中,我们可以使用钩子 (hook) 技术,在网络中注册前向钩子和反向钩子。前向钩子用于记录目标层的输出特征图,反向钩子用于记录目标层的梯度。在本篇文章中,我们将详细介绍如何在Pytorch中实现Grad-CAM。
加载并查看预训练的模型
为了演示Grad-CAM的实现,我将使用来自Kaggle的胸部x射线数据集和我制作的一个预训练分类器,该分类器能够将x射线分类为是否患有肺炎。
model_path="your/model/path/"
# instantiate your model
model=XRayClassifier()
# load your model. Here we're loading on CPU since we're not going to do
# large amounts of inference
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
# put it in evaluation mode for inference
model.eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
首先我们看看这个模型的架构。就像前面提到的,我们需要识别最后一个卷积层,特别是它的激活函数。这一层表示模型学习到的最复杂的特征,它最有能力帮助我们理解模型的行为,下面是我们这个演示模型的代码:
importtorch importtorch.nnasnn importtorch.nn.functionalasF # hyperparameters nc=3# number of channels nf=64# number of features to begin with dropout=0.2 device=torch.device('cuda'iftorch.cuda.is_available() else'cpu') # setup a resnet block and its forward function classResNetBlock(nn.Module): def__init__(self, in_channels, out_channels, stride=1): super(ResNetBlock, self).__init__() self.conv1=nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1=nn.BatchNorm2d(out_channels) self.conv2=nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False) self.bn2=nn.BatchNorm2d(out_channels) self.shortcut=nn.Sequential() ifstride!=1orin_channels!=out_channels: self.shortcut=nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(out_channels) ) defforward(self, x): out=F.relu(self.bn1(self.conv1(x))) out=self.bn2(self.conv2(out)) out+=self.shortcut(x) out=F.relu(out) returnout # setup the final model structure classXRayClassifier(nn.Module): def__init__(self, nc=nc, nf=nf, dropout=dropout): super(XRayClassifier, self).__init__() self.resnet_blocks=nn.Sequential( ResNetBlock(nc, nf, stride=2), # (B, C, H, W) -> (B, NF, H/2, W/2), i.e., (64,64,128,128) ResNetBlock(nf, nf*2, stride=2), # (64,128,64,64) ResNetBlock(nf*2, nf*4, stride=2), # (64,256,32,32) ResNetBlock(nf*4, nf*8, stride=2), # (64,512,16,16) ResNetBlock(nf*8, nf*16, stride=2), # (64,1024,8,8) ) self.classifier=nn.Sequential( nn.Conv2d(nf*16, 1, 8, 1, 0, bias=False), nn.Dropout(p=dropout), nn.Sigmoid(), ) defforward(self, input): output=self.resnet_blocks(input.to(device)) output=self.classifier(output) returnoutput

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
模型3通道接收256x256的图片。它期望输入为[batch size, 3,256,256]。每个ResNet块以一个ReLU激活函数结束。对于我们的目标,我们需要选择最后一个ResNet块。
XRayClassifier( (resnet_blocks): Sequential( (0): ResNetBlock( (conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(3, 64, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): ResNetBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (2): ResNetBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (3): ResNetBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (4): ResNetBlock( (conv1): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ) (classifier): Sequential( (0): Conv2d(1024, 1, kernel_size=(8, 8), stride=(1, 1), bias=False) (1): Dropout(p=0.2, inplace=False) (2): Sigmoid() ) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
在Pytorch中,我们可以很容易地使用模型的属性进行选择。
model.resnet_blocks[-1]
#ResNetBlock(
# (conv1): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (shortcut): Sequential(
# (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
#)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Pytorch的钩子函数
Pytorch有许多钩子函数,这些函数可以处理在向前或后向传播期间流经模型的信息。我们可以使用它来检查中间梯度值,更改特定层的输出。
在这里,我们这里将关注两个方法:
register_full_backward_hook(hook, prepend=False)
该方法在模块上注册了一个后向传播的钩子,当调用backward()方法时,钩子函数将会运行。后向钩子函数接收模块本身的输入、相对于层的输入的梯度和相对于层的输出的梯度
hook(module, grad_input, grad_output) -> tuple(Tensor) or None
- 1
它返回一个torch.utils.hooks.RemovableHandle,可以使用这个返回值来删除钩子。我们在后面会讨论这个问题。
*register_forward_hook(hook, , prepend=False, with_kwargs=False)
这与前一个非常相似,它在前向传播中后运行,这个函数的参数略有不同。它可以让你访问层的输出:
hook(module, args, output) -> None or modified output
- 1
它的返回也是torch.utils.hooks.RemovableHandle
向模型添加钩子函数
为了计算Grad-CAM,我们需要定义后向和前向钩子函数。这里的目标是关于最后一个卷积层的输出的梯度,需要它的激活,即层的激活函数的输出。钩子函数会在推理和向后传播期间为我们提取这些值。
# defines two global scope variables to store our gradients and activations gradients=None activations=None defbackward_hook(module, grad_input, grad_output): globalgradients# refers to the variable in the global scope print('Backward hook running...') gradients=grad_output # In this case, we expect it to be torch.Size([batch size, 1024, 8, 8]) print(f'Gradients size: {gradients[0].size()}') # We need the 0 index because the tensor containing the gradients comes # inside a one element tuple. defforward_hook(module, args, output): globalactivations# refers to the variable in the global scope print('Forward hook running...') activations=output # In this case, we expect it to be torch.Size([batch size, 1024, 8, 8]) print(f'Activations size: {activations.size()}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在定义了钩子函数和存储激活和梯度的变量之后,就可以在感兴趣的层中注册钩子,注册的代码如下:
backward_hook=model.resnet_blocks[-1].register_full_backward_hook(backward_hook, prepend=False)
forward_hook=model.resnet_blocks[-1].register_forward_hook(forward_hook, prepend=False)
- 1
- 2
检索需要的梯度和激活
现在已经为模型设置了钩子函数,让我们加载一个图像,计算gradcam。
fromPILimportImage
img_path="/your/image/path/"
image=Image.open(img_path).convert('RGB')
- 1
- 2
- 3
- 4
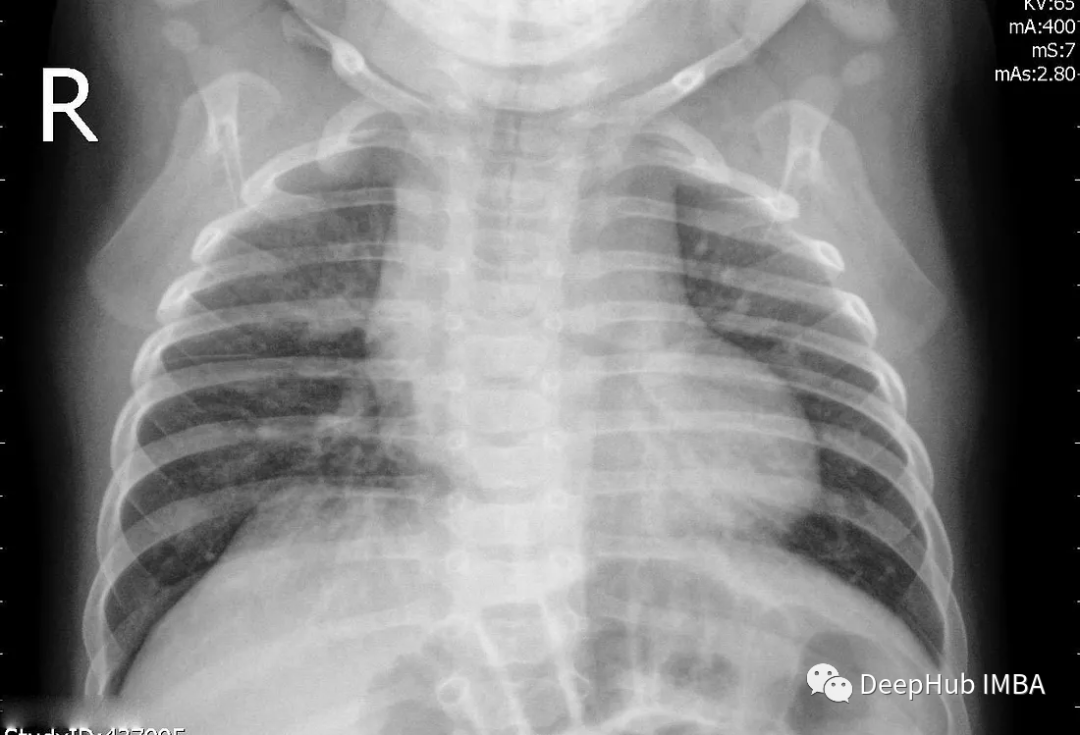
为了进行推理,我们还需要对其进行预处理:
fromtorchvisionimporttransforms
fromtorchvision.transformsimportToTensor
image_size=256
transform=transforms.Compose([
transforms.Resize(image_size, antialias=True),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
img_tensor=transform(image) # stores the tensor that represents the image
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
现在就可以进行前向传播了:
model(img_tensor.unsqueeze(0)).backward()
- 1
钩子函数的返回如下:
Forwardhookrunning...
Activationssize: torch.Size([1, 1024, 8, 8])
Backwardhookrunning...
Gradientssize: torch.Size([1, 1024, 8, 8])
- 1
- 2
- 3
- 4
得到了梯度和激活变量后就可以生成热图:
计算Grad-CAM
为了计算Grad-CAM,我们将原始论文公式进行一些简单的修改:

pooled_gradients=torch.mean(gradients[0], dim=[0, 2, 3])
- 1

importtorch.nn.functionalasF importmatplotlib.pyplotasplt # weight the channels by corresponding gradients foriinrange(activations.size()[1]): activations[:, i, :, :] *=pooled_gradients[i] # average the channels of the activations heatmap=torch.mean(activations, dim=1).squeeze() # relu on top of the heatmap heatmap=F.relu(heatmap) # normalize the heatmap heatmap/=torch.max(heatmap) # draw the heatmap plt.matshow(heatmap.detach())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
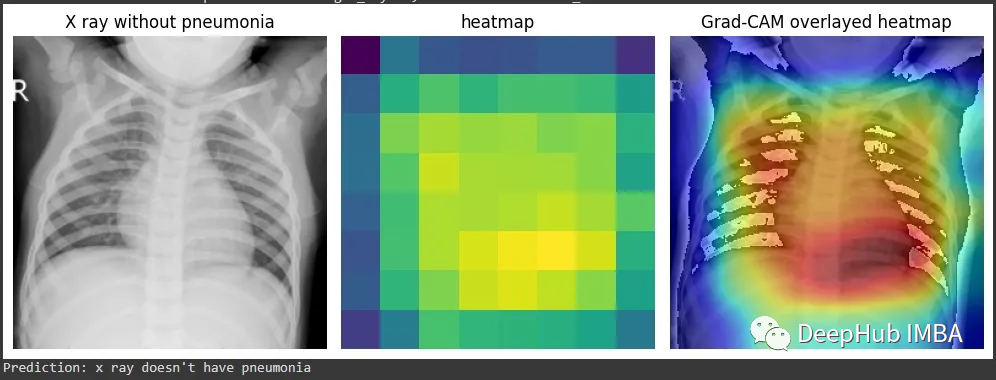
结果如下:
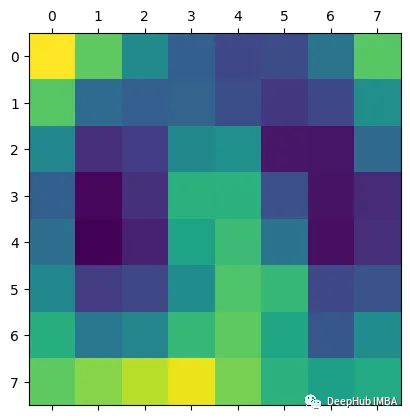
得到的激活包含1024个特征映射,这些特征映射捕获输入图像的不同方面,每个方面的空间分辨率为8x8。通过钩子获得的梯度表示每个特征映射对最终预测的重要性。通过计算梯度和激活的元素积可以获得突出显示图像最相关部分的特征映射的加权和。通过计算加权特征图的全局平均值,可以得到一个单一的热图,该热图表明图像中对模型预测最重要的区域。这就是Grad-CAM,它提供了模型决策过程的可视化解释,可以帮助我们解释和调试模型的行为。
但是这个图能代表什么呢?我们将他与图片进行整合就能更加清晰的可视化了。
结合原始图像和热图
下面的代码将原始图像和我们生成的热图进行整合显示:
fromtorchvision.transforms.functionalimportto_pil_image frommatplotlibimportcolormaps importnumpyasnp importPIL # Create a figure and plot the first image fig, ax=plt.subplots() ax.axis('off') # removes the axis markers # First plot the original image ax.imshow(to_pil_image(img_tensor, mode='RGB')) # Resize the heatmap to the same size as the input image and defines # a resample algorithm for increasing image resolution # we need heatmap.detach() because it can't be converted to numpy array while # requiring gradients overlay=to_pil_image(heatmap.detach(), mode='F') .resize((256,256), resample=PIL.Image.BICUBIC) # Apply any colormap you want cmap=colormaps['jet'] overlay= (255*cmap(np.asarray(overlay) **2)[:, :, :3]).astype(np.uint8) # Plot the heatmap on the same axes, # but with alpha < 1 (this defines the transparency of the heatmap) ax.imshow(overlay, alpha=0.4, interpolation='nearest', extent=extent) # Show the plot plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
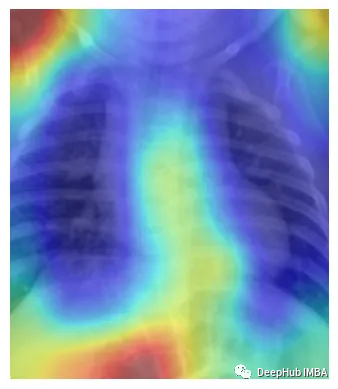
这样看是不是就理解多了。由于它是一个正常的x射线结果,所以并没有什么需要特殊说明的。
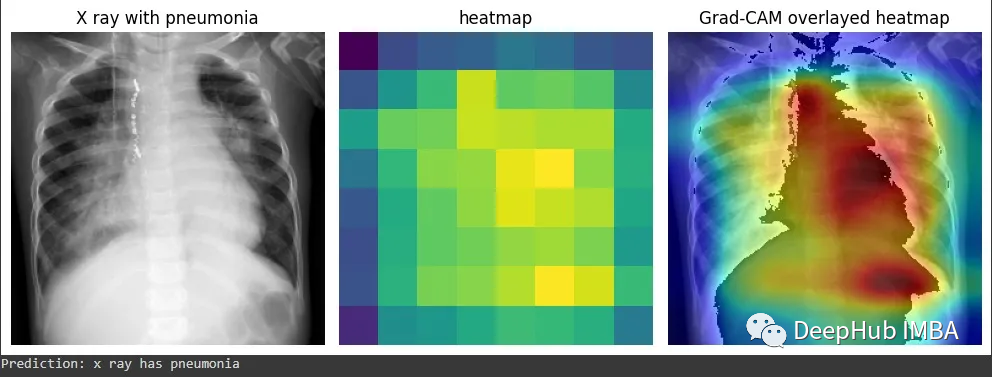
再看这个例子,这个结果中被标注的是肺炎。Grad-CAM能准确显示出医生为确定是否患有肺炎而必须检查的胸部x光片区域。也就是说我们的模型的确学到了一些东西(红色区域再肺部附近)
删除钩子
要从模型中删除钩子,只需要在返回句柄中调用remove()方法。
backward_hook.remove()
forward_hook.remove()
- 1
- 2
总结
这篇文章可以帮助你理清Grad-CAM 是如何工作的,以及如何用Pytorch实现它。因为Pytorch包含了强大的钩子函数,所以我们可以在任何模型中使用本文的代码。
https://avoid.overfit.cn/post/59ce70fd73cc4110acd4016e992b50ea
作者:Vinícius Almeida

